大家好,又见面了,我是你们的朋友全栈君。
憨批的语义分割重制版6——Pytorch 搭建自己的Unet语义分割平台
注意事项
这是重新构建了的Unet语义分割网络,主要是文件框架上的构建,还有代码的实现,和之前的语义分割网络相比,更加完整也更清晰一些。建议还是学习这个版本的Unet。
学习前言
还是快乐的pytorch人。


什么是Unet模型
Unet是一个优秀的语义分割模型,其主要执行过程与其它语义分割模型类似。
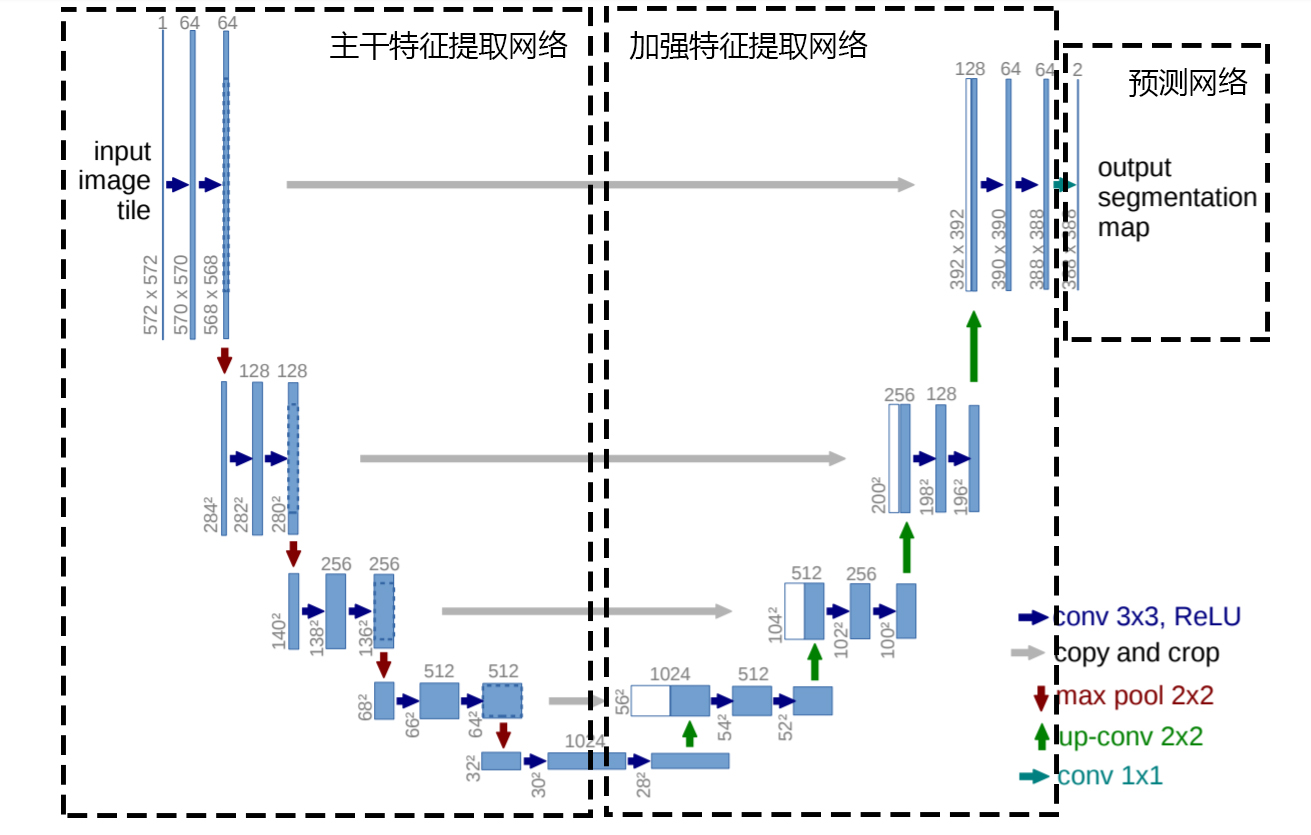
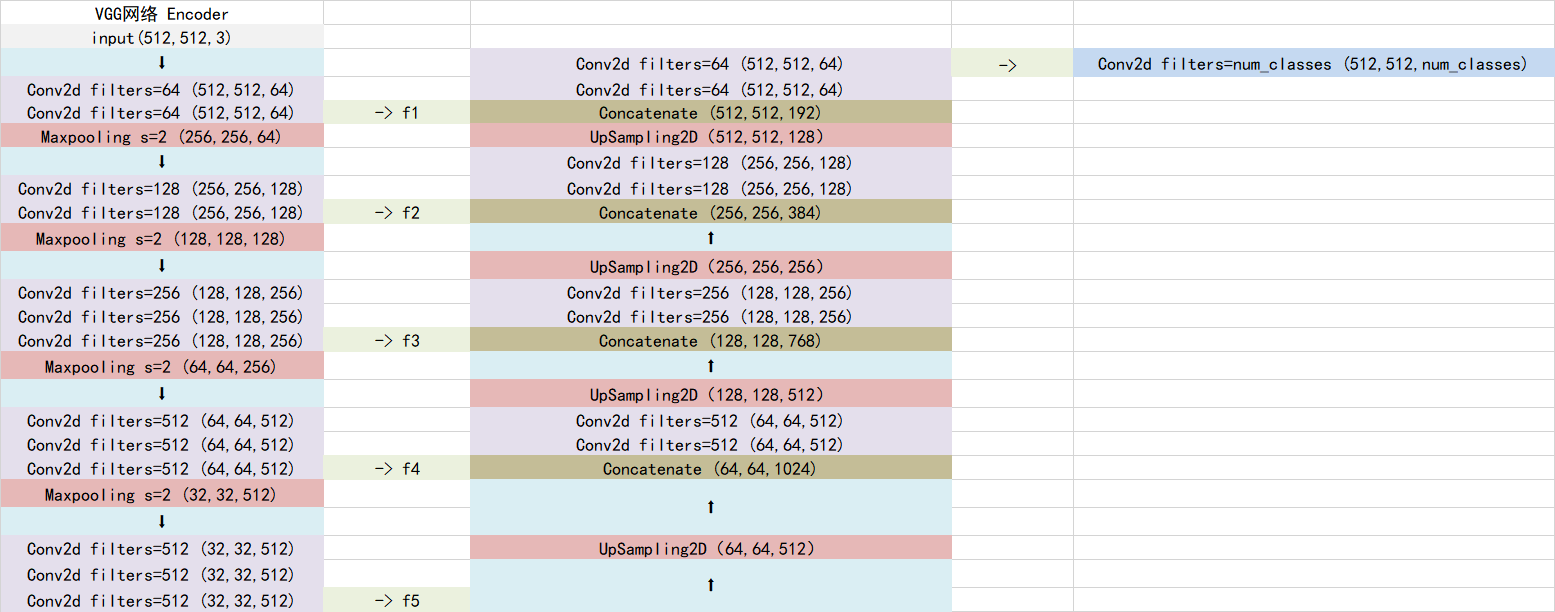
Unet可以分为三个部分,如下图所示:
第一部分是主干特征提取部分,我们可以利用主干部分获得一个又一个的特征层,Unet的主干特征提取部分与VGG相似,为卷积和最大池化的堆叠。利用主干特征提取部分我们可以获得五个初步有效特征层,在第二步中,我们会利用这五个有效特征层可以进行特征融合。
第二部分是加强特征提取部分,我们可以利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合,获得一个最终的,融合了所有特征的有效特征层。
第三部分是预测部分,我们会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。
代码下载
Github源码下载地址为:
https://github.com/bubbliiiing/unet-pytorch
Unet实现思路
一、预测部分
1、主干网络介绍
Unet的主干特征提取部分由卷积+最大池化组成,整体结构与VGG类似。
本文所采用的主干特征提取网络为VGG16,这样也方便使用imagnet上的预训练权重。
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
它的结构如下图所示:
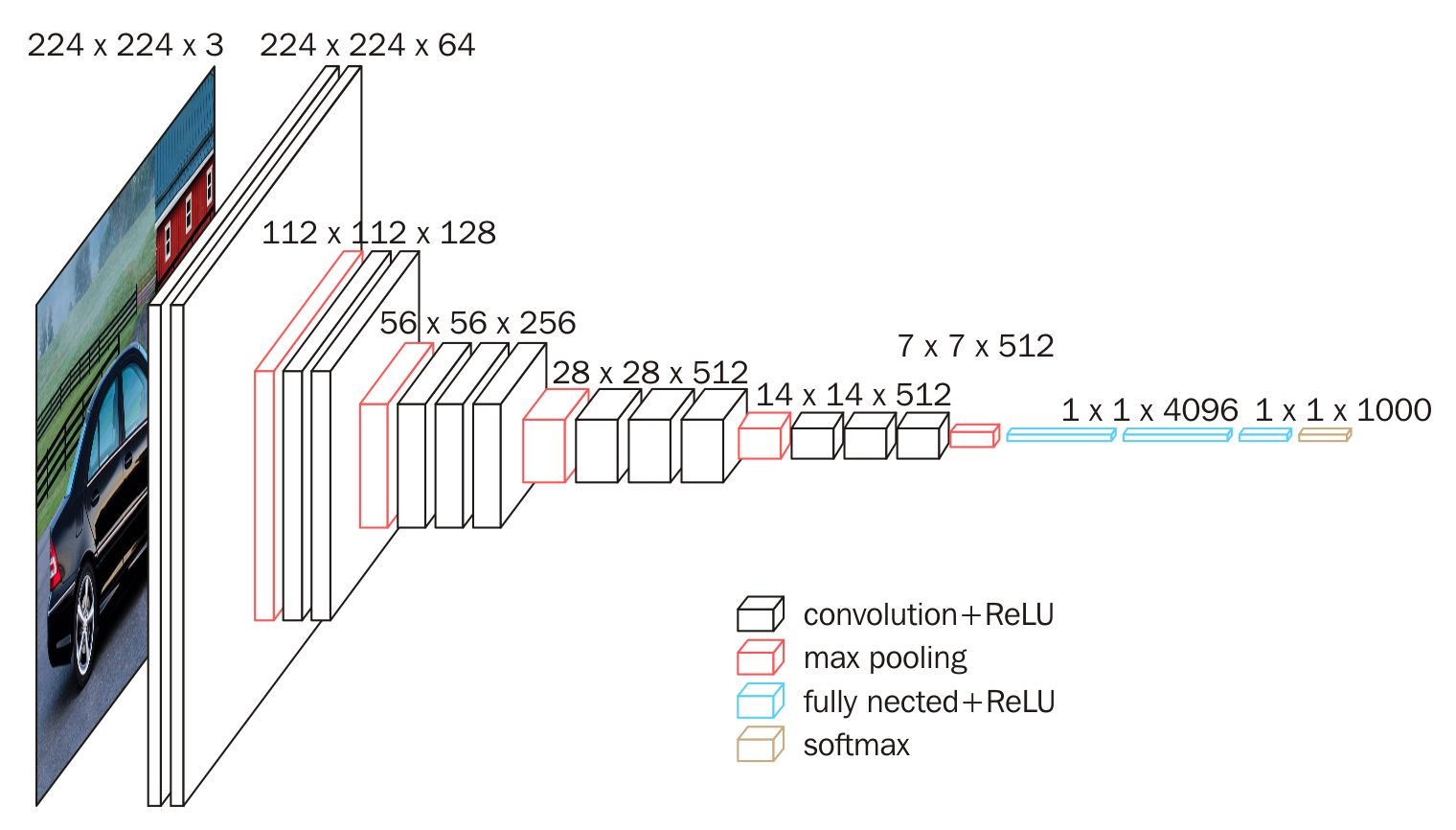
这是一个VGG16被用到烂的图,但确实很好的反应了VGG16的结构。
当我们使用VGG16作为主干特征提取网络的时候,我们只会用到两种类型的层,分别是卷积层和最大池化层。
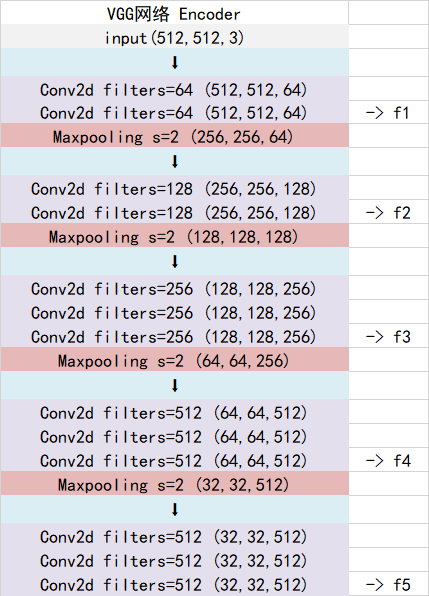
当输入的图像大小为512x512x3的时候,具体执行方式如下:
1、conv1:进行两次[3,3]的64通道的卷积,获得一个[512,512,64]的初步有效特征层,再进行2X2最大池化,获得一个[256,256,64]的特征层。
2、conv2:进行两次[3,3]的128通道的卷积,获得一个[256,256,128]的初步有效特征层,再进行2X2最大池化,获得一个[128,128,128]的特征层。
3、conv3:进行三次[3,3]的256通道的卷积,获得一个[128,128,256]的初步有效特征层,再进行2X2最大池化,获得一个[64,64,256]的特征层。
4、conv4:进行三次[3,3]的512通道的卷积,获得一个[64,64,512]的初步有效特征层,再进行2X2最大池化,获得一个[32,32,512]的特征层。
5、conv5:进行三次[3,3]的512通道的卷积,获得一个[32,32,512]的初步有效特征层。
