大家好,又见面了,我是你们的朋友全栈君。
视觉惯性里程计 VIO – Visual Inertial Odometry 视觉−惯性导航融合SLAM方案

博文末尾支持二维码赞赏哦 _
IO和之前的几种SLAM最大的不同在于两点:
首先,VIO在硬件上需要传感器的融合,包括相机和六轴陀螺仪,
相机产生图片,
六轴陀螺仪产生加速度和角速度。
相机相对准但相对慢,六轴陀螺仪的原始加速度如果拿来直接积分会在很短的时间飘走(zero-drift),
但六轴陀螺仪的频率很高,在手机上都有200Hz。
其次,VIO实现的是一种比较复杂而有效的卡尔曼滤波,比如MSCKF(Multi-State-Constraint-Kalman-Filter),
侧重的是快速的姿态跟踪,而不花精力来维护全局地图,
也不做keyframe based SLAM里面的针对地图的全局优化(bundle adjustment)。
最著名的商业化实现就是Google的Project Tango和已经被苹果收购的Flyby Media,
其中第二代Project Tango搭载了Nividia TK1并有主动光源的深度摄像头的平板电脑,
这款硬件可谓每个做算法的小伙伴的梦幻搭档,具体在这里不多阐述。
主要问题:
使用 IMU 对相机在快门动作期间内估计相机的运动 ,
但是由于 CMOS 相机的快门时间戳和 IMU 的时间戳的同步比较困难 ,
且相机的时间戳不太准确 , Guo 等 [52] 对时间戳不精确的卷帘快
门相机设计了一种 VIO (Visual inertial odometry)系统 ,
其位姿使用线性插值方法近似相机的运动轨迹 , 姿态使用旋转角度和旋转轴表示 ,
旋转轴不变 ,对旋转角度线性插值 ,
使用 MSCKF (Multi-stateconstrained Kalman filter) 建模卷帘快门相机的测量模型。
多传感器融合
传感器融合是一个趋势,也或者说是一个妥协的结果。
为什么说是妥协呢?
主要的原因还是由于单一的传感器不能适用所有的场景,
所以我们寄希望于通过多个传感器的融合达到理想的定位效果。
1、简单的,目前行业中有很多视觉+IMU的融合方案,
视觉传感器在大多数纹理丰富的场景中效果很好,
但是如果遇到玻璃,白墙等特征较少的场景,基本上无法工作;
IMU长时间使用有非常大的累积误差,但是在短时间内,其相对位移数据又有很高的精度,
所以当视觉传感器失效时,融合IMU数据,能够提高定位的精度。
2、再比如,无人车当中通常使用 差分GPS + IMU + 激光雷达(视觉)的定位方案。
差分GPS在天气较好、遮挡较少的情况下能够获得很好的定位精度,
但是在城市高楼区域、恶劣天气情况下效果下降非常多,
这时候融合IMU+激光雷达(视觉)的方案刚好能够填补不足。
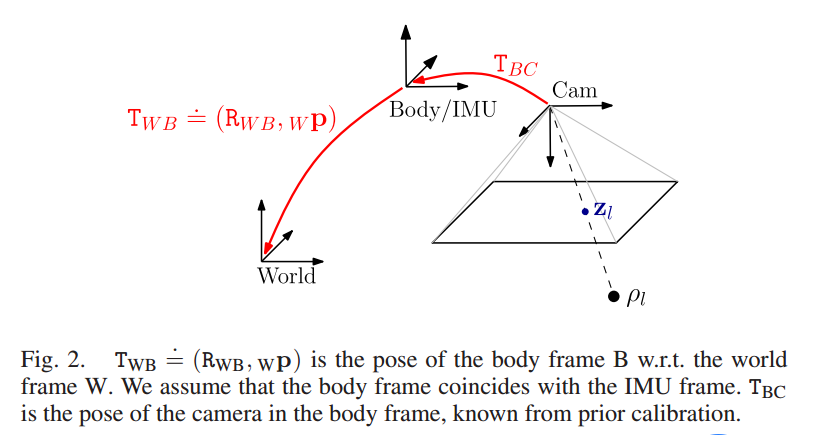
惯性传感器(IMU)
能够测量传感器本体的角速度和加速度,被认为与相机传感器具有明显的互补性,
而且十分有潜力在融合之后得到更完善的SLAM系统。
1、IMU虽然可以测得角速度和加速度,但这些量都存在明显的漂移(Drift),
使得积分两次得到的位姿数据非常不可靠。
好比说,我们将IMU放在桌上不动,用它的读数积分得到的位姿也会漂出十万八千里。
但是,对于短时间内的快速运动,IMU能够提供一些较好的估计。
这正是相机的弱点。
当运动过快时,(卷帘快门的)相机会出现运动模糊,
或者两帧之间重叠区域太少以至于无法进行特征匹配,
所以纯视觉SLAM非常害怕快速的运动。
而有了IMU,即使在相机数据无效的那段时间内,
我们也能保持一个较好的位姿估计,这是纯视觉SLAM无法做到的。
2、相比于IMU,相机数据基本不会有漂移。
如果相机放在原地固定不动,那么(在静态场景下)视觉SLAM的位姿估计也是固定不动的。
所以,
相机数据可以有效地估计并修正IMU读数中的漂移,使得在慢速运动后的位姿估计依然有效。
3、当图像发生变化时,本质上我们没法知道是相机自身发生了运动,
还是外界条件发生了变化,所以纯视觉SLAM难以处理动态的障碍物。
而IMU能够感受到自己的运动信息,从某种程度上减轻动态物体的影响。
IMU 互补滤波算法complementary filter 对 Gyroscope Accelerometer magnetometer 融合
IMU Data Fusing: Complementary, Kalman, and Mahony Filter
Mahony&Madgwick 滤波器 Mahony显式互补滤波
Google Cardboard的九轴融合算法 —— 基于李群的扩展卡尔曼滤波
Madgwick算法详细解读 陀螺仪积分的结果和加速度计磁场计优化的结果加权,就可以得到高精度的融合结果
<<Google Cardbord的九轴融合算法>> <<Madgwick算法>>,<<互补滤波算法>>
讨论的都是在SO3上的传感器融合,
即,输出的只是纯旋转的姿态。
只有旋转,而没有位移,也就是目前的一些普通的VR盒子的效果。
后面 imu+相机的融合是,在SE3上面的传感器融合,在既有旋转又有位移的情况下,该如何对多传感器进行融合。
难点
复杂性主要来源于 IMU测量 加速度 和 角速度 这两个量的事实,所以不得不引入运动学计算。
目前VIO的框架已经定型为两大类:
按照是否把图像特征信息加入状态向量来进行分类
1、松耦合(Loosely Coupled)
松耦合是指IMU和相机分别进行自身的运动估计,然后对其位姿估计结果进行融合。
2、紧耦合(Tightly Coupled)
紧耦合是指把IMU的状态与相机的状态合并在一起,共同构建运动方程和观测方程,然后进行状态估计。
紧耦合理论也必将分为 基于滤波(filter-based) 和 基于优化(optimization-based) 两个方向。
1、在滤波方面,传统的EKF以及改进的MSCKF(Multi-State Constraint KF)都取得了一定的成果,
研究者对EKF也进行了深入的讨论(例如能观性);
2、 优化方面亦有相应的方案。
值得一提的是,尽管在纯视觉SLAM中优化方法已经占了主流,
但在VIO中,由于IMU的数据频率非常高,
对状态进行优化需要的计算量就更大,因此目前仍处于滤波与优化并存的阶段。
VIO为将来SLAM的小型化与低成本化提供了一个非常有效的方向。
而且结合稀疏直接法,我们有望在低端硬件上取得良好的SLAM或VO效果,是非常有前景的。
融合方式
视觉信息和 IMU 数据融合在数据交互的方式上主要可以分为两种方式 , 松耦合 和 紧耦合 .
