大家好,又见面了,我是你们的朋友全栈君。
Exploiting Visual Artifacts to Expose DeepFakes and Face Manipulations论文详记
原文链接:
https://ieeexplore.ieee.org/abstract/document/8638330.
一、论文简述
提取眼睛、牙齿以及脸部轮廓等位置的特征来检测DeepFake视频,属于基于帧内图像伪影的检测方法,使用Logistic回归或浅层全连接网络分类,属于浅层分类器方法。
二、论文内容
作者等人认为,虽然当前的计算机视觉与计算机图形学的工作(指GANs、VAE等模型)在相对自由的场景中有令人满意的效果,但将这些技术应用于人脸操纵上面时,大部分技术会凸显出一定的局限性,这种局限性会在生成内容中产生特征性的伪影。作者等人选择使用眼睛、牙齿以及面部轮廓上的视觉特征,并证明在开发出足够通用的统计视频取证方法之前,基于这些视觉特征的检测方法,是一种易于实现、可行的检测方法。
A、篡改伪影
①全局一致性
作者认为,在利用GANs生成新面孔时,支持图像插值的数据点是随机生成的,不一定具有语义上的意义,虽然生成的结果通常可以描述为不同面孔的和谐混合,但它们似乎缺乏全局一致性,可以观察到许多生成的样本左右眼睛颜色的差异很大,如下图所示。现实中,不同颜色虹膜的现象被称为异瞳,但这对人类来说是罕见的。这种伪影在生成的人脸中的严重程度各不相同,且并非存在于所有的样本中。
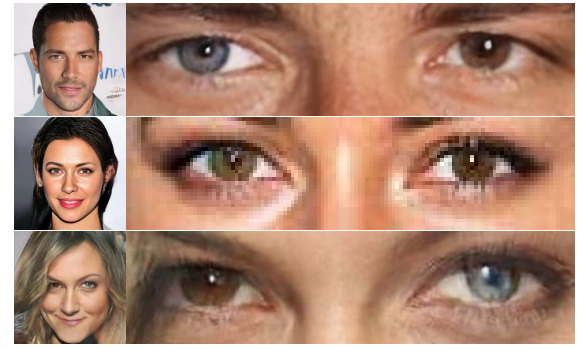

②光照估计
为了重构具有不同属性的人脸,必须将入射光从原始图像转移到伪造图像中。对于Face2Face等方法,估算几何体、估算照明和渲染的过程是显式建模的,而在基于深度学习的方法中,这种模型通常是从数据中隐式学习的,因此对入射光照的错误或不精确的估计将导致相关伪影出现。漫反射通常可以令人信服地重建,特别基于深度学习技术生成的篡改,我们无法发现其相关的伪影。在Face2Face操作的某些情况下(为啥目测DeepFake生成的好像也有?),可以发现着色瑕疵,这些伪影通常会出现在鼻子的某个区域,在该区域的一侧阴影被渲染得太暗,作者认为这些伪影可能是由Face2Face的有限光照模型引起的,因为这种模型没有考虑互反射的影响。下图显示与原始图像进行比较的该伪影的示例。

面部的镜面反射在眼睛中最为明显,许多由DeepFake技术生成的样本显示出不可信的镜面反射,具体表现为:眼睛中的反射要么消失,要么简化为一个白色斑点。这种伪影会导致眼睛看起来不具有神采,下图中示出了与未篡改的图片进行比较的示例。

③几何估计
显然的是,我们必须估计面部几何结构才能完成面部的篡改。如前所述,与光照的情况类似,Face2Face通过将可变形模型拟合到图像中,从而显式地建模几何估计,基于深度学习的技术隐式地从数据中学习底层模型。对于Face2Face数据,我们可以发现由底层几何体的不精确估计引起的伪影,在替换过程中,原始图像上覆盖有一个mask。如果几何估计不完美,则会出现沿mask边界的伪影。这种伪影通常在鼻子区域、脸部遮挡边界周围和眉毛处相对明显。此外,如果部分遮挡的面部的部分(例如头发)没有正确建模,将可能导致出现一些“孔洞”(下图右),上述伪影如下图所示。

另外,在目前社交媒体上流传的假样本上,我们经常可以发现一些几何体的缺失。具体来说,牙齿通常是没有建模模型的,这一点在很多视频中都很明显,在这些视频中,牙齿显示为单个白色斑点,而不是单个牙齿,如下图所示。

