大家好,又见面了,我是你们的朋友全栈君。
参考网址里已经对gmapping包用到的理论做了总结。我这里写一下自己的理解和gmapping的程序执行流程。
gmapping包涉及到两个文件夹。

可以分别在下面两个网址下载:
https://github.com/OpenSLAM-org/openslam_gmapping
https://github.com/ros-perception/slam_gmapping
openslam_gmapping是openslam发布的gmapping库,slam_gmapping是gmapping库的ROS封装,其调用了gmapping库里的算法。gmapping库里的文件很多,但用到的就几个文件。
slam_gmapping文件夹
slam_gmapping文件夹中的main.cpp文件中定义了SlamGMapping类的一个变量并执行了startLiveSlam函数。
slam_gmapping.cpp中有几个非常重要的函数。
1)main.cpp中执行的构造函数是SlamGMapping类的无参数传入的构造函数,主要是读取参数文件的参数。
2)startLiveSlam函数订阅和发布了一些话题。
3)publishLoop函数周期性发布发布map->odom的转换关系。
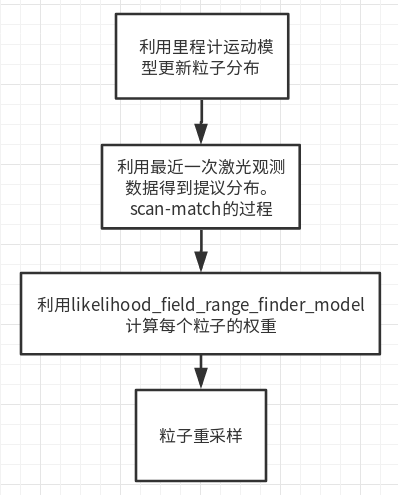
4)laserCallback函数是调用gmapping算法的主要函数。下图显示了该函数的执行流程。

5)updateMap函数里会获取权重最大的粒子,然后遍历该粒子的整个运动轨迹,并用轨迹上的各个点携带的激光数据生成地图。因为下次选中的粒子可能不是原来的,所以这里每次都会找到权重最大的粒子然后重新生成地图,发布出去。
openslam_gmapping文件夹
gmapping算法的主要处理函数就是gridslamprocessor.cpp中的processScan函数。slam_gmapping文件夹中的执行函数主要就是将ros格式的数据打包成gmapping算法所需的数据格式,然后传入processScan函数。下图是该函数的执行流程:
1)调用drawFromMotion函数更新每个粒子的位置分布。该函数里面对x,y,theta各个状态量维度都加了高斯噪声。论文中描述的算法好像没有说加高斯噪声。
//write the state of the reading and update all the particles using the motion model
for (ParticleVector::iterator it=m_particles.begin(); it!=m_particles.end(); it++){
OrientedPoint& pose(it->pose);
pose=m_motionModel.drawFromMotion(it->pose, relPose, m_odoPose);
}
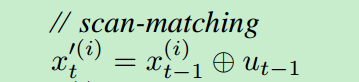
图片截取自论文第6页的伪算法流程
2)scanMatch函数的定义在gridslamprocessor.hxx文件中。它调用optimize函数执行爬山算法搜寻局部最优位姿。然后将最优位置替换掉原来的位姿。但论文中还多执行了一步操作。论文中在最优位置附近再搜寻K个位置,计算其权重,然后加权平均得到最终的均值位姿和协方差。从而用高斯分布来近似目标分布。
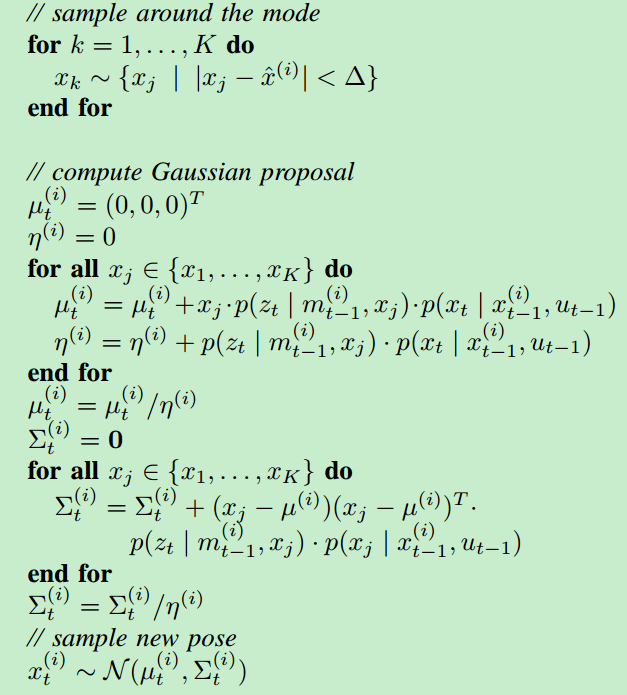
得到均值位姿后再进行一次权重计算。调用updateTreeWeights(false);进行权重归一化,并计算出 N e f f N_{\mathrm{eff}} Neff。
3)执行重采样操作。
resample(plainReading, adaptParticles);
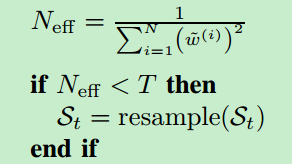
resample函数中会将 N e f f N_{\mathrm{eff}} Neff与阈值进行比较来决定是否进行重采样。 N e f f N_{\mathrm{eff}} Neff越大说明粒子越收敛,越小说明越分散。
如果进行重采样则执行下面的函数获取采样后的粒子下标。
该函数采样转轮算法输出选中的粒子下标。没有被选中的粒子会被删除,其携带的轨迹信息和地图都会被删掉。从这里就可以看出频繁重采样对粒子多样性的影响。因为好的粒子也有概率被删掉。而粒子会慢慢趋于一致。
//采取重采样方法决定,哪些粒子会保留 保留的粒子会返回下标.里面的下标可能会重复,因为有些粒子会重复采样
//而另外的一些粒子会消失掉
uniform_resampler<double, double> resampler;
m_indexes=resampler.resampleIndexes(m_weights, adaptSize);//因为adaptSize传入的是0,输出的粒子数目保持和原来一样,只是有些粒子是一样的。
//m_indexes中粒子下标的顺序是从小到大的。
保留下来的粒子会新增一个节点,保存当前粒子位姿和相应的激光数据帧。然后更新粒子携带的地图信息。
如果不重采样则对每个粒子都新增一个节点。将当前粒子位姿和对应的激光数据帧保存到节点里。然后更新所有粒子的地图信息。
粒子是如何保存轨迹信息和地图的,这里需要说明一下。
先看一下粒子的结构体Particle。其结构体声明在gridslamprocessor.h文件中
/**This class defines a particle of the filter. Each particle has a map, a pose, a weight and retains the current node in the trajectory tree*/
struct Particle{
/**constructs a particle, given a map @param map: the particle map */
