大家好,又见面了,我是你们的朋友全栈君。
虽然上文有提到怎么解释的开放地址法处理hash冲突,但是当时只是给了个简单的图,没有 详细讲解一下,
我当时有点不明白,回头查查资料,然后亲自动手,整理了一下。
然后我就三幅图详细讲解一下:
什么叫线性探测再散列;
什么叫平方探测再散列(二次探测再散列);
 老师的ppt吧。
老师的ppt吧。
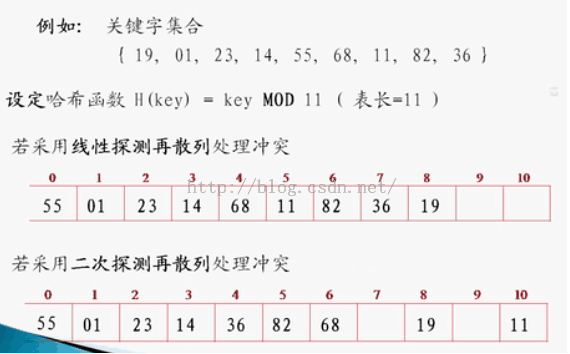
给个原始数据如上图。
下面详细解析。

上面的是线性探测再散列。这个简单。

这个就是那个2次平方再散列啦。
估计讲的很详细啦吧。
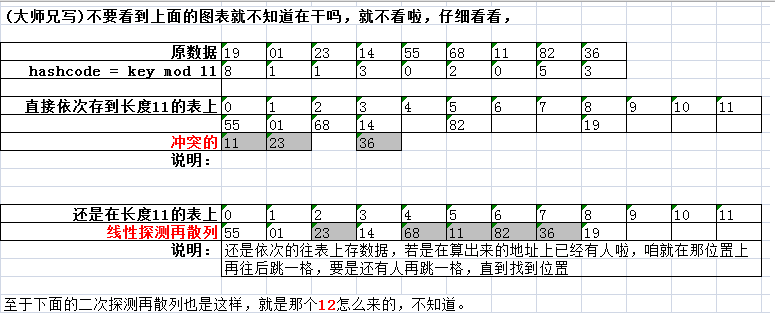
这个只是单纯的看,是不行的,你只是看到,有三个数据在按一定的算法(也就是mod 11 取余)散列到数组上的时候,看到有三个数据产生冲突啦。那么为了让这些数据更好的全部都能落在这个数组上,更好的利用这个数组,不浪费空间,就要去充分利用未分配到数据的数组上的其他位置。那么这就是解决冲突的需求。线性探测法:刚刚开始的时候,数据未冲突的时候,都按照取余的结果挨个按自己的取余结果,可以理解为你上学分班时候,你选座位。当你要去的座位,没人选的时候,你就坐上去,然后这个位置就被选过了,下次如果还有人和你一样,也选了这个座位,那么,他就冲突了。按照线性探测法的做法是:他本来是要坐你的位置的,但是,你已经坐了,那么,他只能以你为基准,查看你的座位的下一个,如果没人就坐下,如果有人,继续找下一个。当他也坐下来之后,后面再来的。发现自己的位置,被这个冲突的哥们占位了,那么,没办法,只能按刚刚那哥们的做法,继续找自己的位置。直到这个班级的所有位置都有人坐,那就OK。对应到这hashmap上就是 把这个数组的所有位置都给占满咯。这个线性探测和平方探测的区别就是在冲突的哥们找自己的位置的差别,一个是挨个查找;一个是高级点,或+n的平方,或-n的平方。都是为了占满教室的位置。
下面是一个总览的链接:
java 解决Hash(散列)冲突的四种方法–开放定址法(线性探测,二次探测,伪随机探测)、链地址法、再哈希、建立公共溢出区
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/146387.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...