大家好,又见面了,我是你们的朋友全栈君。
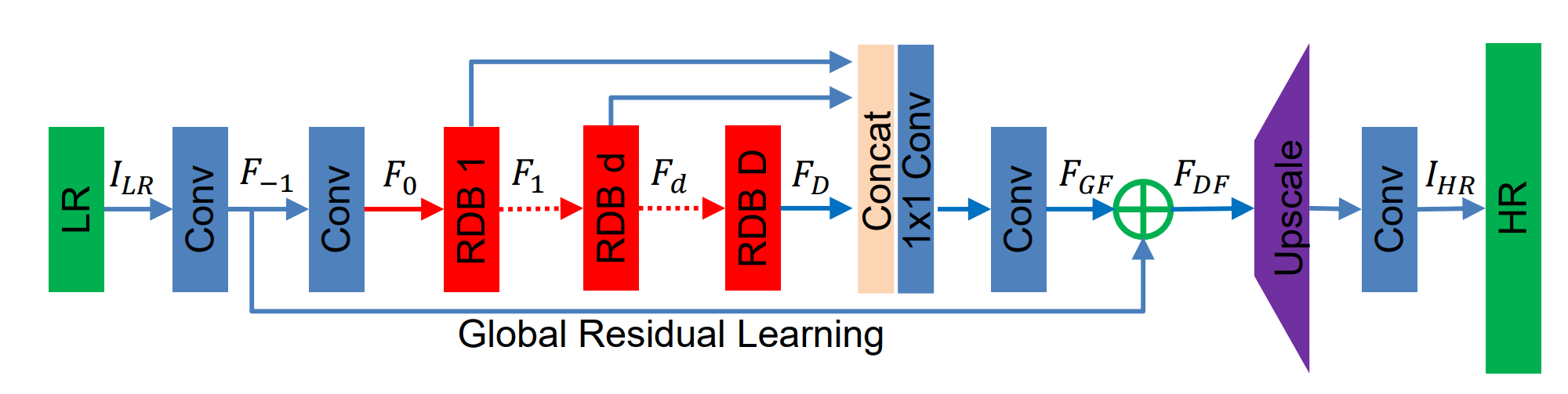

这篇文章提出了一种结合ResNet结构和DenseNet结构的深度超分网络——Residual Dense Network(后文简称RDN)。RDN基于Residual Dense Block(后文简称RDB)块以及全局残差连接来提取全局特征,而RDB块基于Dense结构和局部残差连接进一步提取局部特征。通过这种结构,作者最大化利用了 L R LR LR不同层级的特征,在当时取得了SOTA的表现力。
Note:
- 这篇文章和RCAN是同一批作者。
参考文档:
Residual Dense Network for Image Super-Resolution
Abstract
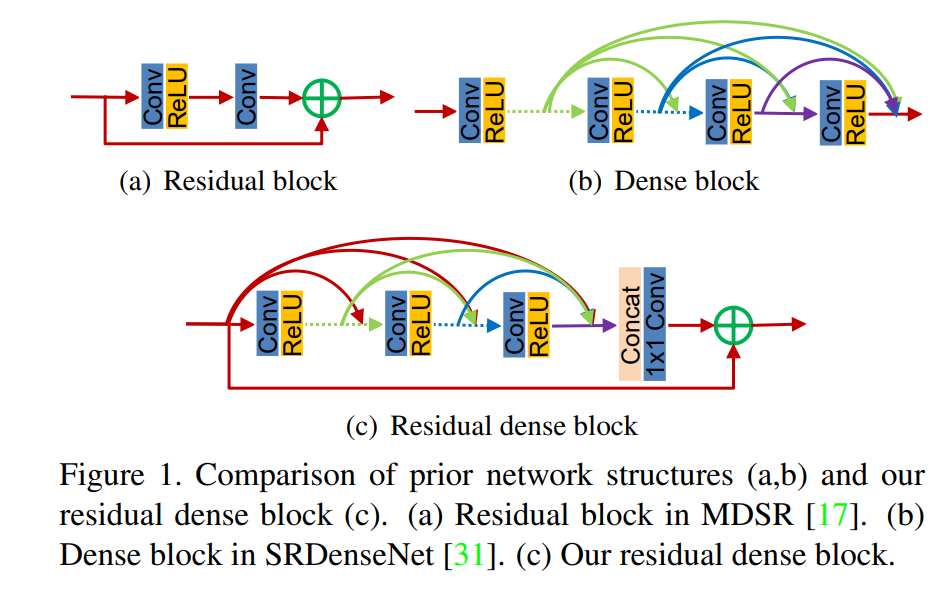
这篇文章提出的原因在于之前的SISR算法都没有很全面地利用 L R LR LR层级中所有的特征信息,如SRDenseNet、宽度网络EDSR、SRGAN(内置SRResNet)等这些虽然利用了不同层级的特征信息,但是还不够,还有更多的信息没有提取;再比如SRCNN、FSRCNN、DCSCN、ESPCN等这种就很少利用不同层级的特征信息。故为了解决这个问题,作者提出了最大化提取利用 L R LR LR层级所有的特征信息的SR算法——RDN。
RDN具有如下特点:
- RDN基于RDB模块和全局残差连接,其中RDB模块内部有 C C C个层,它们组成Dense结构和局部残差连接可以充分提取局部特征。
- RDB模块会接受上一个RDB模块的特征信息,该特征信息会分别传到RDB中稠密结构的每一级,从而构成相邻存储机制(contiguous memory)。