松耦合
松耦合的方法采用独立的惯性定位模块和定位导航模块 ,
两个模块更新频率不一致 , 模块之间存在一定的信息交换 .
在松耦合方式中以惯性数据为核心 , 视觉测量数据修正惯性测量数据的累积误差.
松耦合方法中视觉定位方法作为一个黑盒模块 ,由于不考虑 IMU 信息的辅助 ,
因此在视觉定位困难的地方不够鲁棒 , 另外该方法无法纠正视觉测量引入的漂移 .
紧耦合
紧耦合方式使用 IMU 完成视觉 VO 中的运动估计 ,
IMU 在图像帧间的积分的误差比较小 , IMU的数据可用于预测帧间运动 ,
加速完成点匹配 , 完成VO 位姿估计 .
相对于松耦合 ,
紧耦合的另外一个优点是 IMU 的尺度度量信息可以用于辅助视觉中的尺度的估计 .
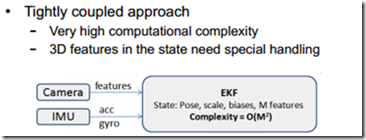
一、基于滤波器的紧耦合 Filter-based Tightly Coupled method
紧耦合需要把图像feature进入到特征向量去,
因此整个系统状态向量的维数会非常高,因此也就需要很高的计算量。
比较经典的算法是MSCKF,ROVIO
1. 紧耦合举例-msckf
据说这也是谷歌tango里面的算法。
在传统的EKF-SLAM框架中,特征点的信息会加入到特征向量和协方差矩阵里,
这种方法的缺点是特征点的信息会给一个初始深度和初始协方差,
如果不正确的话,极容易导致后面不收敛,出现inconsistent的情况。
Msckf维护一个pose的FIFO,按照时间顺序排列,可以称为 滑动窗口(silde window) ,
一个特征点在滑动窗口的几个位姿(帧)都被观察到的话,
就会在这几个位姿间建立约束,从而进行KF的更新。
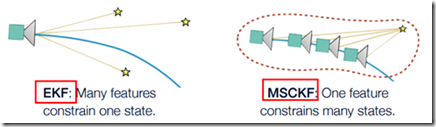
EKF-SLAM: 多个特征点同时约束一个相机位姿,进行KF更新
MSCKF : 一个特征点同时约束多个相机位姿(多相机观测同时优化,窗口多帧优化),进行KF更新
传统的 EKF-based SLAM 做 IMU 融合时,
一般是每个时刻的 系统状态向量(state vector) 包含当前的 位姿pose、速度velocity、以及 3D map points 坐标等(
IMU 融合时一般还会加入 IMU 的 bias(飘逸: 零飘和溫飘)),
然后用 IMU 做 预测predict step,
再用 image frame 中观测 3D map points 的观测误差做 更新update step。
MSCKF 的 motivation改进 是,EKF的每次 更新(类似优化)update step 是基于 3D map points 在单帧 frame 里观测的,
如果能基于其在多帧中的观测效果应该会好(有点类似于 local bundle adjustment 的思想)。
所以 MSCKF 的改进如下:
预测阶段predict step 跟 EKF 一样,
而 更新阶段update step 推迟到某一个 3D map point 在多个 frame 中观测之后进行计算,
在 update 之前每接收到一个 frame,只是将 state vector 扩充并加入当前 frame 的 pose estimate。
这个思想基本类似于 local bundle adjustment(或者 sliding window smoothing),
在update step时,相当于基于多次观测同时优化 pose 和 3D map point。
Event-based Visual Inertial Odometry 单目MSCKF视觉惯性里程计 论文
ros节点代码
Robust Stereo Visual Inertial Odometry for Fast Autonomous Flight 双目MSCKF视觉惯性里程计 论文
ros节点代码
MSCKF算法流程框架:
1. 初始化
1.1 摄像机参数、
噪声方差(图像噪声、IMU噪声、IMU的bias)、
初始的IMU协方差、
IMU和摄像机的外参数*、I
MU和摄像机的时间偏移量*
1.2 MSCKF参数:
状态向量里滑动窗口大小的范围、
空间点三角化误差阈值、
是否做零空间矩阵构造 和 QR分解
1.3 构造MSCKF状态向量
2.读取IMU数据,估计新的MSCKF状态变量和对应的协方差矩阵
3.图像数据处理
3.1 MSCKF状态向量 中 增加当前帧的摄像机位姿;
若位姿数大于滑动窗口大小的范围,
去除状态变量中最早的视图对应的摄像机位姿.
3.2提取图像特征并匹配,去除外点.
3.3 处理所有提取的特征。
判断当前特征是否是之前视图中已经观察到的特征
3.3.1 如果当前帧还可以观测到该特征,则加入该特征的track列表
3.3.2 如果当前帧观测不到该特征(Out_of_View),
将该特征的track加入到featureTracksToResidualize,用于更新MSCKF的状态变量.
3.3.3 给该特征分配新的featureID,并加入到当前视图可观测特征的集合
3.4 循环遍历featureTracksToResidualize中的track,用于更新MSCKF的状态变量
3.4.1 计算每个track对应的三维空间点坐标
(利用第一幅视图和最后一幅视图计算两视图三角化,使用逆深度参数化和高斯牛顿优化求解),
若三角化误差小于设置的阈值,则加入map集合.
3.4.2 计算视觉观测(即图像特征)的估计残差,并计算图像特征的雅克比矩阵.
3.4.3 计算图像特征雅克比矩阵的左零空间矩阵和QR分解,构造新的雅克比矩阵.
3.5 计算新的MSCKF状态向量的协方差矩阵.
3.5.1 计算Kalman增益.
3.5.2 状态矫正.
3.5.3 计算新的协方差矩阵.
