大家好,又见面了,我是你们的朋友全栈君。
深入解析HashMap和ConcurrentHashMapy源码以及底层原理
前言
HashMap 和ConcurrentHashMap,这两个相信大家都不陌生,在面试中基本上是必问的,以及在实际开发过程中也是比用的,那么看了这篇文章,无论在面试还是在实际开发中都可以顺手拈来,得心应手了。
HashMap
基于Map接口实现,元素以键值对的方式存储,并且允许使用null 建和null 值, 因为key不允许重复,因此只能有一个键为null,另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。HashMap是线程不安全的。
下面来细说下jdk1.7和1.8的实现
JDK1.7版本
数据结构图
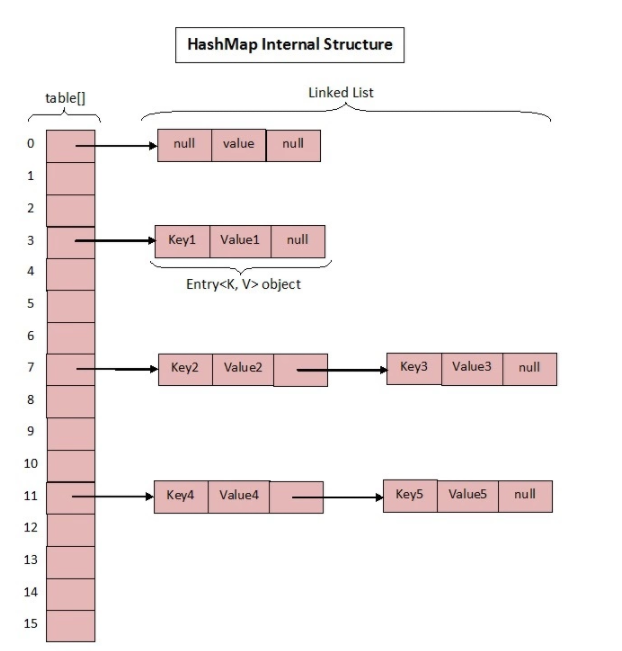

底层原理
HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
比较核心的成员变量
//初始化桶大小,因为底层是数组,所以这是数组默认的大小 16。
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//桶最大值
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的负载因子(0.75)
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//table 真正存放数据的数组
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
//Map 存放数量的大小
transient int size;
// (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
int threshold;
//负载因子,可在初始化时显式指定。
final float loadFactor;
//记录HashMap的修改次数
transient int modCount;
负载因子
在初始化的时候给定的默认的容量是16,负载因子是0.75,如下代码是初始化过程
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。所依建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
为什么负载因子设置的是0.75?
如果设置成1。空间利用更充分,但是这样会发生大量的hash碰撞。有些位置的链表会很长,就不利于查询。省空间而费时间。
如果设置成0.5,hash碰撞的几率小了很多,但是会频繁扩容,费空间而省时间。
/* <p>As a general rule, the default load factor (.75) offers a good * tradeoff between time and space costs. Higher values decrease the * space overhead but increase the lookup cost (reflected in most of * the operations of the <tt>HashMap</tt> class, including * <tt>get</tt> and <tt>put</tt>). The expected number of entries in * the map and its load factor should be taken into account when * setting its initial capacity, so as to minimize the number of * rehash operations. If the initial capacity is greater than the * maximum number of entries divided by the load factor, no rehash * operations will ever occur.*/
看这段源码大致的意思是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
modCount
用于记录HashMap的修改次数, 在HashMap的put(),remove(),Interator()等方法中,使用了该属性
由于HashMap不是线程安全的,所以在迭代的时候,会将modCount赋值到迭代器的expectedModCount属性中,然后进行迭代, 如果在迭代的过程中HashMap被其他线程修改了,modCount的数值就会发生变化, 这个时候expectedModCount和ModCount不相等, 迭代器就会抛出ConcurrentModificationException()异常
具体代码
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
真正存放数据的数组
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
对于Entry我们来看源码
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
...
