大家好,又见面了,我是你们的朋友全栈君。
四、全卷积网络FCN详细讲解(超级详细哦)
1、全卷积网络(FCN)的简单介绍
1.1、CNN与FCN的比较
CNN: 在传统的CNN网络中,在最后的卷积层之后会连接上若干个全连接层,将卷积层产生的特征图(feature map)映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率,如ALexNet网络最后输出一个1000维的向量表示输入图像属于每一类的概率。如下图所示:
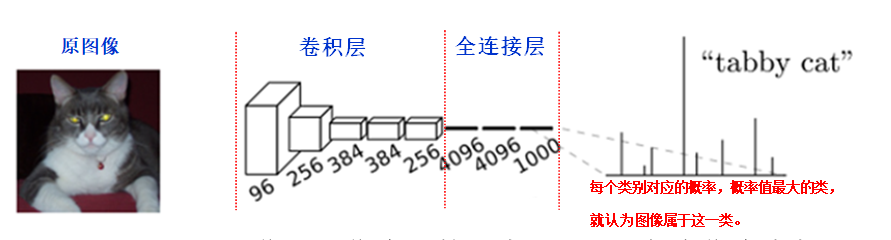

在CNN中, 猫的图片输入到AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高, 用来做分类任务。
FCN: FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题。与上面介绍的经典CNN在卷积层使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷基层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸,从而可以对每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息,最后奇偶在上采样的特征图进行像素的分类。如下图所示:
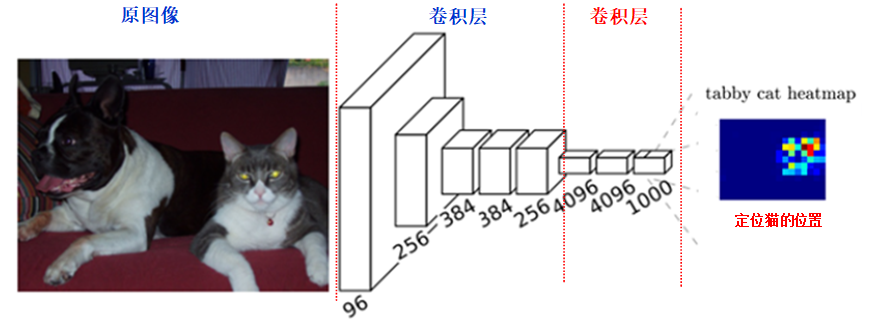
简单的说,FCN与CNN的区别在于FCN把CNN最后的全连接层换成卷积层,其输出的是一张已经标记好的图,而不是一个概率值。
2、FCN上采样理论讲解
FCN网络一般是用来对图像进行语义分割的,于是就需要对图像上的各个像素进行分类,这就需要一个上采样将最后得到的输出上采样到原图的大小。上采样对于低分辨率的特征图,常常采用上采样的方式将它还原高分辨率,这里陈述上采样的三种方法。
2.1、双线性插值上采样
