大家好,又见面了,我是你们的朋友全栈君。
父子查询: 根据父 id 查询下面所有子节点数据;子父查询: 根据子 id 查询上面所有父节点数据;
————mysql递归查询
目录结构:
创建表,并添加测试数据
创建表
DROP TABLE IF EXISTS
vrv_org_tab;
CREATE TABLEvrv_org_tab(idbigint(8) NOT NULL AUTO_INCREMENT,org_namevarchar(50) NOT NULL,org_levelint(4) NOT NULL DEFAULT ‘0’,org_parent_idbigint(8) NOT NULL DEFAULT ‘0’,
PRIMARY KEY (id),
UNIQUE KEYunique_org_name(org_name)
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8;
添加数据
INSERT INTO
vrv_org_tabVALUES (‘1’, ‘北信源’, ‘1’, ‘0’);
INSERT INTOvrv_org_tabVALUES (‘2’, ‘北京’, ‘2’, ‘1’);
INSERT INTOvrv_org_tabVALUES (‘3’, ‘南京’, ‘2’, ‘1’);
INSERT INTOvrv_org_tabVALUES (‘4’, ‘武汉’, ‘2’, ‘1’);
INSERT INTOvrv_org_tabVALUES (‘5’, ‘上海’, ‘2’, ‘1’);
INSERT INTOvrv_org_tabVALUES (‘6’, ‘北京研发中心’, ‘3’, ‘2’);
INSERT INTOvrv_org_tabVALUES (‘7’, ‘南京研发中心’, ‘3’, ‘3’);
INSERT INTOvrv_org_tabVALUES (‘8’, ‘武汉研发中心’, ‘3’, ‘4’);
INSERT INTOvrv_org_tabVALUES (‘9’, ‘上海研发中心’, ‘3’, ‘5’);
INSERT INTOvrv_org_tabVALUES (‘10’, ‘北京EMM项目组’, ‘4’, ‘6’);
INSERT INTOvrv_org_tabVALUES (‘11’, ‘北京linkdd项目组’, ‘4’, ‘6’);
INSERT INTOvrv_org_tabVALUES (‘12’, ‘南京EMM项目组’, ‘4’, ‘7’);
INSERT INTOvrv_org_tabVALUES (‘13’, ‘南京linkdd项目组’, ‘4’, ‘7’);
INSERT INTOvrv_org_tabVALUES (‘14’, ‘武汉EMM项目组’, ‘4’, ‘8’);
INSERT INTOvrv_org_tabVALUES (‘15’, ‘武汉linkdd项目组’, ‘4’, ‘8’);