3.6 状态变量管理
3.6.1 查找所有无feature track可见的视图集合deleteIdx.
3.6.2 将deleteIdx中的视图对应的MSCKF中的状态去除掉.
3.6.3 绘制运动轨迹.
2. ROVIO,基于稀疏图像块的EKF滤波实现的VIO
紧耦合,图像patch的稀疏前端(?),EKF后端
Robust Visual Inertial Odometry Using a Direct EKF-Based Approach 论文
基于扩展卡尔曼滤波:惯性测量用于滤波器的状态传递过程;视觉信息在滤波器更新阶段使用。
他的优点是:计算量小(EKF,稀疏的图像块),但是对应不同的设备需要调参数,参数对精度很重要。
没有闭环.
没有mapping thread。
经常存在误差会残留到下一时刻。
多层次patch特征处理:

处理图像和IMU
图像和IMU的处理沿用了PangFumin的思路。
只是把输入换成了笔记本摄像头和MPU6000传感器
。摄像头数据的读取放在了主线程中,IMU数据的读取放在了单独的线程中。
主线程和IMU线程通过一个Queue共享数据。
处理图像和IMU
图像和IMU的处理沿用了PangFumin的思路。只是把输入换成了笔记本摄像头和MPU6000传感器。
摄像头数据的读取放在了主线程中,IMU数据的读取放在了单独的线程中。
主线程和IMU线程通过一个Queue共享数据。
测试
反复实验的经验如下:一开始的时候很关键。最好开始画面里有很多的feature。
这里有很多办法,我会在黑板上画很多的feature,或者直接把Calibration Targets放在镜头前。
如果开机没有飘(driftaway),就开始缓慢的小幅移动,让ROVIO自己去调整CameraExtrinsics。
接着,就可以在房间里走一圈,再回到原点。
我一开始以为如果有人走动,ROVIO会不准。但是实测结果发现影响有限。
ROVIO有很多特征点,如果一两个特征点位置变动,ROVIO会抛弃他们。这里,ROVIO相当于在算法层面,解决了移动物体的侦测。
ROVIO与VR眼镜
一个是微软的Kinect游戏机,用了RGBD摄像头。
而HTCvive和Oculus,则使用空间的两点和手中的摄像机定位。
ROVIO没有深度信息,这也许就是为什么它容易driftaway。
如果要将ROVIO用于产品上,可能还需要一个特定的房间,在这个房间里,有很多的特征点。
如果房间里是四面白墙,恐怕ROVIO就无法运算了。
有限空间的定位
但是如果环境是可以控制的,也就不需要ROVIO了。
可以在房间里的放满国际象棋盘,在每个格子里标上数字,
这样只需要根据摄像头视野中的四个角上的feature(数字),就能确定位置了。
这里不需要什么算法,因为这样的排列组合是有限的。
只需要一个数据库就可以了。在POC阶段,可能会用数字。当然到了产品阶段会换成别的东西。
二、基于滤波器的松耦合 Filter-based Tightly Coupled
松耦合的方法则简单的多,避免把图像的feature加入状态向量,
而是把图像当成一个black box,计算vo处理之后才和imu数据进行融合。
Ethz的Stephen Weiss在这方面做了很多的研究,
他的ssf和msf都是这方面比较优秀的开源算法,有兴趣的读者可以参考他的博士论文。
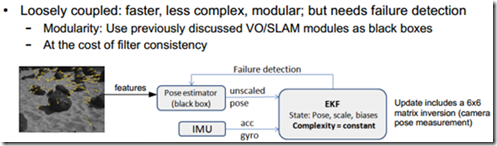
3. 基于滤波器的松耦合举例-ssf
滤波器的状态向量 x 是24维,如下,相较于紧耦合的方法会精简很多。
Ssf_core主要处理state的数据,里面有预测和更新两个过程。
Ssf_update则处理另外一个传感器的数据,主要完成测量的过程

红色字体部分是从传感器获取的数据,用于输入到预测(prediction)和更新阶段(update).
蓝色字体是更新阶段会变化的部分。
黑色部分为约束部分,是不变的。
变量:
p for pwi: 在世界坐标下的 IMU位置 IMU position in the world frame
v for vwi: 在世界坐标下的 IMU速度 IMU velocity in the world frame
q for qwi: 在世界坐标下的 IMU姿态 IMU attitude in the world frame
b_w for bw: 陀螺仪漂移 the gyro biases
b_a for ba: 陀螺仪漂移 the accelerometer biases
L for λ: 视觉尺度因子 the visual scale factor with pmetric*λ = psensor
q_wv for q,,vw: 更新阶段参考帧(相机参考帧) 和 世界参考帧 之间的姿态变化
q_ci for qic: IMU and the update-sensor(相机) 姿态变化
p_ci for pic: IMU and the update-sensor(相机) 位置变换
4. 基于滤波器的松耦合举例-msf

它的理论与 误差状态四元数 RT-SLAM 很接近,稍微有点不同,所以MSF开源程序就成了一个不错的选择
多传感器卡尔曼融合框架 Ethzasl MSF Framework 编译与使用
最终对应于MSF_Core类的三个函数,即
ProcessIMU(处理并汇集IMU消息)、AddMeasurement(处理汇集位姿观测值)、ProcessExternallyPropagatedState(状态预测)。
而msf_updates::pose_measurement::PoseMeasurement<> 实现了状态的更新。
5. D-LG-EKF 李群SE3上的 离散卡尔曼滤波
D-LG-EKF 李群SE3上的 离散卡尔曼滤波 论文 Discrete Extended Kalman Filter on Lie groups
6. RT-SLAM 误差状态四元数 和msf类似
它的基本思想和D-LG-EKF是一样的,都是对均值状态和扰动状态的进行处理。
但是,不同的是,在误差状态四元数里,是把偏移也放到状态里滤波的,
而Google Cardboard里的偏移是通过低通滤波滤出来的。
三、基于优化的松耦合
随着研究的不断进步和计算平台性能的不断提升,
optimization-based的方法在slam得到应用,
很快也就在VIO中得到应用,紧耦合中比较经典的是okvis,松耦合的工作不多。
大佬Gabe Sibley在iros2016的一篇文章
《Inertial Aided Dense & Semi-Dense Methods for Robust Direct Visual Odometry》提到了这个方法。
简单来说就是把vo计算产生的位姿变换添加到imu的优化框架里面去。
四、基于优化的 紧耦合
7. 基于优化的紧耦合举例-okvis 多目+IMU 使用了ceres solver的优化库。
论文Keyframe-Based Visual-Inertial Odometry Using Nonlinear Optimization
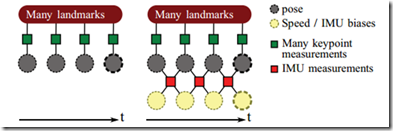
上图左边是纯视觉的odemorty,右边是视觉IMU融合的odemorty结构,
这个核心在于Frame通过IMU进行了联合,
但是IMU自身测量有一个随机游走的偏置,
所以每一次测量又通过这个偏置联合在了一起,
形成了右边那个结构,对于这个新的结构,
我们需要建立一个统一的损失函数进行联合优化.