单线性插值(一个方向上)就是知道两个点的值,并将两点连成一条直线,来确定中间的点的值,假设,现在有两点 ( x 1 , y 1 ) 、 ( x 2 , y 2 ) (x_1,y_1 )、(x_2,y_2) (x1,y1)、(x2,y2)连成一条直线, [ x 1 , x 2 ] [x_1,x_2] [x1,x2]中的点就可以用线上的点表示。双线性插值(两个方向上)是一个三维的坐标系,因此,需要找到4个点来确定中心点坐标,如下图所示的例子:
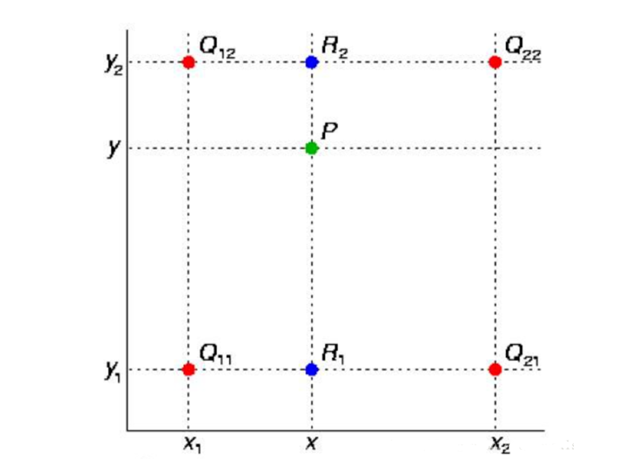
假如我们想得到未知函数 f 在点 P = (x, y) 的值,假设我们已知函数 f 在 Q 1 1 = ( x 1 , y 1 ) 、 Q 1 2 = ( x 1 , y 2 ) , Q 2 1 = ( x 2 , y 1 ) Q_11 = (x_1, y_1)、Q_12 = (x_1, y_2), Q_21 = (x_2, y_1) Q11=(x1,y1)、Q12=(x1,y2),Q21=(x2,y1)以及 Q 2 2 = ( x 2 , y 2 ) Q_22 = (x_2, y_2) Q22=(x2,y2) 四个点的值。最常见的情况,f就是一个像素点的像素值。首先在 x 方向进行线性插值,得到:
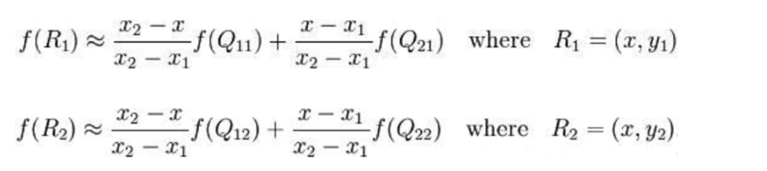
然后在 y 方向进行线性插值,得到:
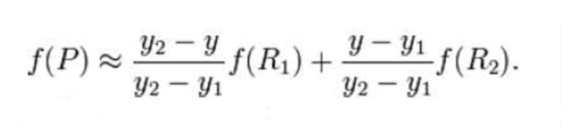
综合起来就是双线性插值最后的结果:
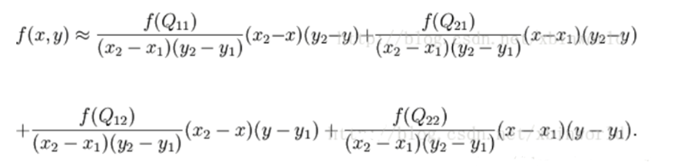
由于图像双线性插值只会用相邻的4个点,因此上述公式的分母都是1。opencv中的源码如下,用了一些优化手段,比如用整数计算代替float(下面代码中的*2048就是变11位小数为整数,最后有两个连乘,因此>>22位),以及源图像和目标图像几何中心的对齐
- SrcX=(dstX+0.5)* (srcWidth/dstWidth) -0.5
- SrcY=(dstY+0.5) * (srcHeight/dstHeight)-0.5,
