大家好,又见面了,我是你们的朋友全栈君。
一、协同过滤算法原理
协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。简单的说就是:人以类聚,物以群分。下面我们将分别说明这两类推荐算法的原理和实现方法。


以上是常见的几种评价方式。
二、基于用户的协同过滤
1、基于用户的协同过滤 user-based collaboratIve filtering
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行商品推荐。

2、寻找偏好的相似用户
我们模拟了5个用户对两件商品的评分,来说明如何通过用户对不同商品的态度和偏好寻找相似的用户。在示例中,5个用户分别对两件商品进行了评分。

(1)欧几里得举例评价

(2)皮尔逊相关度评价
皮尔逊相关度评价是另一种计算用户间关系的方法。他比欧几里德距离评价的计算要复杂一些,但对于评分数据不规范时皮尔逊相关度评价能够给出更好的结果。
相关系数的分类
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关


3、为相似的用户提供推荐物品
(1)为用户C推荐商品
当我们需要对用户C推荐商品时,首先我们检查之前的相似度列表,发现用户C和用户D和E的相似度较高。换句话说这三个用户是一个群体,拥有相同的偏好。因此,我们可以对用户C推荐D和E的商品。但这里有一个问题。我们不能直接推荐前面商品1-商品5的商品。因为这这些商品用户C以及浏览或者购买过了。不能重复推荐。因此我们要推荐用户C还没有浏览或购买过的商品。
(2)加权排序推荐
我们提取了用户D和用户E评价过的另外5件商品A—商品F的商品。并对不同商品的评分进行相似度加权。按加权后的结果对5件商品进行排序,然后推荐给用户C。这样,用户C就获得了与他偏好相似的用户D和E评价的商品。而在具体的推荐顺序和展示上我们依照用户D和用户E与用户C的相似度进行排序。
这里基于用户的协同过滤 user_C对X的喜好=user_D对X的喜好*user_C与user_D的相似度。
因此下表得到的商品*的评分均为推荐出的用户C对该商品的评分。然后对其排序推荐给C.

这里的相似度总计是什么?又为什么需要用总计/相似度?—-看 协同过滤推荐算法(二)归一化处理
以上是基于用户的协同过滤算法。这个算法依靠用户的历史行为数据来计算相关度。也就是说必须要有一定的数据积累(冷启动问题)。对于新网站或数据量较少的网站,还有一种方法是基于物品的协同过滤算法。
三、基于物品的协同过滤算法 item-based collaborative filtering
基于物品的协同过滤算法与基于用户的协同过滤算法很像,将商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。这里的评分代表用户对商品的态度和偏好。简单来说就是如果用户A同时购买了商品1和商品2,那么说明商品1和商品2的相关度较高。当用户B也购买了商品1时,可以推断他也有购买商品2的需求。
1、寻找相似的物品
(1)欧几里得举例评价
在基于物品的协同过滤算法中,我们依然可以使用欧几里德距离评价来计算不同商品间的距离和关系。以下是计算公式。
通过欧几里德系数可以发现,商品间的距离和关系与前面散点图中的表现一致,商品1,3,4距离较近关系密切。商品2和商品5距离较近。

(2)皮尔逊相关度评价
我们选择使用皮尔逊相关度评价来计算多用户与多商品的关系计算。下面是5个用户对5件商品的评分表。我们通过这些评分计算出商品间的相关度。

通过计算可以发现,商品1&2,商品3&4,商品3&5和商品4&5相似度较高。下一步我们可以依据这些商品间的相关度对用户进行商品推荐。

2、为用户提供基于相似物品的推荐
这里我们遇到了和基于用户进行商品推荐相同的问题,当需要对用户C基于商品3推荐商品时,需要一张新的商品与已有商品间的相似度列表。在前面的相似度计算中,商品3与商品4和商品5相似度较高,因此我们计算并获得了商品4,5与其他商品的相似度列表。

以下是通过计算获得的新商品与已有商品间的相似度数据。

加权排序推荐
这里是用户C已经购买过的商品4,5与新商品A,B,C直接的相似程度。我们将用户C对商品4,5的评分作为权重。对商品A,B,C进行加权排序。用户C评分较高并且与之相似度较高的商品被优先推荐。
基于物品的协同过滤:user_C对X的喜好=user_C对Y的喜好*X与Y的相似度
user_C对商品A的喜好=user_C对商品4的喜好*商品A和4的相似度