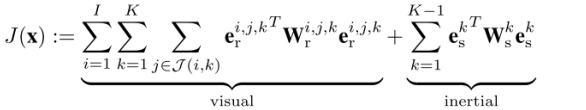
相对应于MSCKF的filter-based SLAM派系,OKVIS是keyframe-based SLAM派系做visual-inertial sensor fusion的代表。
从MSCKF的思想基本可以猜出,OKVIS是将image观测和imu观测显式formulate成优化问题,一起去优化求解pose和3D map point。
的确如此,OKVIS的优化目标函数包括一个reprojection error term(重投影误差)和一个imu integration error term(imu积分误差),
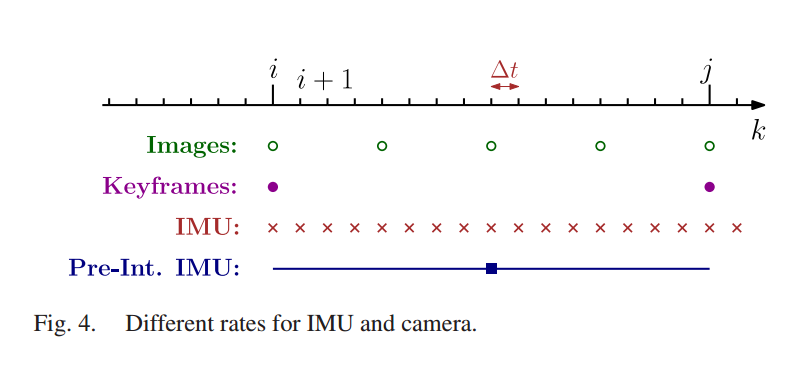
其中已知的观测数据是每两帧之间的feature matching(特征匹配)以及这两帧之间的所有imu采样数据的积分,
注意imu采样频率一般高于视频frame rate,待求的是camera pose和3D map point,
优化针对的是一个bounded window内的frames(包括最近的几个frames和几个keyframes)。
需要注意的是,在这个optimization problem中,对uncertainty(不确定性,类似方差)的建模还是蛮复杂的。
首先是对imu的gyro和accelerometer的bias(漂移)都需要建模,
并在积分的过程中将uncertainty(不确定性,类似方差)也积分,
所以推导两帧之间的imu integration error(imu积分误差)时,
需要用类似于Kalman filter中predict step(预测阶段)里的,
uncertainty propagation(不确定性传播)方式去计算covariance(协方差矩阵)。
另外,imu的kinematics微分方程也是挺多数学公式,
这又涉及到捷联惯性导航(strapdown inertial navigation)
https://www.cl.cam.ac.uk/techreports/UCAM-CL-TR-696.pdf
中相关的很多知识,推导起来不是很容易。
这可以另起一个topic去学习了。
OKVIS使用keyframe的motivation(创新点)是,由于optimization算法速度的限制,
优化不能针对太多frames一起,所以尽量把一些信息量少的frames给marginalization(滤出)掉,
只留下一些keyframes之间的constraints。关于marginalization的机制也挺有趣。
8. 基于优化的 紧耦合 orbslam2 + imu 紧耦合、ORB稀疏前端、图优化后端、带闭环检测和重定位
论文Visual-Inertial Monocular SLAM with Map Reuse
论文On-Manifold Preintegration for Real-Time Visual-Inertial Odometry
欧拉积分、中点积分 与 龙格-库塔积分(Runge-Kutta methods)RK4在VI ORB SLAM2
RK4 算法在 SLAM 中也有很好的应用,特别是 VIO 中的预积分部分,
比如张腾将王京的 VI ORB SLAM2 代码改成 RK4 积分后,
精度也得到了一定的提升:https://github.com/RomaTeng/ORB-VINS_RK4
当然 RK4 算法比起欧拉积分、中点积分计算量要大不少
,SLAM 中影响精度的地方非常多,紧靠 RK4 改进其对于精度的提升程度通常也不会特别大,
不过对于速度要求不高而精度要求很高的场合还是值得尝试的。
使用 evo 工具评测 VI ORB SLAM2 在 EuRoC 上的结果
VISUAL INERTIAL ORB-SLAM代码详细说明
ORB_SLAM2的作者在2017年提出了具有地图重用功能的单目视觉惯性定位算法,
该算法的具体思路和港科大的VINS有着异曲同工之妙,整体过程可分为下面几个部分:
1.整体流程与基础知识总结
2.基于流型的IMU预积分
3.IMU初始化(视觉惯性联合初始化)
4.紧耦合优化模型
1.整体流程与基础知识总结
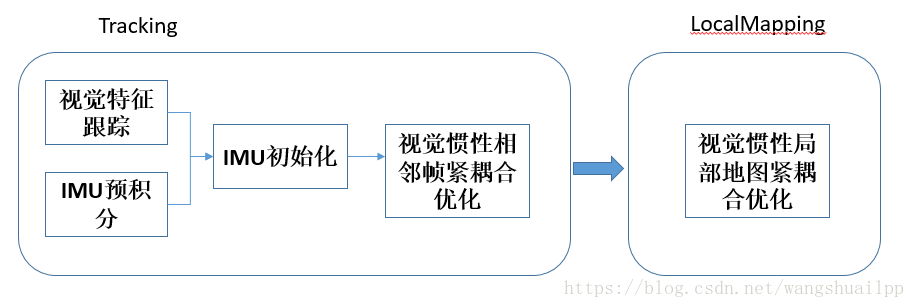
1)整体框架
对于整个ORB_SLAM2的框架大家有一定的了解,主要分为三个线程Tracking、LocalMapping和Loopclosing。
我对VIO这块的理解目前只局限于前两个线程,因此整体框架就包含前两个线程中的理解:
2)基础知识总结
叉乘,叉乘矩阵,叉积的定义式
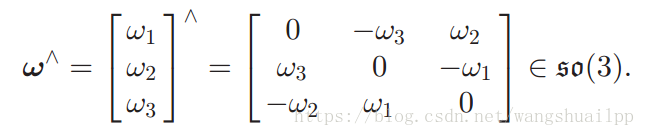
叉积的一个最重要的性质,在后面的雅各比矩阵推导中起到至关重要的作用,需要谨记:
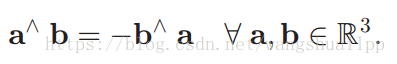
指数函数的一阶泰勒近似:
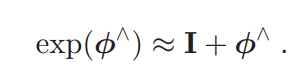
这个式子就是以前数学中指数一阶泰勒展开,很简单,
因为旋转涉及到李群和李代数的指数转换关系,
所以这个式子在后面的优化雅各比推导中很重要。
李群和李代数指数转换关系:

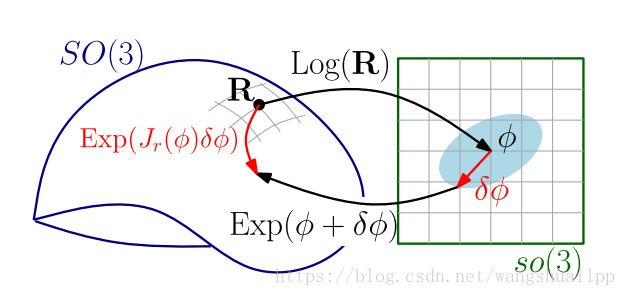
李群和李代数是指数映射关系,是三维向量(旋转向量)与三维旋转矩阵之间的转换,
上图中可以看到流型的李群上的切平面(李代数)可以由李群一阶近似(李群扰动表示李代数扰动).
