大家好,又见面了,我是你们的朋友全栈君。
Mnih, Andriy, and Ruslan Salakhutdinov. “Probabilistic matrix factorization.” Advances in neural information processing systems. 2007.
本篇论文发表于2007年NIPS。Ruslan Salakhutdinov来自多伦多大学,16年转入CMU。Andriy Mnih同样来自多伦多大学,师从Hinton。PMF算法(Probabilistic Matrix Factorization)是现代推荐系统的基础算法之一。
##问题描述
设有 N N N个用户, M M M部电影。一个评分系统可以用 N × M N\times M N×M矩阵 R R R来表示。
推荐系统问题如下: R R R矩阵中只有部分元素是已知的(用户只给一部分电影打过分),且 R R R往往非常稀疏,需要求出 R R R缺失的部分。
除了推荐系统,这个模型也可以用来描述任意“成对”作用的系统。例如:由若干球队组成的联赛,两支球队间的历史比分即为 R R R的已知元素,需要预测尚未进行的比赛结果。这里 R R R是一个方阵。
##基本思路
本文采取low-dimensional factor模型,也称为low rank模型来处理这个问题。其核心思想是:用户和电影之间的关系(即用户对电影的偏好)可以由较少的几个因素的线性组合决定。
例子
用户是否喜欢一部电影取决于三个因素:是娱乐片还是文艺片,是外文片还是华语片,演员是否出名。
用三维向量$x=[0.6, 1.0, -0.2]^T 来 描 述 一 个 用 户 ( 假 设 取 值 在 [ − 1 , 1 ] 之 间 ) : 他 比 较 喜 欢 娱 乐 片 , 只 看 外 文 片 , 对 演 员 要 求 一 般 , 小 众 一 点 更 好 。 对 于 一 部 电 影 , 用 另 一 个 三 维 向 量 来 描 述 来描述一个用户(假设取值在[-1,1]之间):他比较喜欢娱乐片,只看外文片,对演员要求一般,小众一点更好。 对于一部电影,用另一个三维向量来描述 来描述一个用户(假设取值在[−1,1]之间):他比较喜欢娱乐片,只看外文片,对演员要求一般,小众一点更好。对于一部电影,用另一个三维向量来描述y=[0.9, -1.0, 0.8]^T $:这是一部众星云集的-国产-娱乐大作。
可以算出这个用户对于这部电影的喜好程度 r = x T y = − 2.06 r=x^T y =-2.06 r=xTy=−2.06 :相当不喜欢。
用矩阵语言来描述,就是评分矩阵可以分解为两个低维矩阵的乘积 R = U T V R=U^T V R=UTV,其中 D × N D\times N D×N矩阵 U U U描述 N N N个用户的属性, D × M D\times M D×M矩阵 V V V描述 M M M部电影的属性。
根据矩阵秩的性质, R R R的秩不超过 U , V U,V U,V的最小尺寸 D D D。
实际上,由于系统噪音存在,不可能做出这样的完美分解,另外 R R R包含很多未知元素。所以问题转化为:
- 对一个近似矩阵进行分解 R ^ = U T V \hat R=U^TV R^=UTV
- 要求近似矩阵 R ^ \hat R R^在观测到的评分部分和观测矩阵 R R R尽量相似
- 为了防止过拟合,需要对 U , V U,V U,V做某种形式的约束
用贝叶斯观点来说, R R R是观测到的值, U , V U,V U,V描述了系统的内部特征,是需要估计的。
##基础PMF模型
使用如下两个假设
- 观测噪声(观测评分矩阵 R R R和近似评分矩阵 R ^ \hat R R^之差)为高斯分布
- 用户属性 U U U和电影属性 V V V均为高斯分布
利用第一个假设,可以写出完整观测矩阵的概率密度函数。其中 σ \sigma σ是观测噪声的方差,人工设定。
p ( R ∣ U , V ) = N ( R ^ , σ 2 ) = N ( U T V , σ 2 ) p(R|U,V )=N(\hat R,\sigma ^2 )=N(U^TV,\sigma ^2) p(R∣U,V)=N(R^,σ2)=N(UTV,σ2)