- 为了缓解RDB中Dense结构带来网络过宽而不稳定的现象,作者在RDB的末端加入了 1 × 1 1\times 1 1×1瓶颈层来缩小输出通道。
- RDN将 D D D个RDB块通过concat融合起来并使用全局残差连接来提取全局特征信息。
- RDN经实验证明确实充分提取了特征信息,当时取得了SOTA的表现力!
- 整个RDN网络包括低层特征提取、高层(深层)特征提取(局部特征提取+全局特征提取)、上采样层、重建层。
1 Introduction
这篇论文的贡献如下:
- 提出了一个可充分提取图像 L R LR LR层级所有特征信息的超分网络RDN,其网络结构如下:
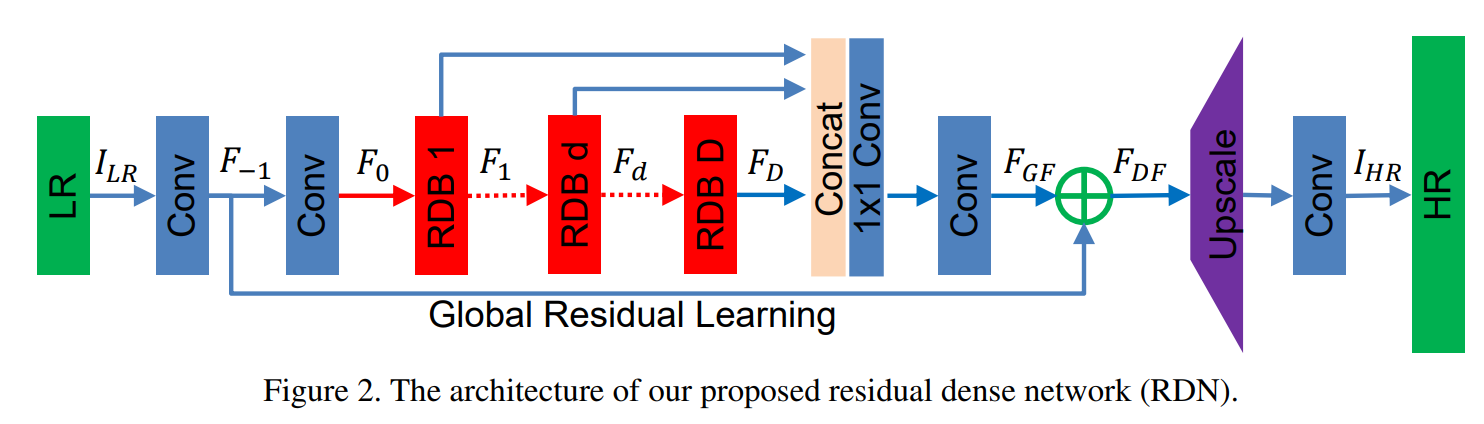 整个RDN主要基于 D D D个RDB模块进行全局特征融合(
整个RDN主要基于 D D D个RDB模块进行全局特征融合(GFF)和全局残差学习(GRL其实就是Long skip connection),将每个RDB提取的局部特征进行concat融合之后和来自低层特征信息进行残差连接,从而使得低层特征和高层特征相结合并迫使网络去学习更多的残差信息。我们通过GFF和GRL组成的Dense Feature Fusion(DFF)来提取全局特征。 - RDB模块用于充分提取 L R LR LR层级的局部特征,其网络结构如下:
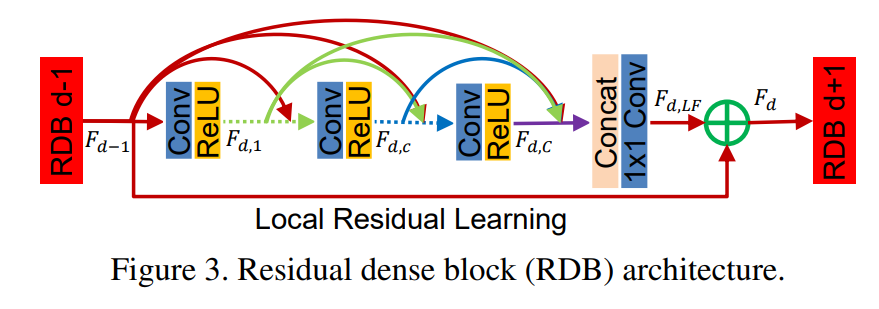
