大家好,又见面了,我是你们的朋友全栈君。
在线性表和树表中的查询中,记录在表的位置跟记录的关键字之间不存在确定关系,也就是说在线性表和树表中查询通常要依托关键字比较,查找的效率取决于比较次数。
散列函数:一个把查找表中的关键字映射成该关键字对应的地址函数,记为Hash(key)=Addr。这里的地址可以是数组下标,索引,或内存地址等。散列函数可能将两个或两个以上的不同关键字映射到同一个地址,称这种情况为“冲突”。(假若这个函数是f(x)=x^2,-无穷<x<+无穷,则当x=+-1时,函数值相同,这种情况就成为冲突)这种冲突最好减少,但是这种冲突是避免不了的,所以要设计好解决冲突的方法。
散列表:根据关键字而直接进行访问的数据结构,散列表建立了关键字和存储地址之间的直接映射关系。理想情况下,散列表的查找时间复杂度为O(1),及与表中的元素个数无关。
散列函数的构造方法:
[注意]
- 散列函数定义域必须包含全部需要存储的关键字,而值域的范围则依赖散列表的大小或地址范围。
- 散列函数计算出来的地址应该能等概率、均匀分布在整个地址空间,从而减少冲突的发生。
- 散列函数应尽简单,能够在较短时间内就计算出任一个关键字对应的散列地址。
常用的散列函数:
- 直接定址法:直接取关键字的某个线性函数值为散列地址,散列函数为:H(key)=a*key+b,其中a,b是常数。若其中H(key)中已经有值了,就往下一个找,直到H(key)中没有值了,就放进去。这种方式最简单,并且不会冲突,适用于关键字的分布基本连续的情况,若关键字分布不连续,空位比较多,将造成空间浪费。
- 除留余数法:假定散列表表长为m,取一个不大于m但最接近或等于m的质数p,利用以下公式把关键字转换成散列地址,散列函数为H(key)=key%p。[注]关键是选好p,使得每一个关键字通过该函数转换后等概率地映射到散列空间上的任意地址,从而尽可能减少冲突的可能性。
- 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
- 平方取中法:当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。
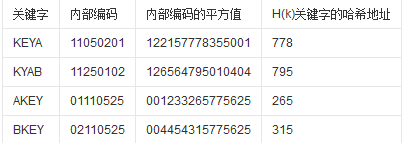
例:我们把英文字母在字母表中的位置序号作为该英文字母的内部编码。例如K的内部编码为11,E的内部编码为05,Y的内部编码为25,A的内部编码为01, B的内部编码为02。由此组成关键字“KEYA”的内部代码为11052501,同理我们可以得到关键字“KYAB”、“AKEY”、“BKEY”的内部编码。之后对关键字进行平方运算后,取出第7到第9位作为该关键字哈希地址。

5.随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
6.折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
冲突解决方法:
1. 开放寻址法:指的是客村放心表象的空闲地址既向它的同义词表项开放,又向它的非同义表项开放。数学递归公式为:Hi=(H(key) + di) MOD m , i=0,1,2,…,k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,可有下列四种取法:
- di=0,,1,2,3,…,m-1,称线性探测(特点:冲突发生时,顺序查看表中下一个单元,直到找出一个空闲单元或查遍全表);
- di=0^2,1^2,-1^2,2^2,-2^2,⑶^2,…,±(k)^2,(k<=m/2)称二次探测(平方探测法)(特点:散列表长度m必须是一个可以表示成4k+3的素数,此方法可避免“堆积问题”,不能探测到散列表的所有单元,但是至少能探测一般);
- di=伪随机数序列,称伪随机序列散列。
- 再散列法:当di=Hash2(key),又称为双散列表。需要使用两个散列函数,当通过第一个散列函数H(key)得到的地址发生冲突,则利用第二散列函数Hash2(key)计算该关键字的地址增量。它的具体函数形式为:Hi=(H(key)+i*Hash2(key))%m,i=0,1,2,…,k ,i是冲突次数。即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间。
2. 链接法(拉链法)
为了避免不同关键字映射到同一地址,可以把所有的同义词存储在一个线性表中,这个线性链表尤其散列地址唯一标识。散列地址为i的同义词链表的头指针存放在散列表的第i个单元中,因而查找、插入和删除操作,主要在同义词链中进行。拉链法适用于进行插入和删除的情况。
例如,关键字序列为{19,14,23,01,68,20,84,27,55,11,10,79},散列函数为H(key)=key%13,用拉链法处理冲突。如图:
| 0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
| 1 |
01 |
14 |
27 |
79 |
| 3 |
55 |
68 |
| 6 |
19 |
84 |
| 7 |
20 |
| 10 |
10 |
23 |
| 11 |
11 |
实例
1.两数之和
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。
你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 + 7 = 9 所以返回 [0, 1]
不用Hash的c++算法:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
vector<int> res;
int n = nums.size();
for(int i = 0;i<n;++i)
{
for(int j = i+1;j<n;++j)
{
if(nums[i]+nums[j]==target)
{
res.push_back(i);
res.push_back(j);
break;
}
}
if(!res.empty())
break;
}
return res;
}
};用HashMap的Java算法:
class Solution {
public int[] twoSum(int[] a, int target) {
int[] res = new int[2];
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < a.length; i++) {
if(map.containsKey(a[i])){
res[0] = map.get(a[i]);
res[1] = i;
}
map.put(target - a[i], i);
}
return res;
}
}15. 三数之和
给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
例如, 给定数组 nums = [-1, 0, 1, 2, -1, -4], 满足要求的三元组集合为: [ [-1, 0, 1], [-1, -1, 2] ]
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
if(nums == null){
return null;
}
if(nums.length < 3){
return new ArrayList<>();
}
Arrays.sort(nums);
HashSet<List<Integer>> set = new HashSet<>();
for (int i = 0; i < nums.length; i++) {
int j = i + 1;
int k = nums.length - 1;
while(j < k){
if(nums[i] + nums[j] + nums[k] == 0){
List<Integer> list = new ArrayList<>();
list.add(nums[i]);
list.add(nums[j]);
list.add(nums[k]);
set.add(list);
while(j < k && nums[j] == nums[j + 1]){
j++;
}
while(j < k && nums[k] == nums[k - 1]){
k--;
}
j++;
k--;
}else if(nums[i] + nums[j] + nums[k] < 0){
j++;
}else{
k--;
}
}
}
return new ArrayList<>(set);
}
}发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/146319.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
