大家好,又见面了,我是你们的朋友全栈君。
激活函数是用来加入非线性因素的,解决线性模型所不能解决的问题
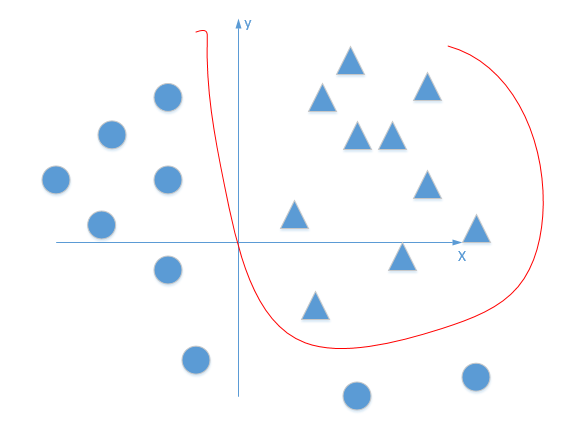
首先我们有这个需求,就是二分类问题,如我要将下面的三角形和圆形点进行正确的分类,如下图:

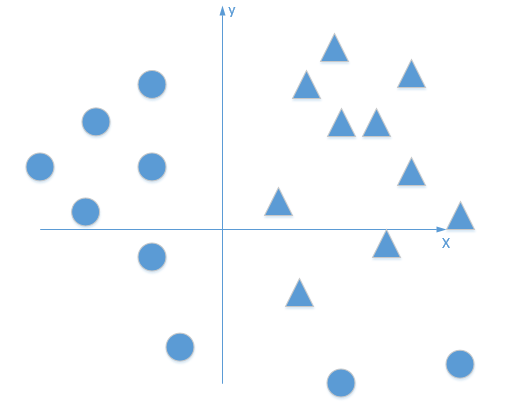
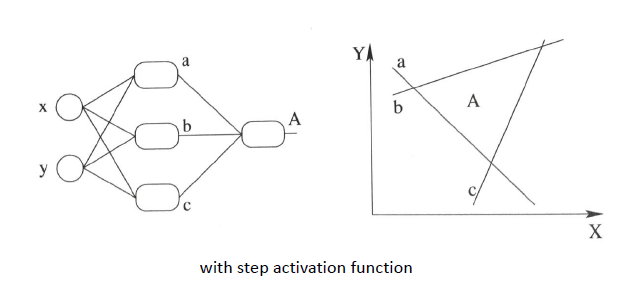
利用我们单层的感知机, 用它可以划出一条线, 把平面分割开:
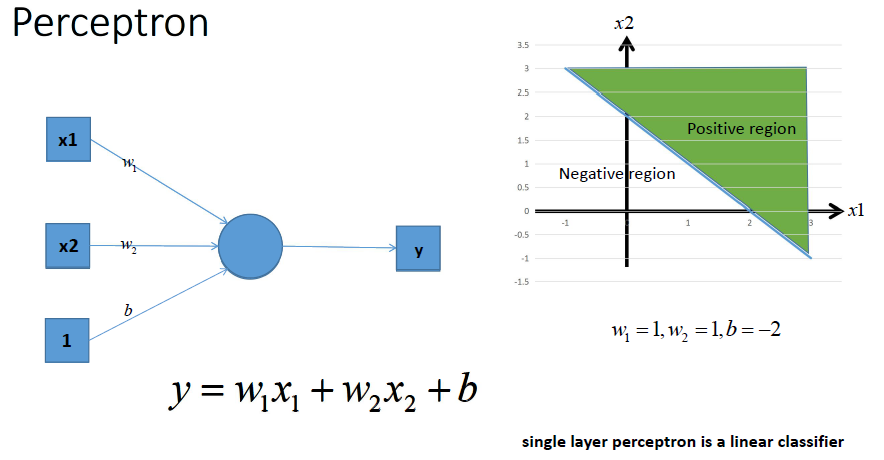
上图直线是由得到,那么该感知器实现预测的功能步骤如下,就是我已经训练好了一个感知器模型,后面对于要预测的样本点,带入模型中,如果y>0,那么就说明是直线的右侧,也就是正类(我们这里是三角形),如果,那么就说明是直线的左侧,也就是负类(我们这里是圆形),虽然这和我们的题目关系不大,但是还是提一下~
好吧,很容易能够看出,我给出的样本点根本不是线性可分的,一个感知器无论得到的直线怎么动,都不可能完全正确的将三角形与圆形区分出来,那么我们很容易想到用多个感知器来进行组合,以便获得更大的分类问题,好的,下面我们上图,看是否可行:
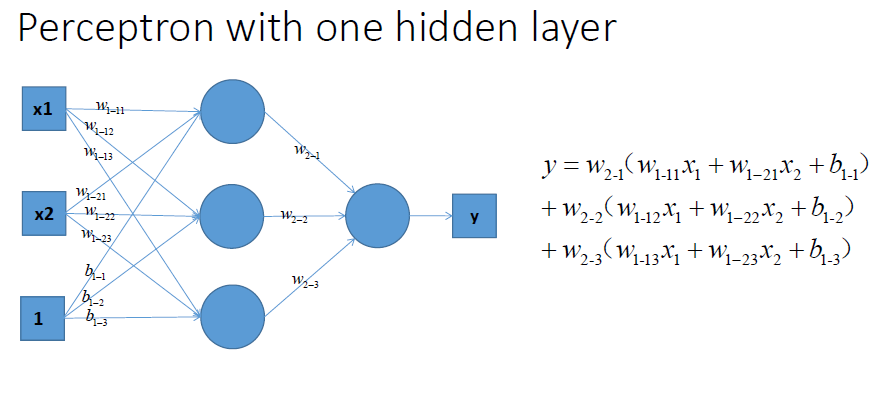
好的,我们已经得到了多感知器分类器了,那么它的分类能力是否强大到能将非线性数据点正确分类开呢~我们来分析一下:
我们能够得到
哎呀呀,不得了,这个式子看起来非常复杂,估计应该可以处理我上面的情况了吧,哈哈哈哈~不一定额,我们来给它变个形.上面公式合并同类项后等价于下面公式:
啧啧,估计大家都看出了,不管它怎么组合,最多就是线性方程的组合,最后得到的分类器本质还是一个线性方程,该处理不了的非线性问题,它还是处理不了。
就好像下图,直线无论在平面上如果旋转,都不可能完全正确的分开三角形和圆形点:
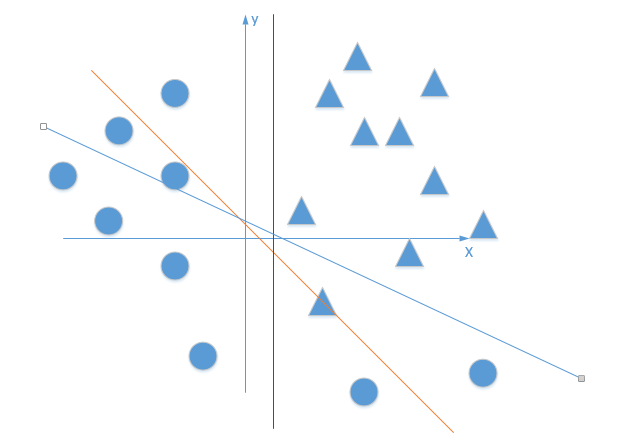
既然是非线性问题,总有线性方程不能正确分类的地方~