整个RDB模块由 C C C个卷积层(包括ReLU)通过Dense结构相连(LFF),并使用局部残差学习LRL(其实就是short skip connection)将上一个RDB输出的特征信息和当前RDB输出的特征信息进行结构。此外上一个RDB的输出特征还会依次加入到Dense结构的每一个层中,形成相邻存储(CM) 。此外,由于每个RDB中设置了 1 × 1 1\times 1 1×1的瓶颈层来缩小输出通道,从而整个RDB块就允许设置较大的Dense growth rate。
2 Related Work
略
3 Residual Dense Network for Image SR
接下来我们具体分析下RDN的网络结构。
3.1 Network Structure
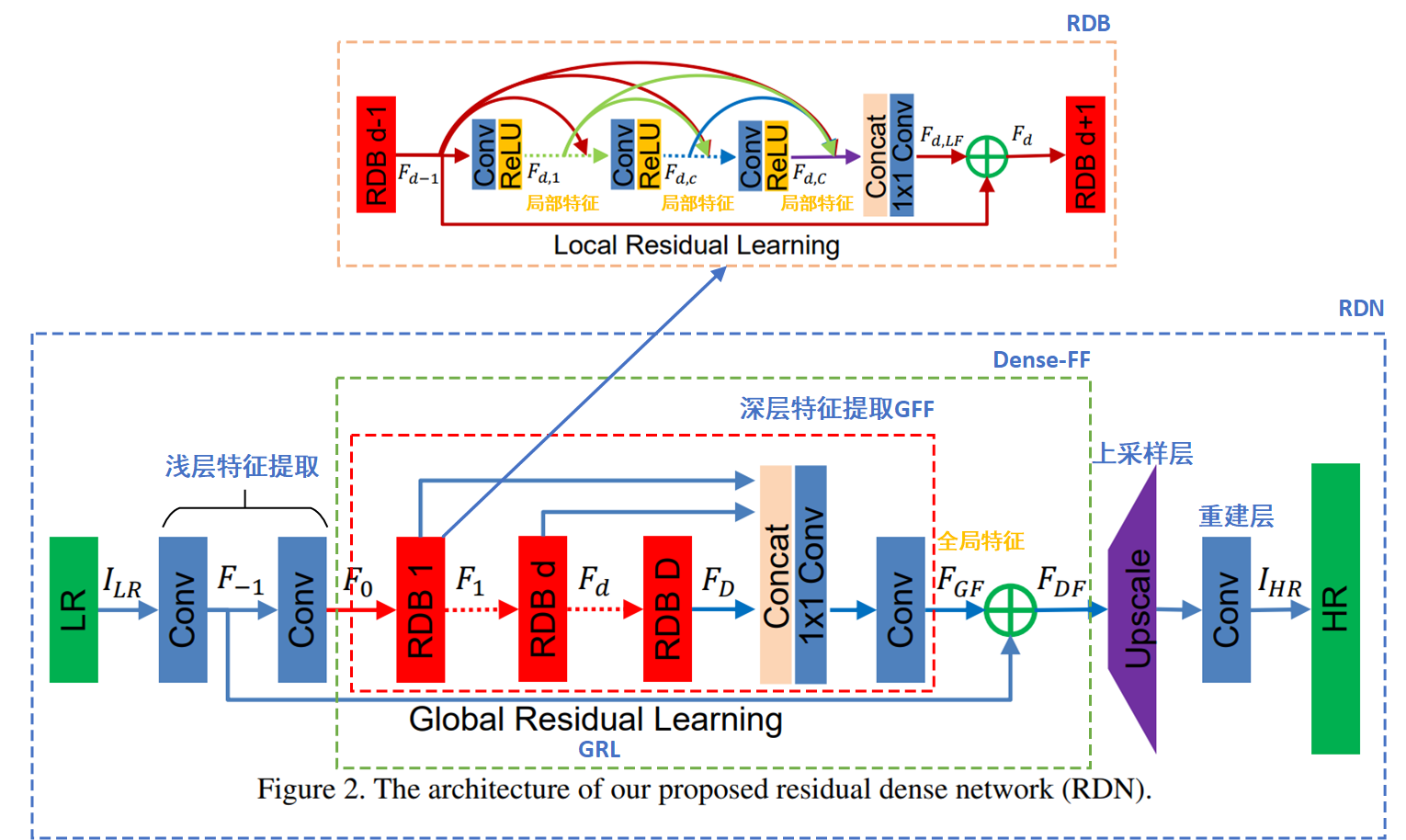
如上图所示就是整个RDN的网络结构:它包括浅层特征提取、RDBs、dense特征融合(DFF)、上采样层组成;不过我更喜欢用浅层特征提取、深层特征提取、上采样层、重建层来表示。
①浅层特征提取
和很多SR算法一样,浅层特征的提取往往只用 1 − 2 1-2 1−2层 3 × 3 3\times 3 3×3卷积层实现,具体表达式为:
F − 1 = H S F E 1 ( I L R ) . (1) F_{-1} = H_{SFE1}(I_{LR}).\tag{1} F−1=HSFE1(ILR).(1)其中 H S F E 1 ( ⋅ ) H_{SFE1}(\cdot) HSFE1(⋅)表示浅层特征第一层卷积层,它通过GRL和深层特征进行残差相连。
浅层特征提取的第二层用数学表达式为:
F 0 = H S F E 2 ( F − 1 ) . (2) F_0 = H_{SFE2}(F_{-1}).\tag{2} F0=HSFE2(F−1).(2)其中 H S F E 2 ( ⋅ ) H_{SFE2}(\cdot) HSFE2(⋅)表示浅层特征提取的第二层卷积层,它用来作为第一个RDB块的输入。