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
class VGG(nn.Module):
def __init__(self, features, num_classes=1000):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg, batch_norm=False, in_channels = 3):
layers = []
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
}
def VGG16(pretrained, in_channels, **kwargs):
model = VGG(make_layers(cfgs["D"], batch_norm = False, in_channels = in_channels), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url("https://download.pytorch.org/models/vgg16-397923af.pth", model_dir="./model_data")
model.load_state_dict(state_dict)
del model.avgpool
del model.classifier
return model
2、加强特征提取结构
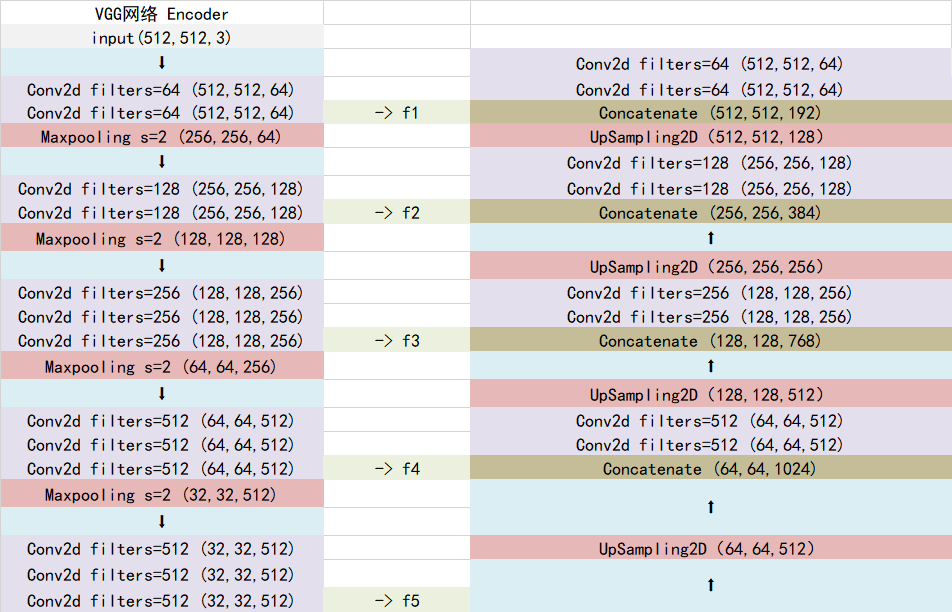
Unet所使用的加强特征提取网络是一个U的形状。
利用第一步我们可以获得五个初步的有效特征层,在加强特征提取网络这里,我们会利用这五个初步的有效特征层进行特征融合,特征融合的方式就是对特征层进行上采样并且进行堆叠。
为了方便网络的构建与更好的通用性,我们的Unet和上图的Unet结构有些许不同,在上采样时直接进行两倍上采样再进行特征融合,最终获得的特征层和输入图片的高宽相同。
具体示意图如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from nets.vgg import VGG16
class unetUp(nn.Module):
def __init__(self, in_size, out_size):
super(unetUp, self).__init__()
self.conv1 = nn.Conv2d(in_size, out_size, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_size, out_size, kernel_size=3, padding=1)
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, inputs1, inputs2):
outputs = torch.cat([inputs1, self.up(inputs2)], 1)
outputs = self.conv1(outputs)
outputs = self.conv2(outputs)
return outputs
class Unet(nn.Module):
def __init__(self, num_classes=21, in_channels=3, pretrained=False):