利用第二个假设,可以写出用户、电影属性的概率密度函数。其中 σ U , σ V \sigma_U, \sigma_V σU,σV是先验噪声的方差,人工设定。
p ( U ) = N ( 0 , σ U 2 ) , p ( V ) = N ( 0 , σ V 2 ) p(U)=N(0,\sigma_U ^2), p(V )=N(0,\sigma_V ^2) p(U)=N(0,σU2),p(V)=N(0,σV2)
综合以上两个概率密度函数,利用经典的后验概率推导,可以得到
p ( U , V ∣ R ) = p ( U , V , R ) / p ( R ) ∝ p ( U , V , R ) = p ( R ∣ U , V ) p ( U ) p ( V ) p(U,V|R)=p(U,V,R)/p(R)\propto p(U,V,R)=p(R|U,V)p(U)p(V) p(U,V∣R)=p(U,V,R)/p(R)∝p(U,V,R)=p(R∣U,V)p(U)p(V)
##基础PMF求解
最大化上述概率,则可以通过已有的观测矩阵 R R R估计出系统参数 U , V U,V U,V。
为了计算方便,对后验概率取对数
ln p ( U , V ∣ R ) = ln p ( R ∣ U , V ) + ln p ( U ) + ln p ( V ) \ln p(U,V|R)=\ln p(R|U,V) + \ln p(U) + \ln p(V) lnp(U,V∣R)=lnp(R∣U,V)+lnp(U)+lnp(V)
高斯分布公式及其对数形式:
p ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) p(x)=\frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) p(x)=2πσ1exp(−2σ2(x−μ)2)ln p ( x ) = − ln ( 2 π σ ) − ( x − μ ) 2 2 σ 2 \ln p(x)=-\ln (\sqrt{2\pi}\sigma) – \frac{(x-\mu)^2}{2\sigma^2} lnp(x)=−ln(2πσ)−2σ2(x−μ)2
由于后验概率中的方差都是预设常数,故只有第二项和待优化的 U , V U,V U,V有关。
最大化上述对数后验概率,等价于最小化如下能量函数:
E ( U , V ) = ( R − U T V ) 2 2 σ 2 + U T U 2 2 σ U 2 + V T V 2 2 σ V 2 E(U,V)=\frac{(R-U^TV)^2}{2\sigma^2}+\frac{U^TU^2}{2\sigma_U^2} + \frac{V^TV^2}{2\sigma_V^2} E(U,V)=2σ2(R−UTV)2+2σU2UTU2+2σV2VTV2
做参数替换约掉一个变量:
E ( U , V ) = 1 2 ( R − U T V ) 2 + λ U 2 U T U 2 + λ V 2 V T V 2 E(U,V)=\frac{1}{2}(R-U^TV)^2+\frac{\lambda_U}{2}U^TU^2 + \frac{\lambda_V}{2}V^TV^2 E(U,V)=21(R−UTV)2+2λUUTU2+2λVVTV2
如果系统先验方差 σ U , σ V \sigma_U,\sigma_V σU,σV无穷大(即无法对系统参数做约束),则上式只剩第一项,退化为一个SVD分解问题。
刚才的几步推导中,为了书写简便实际上做了一些省略:矩阵的概率密度应该等于其元素概率密度的乘积。取对数之后,即等于其元素概率密度的和。
E ( U , V ) = 1 2 ∑ i j I i j ( R i j − U i T V j ) 2 + λ U 2 ∑ i U i T U i 2 + λ V 2 ∑ j V j T V j 2 E(U,V)=\frac{1}{2}\sum_{ij}I_{ij}(R_{ij}-U_i^TV_j)^2+\frac{\lambda_U}{2}\sum_iU_i^TU_i^2 + \frac{\lambda_V}{2}\sum_jV_j^TV_j^2 E(U,V)=21ij∑Iij(Rij−UiTVj)2+2λUi∑UiTUi2+2λVj∑VjTVj2其中 R i j R_{ij} Rij是标量, U i , V j U_i,V_j Ui,Vj都是维度为D的向量。后两项相当于约束了内部特征矩阵 U , V U,V U,V的范数。标记 I i j I_{ij} Iij表示用户i是否对电影j评分。