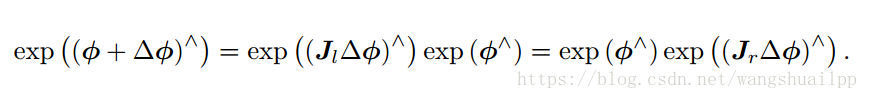
上面的公式参考视觉SLAM十四讲中,原文预积分中给出的是李代数“向量”形式,
感觉不太好理解,所以还是用反对称矩阵来表示,其中Jr是李代数上的右雅各比

同样的李代数扰动可以表示李群扰动
李群扰动 = 李代数扰动 后指数映射
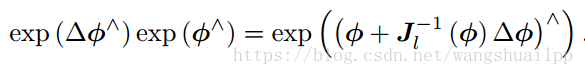
2.基于流型的IMU预积分
3.IMU初始化(视觉惯性联合初始化)
终于来到视觉惯性初始化阶段了,这段是视觉和惯性数据融合的第一步,是一段松耦合过程。
理论上是将准确的视觉数据(但缺少尺度)和快速的IMU数据(需要重力加速度又存在零偏误差)相结合。
具体介绍在VINS的博客中也同样说过,这部分关于最小二乘、尺度收敛等问题请参考我的博客:
视觉SLAM常见的QR分解SVD分解等矩阵分解方式求解满秩和亏秩最小二乘问题(最全的方法分析总结)
(1)陀螺仪偏置标定(零偏)
这一部分比较简单,直接联立N-1个相机做旋转矩阵的最小二乘即可,然后通过高斯牛顿方法即可得到零偏bg。
需要注意一点,当求出零偏后将其代入预积分公式会重新计算一遍预积分值,使预积分数值更加准确.
(2)尺度恢复和重力加速度预估
首先建立预估状态向量X=[s,gw],其中s是尺度,gw是世界坐标系下的重力加速度也是第一个相机坐标系下的重力加速度。
ORB_SLAM2中世界坐标选取的是第一个相机对应的坐标(VINS则不同),这样做会存在一个问题,
因为第一个相机可能自身存在一定的旋转倾斜导致整个世界坐标看起来是歪着的,画轨迹的时候有一种倾斜的即视感,
所以我觉得还是尽量固定好z方向,使轨迹没有横滚和俯仰。
这里使用了三个关键帧联立视觉和IMU预积分数据构建一个AX=B的最小二乘超定方程,至少需要四个关键帧,
采用奇异值分解求最小二乘问题,速度较慢但精度高。
(3)加速度计偏置标定和尺度重力加速度优化
上面计算过程没有考虑到加速度计偏置的影响,使得重力加速度和加速度计偏置难以区分,
很有可能会导致系统病态性问题,文中提出了重力加速度的大小G,假设其是一个不变值,优化重力加速度的方向。
4.紧耦合优化模型
视觉惯性紧耦合优化部分分为三个部分,分别是Tracking、LocalMapping和Loopclosing,
我只是学习了前两个部分,所以就简单的介绍下这两个内容
(1)Tracking线程中帧间紧耦合优化
论文中说的也比较清楚,分为两中情况,分别是有地图更新和无地图更新。
Tracking线程中一开始是没有地图更新的,地图更新是在LocalMapping和LoopClosing中完成。
因此这两种方式是随机切换的。
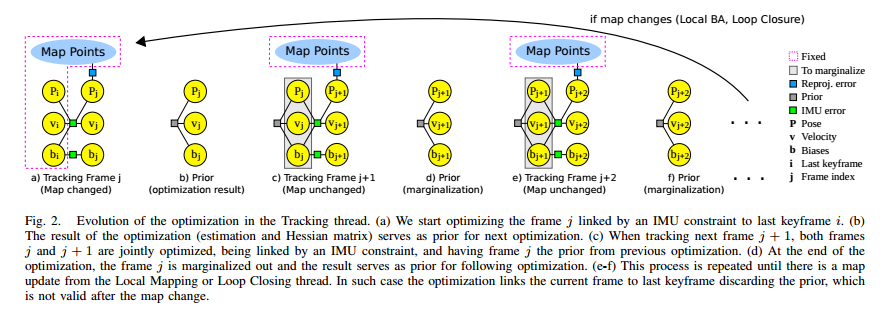
红色虚框是固定的状态量(fix),不会进行优化但是会在优化的时候作为约束项优化其他状态量,
浅灰色实框是将要进行边缘化的状态量(marginalize),
蓝色实框是视觉重投影误差方程,
深灰色实框是无地图更新时候的先验数据(prior),
绿色实框是IMU测量误差方程。
(a)是出现地图更新的状态,一开始j是当前帧,i是上一帧,
通过视觉重投影误差和IMU测量误差优化当前帧的状态量(pj,vj,bj),
上一帧的状态量和Map Points不会进行优化而是作为约束项优化当前状态量。
(b)是(a)优化后的结果(估计值和海塞矩阵H),同时将优化结果
(c)是无地图更新状态,当前帧变成了j+1,
此时通过重投影误差和IMU测量误差优化当前帧和上一帧j的状态量(pj,vj,bj, pj+1,vj+1,bj+1),
Map Points不会进行优化而是作为约束项优化j和j+1时刻的状态量,
同时j时刻的优化结果作为先验数据优化,然后将j时刻的状态量边缘化掉。
(d)边缘化掉j时刻的j+1时刻优化量(估计值和海塞矩阵H)作为下一时刻优化的先验数据。
(e)和(c)的过程一模一样。
(f)和(d)的过程一模一样。
然后一直循环(c)(d)过程,直到LocalMapping和LoopClosing中发生地图更新会回到(a)处重复过程。
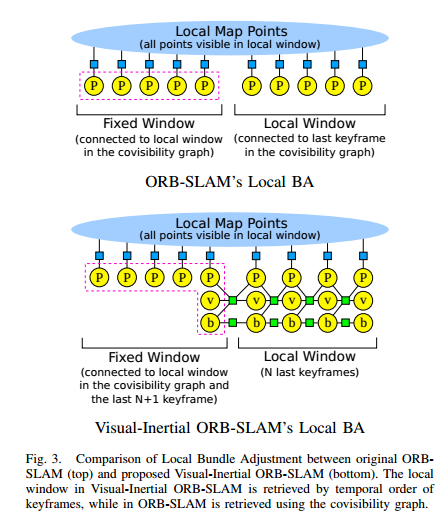
(2)LocalMapping线程
整个BA优化的只优化固定的N帧,而且这N帧是共视程度最高的N个关键帧,在局部窗口中(Local Windows),
地图中所有的点都是这些N个关键帧产生,其他的关键帧是在固定窗口中(Fixed Window),
只提供与局部地图点的观测值,不进行优化。当然局部地图路标点也需要优化。
需要优化的关键帧包含有视觉重投影误差和IMU测量误差。
需要优化的特征点包含Local和Fixed Window的重投影误差。
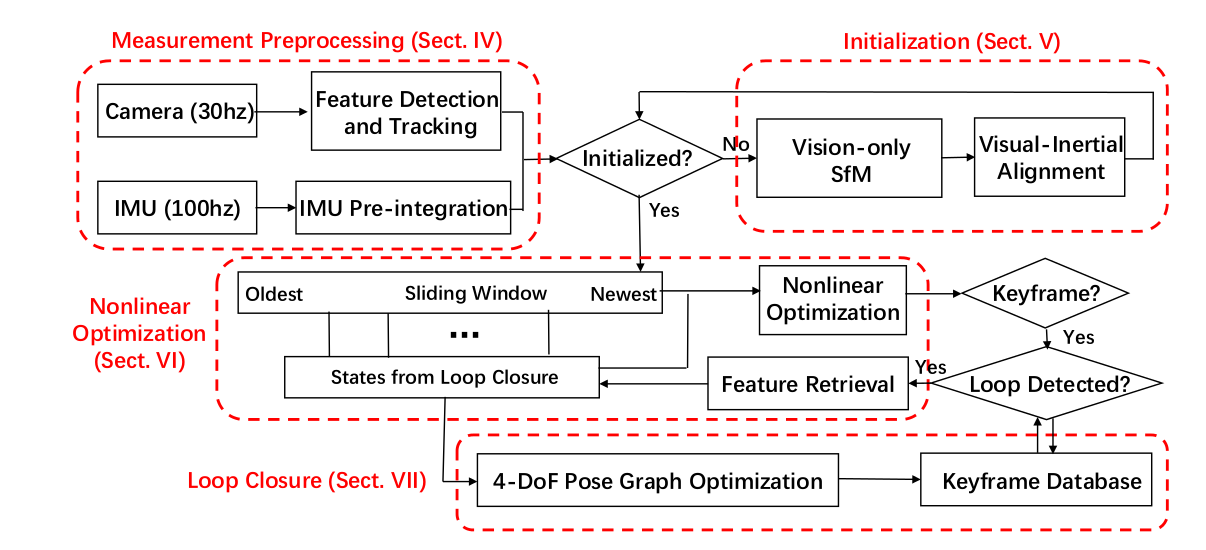
7.基于优化的紧耦合 VINS-Mono 港科大的VIO
前端基于KLT跟踪算法, 后端基于滑动窗口的优化(采用ceres库), 基于DBoW的回环检测
代码主要分为:
前端(feature tracker),
后端(sliding window, loop closure),
还加了初始化(visual-imu aligment).
VINS代码主要包含在两个文件中,
分别是feature_tracker 和
vins_estimate,
1. feature_tracker 就像文件的名字一样,总体的作用是接收图像,使用KLT光流算法跟踪;
2. vins_estimate包含相机和IMU数据的前端预处理(也就是预积分过程)、
单目惯性联合初始化(在线的标定过程)、基于滑动窗口的BA联合优化、全局的图优化和回环检测等。
要想真正的理解一个SLAM框架,必须真正搞懂其对应的算法模型,然后才能研究其代码逻辑,
最后做到相得益彰的效果,因此本次讲解主要是结合论文中的理论知识这和两个文件中的代码进行详细的探讨。
整体的框架都比较熟悉,
如下图所示:
第一部分是Measuremen Preprocessing:观测值数据预处理,包含图像数据跟踪IMU数据预积分;
第二部分是Initialization:初始化,包含单纯的视觉初始化和视觉惯性联合初始化;
第三部分Local Visual-Inertia BA and Relocalization:
局部BA联合优化和重定位,包含一个基于滑动窗口的BA优化模型;
第四部分Global Pose Graph Optimization:全局图优化,只对全局的位姿进行优化;
第五部分Loop detection:回环检测。
Feature tracker 特征跟踪
这部分代码在feature_tracker包下面,主要是接收图像topic,
使用KLT光流算法跟踪特征点,同时保持每一帧图像有最少的(100-300)个特征点。
根据配置文件中的freq,确定每隔多久的时候,
把检测到的特征点打包成/feature_tracker/featuretopic 发出去,
要是没有达到发送的时间,这幅图像的feature就作为下一时刻的
KLT追踪的特征点,就是不是每一副图像都要处理的,那样计算时间大了,
而且数据感觉冗余,帧与帧之间图像的差距不会那么明显。
这里的freq配置文件建议至少设置10,为了保证好的前端。
void img_callback(const sensor_msgs::ImageConstPtr &img_msg)
{
