大家好,又见面了,我是你们的朋友全栈君。
Simulation-Based Search
基于仿真的搜索包含两点:一个是simulation,其次是search。simulation是基于强化学习model进行采样,得到样本数据。但这不是基于和环境交互获得的真实数据。search则是为了利用样本结果来帮我们计算应该采用什么动作,以实现长期利益最大化
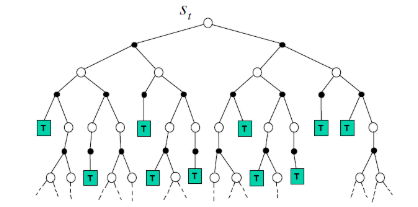
要理解什么是Simulation-Based Search,首先要明白什么是forward search,forward search从当前考虑的一个节点(状态) S t S_t St开始,然后对其所有可能的action进行扩展,建立一棵以 S t S_t St为根节点的搜索树,这棵树是一个MDP(马尔科夫决策过程),求解这个MDP,然后得到 S t S_t St状态最应该采用的动作 A t A_t At。如下图所示

MC Search
Simulation-based Search的一种简单方法是:简单MC Search。它基于一个模型 M v M_v Mv和策略 π \pi π,针对当前状态 S t S_t St,对每一个可能采样的动作KaTeX parse error: Undefined control sequence: \inA at position 2: a\̲i̲n̲A̲,都进行K轮采样,这样每个动作 a a a都会得到K组完整的episode。即:
{ S t , a , R t + 1 k , S t + 1 k , A t + 1 k , . . . S T k } k = 1 K − M v , π \{S_t,a,R_{t+1}^k,S_{t+1}^k,A_{t+1}^k,…S_T^k\}_{k=1}^K -M_v,\pi {
St,a,Rt+1k,St+1k,At+1k,...STk}k=1K−Mv,π
对于每个 ( S t , a ) (S_t,a) (St,a),使用MC算法算法先算出每一个episode的 G t G_t Gt,然后得到每个 ( S t , a ) (S_t,a) (St,a),算出动作价值函数和选择最优动作
Q ( S t , a ) = 1 K ∑ k = 1 K G t Q(S_t,a)=\frac{1}{K}\sum_{k=1}^{K}G_t Q(St,a)=K1k=1∑KGt
a t = a r g max a ∈ A Q ( S t , a ) a_t=arg\max_{a\in A}Q(S_t,a) at=arga∈AmaxQ(St,a)
如果我们的 ( S , A ) (S,A) (S,A)数量达到非常大的量级,比如围棋的级别,那么简单MC Search算法就太慢了。
MCTS
MCTS放弃了简单MC Search中的对当前状态 S t S_t St都要进行K次模拟采样的做法,而是总共对当前状态 S t S_t St进行K次采样,这样采样的动作可能就是全集 A A A中的一部分,这样可以大大降低计算量,但是会造成可能错失很多动作的选择,而这些动作或许会更好。
在MCTS中,当前状态 S t S_t St对应的状态序列(episode)是这样的:
{ S t , A t k , R t + 1 k , S t + 1 k , A t + 1 k , . . . S T k } k = 1 K − M v , π \{S_t,A_t^k,R_{t+1}^k,S_{t+1}^k,A_{t+1}^k,…S_T^k\}_{k=1}^K – M_v,\pi {
St,Atk,Rt+1k,St+1k,At+1k,...STk}k=1K−Mv,π
采样完成后,可以基于采样结果构建MCTS搜索树,然后计算 Q ( s t , a ) Q(s_t,a) Q(st,a)和最大 Q ( s t , a ) Q(s_t,a) Q(st,a)对应的动作。
Q ( S t , a ) = 1 N ( S t , a ) ∑ k = 1 K ∑ u = t T 1 ( S u k = S t , A u k = a ) G u Q(S_t,a)=\frac{1}{N(S_t,a)}\sum_{k=1}^{K}\sum_{u=t}^{T}1(S_{uk}=S_t,A_{uk}=a)G_u Q(St,a)=N(St,a)1k=1∑Ku=t∑T1(Suk=St,Auk=a)Gu
a t = a r g max a ∈ A Q ( S t , a ) a_t=arg\max_{a\in A}Q(S_t,a) at=arga∈AmaxQ(St,a)
MCTS搜索的策略分为两个阶段:第一个是Tree policy,即采样得到的状态还在搜索树时采用的策略,可以使用 ϵ \epsilon ϵ-greedy,或者是上线置信区间(UCT),第二个阶段是,如果当前状态已经不在MCTS内了,使用默认策略(default policy)来完成采样。
上线置信区间算法UCT
上线置信区间算法(UpperConfidence Bound Applied to Trees,UCT)在棋类问题中比 ϵ \epsilon ϵ-greedy更常用。比如在某个状态下游两个可选动作,第一个动作在历史上是0胜1败,第二个动作是8胜10负,如果是 ϵ \epsilon ϵ-greedy算法,则第二个动作非常容易被选择到,但是可能只是因为第一个动作的历史棋局比较少导致的,实际上它才是更好的。所以UCT是个不错的解决方法。
UCT的公式如下:
s c o r e = w i n i + c l n N i n i score=\frac{w_i}{n_i}+c\sqrt{\frac{lnN_i}{n_i}} score=niwi+cnilnNi
其中 w i w_i wi是 i i i节点的胜利次数, n i n_i ni是 i i i的模拟次数, N i N_i Ni是所有模拟次数, c c c是探索常数,理论值为 2 \sqrt{2} 2。
