大家好,又见面了,我是你们的朋友全栈君。
类别不平衡问题
类别不平衡问题,顾名思义,即数据集中存在某一类样本,其数量远多于或远少于其他类样本,从而导致一些机器学习模型失效的问题。例如逻辑回归即不适合处理类别不平衡问题,例如逻辑回归在欺诈检测问题中,因为绝大多数样本都为正常样本,欺诈样本很少,逻辑回归算法会倾向于把大多数样本判定为正常样本,这样能达到很高的准确率,但是达不到很高的召回率。
类别不平衡问题在很多场景中存在,例如欺诈检测,风控识别,在这些样本中,黑样本(一般为存在问题的样本)的数量一般远少于白样本(正常样本)。
上采样(过采样)和下采样(负采样)策略是解决类别不平衡问题的基本方法之一。上采样即增加少数类样本的数量,下采样即减少多数类样本以获取相对平衡的数据集。
最简单的上采样方法可以直接将少数类样本复制几份后添加到样本集中,最简单的下采样则可以直接只取一定百分比的多数类样本作为训练集。
SMOTE算法详解
SMOTE全称是Synthetic Minority Oversampling Technique即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
SMOTE 算法是利用特征空间中现存少数类样本之间的相似性来建立人工数据的,也可以认为SMOTE算法假设了在相距较近的少数类样本之间的样本仍然是少数类,
具体过程如下:
随机选择一个少数类样本,计算它到少数类样本集中所有样本的距离,得到它k近邻。
根据样本不平衡比例设置一个采样比例以确定采样倍率n,对于每一个少数类样本x,从其k近邻中随机选择若干个样本
对于每一个随机选出的近邻,选择一个在[0,1]之间的随机数乘以随机近邻和x的特征向量的差,然后加上一个x,
用公式表示:
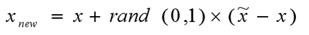

SMOTE算法摒弃了随机过采样复制样本的做法,可以防止随机过采样易过拟合的问题,而这些多出来的样本本身不带有信息,而且SMOTE 算法对于每个原少数类样本产生相同数量的合成数据样本,这就使得类间发生重复的可能性加大。
SMOTE算法调用
SMOTE算法是用的比较多的一种上采样算法,SMOTE算法的原理并不是太复杂,用python从头实现也只有几十行代码,但是python的imblearn包提供了更方便的接口,在需要快速实现代码的时候可直接调用imblearn。
imblearn类别不平衡包提供了上采样和下采样策略中的多种接口,基本调用方式一致,主要介绍一下对应的SMOTE方法和下采样中的RandomUnderSampler方法。imblearn可使用pip install imblearn直接安装。
代码示例
生成类别不平衡数据
#使用sklearn的make_classification生成不平衡数据样本
from sklearn.datasets import make_classification
#生成一组0和1比例为9比1的样本,X为特征,y为对应的标签
X, y = make_classification(n_classes=2, class_sep=2,
weights=[0.9, 0.1], n_informative=3,
n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=1000, random_state=10)
查看数据分布
from collections import Counter
#查看所生成的样本类别分布,0和1样本比例9比1,属于类别不平衡数据
print(Counter(y))
#Counter({0: 900, 1: 100})
SMOTE算法核心语句
#使用imlbearn库中上采样方法中的SMOTE接口
from imblearn.over_sampling import SMOTE
#定义SMOTE模型,random_state相当于随机数种子的作用
smo = SMOTE(random_state=42)
X_smo, y_smo = smo.fit_sample(X, y)
查看经过SMOTE之后的数据分布
print(Counter(y_smo))
#Counter({0: 900, 1: 900})
从上述代码中可以看出,SMOTE模型默认生成一比一的数据,如果想生成其他比例的数据,可以使用radio参数。不仅可以处理二分类问题,同样适用于多分类问题
#可通过radio参数指定对应类别要生成的数据的数量
smo = SMOTE(ratio={
1: 300 },random_state=42)
#生成0和1比例为3比1的数据样本
X_smo, y_smo = smo.fit_sample(X, y)
print(Counter(y_smo))
#Counter({0: 900, 1: 300})
imblearn中上采样接口提供了随机上采样RandomOverSampler,SMOTE,ADASYN三种方式,调用方式和主要参数基本一样。下采样接口中也提供了多种方法,以RandomUnderSampler为例。
from imblearn.under_sampling import RandomUnderSampler
#同理,也可使用ratio来指定下采样的比例
rus = RandomUnderSampler(ratio={
0: 500 }, random_state=0)
X_rus, y_rus = rus.fit_sample(X, y)
print(Counter(y_smo))
Counter({
0: 500, 1: 300})
欠采样代码
如果数据类别不平衡高达200:1,可将其比例调整为10:1,
from imblearn.under_sampling import RandomUnderSampler
from collections import Counter
def ratio_multiplier(y):
multiplier = {
0: 0.05, 1: 1}
target_stats = Counter(y)
for key, value in target_stats.items():
target_stats[key] = int(value * multiplier[key])
return target_stats
rus = RandomUnderSampler(random_state=100,ratio=ratio_multiplier)#100
X_res, y_res = rus.fit_sample(X_train_all, y_train_all)
参考:https://blog.csdn.net/nlpuser/article/details/81265614
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/150181.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