for (int i = 0; i < NUM_OF_CAM; i++)
{
ROS_DEBUG("processing camera %d", i);
if (i != 1 || !STEREO_TRACK)
//调用FeatureTracker的readImage
trackerData[i].readImage(ptr->image.rowRange(ROW * i, ROW * (i + 1)));
}
for (unsigned int i = 0;; i++)
{
bool completed = false;
for (int j = 0; j < NUM_OF_CAM; j++)
if (j != 1 || !STEREO_TRACK)
//更新feature的ID
completed |= trackerData[j].updateID(i);
if (!completed)
break;
}
//发布特征点topic
if (round(1.0 * pub_count / (img_msg->header.stamp.toSec() - first_image_time)) <= FREQ)
{
sensor_msgs::PointCloudPtr feature_points(new sensor_msgs::PointCloud);
//特征点的id,图像的(u,v)坐标
sensor_msgs::ChannelFloat32 id_of_point;
sensor_msgs::ChannelFloat32 u_of_point;
sensor_msgs::ChannelFloat32 v_of_point;
pub_img.publish(feature_points);
}
if (SHOW_TRACK)
{
//根据特征点被追踪的次数,显示他的颜色,越红表示这个特征点看到的越久,一幅图像要是大部分特征点是蓝色,前端tracker效果很差了,估计要挂了
double len = std::min(1.0, 1.0 * trackerData[i].track_cnt[j] / WINDOW_SIZE);
cv::circle(tmp_img, trackerData[i].cur_pts[j], 2, cv::Scalar(255 * (1 - len), 0, 255 * len), 2);
}
}
void FeatureTracker::readImage(const cv::Mat &_img)
{
//直方图均匀化
//if image is too dark or light, trun on equalize to find enough features
if (EQUALIZE)
{
cv::Ptr<cv::CLAHE> clahe = cv::createCLAHE(3.0, cv::Size(8, 8));
TicToc t_c;
clahe->apply(_img, img);
ROS_DEBUG("CLAHE costs: %fms", t_c.toc());
}
if (cur_pts.size() > 0)
{
TicToc t_o;
vector<uchar> status;
vector<float> err;
//根据上一时刻的cur_img,cur_pts,寻找当前时刻的forw_pts,
cv::calcOpticalFlowPyrLK(cur_img, forw_img, cur_pts, forw_pts, status, err, cv::Size(21, 21), 3);
}
if (img_cnt == 0)
{
//根据fundamentalMatrix中的ransac去除一些outlier
rejectWithF();
//跟新特征点track的次数
for (auto &n : track_cnt)
n++;
//为下面的goodFeaturesToTrack保证相邻的特征点之间要相隔30个像素,设置mask image
setMask();
int n_max_cnt = MAX_CNT - static_cast<int>(forw_pts.size());
if (n_max_cnt > 0)
{
//保证每个image有足够的特征点,不够就新提取
cv::goodFeaturesToTrack(forw_img, n_pts, MAX_CNT - forw_pts.size(), 0.1, MIN_DIST, mask);
}
}
}
滑动窗口优化更新 Slide Window
主要是:
对imu的数据进行预积分,
vision重投影误差的构造,
loop-closure的检测,
slide-window的维护 ,
marginzation prior的维护,
东西比较多。
loop-closure的检测是使用视觉词带的,
这里的特征不是feature-tracker的,那样子太少了。
是通过订阅IMAGE_TOPIC,传递到闭环检测部分,重新检测的,
这个我还没有认真看(做了很多限制,为了搜索的速度,词带不会很大,做了很多限制,
从论文上看优化的方程只是加了几个vision重投影的限制,速度不会太慢)。
是只有4个自由度的优化,roll, pitch由于重力对齐的原因是可观测的,就不去优化。
最主要的还是下面这个最小二乘法方程构建,主要的代码我列出来。
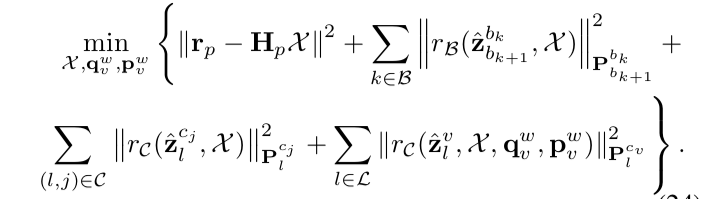
void Estimator::processIMU(double dt, const Vector3d &linear_acceleration, const Vector3d &angular_velocity)
{
if (frame_count != 0)
{
pre_integrations[frame_count]->push_back(dt, linear_acceleration, angular_velocity);
//调用imu的预积分,propagation ,计算对应的雅可比矩阵
//if(solver_flag != NON_LINEAR)
tmp_pre_integration->push_back(dt, linear_acceleration, angular_velocity);
dt_buf[frame_count].push_back(dt);
linear_acceleration_buf[frame_count].push_back(linear_acceleration);
angular_velocity_buf[frame_count].push_back(angular_velocity);
//提供imu计算的当前位置,速度,作为优化的初值
int j = frame_count;
Vector3d un_acc_0 = Rs[j] * (acc_0 - Bas[j]) - g;
Vector3d un_gyr = 0.5 * (gyr_0 + angular_velocity) - Bgs[j];
Rs[j] *= Utility::deltaQ(un_gyr * dt).toRotationMatrix();
Vector3d un_acc_1 = Rs[j] * (linear_acceleration - Bas[j]) - g;
Vector3d un_acc = 0.5 * (un_acc_0 + un_acc_1);