super(Unet, self).__init__()
self.vgg = VGG16(pretrained=pretrained,in_channels=in_channels)
in_filters = [192, 384, 768, 1024]
out_filters = [64, 128, 256, 512]
# upsampling
self.up_concat4 = unetUp(in_filters[3], out_filters[3])
self.up_concat3 = unetUp(in_filters[2], out_filters[2])
self.up_concat2 = unetUp(in_filters[1], out_filters[1])
self.up_concat1 = unetUp(in_filters[0], out_filters[0])
# final conv (without any concat)
self.final = nn.Conv2d(out_filters[0], num_classes, 1)
def forward(self, inputs):
feat1 = self.vgg.features[ :4 ](inputs)
feat2 = self.vgg.features[4 :9 ](feat1)
feat3 = self.vgg.features[9 :16](feat2)
feat4 = self.vgg.features[16:23](feat3)
feat5 = self.vgg.features[23:-1](feat4)
up4 = self.up_concat4(feat4, feat5)
up3 = self.up_concat3(feat3, up4)
up2 = self.up_concat2(feat2, up3)
up1 = self.up_concat1(feat1, up2)
final = self.final(up1)
return final
def _initialize_weights(self, *stages):
for modules in stages:
for module in modules.modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.fill_(1)
module.bias.data.zero_()
3、利用特征获得预测结果
利用1、2步,我们可以获取输入进来的图片的特征,此时,我们需要利用特征获得预测结果。
利用特征获得预测结果的过程为:
利用一个1×1卷积进行通道调整,将最终特征层的通道数调整成num_classes。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from nets.vgg import VGG16
class unetUp(nn.Module):
def __init__(self, in_size, out_size):
super(unetUp, self).__init__()