最后,为了限制评分的范围,对高斯函数的均值施加logistic函数 g ( x ) = 1 / ( 1 + exp ( − x ) ) g(x)=1/(1+\exp (-x)) g(x)=1/(1+exp(−x)),其取值在(0,1)之间。最终的能量函数是:
E ( U , V ) = 1 2 ∑ i j I i j ( R i j − g ( U i T V j ) ) 2 + λ U 2 ∑ i U i T U i 2 + λ V 2 ∑ j V j T V j 2 E(U,V)=\frac{1}{2}\sum_{ij}I_{ij}(R_{ij}-g(U_i^TV_j))^2+\frac{\lambda_U}{2}\sum_iU_i^TU_i^2 + \frac{\lambda_V}{2}\sum_jV_j^TV_j^2 E(U,V)=21ij∑Iij(Rij−g(UiTVj))2+2λUi∑UiTUi2+2λVj∑VjTVj2
至此,可以使用梯度下降方法,通过 ∂ E / ∂ U i k , ∂ E / ∂ V j k \partial {E}/\partial {U_{ik}}, \partial {E}/\partial {V_{jk}} ∂E/∂Uik,∂E/∂Vjk求解 U i , V j U_i, V_j Ui,Vj中的每一个元素。
需要估计的参数数量为 M × D + N × D M\times D + N\times D M×D+N×D。对于每一个参数,由于能量函数第一项只在有观测时需要计算,所以所需时间相对于观测数量为线性(?)。
性能
1998年至2005年Netflix数据,设定D=30,使用Matlab,在30分钟内完成训练。
控制模型复杂度
最简单的控制复杂度的方法是调整特征维度: D D D约大,模型越精确,但也越容易过拟合。 D D D应该和用户的打分数量相关:如果用户看过的电影多,则可以用较多特征来描述,可以使用较大的D。
但实际数据往往是不均衡的:电影爱好者给出的打分很多,而很多用户只会给一两部电影打分。
较好的方法是选择一个中等尺度的 D D D,之后调整 λ U = σ / σ U , λ V = σ / σ V \lambda_U=\sigma / \sigma_U, \lambda_V=\sigma / \sigma_V λU=σ/σU,λV=σ/σV。
σ \sigma σ大说明观测噪声大,则第一个误差项不靠谱, λ U \lambda_U λU较大,应较多依赖后两个正则项:要求系统参数 U , V U,V U,V的绝对值较小;反之, σ U \sigma_U σU大,说明系统参数本身方差大, λ U \lambda_U λU较小,允许 U , V U,V U,V的绝对值较大
##带有自适应先验的PMF
先验的超参数(hyperparameter): Θ U , Θ V \Theta_U, \Theta_V ΘU,ΘV可以从训练样本中估计。这两个 Θ \Theta Θ和前述 λ \lambda λ类似。
ln p ( U , V , Θ U , Θ V ∣ R ) = ln p ( R ∣ U , V ) + ln p ( U ∣ Θ U ) + ln p ( V ∣ Θ V ) + ln p ( Θ U ) + ln p ( Θ V ) \ln p(U,V,\Theta_U,\Theta_V|R)=\ln p(R|U,V) + \ln p(U|\Theta_U) + \ln p(V|\Theta_V)+\ln p(\Theta_U)+\ln p(\Theta_V) lnp(U,V,ΘU,ΘV∣R)=lnp(R∣U,V)+lnp(U∣ΘU)+lnp(V∣ΘV)+lnp(ΘU)+lnp(ΘV)
类似地,可以给 Θ U , Θ V \Theta_U,\Theta_V ΘU,ΘV设定先验,轮流对参数和超参数使用梯度下降或者EM算法更新。
