大家好,又见面了,我是你们的朋友全栈君。
灰色关联度模型
引入
灰色关联度矩阵是灰色系统另一个非常重要的领域,通常用于分析向量与向量之间或矩阵与矩阵之间的关联度,其实用性非常强。
基本原理
(1)基本定义
假设有一组参考数列:
x j = ( x j ( 1 ) , x j ( 2 ) , x j ( 3 ) , . . . , x j ( n ) ) . j = 1 , 2 , 3 , . . . , s x_{j}=(x_{j}(1),x_{j}(2),x_{j}(3),…,x_{j}(n)). j=1,2,3,…,s xj=(xj(1),xj(2),xj(3),...,xj(n)).j=1,2,3,...,s
比较数列:
x i = ( x i ( 1 ) , x i ( 2 ) , x i ( 3 ) , . . . , x i ( n ) ) . i = 1 , 2 , 3 , . . . , t x_{i}=(x_{i}(1),x_{i}(2),x_{i}(3),…,x_{i}(n)). i=1,2,3,…,t xi=(xi(1),xi(2),xi(3),...,xi(n)).i=1,2,3,...,t
由以上两个数列,定义关联度矩阵如下:
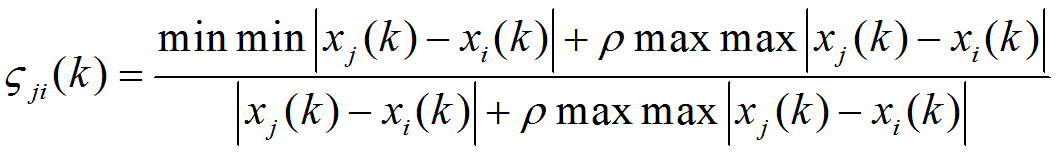

(2)模型说明
①变量 ζ j i ( k ) ζ_{ji}(k) ζji(k)表示的是第 i i i个比较数列与第 j j j个参考数列第 k k k个样本之间的关联系数。
② m i n m i n ∣ x j ( k ) − x i ( k ) ∣ min min|x_{j}(k)-x_{i}(k)| minmin∣xj(k)−xi(k)∣和 m a x m a x ∣ x j ( k ) − x i ( k ) ∣ max max|x_{j}(k)-x_{i}(k)| maxmax∣xj(k)−xi(k)∣表示的是参考数列矩阵与比较数列矩阵数值作差之后的最小值和最大值。把 m i n m i n ∣ x j ( k ) − x i ( k ) ∣ min min|x_{j}(k)-x_{i}(k)| minmin∣xj(k)−xi(k)∣和 m a x m a x ∣ x j ( k ) − x i ( k ) ∣ max max|x_{j}(k)-x_{i}(k)| maxmax∣xj(k)−xi(k)∣耦合到变量中可以保证 ζ j i ( k ) ζ_{ji}(k) ζji(k)之值位于[0,1]区间,同时上下对称的结构可以消除量纲不同和数值悬殊的问题。
③ ∣ x j ( k ) − x i ( k ) ∣ |x_{j}(k)-x_{i}(k)| ∣xj(k)−xi(k)∣式被称之为“Hamming”距离,Hamming距离的倒数被称之为反倒数距离,灰色关联度的本质就是通过反倒数的大小来判定关联程度:假设有曲线 x i x_{i} xi和 x j x_{j} xj上面的点 ( k , x i ( k ) ) (k,x_{i}(k)) (k,xi(k))和 ( k , x j ( k ) ) (k,x_{j}(k)) (k,xj(k)),这两个点的Hamming距离越大,表示两条曲线距离越大,倒数也就越小。反过来,倒数越大,表示两个曲线之间的距离越小,因为曲线已经消除了量级之间的差异,则Hamming距离越小的曲线形态就越相似。因此,灰色关联度的本质其实是依据曲线态势相近程度来分辨数列的相关度。
④分辨率 ρ ρ ρ取值在[0,1]之间
(3)定义数列相关度
z ( 1 ) ( k ) = x ( 1 ) ( k ) + x ( 1 ) ( k − 1 ) 2 , k = 2 , 3 , 4 z^{(1)}(k)=\frac{x^{(1)}(k)+x^{(1)}(k-1)}{2},k=2,3,4 z(1)(k)=2x(1)(k)+x(1)(k−1),k=2,3,4
则称新数列 z ( 1 ) = ( z ( 1 ) ( 2 ) , z ( 1 ) ( 3 ) , . . . , z ( 1 ) ( n ) ) z^{(1)}=(z^{(1)}(2),z^{(1)}(3),…,z^{(1)}(n)) z(1)=(z(1)(2),z(1)(3),...,z(1)(n))为 x ( 1 ) x^{(1)} x(1)的紧邻均值数列。
(4)定义GM(1,1)的灰微分方程
由于 ζ j i ( k ) ζ_{ji}(k) ζji(k)只能反映出点与点之间的相关性,相关性信息分散,不方便刻画数列之间的相关性,需要把它整合起来,所以我们在此,定义相关度:
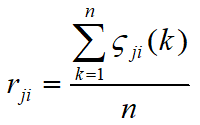
如果把 x i x_{i} xi和 x j x_{j} xj之间的相关度写成矩阵形式,则有
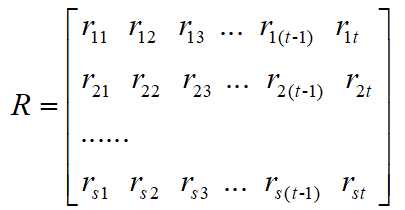
根据这个矩阵我们就可以很清楚得出,待比较数列从列可以看出其作用大小,参考数列从行可以看出其受影响程度的大小,而依据矩阵数值大小可以分析出比较数列矩阵中那些数列起到主要作用。比如某一列数值明显大于其他列,这样的数列叫做优势子因素,反之为劣势子因素;如果某一行数值明显大于其他行则称之为优势母因素,优势母因素比较敏感,容易受到子因素的驱动影响。
MATLAB源码
%灰色关联度矩阵模型
clc;
close;
clear all;
% 控制输出结果精度
format short;
% 原始数据,其中前五项为子因素,后两项为母因素
x=[
10 10 10 12 12 12 12 12 15 15 15 15 12 12 12 15 15 15 15 20 20 20 10 10 10 7 7 15 15 15 13 13 13 13 13 13