Ps[j] += dt * Vs[j] + 0.5 * dt * dt * un_acc;
Vs[j] += dt * un_acc;
}
}
void Estimator::processImage(const map<int, vector<pair<int, Vector3d>>> &image, const std_msgs::Header &header)
{
//根据视差判断是不是关键帧,
if (f_manager.addFeatureCheckParallax(frame_count, image))
marginalization_flag = MARGIN_OLD;
else
marginalization_flag = MARGIN_SECOND_NEW;
ImageFrame imageframe(image, header.stamp.toSec());
imageframe.pre_integration = tmp_pre_integration;
all_image_frame.insert(make_pair(header.stamp.toSec(), imageframe));
tmp_pre_integration = new IntegrationBase{
acc_0, gyr_0, Bas[frame_count], Bgs[frame_count]};
//参数要是设置imu-camera的外参数未知,也可以帮你求解的
if(ESTIMATE_EXTRINSIC == 2)
{
}
//初始化的流程
if (solver_flag == INITIAL)
{
if (frame_count == WINDOW_SIZE)
{
bool result = false;
if( ESTIMATE_EXTRINSIC != 2 && (header.stamp.toSec() - initial_timestamp) > 0.1)
{
//构造sfm,优化imu偏差,加速度g,尺度的确定
result = initialStructure();
initial_timestamp = header.stamp.toSec();
}
if(result)
{
solver_flag = NON_LINEAR;
solveOdometry();
slideWindow();
f_manager.removeFailures();
ROS_INFO("Initialization finish!");
last_R = Rs[WINDOW_SIZE];
last_P = Ps[WINDOW_SIZE];
last_R0 = Rs[0];
last_P0 = Ps[0];
}
else
slideWindow();
}
//先凑够window-size的数量的Frame
else
frame_count++;
}
else
{
solveOdometry();
//失败的检测
if (failureDetection())
{
clearState();
setParameter();
return;
}
slideWindow();
f_manager.removeFailures();
// prepare output of VINS
key_poses.clear();
for (int i = 0; i <= WINDOW_SIZE; i++)
key_poses.push_back(Ps[i]);
last_R = Rs[WINDOW_SIZE];
last_P = Ps[WINDOW_SIZE];
last_R0 = Rs[0];
last_P0 = Ps[0];
}
}
void Estimator::slideWindow()
{
//WINDOW_SIZE中的参数的之间调整,同时FeatureManager进行管理feature,有些点要删除掉,有些点的深度要在下一frame表示(start frame已经删除了)
Headers[frame_count - 1] = Headers[frame_count];
Ps[frame_count - 1] = Ps[frame_count];
Vs[frame_count - 1] = Vs[frame_count];
Rs[frame_count - 1] = Rs[frame_count];
Bas[frame_count - 1] = Bas[frame_count];
Bgs[frame_count - 1] = Bgs[frame_count];
delete pre_integrations[WINDOW_SIZE];
pre_integrations[WINDOW_SIZE] = new IntegrationBase{
acc_0, gyr_0, Bas[WINDOW_SIZE], Bgs[WINDOW_SIZE]};
//清楚数据,给下一副图像提供空间
dt_buf[WINDOW_SIZE].clear();
linear_acceleration_buf[WINDOW_SIZE].clear();
angular_velocity_buf[WINDOW_SIZE].clear();
}
void Estimator::solveOdometry()
{
if (frame_count < WINDOW_SIZE)
return;
if (solver_flag == NON_LINEAR)
{
//三角化点
f_manager.triangulate(Ps, tic, ric);
ROS_DEBUG("triangulation costs %f", t_tri.toc());
optimization();
}
}
void Estimator::optimization()
{
//添加frame的state,(p,v,q,b_a,b_g),就是ceres要优化的参数
for (int i = 0; i < WINDOW_SIZE + 1; i++)
{
ceres::LocalParameterization *local_parameterization = new PoseLocalParameterization();
problem.AddParameterBlock(para_Pose[i], SIZE_POSE, local_parameterization);
problem.AddParameterBlock(para_SpeedBias[i], SIZE_SPEEDBIAS);
}
//添加camera-imu的外参数
for (int i = 0; i < NUM_OF_CAM; i++)
{
ceres::LocalParameterization *local_parameterization = new PoseLocalParameterization();
problem.AddParameterBlock(para_Ex_Pose[i], SIZE_POSE, local_parameterization);
}
//为ceres参数赋予初值
vector2double();
//添加margination residual, 先验知识
//他的Evaluate函数看好,固定了线性化的点,First Jacobian Estimate