②深层特征提取
假设深层特征提取一共有 D D D个RDB块,那么对于 d ∈ { 1 , ⋯ , D } d\in \{1,\cdots,D\} d∈{
1,⋯,D},第 d d d个RDB块的输入输出可表示为:
F d = H R D B , d ( F d − 1 ) = H R D B , d ( H R D B , d − 1 ( ⋯ ( H R D B , 1 ( F 0 ) ) ⋯ ) ) . (3) F_d = H_{RDB,d}(F_{d-1})=H_{RDB,d}({\color{lightseagreen}H_{RDB,d-1}(\cdots({\color{mediumorchid}H_{RDB,1}(F_0)})\cdots)}).\tag{3} Fd=HRDB,d(Fd−1)=HRDB,d(HRDB,d−1(⋯(HRDB,1(F0))⋯)).(3)其中 F d F_d Fd表示第 d d d个RDB块输出的局部特征, H R D B , d ( ⋅ ) H_{RDB,d}(\cdot) HRDB,d(⋅)是第 d d d个RDB块算子,表示深层特征提取。
Dense Feature Fusion(DFF):最后将 D D D个RDBs的所有局部特征进行concat之后,用 1 × 1 1\times 1 1×1瓶颈层进行降维并使用一个 3 × 3 3\times 3 3×3卷积层进一步提取深层特征,最后输出的就是全局特征 F G F F_{GF} FGF。全局特征和来自浅层特征 F − 1 F_{-1} F−1通过GRL进行残差相连输出最终的Dense Feature—— F D F F_{DF} FDF,表达式为:
F D F = H D F F ( F − 1 , F 0 , F 1 , ⋯ , F D ) . (4) F_{DF} = H_{DFF}(F_{-1},F_0, F_1,\cdots,F_D).\tag{4} FDF=HDFF(F−1,F0,F1,⋯,FD).(4)其中 H D F F ( ⋅ ) H_{DFF}(\cdot) HDFF(⋅)表示整个DFF过程,它是GFF和GRL的结合。
③上采样层
上采样层采用ESPCN提出的亚像素卷积层,这种方式既节约存储资源又有较高效的执行效率,使用PyTorch可以直接调用torch.nn.PixelShuffle(r),具体可见我的另一篇PyTorch之PixelShuffle。
④重建层
和其他SR结构一样,重建层可以重用一层 3 × 3 3\times 3 3×3卷积层代替,来进一步调整校正上采样的结构。
整个RDN网络的前向过程可表示为:
I S R = H R D N ( I L R ) . (5) I_{SR} = H_{RDN}(I_{LR}).\tag{5} ISR=HRDN(ILR).(5)其中 H R D N ( ⋅ ) H_{RDN}(\cdot) HRDN(⋅)是RDN网络算子,表示上述4个过程的串接总和。
3.2 Residual Dense Block
接下来我们从上往下分析RDB的结构,如下图所示:
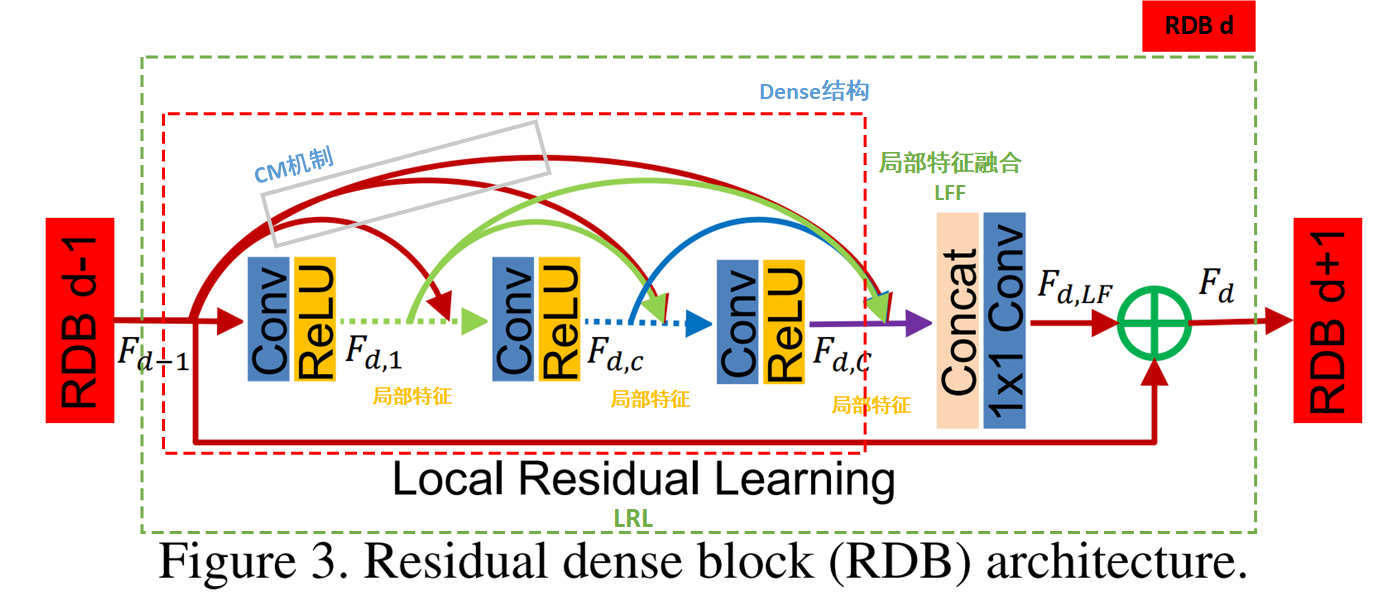
整个RDB块由CM机制、Dense结构、局部特征融合LFF以及局部残差学习LRL组成,接下来我们分别介绍这4个部分。
①CM机制