INSERT INTOvrv_org_tabVALUES (‘16’, ‘上海EMM项目组’, ‘4’, ‘9’);
INSERT INTOvrv_org_tabVALUES (‘17’, ‘上海linkdd项目组’, ‘4’, ‘9’);
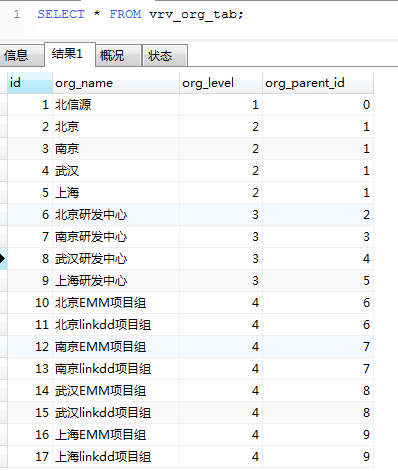
select * from vrv_org_tab;
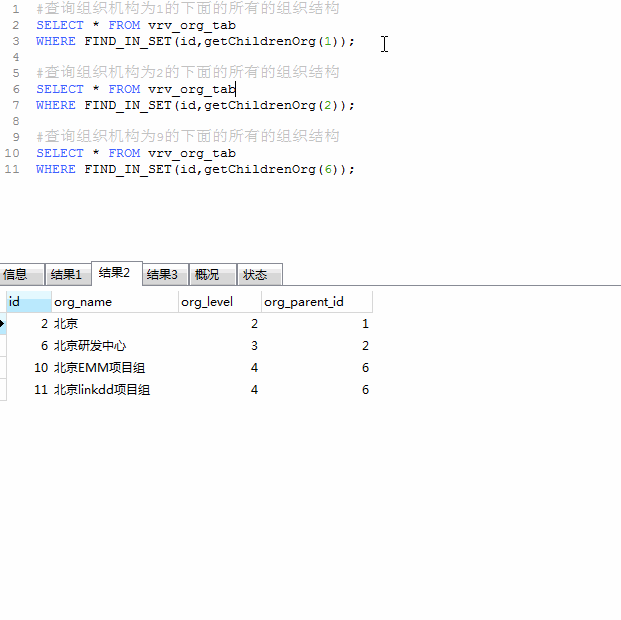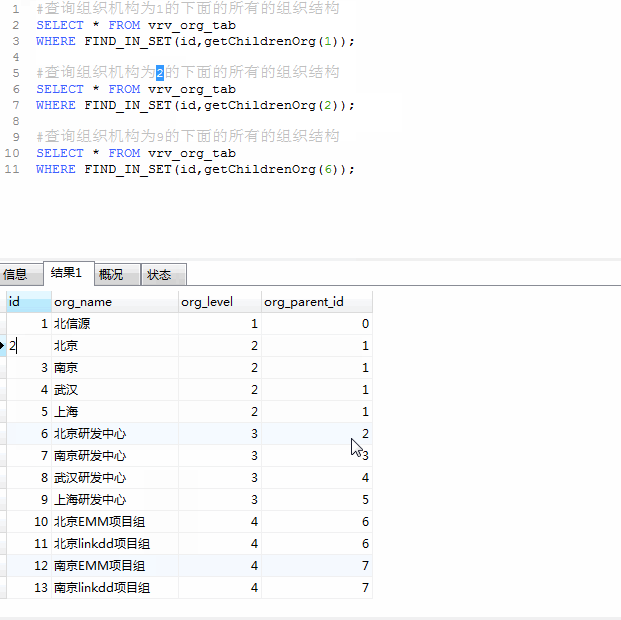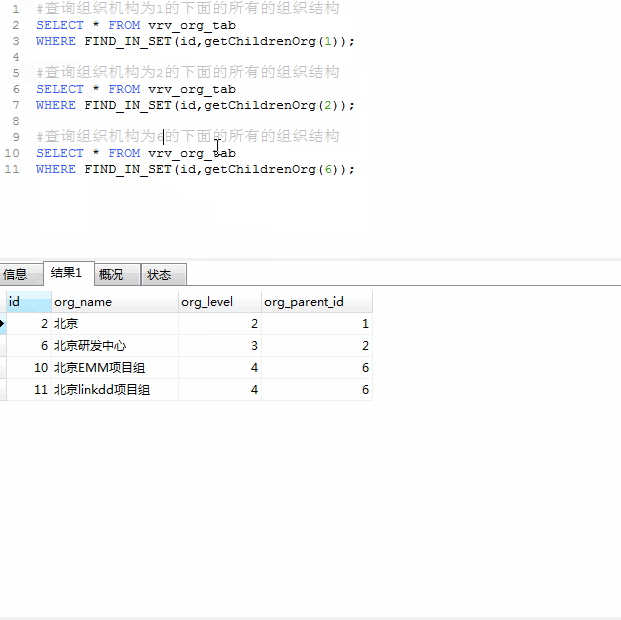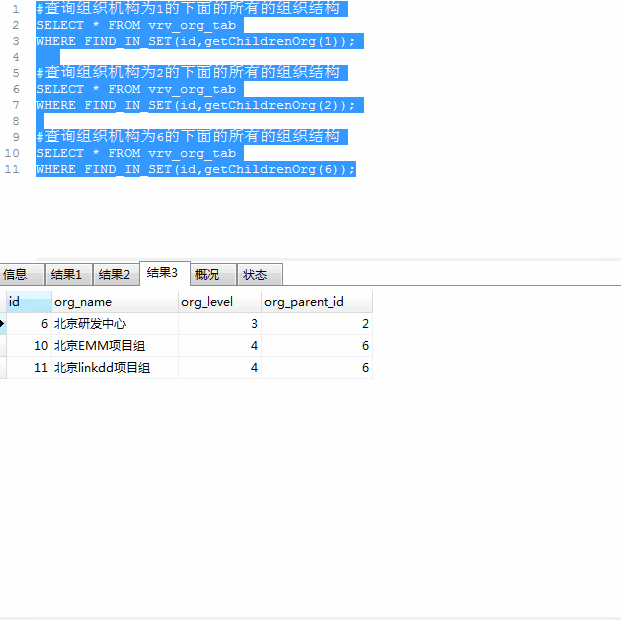
根据父id递归查询所有子节点
创建函数
create function getChildrenOrg(orgid INT)
returns varchar(4000)
BEGIN
DECLARE oTemp VARCHAR(4000);
DECLARE oTempChild VARCHAR(4000);
SET oTemp = '';
SET oTempChild = CAST(orgid AS CHAR);
WHILE oTempChild IS NOT NULL
DO
SET oTemp = CONCAT(oTemp,',',oTempChild);
SELECT GROUP_CONCAT(id) INTO oTempChild FROM vrv_org_tab WHERE FIND_IN_SET(org_parent_id,oTempChild) > 0;
END WHILE;
RETURN oTemp;
END根据函数查询
根据子id递归查询所有父节点
根据子id查询父节点就不那么麻烦了,不需要写递归函数,当然,你也可以写递归函数来查询。我这边提供的是不写函数的方式。请看代码
写sql语句
SELECT id,org_name,org_level,org_parent_id
FROM (
SELECT
@r AS _id,
(SELECT @r := org_parent_id FROM vrv_org_tab WHERE id = _id) AS parent_id,
@l := @l + 1 AS lvl
FROM
(SELECT @r := 10000, @l := 0) vars,
vrv_org_tab h
WHERE @r <> 0) T1
JOIN vrv_org_tab T2
ON T1._id = T2.id
ORDER BY id;注意:大家看到那个10000了吗,就是我们的子节点id。
注意:只支持单个查询,意思是不可以根据两个或者两个以上的子节点同时查询出所有父节点。我们可以看到,上面参数都是单个值进行递归查询的。
西面提供一个函数支持多个查询
根据组织机构名称模糊查询所有父节点
该功能常用于组织机构模糊搜索