if (last_marginalization_info)
{
// construct new marginlization_factor
MarginalizationFactor *marginalization_factor = new MarginalizationFactor(last_marginalization_info);
problem.AddResidualBlock(marginalization_factor, NULL,
last_marginalization_parameter_blocks);
}
//添加imu的residual
for (int i = 0; i < WINDOW_SIZE; i++)
{
int j = i + 1;
if (pre_integrations[j]->sum_dt > 10.0)
continue;
IMUFactor* imu_factor = new IMUFactor(pre_integrations[j]);
problem.AddResidualBlock(imu_factor, NULL, para_Pose[i], para_SpeedBias[i], para_Pose[j], para_SpeedBias[j]);
}
//添加vision的residual
for (auto &it_per_id : f_manager.feature)
{
for (auto &it_per_frame : it_per_id.feature_per_frame)
{
imu_j++;
if (imu_i == imu_j)
{
continue;
}
Vector3d pts_j = it_per_frame.point;
ProjectionFactor *f = new ProjectionFactor(pts_i, pts_j);
problem.AddResidualBlock(f, loss_function, para_Pose[imu_i], para_Pose[imu_j], para_Ex_Pose[0], para_Feature[feature_index]);
f_m_cnt++;
}
}
//添加闭环的参数和residual
if(LOOP_CLOSURE)
{
ceres::LocalParameterization *local_parameterization = new PoseLocalParameterization();
problem.AddParameterBlock(front_pose.loop_pose, SIZE_POSE, local_parameterization);
if(front_pose.features_ids[retrive_feature_index] == it_per_id.feature_id)
{
Vector3d pts_j = Vector3d(front_pose.measurements[retrive_feature_index].x, front_pose.measurements[retrive_feature_index].y, 1.0);
Vector3d pts_i = it_per_id.feature_per_frame[0].point;
ProjectionFactor *f = new ProjectionFactor(pts_i, pts_j);
problem.AddResidualBlock(f, loss_function, para_Pose[start], front_pose.loop_pose, para_Ex_Pose[0], para_Feature[feature_index]);
retrive_feature_index++;
loop_factor_cnt++;
}
}
//设置了优化的最长时间,保证实时性
if (marginalization_flag == MARGIN_OLD)
options.max_solver_time_in_seconds = SOLVER_TIME * 4.0 / 5.0;
else
options.max_solver_time_in_seconds = SOLVER_TIME;
// 求解
ceres::Solve(options, &problem, &summary);
// http://blog.csdn.net/heyijia0327/article/details/53707261#comments
// http://blog.csdn.net/heyijia0327/article/details/52822104
if (marginalization_flag == MARGIN_OLD)
{
//如果当前帧是关键帧的,把oldest的frame所有的信息margination,作为下一时刻的先验知识,参考上面的两个网址,大神的解释很明白
}
else{
//如果当前帧不是关键帧的,把second newest的frame所有的视觉信息丢弃掉,imu信息不丢弃,记住不是做margination,是为了保持矩阵的稀疏性
}
}
后续
imu的参数很重要,还有就是硬件同步,global shutter的摄像头很重要。
我要是动作快的话,效果就不行了。但人家的视频感觉效果很不错。
这个还要继续弄硬件和代码原理,
代码中最小二乘法优化中的FOCAL_LENGTH感觉要根据自己的摄像头设置,
还没有具体看,视觉信息矩阵的设置还没有看。
8. gtsam 因子图优化+贝叶斯滤波 类是一个g2o框架 可以优化很多
论文 On-Manifold Preintegration for Real-Time Visual-Inertial Odometry
IMU Preintegration (2015-2016)
从OKVIS的算法思想中可以看出,在优化的目标函数中,
两个视频帧之间的多个imu采样数据被积分成一个constraint,这样可以减少求解optimization的次数。
然而OKVIS中的imu积分是基于前一个视频帧的estimated pose,这样在进行optimization迭代求解时,
当这个estimated pose发生变化时,需要重新进行imu积分。
为了加速计算,这自然而然可以想到imu preintegraion的方案,
也就是将imu积分得到一个不依赖于前一个视频帧estimated pose的constraint。
当然与之而来的还有如何将uncertainty也做类似的propagation(考虑imu的bias建模),
以及如何计算在optimization过程中需要的Jacobians。
在OKVIS的代码ImuError.cpp和GTSAM 4.0的代码ManifoldPreintegration.cpp中可以分别看到对应的代码。
五、雷达结合IMU
2Dlidar(3Dlidar)+IMU
2Dlidar(3Dlidar)+IMU Google的SLAM cartographer 代码
六、雷达结合相机
七. GPS + IMU 组合导航

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/149675.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