CM,相邻存储机制,指的是对于每个RDB块中每个Dense块的每一层 c ∈ { 1 , ⋯ , C } c\in \{1, \cdots, C\} c∈{
1,⋯,C}都会接受来自于上一个RDB块输出的局部特征。
②Dense结构
和SRDenseNet结构类似,我们在RDB中使用Dense结构: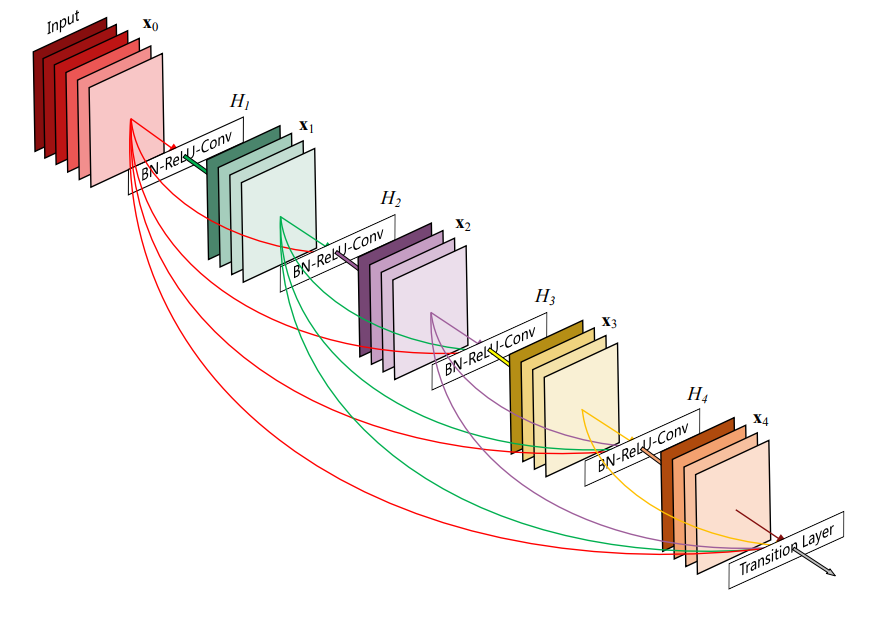
我们直接用表达式为(不了解Dense块的前向过程可阅读DenseNet的论文):
F d , c = σ ( W d , c [ F d − 1 , F d , 1 , ⋯ , F d , c − 1 ] ) . (6) F_{d,c} = \sigma(W_{d,c}[F_{d-1},F_{d,1},\cdots, F_{d,c-1}]).\tag{6} Fd,c=σ(Wd,c[Fd−1,Fd,1,⋯,Fd,c−1]).(6)其中 F d , c F_{d,c} Fd,c表示为第 c c c层输出的局部特征,其深度为 G G G,表示DenseNet中的Growth rate; W d , c W_{d,c} Wd,c表示第 d d d个RDB中第 c c c层的卷积层参数,这里省略bias; σ ( ⋅ ) \sigma(\cdot) σ(⋅)表示ReLU; [ F d − 1 , F d , 1 , ⋯ , F d , c − 1 ] [F_{d-1},F_{d,1},\cdots, F_{d,c-1}] [Fd−1,Fd,1,⋯,Fd,c−1]表示上一个RDB的输出 F d − 1 F_{d-1} Fd−1、前 c − 1 c-1 c−1层输出的局部特征通过concat堆叠而成,其深度为 G 0 + ( c − 1 ) G G_0+(c-1)G G0+(c−1)G。