}
key写入时的key
value写入时的value
next用于实现链表结构
hash 存放的是当前 key 的 hashcode
存储机制
put方法
public V put(K key, V value) {
//判断当前数组是否需要初始化
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//key 为空,则 put 一个空值进去
if (key == null)
return putForNullKey(value);
//key 计算出 hashcode
int hash = hash(key);
//计算出的 hashcode 定位出所在桶
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆 //盖,并返回原来的值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。
addEntry(hash, key, value, i);
return null;
}
addEntry(hash, key, value, i)
void addEntry(int hash, K key, V value, int bucketIndex) {
//判断是否需要扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
//进行两倍扩充,并将当前的 key 重新 hash 并定位
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//新建一個entry
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
get 方法
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//根据 key 计算出 hashcode,然后定位到具体的桶中
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//不是链表就根据 key、key 的 hashcode 是否相等来返回值
//链表则需要遍历直到 key 及 hashcode 相等时候就返回值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
JDK1.8版本
对于1.7版本的hashmap,Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 O(N)。
数据结构图
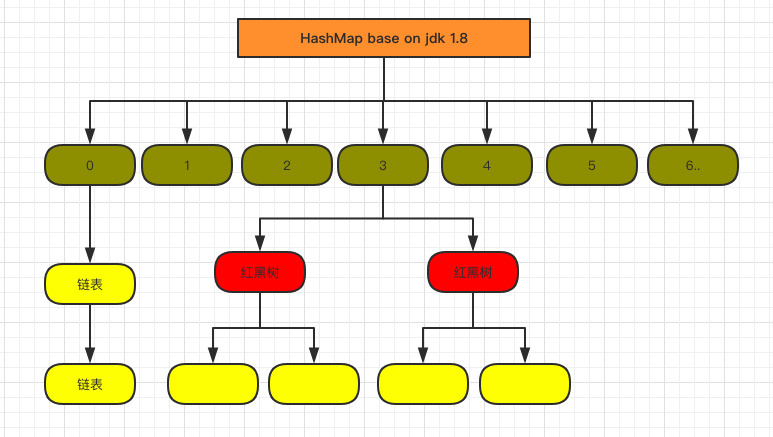
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VW9UgQdt-1589040683846)(E:\技术帖子\笔记\基础\图\hashmap\hashmap1.8.png)]
底层原理
HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。查询效率直接提高到了 O(logn)。
比较核心的成员变量
public class HashMap<k,v> extends AbstractMap<k,v> implements Map<k,v>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f;//填充比
//当add一个元素到某个位桶,其链表长度达到8时将链表转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
transient Node<k,v>[] table;//存储元素的数组
transient Set<map.entry<k,v>> entrySet;
transient int size;//存放元素的个数
transient int modCount;//被修改的次数fast-fail机制
int threshold;//临界值 当实际大小(容量*填充比)超过临界值时,会进行扩容
final float loadFactor;//填充比(......后面略)
node 的方法和1.7的entery的结构一样
TreeNode
//红黑树
static final class TreeNode<k,v> extends LinkedHashMap.Entry<k,v> {
TreeNode<k,v> parent; // 父节点
TreeNode<k,v> left; //左子树
TreeNode<k,v> right;//右子树
TreeNode<k,v> prev; // needed to unlink next upon deletion
boolean red; //颜色属性
TreeNode(int hash, K key, V val, Node<k,v> next) {
super(hash, key, val, next);
}
//返回当前节点的根节点
final TreeNode<k,v> root() {
for (TreeNode<k,v> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
存取机制
put 方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {//表示示有冲突,开始处理冲突
Node<K,V> e; K k;
//如果当前桶有值( Hash 冲突),那么就要比较当前桶中的 key、key 的 hashcode 与写入的 key 是否相等,相等就赋值给 e,检查第一个Node,p是不是要找的值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//如果当前桶为红黑树,那就要按照红黑树的方式写入数据
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果冲突的节点数已经达到8个,看是否需要改变冲突节点的存储结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//在遍历过程中找到 key 相同时直接退出遍历
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果 e != null 就相当于存在相同的 key,那就需要将值覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断是否需要进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
resize()
扩容机制,构造hash表时,如果不指明初始大小,默认大小为16(即Node数组大小16),如果Node[]数组中的元素达到(填充比*Node.length)重新调整HashMap大小 变为原来2倍大小,扩容很耗时
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
/*如果旧表的长度不是空*/
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*把新表的长度设置为旧表长度的两倍,newCap=2*oldCap*/
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
/*把新表的门限设置为旧表门限的两倍,newThr=oldThr*2*/
newThr = oldThr << 1; // double threshold
}
/*如果旧表的长度的是0,就是说第一次初始化表*/
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;//新表长度乘以加载因子
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
/*下面开始构造新表,初始化表中的数据*/
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;//把新表赋值给table
if (oldTab != null) {//原表不是空要把原表中数据移动到新表中
/*遍历原来的旧表*/
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)//说明这个node没有链表直接放在新表的e.hash & (newCap - 1)位置
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
/*如果e后边有链表,到这里表示e后面带着个单链表,需要遍历单链表,将每个结点重*/
else { // preserve order保证顺序
新计算在新表的位置,并进行搬运
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;//记录下一个结点
//新表是旧表的两倍容量,实例上就把单链表拆分为两队,
//e.hash&oldCap为偶数一队,e.hash&oldCap为奇数一对