比如对于下面的棋局,对于根节点来说,有3个选择,第一个选择7胜3负,第二个选择5胜3负,第三个选择0胜3负。

如果 c = 10 c=10 c=10,则第一个节点的分数为:
s c o r e ( 7 , 10 ) = 7 / 10 + C ∗ l o g ( 21 ) 10 ≈ 6.2 score(7,10)=7/10+C*\sqrt{\frac{log(21)}{10}}\approx6.2 score(7,10)=7/10+C∗10log(21)≈6.2
第二个节点的分数为:
s c o r e ( 5 , 8 ) = 5 / 8 + C ∗ l o g ( 21 ) 8 ≈ 6.8 score(5,8)=5/8+C*\sqrt{\frac{log(21)}{8}}\approx6.8 score(5,8)=5/8+C∗8log(21)≈6.8
第三个节点的分数为:
s c o r e ( 0 , 3 ) = 0 / 3 + C ∗ l o g ( 21 ) 3 ≈ 10 score(0,3)=0/3+C*\sqrt{\frac{log(21)}{3}}\approx10 score(0,3)=0/3+C∗3log(21)≈10
棋类游戏MCTS搜索
在像围棋这样的零和问题中,一个动作只有在棋局结束才能拿到真正的奖励,因此我们对MCTS的搜索步骤和树结构上需要根据问题的不同做一些细化。
对于MCTS的树结构,如果是最简单的方法,只需要在节点上保存状态对应的历史胜负记录。
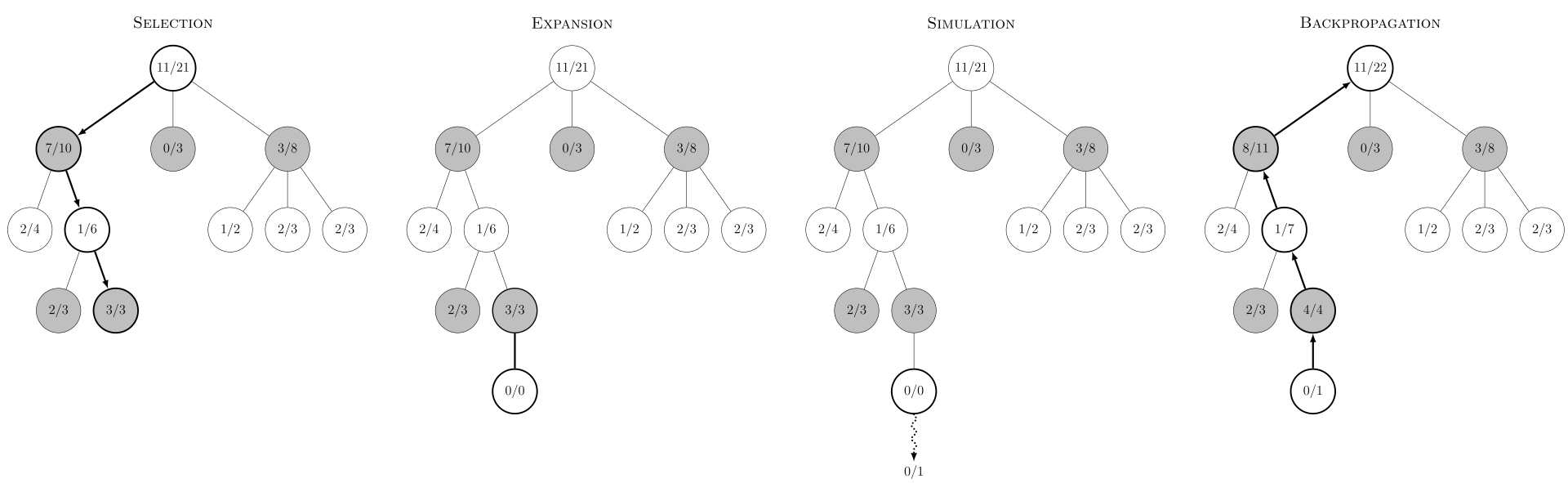
(1)选择(Selection):这一步会从根节点开始,每次都选一个最值得搜索的子节点,一般使用UCT方法选择。直到来到一个可能有后继子节点,但是还没有被扩展的节点,如上图的3/3。之所以说有后继子节点,是因为该状态下还有未走过的着棋法,也就是MCTS中没有后续的动作可以在搜索树中找到了。这是进入(2)。
(2)扩展(Expansion):对于那个还没被扩展的子节点,加上一个0/0的子节点,表示没有历史记录参考,这时我们进入(3)。
(3)仿真(Simulation):从那个新的着棋法开始,用一个简单策略(Rollout policy)走到底,得到一个胜负结果。这里之所以选择一种比较快的走子法是因为如果策略走得慢,虽然会更准确,但由于耗时多,模拟次数就变少。所以不一定“棋力”更强,有可能会更弱。
(4)回溯(Backpropagation):将我们最后得到的胜负结果回溯加到MCTS树结构上。注意除了之前的MCTS树要回溯外,新加入的节点也要加上一次胜负历史记录,如上图最右边所示。
MCTS的简单实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import math
import random
import numpy as np
AVAILABLE_CHOICES = [1, -1, 2, -2]
AVAILABLE_CHOICE_NUMBER = len(AVAILABLE_CHOICES)
MAX_ROUND_NUMBER = 10
class State(object):
""" 蒙特卡罗树搜索的游戏状态,记录在某一个Node节点下的状态数据,包含当前的游戏得分、当前的游戏round数、从开始到当前的执行记录。 需要实现判断当前状态是否达到游戏结束状态,支持从Action集合中随机取出操作。 """
def __init__(self):
self.current_value = 0.0
# For the first root node, the index is 0 and the game should start from 1
self.current_round_index = 0
self.cumulative_choices = []
def get_current_value(self):
return self.current_value
def set_current_value(self, value):
self.current_value = value
def get_current_round_index(self):
return self.current_round_index
def set_current_round_index(self, turn):
self.current_round_index = turn
def get_cumulative_choices(self):
return self.cumulative_choices
def set_cumulative_choices(self, choices):
self.cumulative_choices = choices
def is_terminal(self):
# The round index starts from 1 to max round number
return self.current_round_index == MAX_ROUND_NUMBER
def compute_reward(self):
return -abs(1 - self.current_value)
def get_next_state_with_random_choice(self):
random_choice = random.choice([choice for choice in AVAILABLE_CHOICES])
next_state = State()
next_state.set_current_value(self.current_value + random_choice)
next_state.set_current_round_index(self.current_round_index + 1)