创建函数
CREATE FUNCTION getParentOrgByOrgName(orgName VARCHAR(20))
RETURNS VARCHAR(4000)
BEGIN
DECLARE sPid VARCHAR(1000);
DECLARE sPidTemp VARCHAR(1000);
DECLARE pid VARCHAR(1000);
DECLARE count INT DEFAULT 0;
DECLARE allpid VARCHAR(4000);
SET sPidTemp = '';
SELECT GROUP_CONCAT(DISTINCT(CAST(id AS CHAR))) INTO sPid
FROM vrv_org_tab WHERE org_name LIKE CONCAT('%',orgName,'%');
SET allpid = '';
WHILE count = 0
DO
IF sPid IS NULL THEN
SET allpid = '-1';
SET count = 1;
ELSE
SET pid = SUBSTRING_INDEX(sPid,',',1);
SET sPidTemp = CONCAT(sPidTemp,',',pid);
IF LENGTH(pid) = LENGTH(sPid) THEN
SET count = 1;
SET sPid = SUBSTRING(sPid FROM LENGTH(SUBSTRING_INDEX(sPid,',',1)) FOR LENGTH(sPid)+1);
ELSE
SET sPid = SUBSTRING(sPid FROM LENGTH(SUBSTRING_INDEX(sPid,',',1))+2 FOR LENGTH(sPid)+1);
END IF;
SELECT GROUP_CONCAT(CAST(id AS CHAR)) INTO sPidTemp
FROM (
SELECT
@r AS _id,
(SELECT @r := org_parent_id FROM vrv_org_tab WHERE id = _id) AS parent_id,
@l := @l + 1 AS lvl
FROM
(SELECT @r := pid, @l := 0) vars,
vrv_org_tab h
WHERE @r <> 0) T1
JOIN vrv_org_tab T2
ON T1._id = T2.id;
SET allpid = CONCAT_WS(',',pid,sPidTemp,allpid);
END IF;
END WHILE;
RETURN allpid;
END根据函数查询
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/147649.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