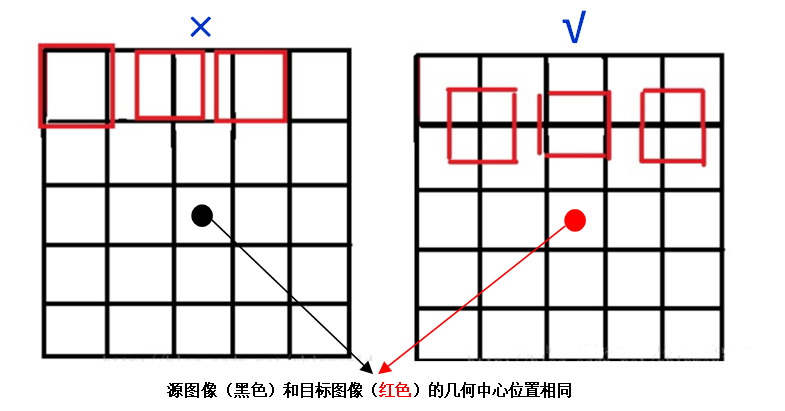
这个要重点说一下,源图像和目标图像的原点(0,0)均选择左上角,然后根据插值公式计算目标图像每点像素,假设你需要将一幅5×5的图像缩小成3×3,那么源图像和目标图像各个像素之间的对应关系如下。如果没有这个中心对齐,根据基本公式去算,就会得到左边这样的结果;而用了对齐,就会得到右边的结果:
2.2、反卷积上采样
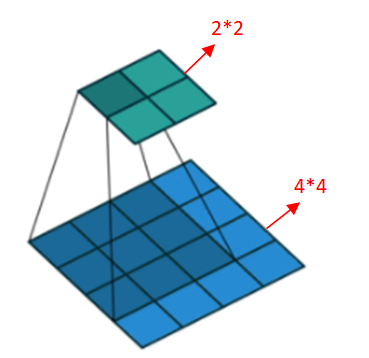
怎样上采样: 普通的卷积操作,会使得分辨率降低,如下图33的卷积核去卷积44得到2*2的输出。
上采样的过程也是卷积,那么怎么会得到分辨率提高呢?之前我们看卷积时有个保持输出与输入同分辨率的方法就是周围补0。
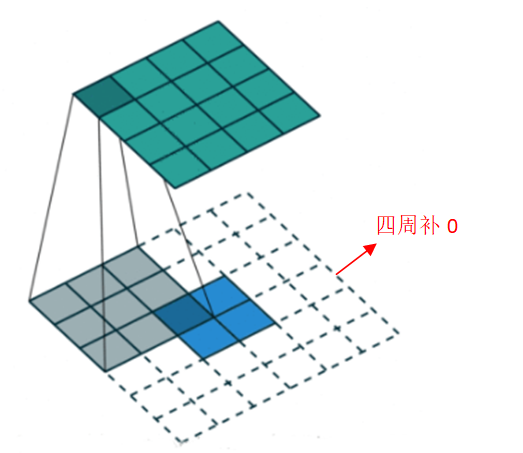
其实上面这种补0的方法事有问题的,你想一下,只在四周补0会导致最边上的信息不太好,那我们把这个信息平均下,在每个像素与像素之间补0,如下图所示:
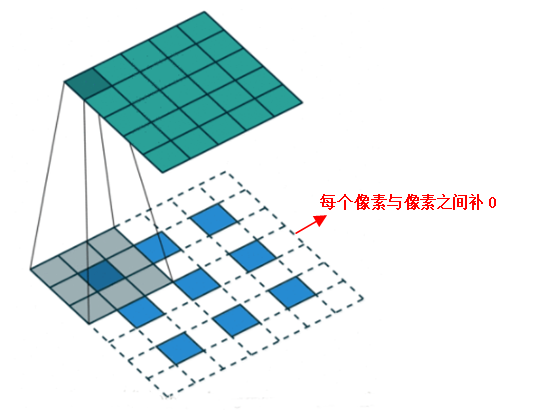
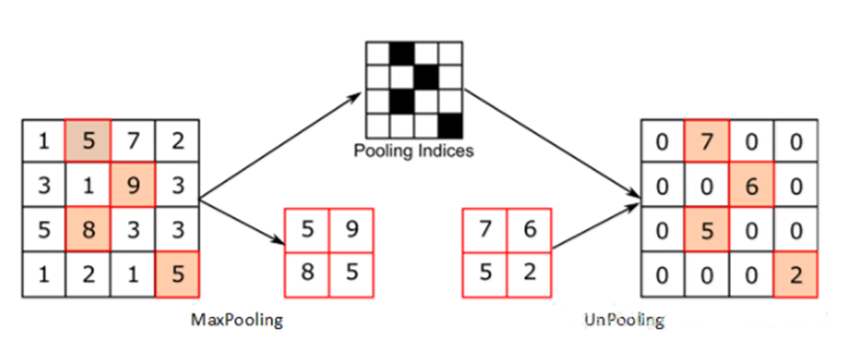
2.3、反池化上采样
反池化可以用下图来理解,再池化时需要记录下池化的位置,反池化时把池化的位置直接还原,其他位置填0。
上面三种方法各有优缺,双线性插值方法实现简单,无需训练;反卷积上采样需要训练,但能更好的还原特征图;
2、 FCN具体实现过程
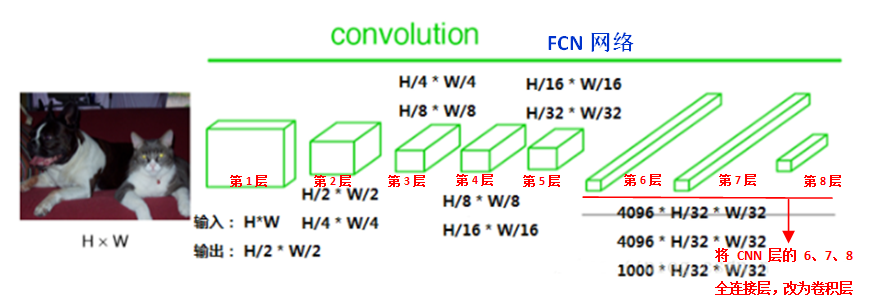
FCN与CNN的核心区别就是FCN将CNN末尾的全连接层转化成了卷积层:以Alexnet为例,输入是2272273的图像,前5层是卷积层,第5层的输出是256个特征图,大小是66,即25666,第6、7、8层分别是长度是4096、4096、1000的一维向量。如下图所示:
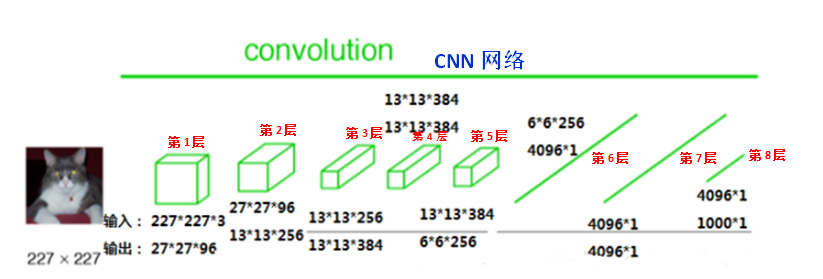