B、基于视觉伪影的分类
在实际检测中,伪影的视觉外观并不总是像示例种那样明显,然而,我们表明相对简单的特征可以用来建模这些观测,这些特征可用于检测生成或篡改的人脸。具体来说,我们提出一个算法来检测:1、完全生成的人脸(也就是Entire Face Synthesis,直接用GAN或者其他生成模型生成的人脸,没有明确的目标);2、目前在社交媒体上流传的DeepFake;3、由Face2Face篡改的图像。
①、完全生成脸部的检测
作者利用眼睛颜色的差异来检测完全生成的人脸。为了提取每只眼睛的颜色特征,作者为每个输入图像检测面部LandMark,然后将图像裁剪到面部区域并重塑图像为768×768像素(没看源码,原文是 the images are cropped to the face region and resized to 768 pixels in height,我个人理解为resize成768*768),使得所有待处理的样本具有相同的分辨率。作者通过检测虹膜位置的像素来计算眼睛的颜色特征。作者考虑将虹膜检测为眼睛LandMark内的一个圆,由于虹膜与巩膜的对比度通常比较高,因此利用Canny算子做边缘检测并应用Hough圆变换,通过对可能属于瞳孔的暗像素和可能来自反射或不准确分割的亮像素进行阈值化,进一步细化分割。下图显示了检测pipeline中主要步骤的分割结果。

作者还提出两个一致性检查来帮助识别虹膜检测中的失败情况:1、对于左眼和右眼,虹膜中心和眼睛中心的距离(依据LandMark计算)应该相似;2、两个虹膜都有相似的半径。为了提高分割的可信度,丢弃违反这些假设的样本。
作者定义了多种特征来描述左右眼颜色的差异。首先,将颜色变换为HSV颜色空间,并对左右眼的分割像素进行平均,左眼 l H l_H lH、 l S l_S lS、 l V l_V lV和右眼 r H r_H rH、 r S r_S rS、 r V r_V rV的平均H、S、V值之间的差值计算如下:
D i s t H = m i n ( ∣ l H − r H ∣ , 360 − ∣ l H − r H ∣ ) D i s t S = ∣ l S − r S ∣ D i s t V = ∣ l V − r V ∣ D i s t H S V = D i s t H + D i s t S + D i s t V Dist_H=min(|l_H-r_H|,360-|l_H-r_H|)\\ Dist_S=|l_S-r_S|\\ Dist_V=|l_V-r_V|\\ Dist_{HSV}=Dist_H+Dist_S+Dist_V DistH=min(∣lH−rH∣,360−∣lH−rH∣)DistS=∣lS−rS∣DistV=∣lV−rV∣DistHSV=DistH+DistS+DistV
另外,作者为每个虹膜计算RGB值的标准化64-bin直方图,对于每个颜色通道,分别计算左右眼之间的相关性,得到特征CorrelR、CorrelG、CorrelB。对于不需要任何训练数据的分类,可以直接使用HSV距离 D i s t H S V Dist_{HSV} DistHSV作为分类特征,若为了进一步提高分类性能,可以将所描述的特征组合成一个六维特征向量:
F = ( D i s t H , D i s t S , D i s t V , C o r r e l R , C o r r e l G , C o r r e l B ) F=(Dist_H, Dist_S, Dist_V , Correl_R, Correl_G, Correl_B) F=(DistH,DistS,DistV,CorrelR,CorrelG,CorrelB)
这些特征通过欧式距离传递给的 K K K近邻分类器( K = 20 K=20 K=20)做分类。
②、DeepFakes的检测
作者利用眼睛和牙齿区域缺失的细节和光反射进行DeepFake检测。作者再次检测面部LandMark并将输入图像裁剪到面部区域,为了适应输入数据的不同分辨率,所有样本都重塑为256×256。对于眼睛区域,作者通过考虑相关眼部LandMark的凸包中的像素来分割;对于牙齿区域,作者先将图片转为灰度图,通过K均值聚类,将嘴部LandMark的凸包中包含的像素点聚类为亮和暗两个簇,亮簇中的所有像素认定为牙齿,若小于1%的嘴部像素被分类为牙齿,则丢弃样本。下图显示了分割的结果。