1216.482 612.364 477.838 988.53 482.685 468.074 1263.494 1235.787 422.27 1276.28 494.07 464.21 454.431 736.462 530.722 507.105 1067.189 911.603 519.956 1703.432 1570.14 521.364 984.01 158.825 199.623 1536.96 402.327 305.36 1012.77 982.12 500 520 1100 1783.644 404.951 584.652
910 910 910 707 707 707 707 707 1196 1196 1196 1196 1262 1262 1262 1004 1004 1004 1004 870 870 870 1023 1023 1023 1398 1398 1361 1361 1361 1702 1702 1702 1702 1702 1702
804.35 804.35 804.35 877.89 877.89 877.89 877.89 877.89 785.66 785.66 785.66 785.66 788.43 788.43 788.43 818.99 818.99 818.99 818.99 841.59 841.59 841.59 874.38 874.38 874.38 823.76 823.76 784.29 784.29 784.29 764.43 764.43 764.43 764.43 764.43 764.43
990.24 990.24 990.24 948.08 948.08 948.08 948.08 948.08 747.03 747.03 747.03 747.03 809.27 809.27 809.27 909.25 909.25 909.25 909.25 869.5 869.5 869.5 925.45 925.45 925.45 774.6 774.6 782.25 782.25 782.25 703.67 703.67 703.67 703.67 703.67 703.67
20 20 20 26.5 26.5 26.5 26.5 26.5 21.8 21.8 21.8 21.8 22.5 22.5 22.5 17.98 17.98 17.98 17.98 16.7 16.7 16.7 22 22 22 19.6 19.6 30.5 30.5 30.5 22.8 22.8 22.8 22.8 22.8 22.8
23.65 23.65 23.65 28 28 28 28 28 22.45 22.45 22.45 22.45 23.45 23.45 23.45 20 20 20 20 17 17 17 22.45 22.45 22.45 20 20 31.5 31.5 31.5 23 23 23 23 23 23
];
n1=size(x,1);
% 数据标准化处理
for i = 1:n1
x(i,:) = x(i,:)/x(i,1);
end
% 保存中间变量,亦可省略此步,将原始数据赋予变量data
data=x;
%% 分离数据
% 分离参考数列(母因素)
consult=data(6:n1,:);
m1=size(consult,1);
% 分离比较数列(子因素)
compare=data(1:5,:);
m2=size(compare,1);
for i=1:m1
for j=1:m2
t(j,:)=compare(j,:)-consult(i,:);
end
min_min=min(min(abs(t')));
max_max=max(max(abs(t')));
% 通常分辨率都是取0.5
resolution=0.5;
% 计算关联系数
coefficient=(min_min+resolution*max_max)./(abs(t)+resolution*max_max);
% 计算关联度
corr_degree=sum(coefficient')/size(coefficient,2);
r(i,:)=corr_degree;
end
% 输出关联度值并绘制柱形图
r
bar(r,0.90);
axis tight;
legend('第一行','第二行','第三行','第四行','第五行');% 图例
grid on;% 加入网格
% 去掉X轴上默认的标签
set(gca,'XTickLabel','');
% 设定X轴刻度的位置,这里有2个母因素
n=2;
% 这里注意:x_range范围如果是[1 n]会导致部门柱形条不能显示出来,所以范围要缩一点
x_value = 1:1:n;
x_range = [0.6 n+.4];
% 获取当前图形的句柄
set(gca,'XTick',x_value,'XLim',x_range);
% 在X轴上标记2个母因素
profits={'第六行','第七行'};
y_range = ylim;
% 用文本标注母因素名称
handle_date = text(x_value,y_range(1)*ones(1,n)+.018,profits(1:1:n));
% y轴标记
ylabel('影响程度');
title('各项子因素对母因素的影响作用');
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/146322.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