在FCN中第6、7、8层都是通过卷积得到的,卷积核的大小全部是1 * 1,第6层的输出是4096 * 7 * 7,第7层的输出是4096 * 7 * 7,第8层的输出是1000 * 7 * 7(7是输入图像大小的1/32),即1000个大小是77的特征图(称为heatmap),如下图所示:
经过多次卷积后,图像的分辨率越来越低,为了从低分辨率的热图heatmap恢复到原图大小,以便对原图上每一个像素点进行分类预测,需要对热图heatmap进行反卷积,也就是上采样。论文中首先进行了一个上池化操作,再进行反卷积(上述所提到的上池化操作和反卷积操作,其实可以理解为上卷积操作),使得图像分辨率提高到原图大小。如下图所示:

跳级(strip)结构:对第5层的输出执行32倍的反卷积得到原图,得到的结果不是很精确,论文中同时执行了第4层和第3层输出的反卷积操作(分别需要16倍和8倍的上采样),再把这3个反卷积的结果图像融合,提升了结果的精确度:
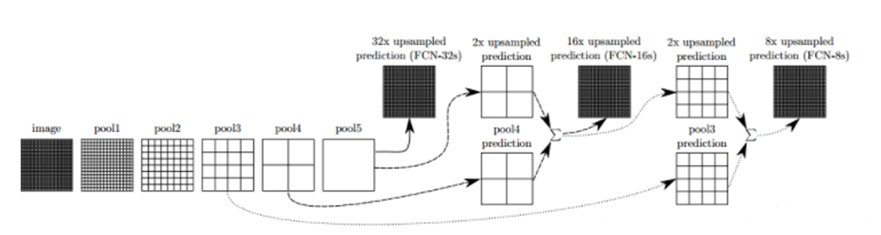
最后像素的分类按照该点在1000张上采样得到的图上的最大的概率来定。FCN可以接受任意大小的输入图像,但是FCN的分类结果还是不够精细,对细节不太敏感,再者没有考虑到像素与像素之间的关联关系,丢失了部分空间信息。
3、 FCN模型实现过程
3.1、模型训练
• 用AlexNet,VGG16或者GoogleNet训练好的模型做初始化,在这个基础上做fine-tuning,只需在末尾加上upsampling,参数的学习还是利用CNN本身的反向传播原理。
• 采用全图做训练,不进行局部抽样。实验证明直接用全图已经很高效。
FCN例子: 输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21,模型基于AlexNet。
• 蓝色:卷积层。
• 绿色:Max Pooling层。
• 黄色: 求和运算, 使用逐数据相加,把三个不同深度的预测结果进行融合:较浅的结果更为精细,较深的结果更为鲁棒。
• 灰色: 裁剪, 在融合之前,使用裁剪层统一两者大小, 最后裁剪成和输入相同尺寸输出。