self.conv1 = nn.Conv2d(in_size, out_size, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_size, out_size, kernel_size=3, padding=1)
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, inputs1, inputs2):
outputs = torch.cat([inputs1, self.up(inputs2)], 1)
outputs = self.conv1(outputs)
outputs = self.conv2(outputs)
return outputs
class Unet(nn.Module):
def __init__(self, num_classes=21, in_channels=3, pretrained=False):
super(Unet, self).__init__()
self.vgg = VGG16(pretrained=pretrained,in_channels=in_channels)
in_filters = [192, 384, 768, 1024]
out_filters = [64, 128, 256, 512]
# upsampling
self.up_concat4 = unetUp(in_filters[3], out_filters[3])
self.up_concat3 = unetUp(in_filters[2], out_filters[2])
self.up_concat2 = unetUp(in_filters[1], out_filters[1])
self.up_concat1 = unetUp(in_filters[0], out_filters[0])
# final conv (without any concat)
self.final = nn.Conv2d(out_filters[0], num_classes, 1)
def forward(self, inputs):
feat1 = self.vgg.features[ :4 ](inputs)
feat2 = self.vgg.features[4 :9 ](feat1)
feat3 = self.vgg.features[9 :16](feat2)
feat4 = self.vgg.features[16:23](feat3)
feat5 = self.vgg.features[23:-1](feat4)
up4 = self.up_concat4(feat4, feat5)
up3 = self.up_concat3(feat3, up4)
up2 = self.up_concat2(feat2, up3)
up1 = self.up_concat1(feat1, up2)
final = self.final(up1)
return final
def _initialize_weights(self, *stages):
for modules in stages:
for module in modules.modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.fill_(1)
module.bias.data.zero_()