next_state.set_cumulative_choices(self.cumulative_choices +[random_choice])
return next_state
def __repr__(self):
return "State: {}, value: {}, round: {}, choices: {}".format(
hash(self), self.current_value, self.current_round_index,
self.cumulative_choices)
class Node(object):
""" 蒙特卡罗树搜索的树结构的Node,包含了父节点和直接点等信息,还有用于计算UCB的遍历次数和quality值,还有游戏选择这个Node的State。 """
def __init__(self):
self.parent = None
self.children = []
self.visit_times = 0
self.quality_value = 0.0
self.state = None
def set_state(self, state):
self.state = state
def get_state(self):
return self.state
def get_parent(self):
return self.parent
def set_parent(self, parent):
self.parent = parent
def get_children(self):
return self.children
def get_visit_times(self):
return self.visit_times
def set_visit_times(self, times):
self.visit_times = times
def visit_times_add_one(self):
self.visit_times += 1
def get_quality_value(self):
return self.quality_value
def set_quality_value(self, value):
self.quality_value = value
def quality_value_add_n(self, n):
self.quality_value += n
def is_all_expand(self):
return len(self.children) == AVAILABLE_CHOICE_NUMBER
def add_child(self, sub_node):
sub_node.set_parent(self)
self.children.append(sub_node)
def __repr__(self):
return "Node: {}, Q/N: {}/{}, state: {}".format(
hash(self), self.quality_value, self.visit_times, self.state)
def tree_policy(node):
""" 蒙特卡罗树搜索的Selection和Expansion阶段,传入当前需要开始搜索的节点(例如根节点),根据exploration/exploitation算法返回最好的需要expend的节点,注意如果节点是叶子结点直接返回。 基本策略是先找当前未选择过的子节点,如果有多个则随机选。如果都选择过就找权衡过exploration/exploitation的UCB值最大的,如果UCB值相等则随机选。 """
# Check if the current node is the leaf node
while node.get_state().is_terminal() == False:
if node.is_all_expand():
node = best_child(node, True)
else:
# Return the new sub node
sub_node = expand(node)
return sub_node
# Return the leaf node
return node
def default_policy(node):
""" 蒙特卡罗树搜索的Simulation阶段,输入一个需要expand的节点,随机操作后创建新的节点,返回新增节点的reward。注意输入的节点应该不是子节点,而且是有未执行的Action可以expend的。 基本策略是随机选择Action。 """
# Get the state of the game
current_state = node.get_state()
# Run until the game over
while current_state.is_terminal() == False:
# Pick one random action to play and get next state
current_state = current_state.get_next_state_with_random_choice()
final_state_reward = current_state.compute_reward()
return final_state_reward
def expand(node):
""" 输入一个节点,在该节点上拓展一个新的节点,使用random方法执行Action,返回新增的节点。注意,需要保证新增的节点与其他节点Action不同。 """
tried_sub_node_states = [
sub_node.get_state() for sub_node in node.get_children()
]
new_state = node.get_state().get_next_state_with_random_choice()