##限制性PMF
“用户是否给某部电影打过分”这个信息本身就能一定程度上说明用户的属性。Constrained PMF尝试把 I i j I_{ij} Iij引入到模型中去。这也是本文的创新之处。
用 M × D M\times D M×D矩阵 W W W表述电影对用户的影响。其中第k行 W k W_k Wk表示,如果用户看过第k部电影,则用户应该具有属性 W k W_k Wk。
用户属性U由两部分组成:和之前相同的高斯部分 Y Y Y,以及 W W W用“看过”矩阵 I I I加权的结果。
U i = Y i + 1 ∑ k I i k ∑ k I i k W k U_i = Y_i + \frac{1}{\sum_kI_{ik}}\sum_kI_{ik}W_k Ui=Yi+∑kIik1k∑IikWk
其中 W W W服从方差为 σ W \sigma_W σW的0均值高斯分布。
在已知 R R R的情况下,同样用梯度下降方法可以求解 U , V , W U,V,W U,V,W。
下图用概率图模型表示基础PMF(左)和限定性PMF(右):
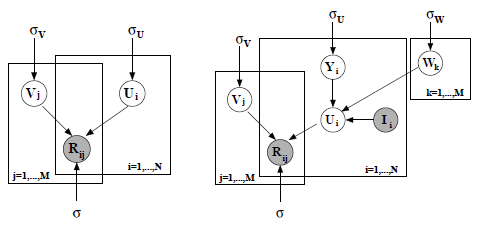

##实验
涉及的数据集如下
数据集 | 打分 | 用户 | 电影
——– | —
Netflix Train | 100,480K | 480K | 17K
Netflix Valid | 1,408K | – | –
Netflix Test | 2,817K | – | –
为了提高训练速度,采用了mini-batche方法:每100K个观测(用户给某部电影打分),更新一次待求参数。learning rate = 0.005, momentum = 0.9。
梯度下降的learning rate和momentum参见这个链接
简而言之,学习率决定每一步大小,动量避免曲折过于严重。
可以看出限定性PMF比基础PMF的优越性
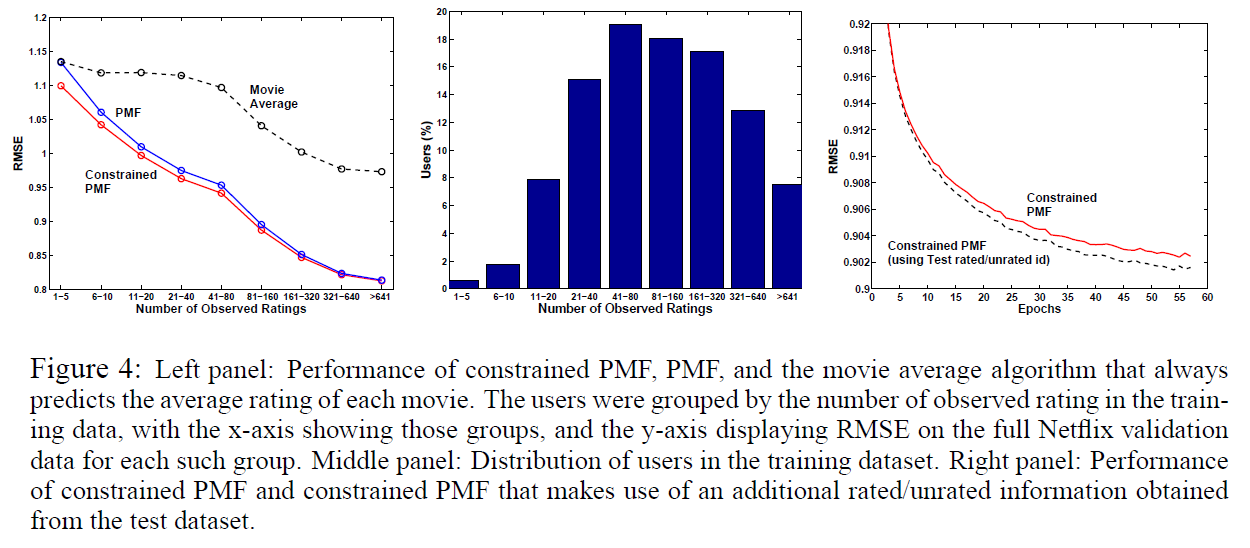
扩展
第6章总结中提到: Efficiency in training PMF models comes from finding only point estimates of model parameters and hyperparameters, instead of inferring the full posterior distribution over them.
这里的point estimation指的是只估计了 U , V , λ U , λ V U,V,\lambda_U,\lambda_V U,V,λU,λV的一个值,而没有估计它们的概率分布,所以大大提高了速度。但是其缺点是容易过拟合。
与之相对的,还可以使用贝叶斯估计,把系统参数当成一个随机变量。具体可以参看这篇博客:贝叶斯PMF,介绍同作者的这篇论文:
Salakhutdinov, Ruslan, and A. Mnih. “Bayesian probabilistic matrix factorization using markov chain monte carlo.” International Conference on Machine Learning 2008:880-887.
另外,如果需要考虑一些明确的从属信息,例如评分的用户身份、评分发生的时间等,可以参看这篇博客:DPMF,介绍这篇论文:
Adams, Ryan Prescott, George E. Dahl, and Iain Murray. “Incorporating side information in probabilistic matrix factorization with gaussian processes.” arXiv preprint arXiv:1003.4944 (2010).
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/147543.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