作者选择用纹理能量(texture energy)的方法,通过设计16个固定的5×5卷积mask来提取描述纹理复杂性的特征,根据Laws等人(纹理能量分割论文作者)的建议,在计算能量图之前,将每个像素减去一个平均值,平均值由一个15×15的局部平均核计算而得。滤波后得到的16个能量图再利用一个10×10的核做平均,并对对称的pair进行组合(symmetric pairs的意思是?),这将会在每个像素上产生9个纹理特征。为了生成每个样本的特征向量,我们分别对眼睛、牙齿和整个图像中所有像素的9个特征进行平均。这些描述子最后将用两种分类模型分类:1、拟合一个Logistic回归模型作为一个典型的“现成”分类器;2、对高容量模型,作者训练一个浅层的全连接神经网络来分类,包含三层64个节点和ReLU激活函数。网络用ADAM进行训练,并用 α \alpha α值为0.1的L2惩罚正则化。
Textured Image Segmentation算法论文连接 https://apps.dtic.mil/sti/citations/ADA083283.
③、Face2Face的检测
对于Face2Face数据,作者使用了与Deepfakes相同的分类器,但功能不同。我们没有分割眼睛和牙齿,而是计算面部边界和鼻尖的特征。同样,脸部轮廓的分割是通过在检测到的面部LandMark周围生成凸包,并在边缘周围取一个10像素宽的区域来提取的;鼻子的分割直接提取凸包周围相关的LandMark。分割的一个例子如下图所示,特征、分类器及其超参数的计算如前所述。

三、论文实验及结果
实验数据集:
①、完全合成人脸:正例来自CelebA,负例来自ProGAN和Glow(鲁棒性测试)
②、DeepFake:自建数据集,负例收集自YouTube
③、Face2Face:FaceForensics
实验效果:
①、完全合成人脸:做了两次实验,一次直接计算色差;一次计算训练的k近邻分类器返回的概率,ROC曲线如下图所示。
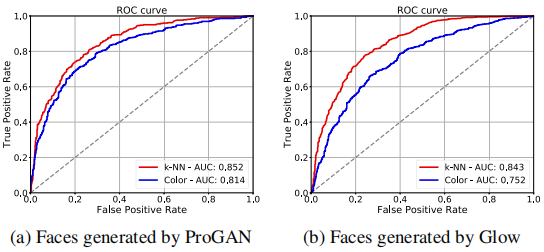
可以看到用KNN分类器对ProGAN测试数据进行高置信度分割,取得了最佳的分割效果,AUC为0.852;直接使用色差进行分类,而不使用任何训练数据,AUC为0.814。对于鲁棒性测试的Glow数据,AUC最高也能达到0.843,说明泛化能力不错。
②、DeepFake:在丢弃部分无法分割的样本后,处理了342个假样本和367个真样本,下图显示了所提出的分类器的ROC曲线。
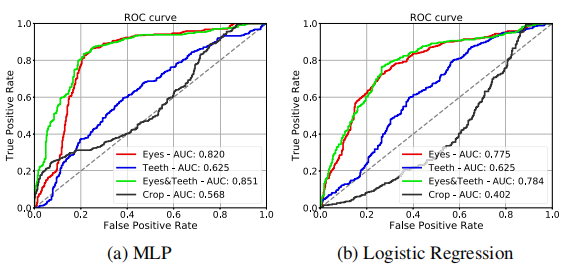
可以看到,仅用牙齿生成的特征进行分类的效果相对较差,两种分类器的AUC均为0.625。从眼睛区域提取的特征可以得到更好的性能,分别为0.820和0.784。利用组合特征向量训练的三层神经网络,获得了AUC为0.851的最佳结果。
③、Face2Face:FaceForensics数据集用于进一步评估提出的纹理特征的适用性。分类结果ROC曲线如下图所示。
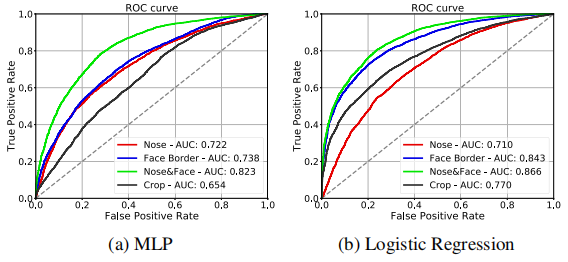
可以看到,基于Logistic回归模型的分类器性能最好,利用组合特征向量AUC高达0.866。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/145181.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