那么抛开神经网络中神经元需不需要激活函数这点不说,如果没有激活函数,仅仅是线性函数的组合解决的问题太有限了,碰到非线性问题就束手无策了.那么加入激活函数是否可能能够解决呢?
在上面线性方程的组合过程中,我们其实类似在做三条直线的组合,如下图:
下面我们来讲一下激活函数,我们都知道,每一层叠加完了之后,我们需要加入一个激活函数(激活函数的种类也很多,如sigmod等等~)这里就给出sigmod例子,如下图:
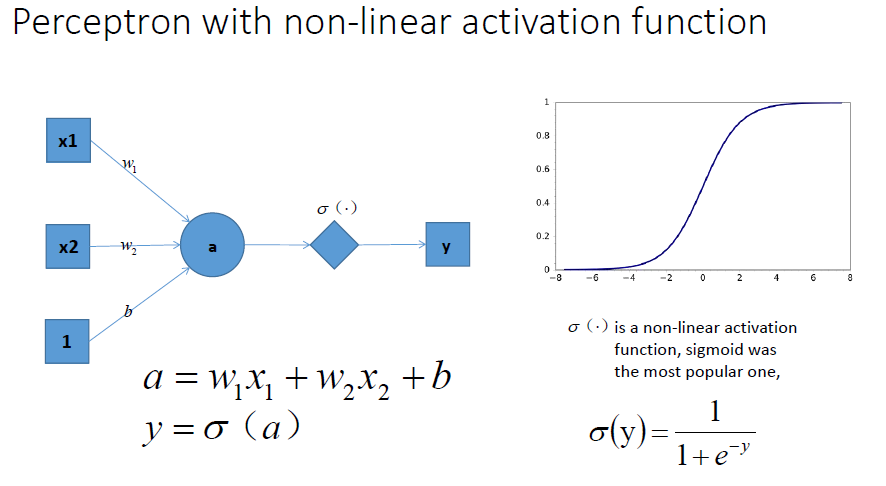
通过这个激活函数映射之后,输出很明显就是一个非线性函数!能不能解决一开始的非线性分类问题不清楚,但是至少说明有可能啊,上面不加入激活函数神经网络压根就不可能解决这个问题~
同理,扩展到多个神经元组合的情况时候,表达能力就会更强~对应的组合图如下:(现在已经升级为三个非线性感知器在组合了)

跟上面线性组合相对应的非线性组合如下:
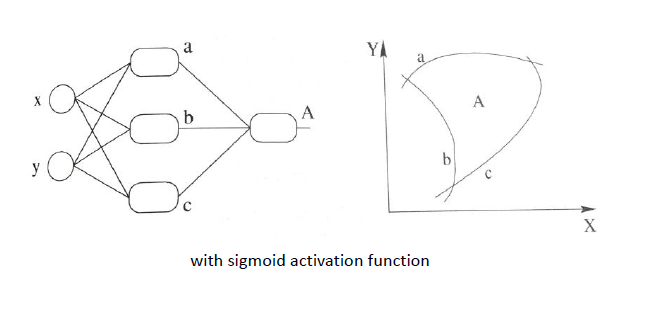
这看起来厉害多了,是不是~最后再通过最优化损失函数的做法,我们能够学习到不断学习靠近能够正确分类三角形和圆形点的曲线,到底会学到什么曲线,不知道到底具体的样子,也许是下面这个~
那么随着不断训练优化,我们也就能够解决非线性的问题了
1.为何引入非线性的激活函数?
如果不用激活函数,在这种情况下每一层输出都是上层输入的线性函数。容易验证,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。因此引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
2.引入ReLu的原因
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现 梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,ReLu会使一部分神经元的输出为0,这样就造成了 网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/147956.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