Particle(const ScanMatcherMap& map);
/** @returns the weight of a particle */
inline operator double() const {
return weight;}
/** @returns the pose of a particle */
inline operator OrientedPoint() const {
return pose;}
/** sets the weight of a particle @param w the weight */
inline void setWeight(double w) {
weight=w;}
/** The map */
ScanMatcherMap map;
/** The pose of the robot */
OrientedPoint pose;
/** The pose of the robot at the previous time frame (used for computing thr odometry displacements) */
OrientedPoint previousPose;
/** The weight of the particle */
double weight;
/** The cumulative weight of the particle */
double weightSum;
double gweight;
/** The index of the previous particle in the trajectory tree */
int previousIndex;
/** Entry to the trajectory tree */
TNode* node; //指向最近一个轨迹节点
};
每个粒子都会有一个指向最近一个轨迹节点的指针node。通过该指针就可以遍历该粒子所有位姿点和对应的激光数据帧。
节点的数据结构如下:
struct TNode{
/**Constructs a node of the trajectory tree. @param pose: the pose of the robot in the trajectory @param weight: the weight of the particle at that point in the trajectory @param accWeight: the cumulative weight of the particle @param parent: the parent node in the tree @param childs: the number of childs */
TNode(const OrientedPoint& pose, double weight, TNode* parent=0, unsigned int childs=0);
/**Destroys a tree node, and consistently updates the tree. If a node whose parent has only one child is deleted, also the parent node is deleted. This because the parent will not be reacheable anymore in the trajectory tree.*/
~TNode();
/**The pose of the robot*/
OrientedPoint pose;
/**The weight of the particle*/
double weight;
/**The sum of all the particle weights in the previous part of the trajectory*/
double accWeight;
double gweight;
/**The parent*/
TNode* parent;
/**The range reading to which this node is associated*/
const RangeReading* reading;
/**The number of childs*/
unsigned int childs;
/**counter in visiting the node (internally used)*/
mutable unsigned int visitCounter;
/**visit flag (internally used)*/
mutable bool flag;
};
gmapping中用树来存储粒子的整个轨迹。每一个节点就是轨迹中的一点。该节点存储了机器人的位姿,该节点粒子的权重,所有父节点粒子权重之和,该节点激光数据帧,指向父节点的指针和子节点的数量。Fastslam为了解决fullslam问题,它保存了机器人的整条轨迹。
在最后生成地图时会先取出累积权重(轨迹上各个节点的权重之和)最大的粒子,然后遍历其轨迹中的每一个位姿点。利用每个位姿点对应的激光数据帧绘制地图。然后处理成便于rviz显示的样子发布出去。
参考网址:
GMapping漫谈
GMapping原理分析
简单傻x的图解–gmapping
Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters
关注公众号《首飞》回复“机器人”获取精心推荐的C/C++,Python,Docker,Qt,ROS1/2,机器人学等机器人行业常用技术资料。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150352.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