Note:
- 和经典DenseNet块相比,在本文的Dense结构中去掉了BN层。一来是BN层的存储消耗和一层卷积层类似,我们大可以节省下这部分资源而用卷积层代替进一步提升模型复杂度;二来是在EDSR中文中提出了不同于识别等高级计算机任务,BN并不适用于超分任务。
- 每个RDB块的输出和输出feature map( F d F_d Fd)的深度都是 G 0 G_0 G0。
③局部特征融合
我们将上一个RDB的输出 F d − 1 F_{d-1} Fd−1、当前RDB中 C C C个层输出的所有局部特征进行concat融合,表达式为:
F d , L F = H L F F d ( [ F d − 1 , F d , 1 , ⋯ , F d , c , ⋯ , F d , C ] ) . (7) F_{d,LF} = H^d_{LFF}([F_{d-1}, F_{d,1}, \cdots, F_{d,c}, \cdots, F_{d,C}]).\tag{7} Fd,LF=HLFFd([Fd−1,Fd,1,⋯,Fd,c,⋯,Fd,C]).(7)其中算子 H L F F d ( ⋅ ) H^d_{LFF}(\cdot) HLFFd(⋅)表示在第 d d d个RDB中将所有层特征信息进行融合,并使用 1 × 1 1\times 1 1×1进行缩减输出feature map的通道,从而避免Dense结构导致网络过宽而让训练不稳定的问题,缩减后的输出 F d , L F F_{d,LF} Fd,LF的通道数为 G 0 + C ∗ G → G 0 G_0+C*G\to G_0 G0+C∗G→G0。
Note:
- LFF的存在允许让Dense结构的RDB拥有更大的增长率Growth rate!