算出来用户C对商品ABC的评分后为什么要用总计/用户C对商品45的评分?—–公式
基于物品的协同过滤算法详解
一、算法描述
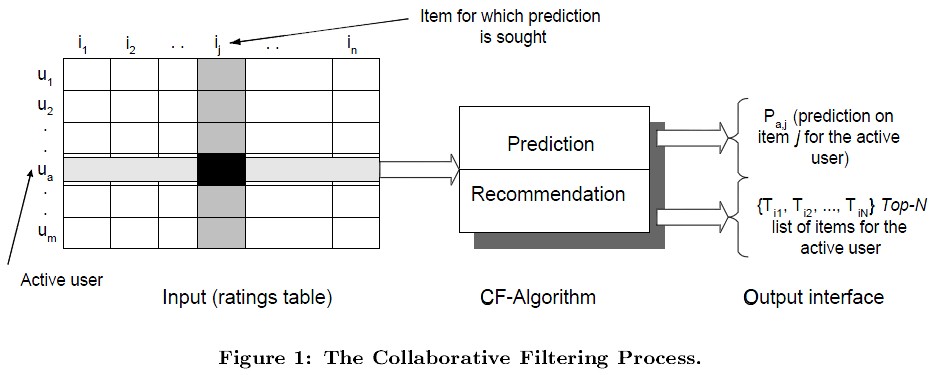
在CF中,用m×n的矩阵表示用户对物品的喜好情况,一般用打分表示用户对物品的喜好程度,分数越高表示越喜欢这个物品,0表示没有买过该物品。图中行表示一个用户,列表示一个物品,Uij表示用户i对物品j的打分情况。CF分为两个过程,一个为预测过程,另一个为推荐过程。预测过程是预测用户对没有购买过的物品的可能打分值,推荐是根据预测阶段的结果推荐用户最可能喜欢的一个或Top-N个物品。
二、User-based算法与Item-based算法对比
CF算法分为两大类,一类为基于memory的(Memory-based),另一类为基于Model的(Model-based),User-based和Item-based算法均属于Memory-based类型,具体细分类可以参考wikipedia的说明。
User-based的基本思想是如果用户A喜欢物品a,用户B喜欢物品a、b、c,用户C喜欢a和c,那么认为用户A与用户B和C相似,因为他们都喜欢a,而喜欢a的用户同时也喜欢c,所以把c推荐给用户A。该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。
User-based算法存在两个重大问题:
1. 数据稀疏性。一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
2. 算法扩展性。最近邻居算法的计算量随着用户和物品数量的增加而增加,不适合数据量大的情况使用。
Iterm-based的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。还是以之前的例子为例,可以知道物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。
因为物品直接的相似性相对比较固定,所以可以预先在线下计算好不同物品之间的相似度,把结果存在表中,当推荐时进行查表,计算用户可能的打分值,可以同时解决上面两个问题。
三、Item-based算法详细过程
1、相似度计算
Item-based算法首选计算物品之间的相似度,计算相似度的方法有以下几种:
1. 基于余弦(Cosine-based)的相似度计算,通过计算两个向量之间的夹角余弦值来计算物品之间的相似性,公式如下:
其中分子为两个向量的内积,即两个向量相同位置的数字相乘。
2. 基于关联(Correlation-based)的相似度计算,计算两个向量之间的Pearson-r关联度,公式如下:
其中表示用户u对物品i的打分,表示第i个物品打分的平均值。
3. 调整的余弦(Adjusted Cosine)相似度计算,由于基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给高分,而有的用户偏向于给低分,该方法通过减去用户打分的平均值消除不同用户打分习惯的影响,公式如下:
其中表示用户u打分的平均值。
2、预测值计算
根据之前算好的物品之间的相似度,接下来对用户未打分的物品进行预测,有两种预测方法:
(1)加权求和
用过对用户u已打分的物品的分数进行加权求和,权值为各个物品与物品i的相似度,然后对所有物品相似度的和求平均,计算得到用户u对物品i打分,公式如下:
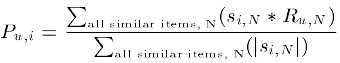
其中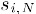 为物品i与物品N的相似度,为用户u对物品N的打分。
为物品i与物品N的相似度,为用户u对物品N的打分。
物品i与物品n(n从1开始)的相似度*用户u对物品n的打分,累计加和;除以物品i与物品n的相似度加和。
(2)回归
和上面加权求和的方法类似,但回归的方法不直接使用相似物品N的打分值,因为用余弦法或Pearson关联法计算相似度时存在一个误区,即两个打分向量可能相距比较远(欧氏距离),但有可能有很高的相似度。因为不同用户的打分习惯不同,有的偏向打高分,有的偏向打低分。如果两个用户都喜欢一样的物品,因为打分习惯不同,他们的欧式距离可能比较远,但他们应该有较高的相似度。在这种情况下用户原始的相似物品的打分值进行计算会造成糟糕的预测结果。通过用线性回归的方式重新估算一个新的值,运用上面同样的方法进行预测。重新计算的方法如下:
其中物品N是物品i的相似物品,和通过对物品N和i的打分向量进行线性回归计算得到,为回归模型的误差。具体怎么进行线性回归文章里面没有说明,需要查阅另外的相关文献。
四、结论
通过实验对比结果得出结论:1. Item-based算法的预测结果比User-based算法的质量要高一点。2. 由于Item-based算法可以预先计算好物品的相似度,所以在线的预测性能要比User-based算法的高。3. 用物品的一个小部分子集也可以得到高质量的预测结果。
转载请注明出处,原文地址:https://blog.csdn.net/yimingsilence/article/details/54934302
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/149161.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