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {//lo队不为null,放在新表原位置
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {//hi队不为null,放在新表j+oldCap位置
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
treeifyBin(tab, hash)
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//判断当前hashMap的长度,如果不足64,只进行resize(),扩容table
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//如果达到64,那么将冲突的存储结构为红黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
put过程梳理:
1,判断键值对数组tab[]是否为空或为null,否则以默认大小resize();
2,根据键值key计算hash值得到插入的数组索引i,如果tab[i]==null,直接新建节点添加,否则转入3
3,判断当前数组中处理hash冲突的方式为链表还是红黑树(check第一个节点类型即可),分别处理
get 方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//将 key hash 之后取得所定位的桶,如果桶为空则直接返回 null
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果第一个不匹配,则判断它的下一个是红黑树还是链表
if ((e = first.next) != null) {
//红黑树就按照树的查找方式返回值
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//按照链表的方式遍历匹配返回值
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
存在问题
在并发情况下会出现死循环,代码如下
final HashMap<String, String> map = new HashMap<String, String>();
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}).start();
}
在扩容的时候会调用 resize() 方法,就是这里的并发操作容易在一个桶上形成环形链表;这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标就会出现死循环。
ConcurrentHashMap
在包java.util.concurrent下,和HashMap不同的是专门处理并发问题
jdk1.7版本
数据结构图
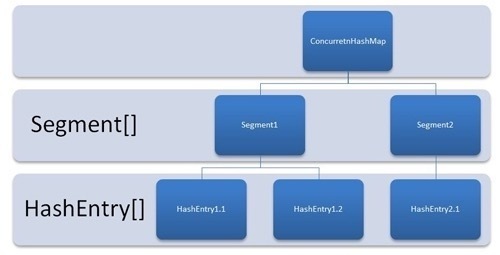
如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。
底层原理
ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
核心的成员变量
/**
* Segment 数组,存放数据时首先需要定位到具体的 Segment 中。
*/
final Segment<K,V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
segments
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
HashEntry
value 和next都保持着线程可见性
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
}
存取机制
put 方法
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
//通过key定位到segment
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
s.put(key, hash, value, false)
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
//遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
//为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//解除在 scanAndLockForPut(key, hash, value) 中所获取当前 Segment 的锁
unlock();
}
return oldValue;
}
虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。用的是scanAndLockForPut(key, hash, value) 自旋锁获取
scanAndLockForPut(key, hash, value)
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
//自旋获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
//如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
MAX_SCAN_RETRIES
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
get 方法
将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上,整个过程不需要加锁,
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
jdk1.8版本
在1.7基础上解决查询遍历链表效率太低问题
数据结构图
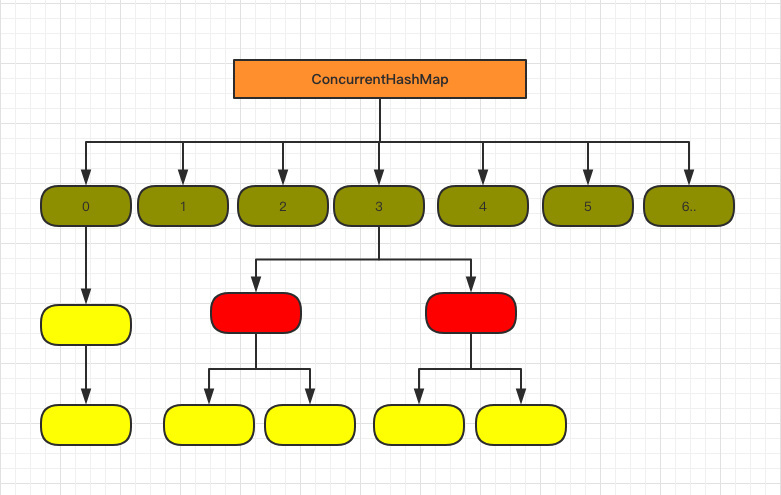
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GpSNZWsS-1589040683854)(E:\技术帖子\笔记\基础\图\hashmap\ConcurrentHashMap1.8.png)]
底层原理
和1.8的hashMap比较去除了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
而且将HashEntry 改成Node,功能上是一样的
Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
...
}
存储机制
put 方法
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//根据key计算出hashcode
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//判断是否进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//当前位置的 hashcode == MOVED == -1,则需要进行扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//都不满足,则利用 synchronized 锁写入数据
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//数量大于 TREEIFY_THRESHOLD 则要转换为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
get 方法
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//计算出hashcode
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//如果就在桶上那么直接返回值。
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
//红黑树那就按照树的方式获取值
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
//按照链表的方式遍历获取值
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
如果大家对java架构相关感兴趣,可以关注下面公众号,会持续更新java基础面试题, netty, spring boot,spring cloud等系列文章,一系列干货随时送达, 超神之路从此展开, BTAJ不再是梦想!

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150264.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
