大家好,又见面了,我是你们的朋友全栈君。
CNN
cnn每一层会输出多个feature map, 每个Feature Map通过一种卷积滤波器提取输入的一种特征,每个feature map由多个神经元组成,假如某个feature map的shape是m*n, 则该feature map有m*n个神经元。对于卷积层会有kernel, 记录上一层的feature map与当前层的卷积核的权重,因此kernel的shape为(上一层feature map的个数,当前层的卷积核数)。本文默认子采样过程是没有重叠的,卷积过程是每次移动一个像素,即是有重叠的。默认子采样层没有权重和偏置。关于CNN的其它描述不在这里论述,可以参考一下参考文献。只关注如何训练CNN。
CNN网络结构
一种典型卷积网络结构是LeNet-5,用来识别数字的卷积网络。结构图如下(来自Yann LeCun的论文):


在卷积神经网络算法的一个实现文章中,有一个更好看的图:

该图的输入是一张28*28大小的图像,在C1层有6个5*5的卷积核,因为C1层输出6个(28-5+1)(28-5+1)大小的feature map。然后经过子采样层,这里假设子采样层是对卷积层的均值处理(mean pooling), 其实一般还会有加偏置和激活的操作,为了简化,省略了这两步,只是对卷积层进行一个采样的操作。因此S2层输出的6个feature map大小为(24/2)(24/2).在卷积层C3中,它的输入是6个feature map,与C1不一样(C1只有一个feature map,如果是RGB的话,C1会有三个channel)。C3层有12个5*5卷积核,每个卷积核会与上一层的6个feature map分别做卷积(事实上,一般是选择几种输入feature map来做卷积,而不是全部的feature map),然后对这6个卷积结果求和组成一个新的feature map,即该层会有12个大小为(12-5+1)*(12-5+1)的feature map,这个feature map是经过sigmod 函数处理然后结果下一层S4。
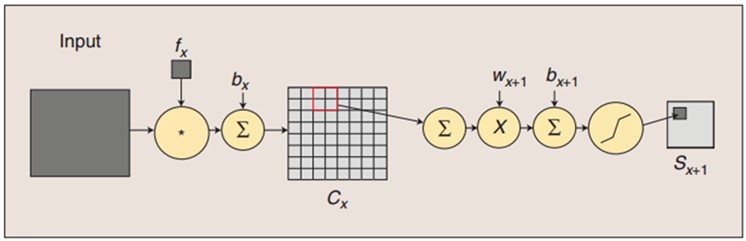
图片来源
同理,S4层有12个(与卷积层的feature map数一致)大小为(8/2)*(8/2)的feature map。输出层把S4层的feature mapflatten一个向量,向量长度为12*4*4=192,以该向量作为输入,与下面的其它层全连接,进行分类等操作,也就是说把一张图片变成一个向量,接入到别的网络,如传统的BP神经网络,不过从整体来看,CNN可以看做是一个BP神经网络。在
这里有两张很生动的图来描述这个过程:


权值共享理解
从代码的实现来看,每个卷积核会与部分或全部的输入(上一层输出)feature map进行卷积求和,但是每个卷积核的权重与一个feature map是一一对应,如上一章节中的C3-S4,说是有12个卷积核,然后就有12个输出feature map,但是每个卷积核与输入的6个feature map的权重都是不一样,即kernel不一样,也就是说每个卷积核的权重与一个feature map是一一对应。至于权值共享的话,对于同一个输入的feature map的神经元patch,用的是同一个卷积核权重,这个是共享的,只在同feature map共享,不在跨feature map共享,只是个人理解,有可能有错,if wrong please correct me.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/149707.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