二、训练部分
1、训练文件详解
我们使用的训练文件采用VOC的格式。
语义分割模型训练的文件分为两部分。
第一部分是原图,像这样:

第二部分标签,像这样:

原图就是普通的RGB图像,标签就是灰度图或者8位彩色图。
原图的shape为[height, width, 3],标签的shape就是[height, width],对于标签而言,每个像素点的内容是一个数字,比如0、1、2、3、4、5……,代表这个像素点所属的类别。
语义分割的工作就是对原始的图片的每一个像素点进行分类,所以通过预测结果中每个像素点属于每个类别的概率与标签对比,可以对网络进行训练。
2、LOSS解析
本文所使用的LOSS由两部分组成:
1、Cross Entropy Loss。
2、Dice Loss。
Cross Entropy Loss就是普通的交叉熵损失,当语义分割平台利用Softmax对像素点进行分类的时候,进行使用。
Dice loss将语义分割的评价指标作为Loss,Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]。
计算公式如下:
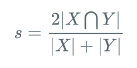
就是预测结果和真实结果的交乘上2,除上预测结果加上真实结果。其值在0-1之间。越大表示预测结果和真实结果重合度越大。所以Dice系数是越大越好。
如果作为LOSS的话是越小越好,所以使得Dice loss = 1 – Dice,就可以将Loss作为语义分割的损失了。
实现代码如下:
import torch
import torch.nn.functional as F
import numpy as np
from torch import nn
from torch.autograd import Variable
from random import shuffle
from matplotlib.colors import rgb_to_hsv, hsv_to_rgb
from PIL import Image
import cv2
def CE_Loss(inputs, target, num_classes=21):
n, c, h, w = inputs.size()
nt, ht, wt = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = inputs.transpose(1, 2).transpose(2, 3).contiguous().view(-1, c)
temp_target = target.view(-1)
CE_loss = nn.NLLLoss(ignore_index=num_classes)(F.log_softmax(temp_inputs, dim = -1), temp_target)
return CE_loss
def Dice_loss(inputs, target, beta=1, smooth = 1e-5):
n, c, h, w = inputs.size()
nt, ht, wt, ct = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = torch.softmax(inputs.transpose(1, 2).transpose(2, 3).contiguous().view(n, -1, c),-1)