# Check until get the new state which has the different action from others
while new_state in tried_sub_node_states:
new_state = node.get_state().get_next_state_with_random_choice()
sub_node = Node()
sub_node.set_state(new_state)
node.add_child(sub_node)
return sub_node
def best_child(node, is_exploration):
""" 使用UCB算法,权衡exploration和exploitation后选择得分最高的子节点,注意如果是预测阶段直接选择当前Q值得分最高的。 """
# TODO: Use the min float value
best_score = -sys.maxsize
best_sub_node = None
# Travel all sub nodes to find the best one
for sub_node in node.get_children():
# Ignore exploration for inference
if is_exploration:
C = 1 / math.sqrt(2.0)
else:
C = 0.0
# UCB = quality / times + C * sqrt(2 * ln(total_times) / times)
left = sub_node.get_quality_value() / sub_node.get_visit_times()
right = 2.0 * math.log(node.get_visit_times()) / sub_node.get_visit_times()
score = left + C * math.sqrt(right)
if score > best_score:
best_sub_node = sub_node
best_score = score
return best_sub_node
def backup(node, reward):
""" 蒙特卡洛树搜索的Backpropagation阶段,输入前面获取需要expend的节点和新执行Action的reward,反馈给expend节点和上游所有节点并更新对应数据。 """
# Update util the root node
while node != None:
# Update the visit times
node.visit_times_add_one()
# Update the quality value
node.quality_value_add_n(reward)
# Change the node to the parent node
node = node.parent
def monte_carlo_tree_search(node):
""" 实现蒙特卡洛树搜索算法,传入一个根节点,在有限的时间内根据之前已经探索过的树结构expand新节点和更新数据,然后返回只要exploitation最高的子节点。 蒙特卡洛树搜索包含四个步骤,Selection、Expansion、Simulation、Backpropagation。 前两步使用tree policy找到值得探索的节点。 第三步使用default policy也就是在选中的节点上随机算法选一个子节点并计算reward。 最后一步使用backup也就是把reward更新到所有经过的选中节点的节点上。 进行预测时,只需要根据Q值选择exploitation最大的节点即可,找到下一个最优的节点。 """
computation_budget = 2
# Run as much as possible under the computation budget
for i in range(computation_budget):
# 1. Find the best node to expand
expand_node = tree_policy(node)
# 2. Random run to add node and get reward
reward = default_policy(expand_node)
# 3. Update all passing nodes with reward
backup(expand_node, reward)
# N. Get the best next node
best_next_node = best_child(node, False)
return best_next_node
def main():
# Create the initialized state and initialized node
init_state = State()
init_node = Node()
init_node.set_state(init_state)
current_node = init_node
# Set the rounds to play
for i in range(10):
print("Play round: {}".format(i + 1))
current_node = monte_carlo_tree_search(current_node)
print("Choose node: {}".format(current_node))
if __name__ == "__main__":
main()
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150284.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