④局部残差学习
作者指出在上述结构基础上再添加LRL结构可以进一步提升整体的表现力,因此LRL的引入也是有必要的,其数学表达式为:
F d = F d − 1 + F d , L F . (8) F_d = F_{d-1} + F_{d,LF}.\tag{8} Fd=Fd−1+Fd,LF.(8)
3.3 Dense Feature Fusion
当对所有RDBs输出的局部特征进行concat融合之后并使用全局残差学习GRL进一步将不同层级特征进行融合之后,就可以将输出的feature map进行上采样了。而上述这个过程就是Dense Feature Fusion(DFF)做的事情,它包括全局特征融合GFF和全局残差学习GRL两个部分。
①全局特征融合GFF
通过GFF将各个RDBs输出的局部特征信息进行concat融合,并使用 1 × 1 1\times 1 1×1卷积层进行通道缩减以及 3 × 3 3\times 3 3×3卷积层进一步提取高层特征信息,这一层也很重要,它提取之后的特征和来自低层的信息 F − 1 F_{-1} F−1进行残差融合会产生不错的性能提升,这在SRGAN结构中也得到了体现:
用数学表达式为:
F G F = H G F F ( [ F 1 , ⋯ , F D ] ) . (9) F_{GF} = H_{GFF}([F_1, \cdots, F_D]).\tag{9} FGF=HGFF([F1,⋯,FD]).(9)其中算子 H G F F ( ⋅ ) H_{GFF}(\cdot) HGFF(⋅)表示的就是上述过程。
②全局残差学习GRL
类似于RDBs中的LRL,GRL也是将低层特征信息和高层特征信息进行残差连接,具体表达式为:
F D F = F − 1 + F G F . (10) F_{DF} = F_{-1} + F_{GF}.\tag{10} FDF=F−1+FGF.(10)
最后的输出 F D F F_{DF} FDF就是我们下一个环节上采样的输入。
3.4 Implementation Details
- 除了 1 × 1 1\times 1 1×1的卷积层之外,其余所有卷积层都是用 3 × 3 3\times 3 3×3卷积核大小的滤波器。
- G 0 = 64 G_0=64 G0=64。
- 最后重建层输出通道数为3,当然也可是处理灰度图,即通道数为1。
4 Discussions
①Difference to DenseNet
- 一般来说,DenseNet广泛用于高级计算机视觉任务(如目标识别),而RDN是为图像SR这种简单任务设计的。因此去掉了批处理规范化(BN)层,减轻了GPU内存消耗,减小了计算复杂度,并提升了网络性能。
- 在DenseNe中,两个相邻Dense块之间使用过渡层。而在RDN中,密集连接层输出与局部特征融合输出(LFF)的结合方式是使用局部残差学习(LRL),这在实验中证明是非常有效的。
- 采用全局特征融合来充分利用DenseNet中忽略的层次特征。
②Difference to SRDenseNet
- 第一个是基本架构块的设计不同。本文的残差密集块(RDB)从三个方面做了改进:一、引入了相邻存储(CM)机制,它允许前面RDB的状态直接访问当前RDB的每一层。二、通过使用局部特征融合(LFF),RDB允许更大的增长率,从而能够更稳定地训练深度网络。三、局部残差学习(LRL)被用于RDB,以进一步优化信息流和梯度。
- 第二个不同是RDB之间没有紧密的连接。相反,RDB使用全局特征融合(GFF)和全局残差学习来提取全局特征,因为具有相邻内存的RDB已经完整的提取了局部特征。
- SRDenseNet使用L2损失函数。而RDN使用了L1损失函数,L1损失函数已被证实了对性能具有更强大的收敛性。
5 Experiments
实验部分可参考:超分算法RDN:Residual Dense Network for Image Super-Resolution 超分辨率图像重建
6 Conclusion
- 文章提出了一种具有非常深的SISR结构——
RDN。RDN通过结合ResNet和DenseNet的优势在 L R LR LR层级上最大化提取所有的特征信息。 - RDN基于
RDB以及全局残差学习(GRL),每个RDB块中包含了Dense结构,通过LFF来提取融合每一层局部信息之后的特征信息,并于LRL的另一端,即来自上个RDB块的局部特征信息进行残差结合输出当前RDB块最终的局部特征信息。GFF将所有来自RDBs的局部信息进行融合产生全局信息 F G F F_{GF} FGF,并于GRL另一端,即低层特征信息 F − 1 F_{-1} F−1进行残差结合输出最终的特征信息。 - RDN属于SISR方法,其结构主要包括低层特征提取、深层特征提取、上采样层、重建层。本文中上采样层采用亚像素卷积层,而深层特征提取GFF是RDN的重点。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150412.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