• 对于不同尺寸的输入图像,各层数据的尺寸(height,width)相应变化,深度(channel)不变。
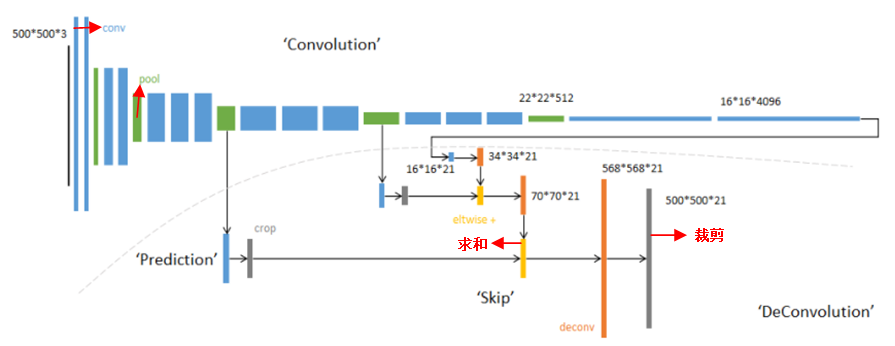
• 全卷积层部分进行特征提取, 提取卷积层(3个蓝色层)的输出来作为预测21个类别的特征。
• 图中虚线内是反卷积层的运算, 反卷积层(3个橙色层)可以把输入数据尺寸放大。和卷积层一样,升采样的具体参数经过训练确定。
1、 以经典的AlexNet分类网络为初始化。最后两级是全连接(红色),参数弃去不用。
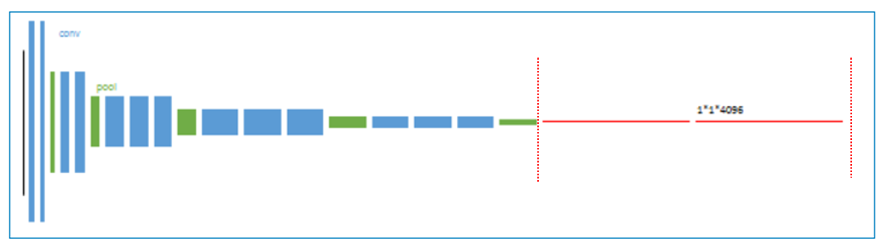
2、 反卷积(橙色)的步长为32,这个网络称为FCN-32s
从特征小图()预测分割小图(),之后直接升采样为大图。
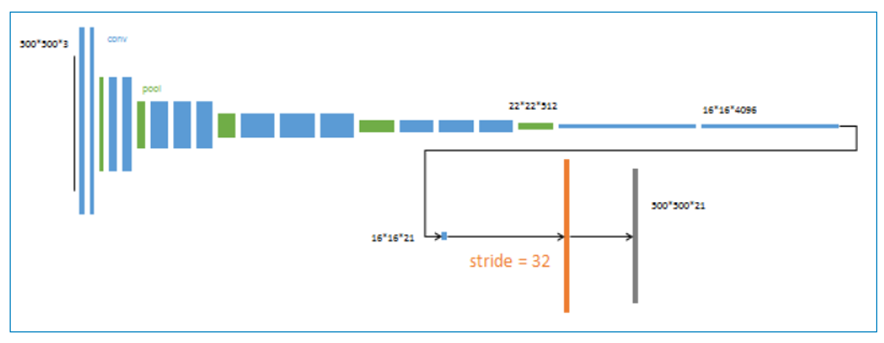
3、 第二次反卷积步长为16,这个网络称为FCN-16s
升采样分为两次完成(橙色×2), 在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。
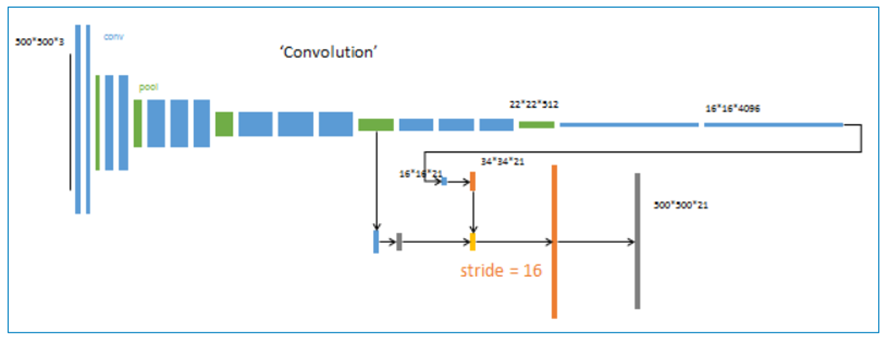
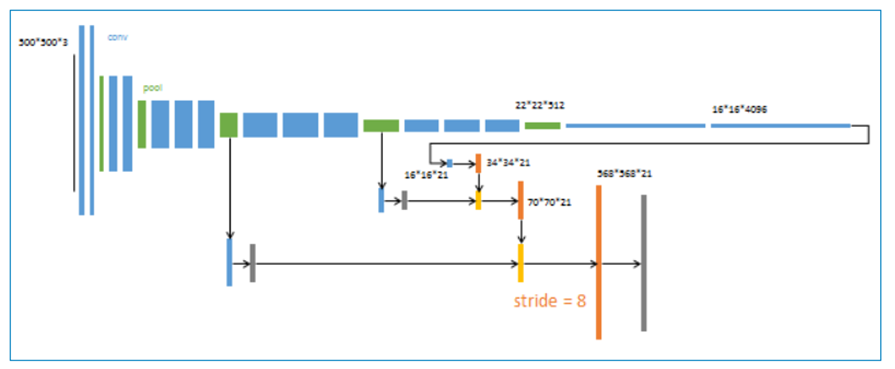
4、 第三次反卷积步长为8,记为FCN-8s。
升采样分为三次完成(橙色×3), 进一步融合了第3个pooling层的预测结果。
其他参数:
• minibatch:20张图片
• learning rate:0.001
• 初始化:分类网络之外的卷积层参数初始化为0
• 反卷积参数初始化为bilinear插值。最后一层反卷积固定位bilinear插值不做学习

总体来说,本文的逻辑如下:
• 想要精确预测每个像素的分割结果
• 必须经历从大到小,再从小到大的两个过程
• 在升采样过程中,分阶段增大比一步到位效果更好
• 在升采样的每个阶段,使用降采样对应层的特征进行辅助
缺点:
- 得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感