temp_target = target.view(n, -1, ct)
#--------------------------------------------#
# 计算dice loss
#--------------------------------------------#
tp = torch.sum(temp_target[...,:-1] * temp_inputs, axis=[0,1])
fp = torch.sum(temp_inputs , axis=[0,1]) - tp
fn = torch.sum(temp_target[...,:-1] , axis=[0,1]) - tp
score = ((1 + beta ** 2) * tp + smooth) / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth)
dice_loss = 1 - torch.mean(score)
return dice_loss
训练自己的Unet模型
首先前往Github下载对应的仓库,下载完后利用解压软件解压,之后用编程软件打开文件夹。
注意打开的根目录必须正确,否则相对目录不正确的情况下,代码将无法运行。
一定要注意打开后的根目录是文件存放的目录。
一、数据集的准备
本文使用VOC格式进行训练,训练前需要自己制作好数据集,如果没有自己的数据集,可以通过Github连接下载VOC12+07的数据集尝试下。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的SegmentationClass中。

二、数据集的处理
在完成数据集的摆放之后,我们需要对数据集进行下一步的处理,目的是获得训练用的train.txt以及val.txt,需要用到根目录下的voc_annotation.py。
如果下载的是我上传的voc数据集,那么就不需要运行根目录下的voc_annotation.py。
如果是自己制作的数据集,那么需要运行根目录下的voc_annotation.py,从而生成train.txt和val.txt。
三、开始网络训练
通过voc_annotation.py我们已经生成了train.txt以及val.txt,此时我们可以开始训练了。训练的参数较多,大家可以在下载库后仔细看注释,其中最重要的部分依然是train.py里的num_classes。
num_classes用于指向检测类别的个数+1!训练自己的数据集必须要修改!
之后就可以开始训练了。
四、训练结果预测
训练结果预测需要用到两个文件,分别是unet.py和predict.py。
我们首先需要去unet.py里面修改model_path以及num_classes,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
num_classes指向检测类别的个数+1。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/147893.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