- 对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性
3.2、FCN模型的简单总结
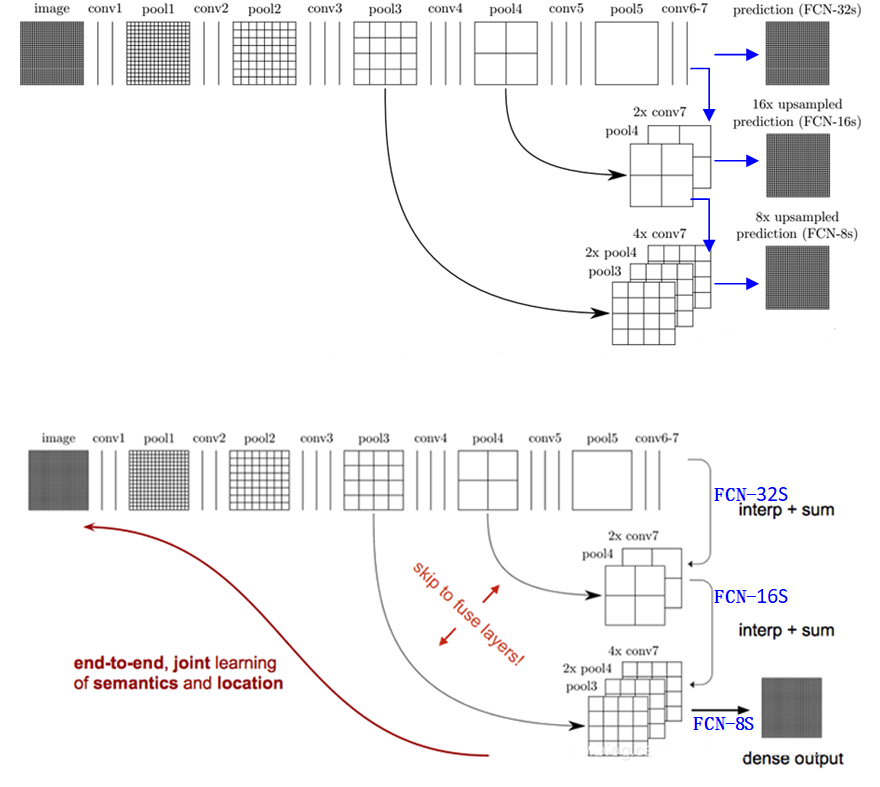
FCN的卷积网络部分可以采用VGG、GoogleNet、AlexNet等作为前置基础网络,在这些的预训练基础上进行迁移学习与finetuning,对反卷积的结果跟对应的正向feature map进行叠加输出(这样做的目的是得到更加准确的像素级别分割),根据上采样的倍数不一样分为FCN-8S、FCN-16S、FCN-32S,图示如下:
详情:
对原图像进行卷积 conv1、pool1后原图像缩小为1/2;
之后对图像进行第二次 conv2、pool2后图像缩小为1/4;
继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;
继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;
最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,
然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap。
实例
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里向前迭代。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个差值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。(具体怎么做,本博客已经在3.1节进行了详细的讲解,不懂的地方可以回过头不查看。)如下图所示:注,上下两个图表达相同的意思。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150469.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
