大家好,又见面了,我是你们的朋友全栈君。
Elasticsearch的介绍
Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档。
Elasticsearch具有以下特点:
- 分布式,无需人工搭建集群(solr就需要人为配置,使用Zookeeper作为注册中心)
- Restful风格,一切API都遵循Rest原则,容易上手近实时搜索,数据更新在Elasticsearch中几乎是完全同步的。
- 开源的全文检索技术(Solr、Elasticsearch等)
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
- 分布式的功能,数据高可用,集群高可用
- 基于Lucene,API更简单,更高级,隐藏了Lucene的复杂性,提供简单的API
- 支持的语言很多,支持PB级别的数据,能完成搜索的功能和分析功能
Elasticsearch 和 Lucene区别:
Lucene:Lucene就是一个jar包,里面包含了各种建立倒排索引的方法,java开发的时候只需要导入这个jar包就可以开发。(这是典型的用空间换时间)
但是Lucene不是分布式的。ES的底层就是Lucene,ES是分布式的。
1、Elasticsearch的安装
Elastic官网地址:https://www.elastic.co/cn/
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch
使用ES需要先安装JDK,特别需要注意 ES 版本和 JDK 版本的兼容问题,ES6.1.1以上版本需要JDK1.8以上版本。
ES官网下载地址:https://www.elastic.co/cn/downloads/past-releases
1.1 使用国内镜像下载ES
官网下载速度太慢了,可以通过华为云镜像下载:
https://mirrors.huaweicloud.com/elasticsearch/
然后选择你自己需要的版本号进行下载

【下载注意事项】
前面说了,Elasticsearch需要有Java环境,并且ES6.1.1以上版本需要JDK1.8以上版本。
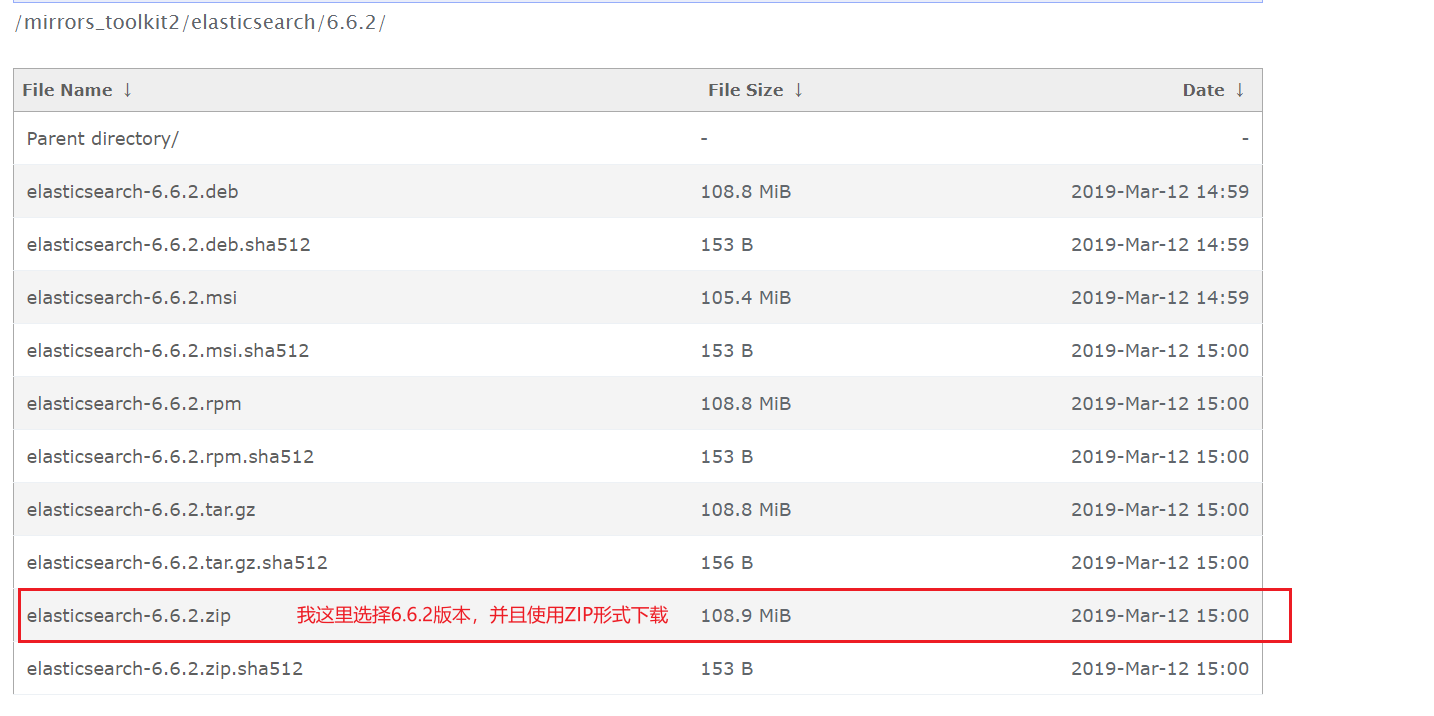
但是最新的ElasticSearch7.x需要的是Java11环境,如果你用的 JDK 1.8 版本的,可以选择 ES6.1.1以上且ES7.x 以下的版本进行下载。
我选择的是6.6.2版本的
下载完成之后解压:
1.2 安装
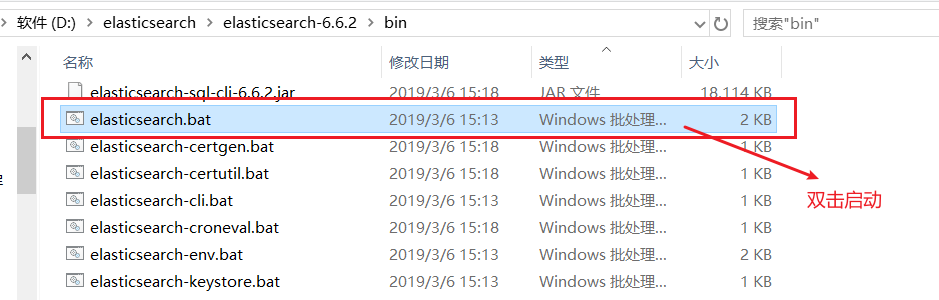
安装非常的简单,解压后进入 elasticsearch 下的的 bin目录,双击 elasticsearch.bat 启动服务
启动之后是这样的:
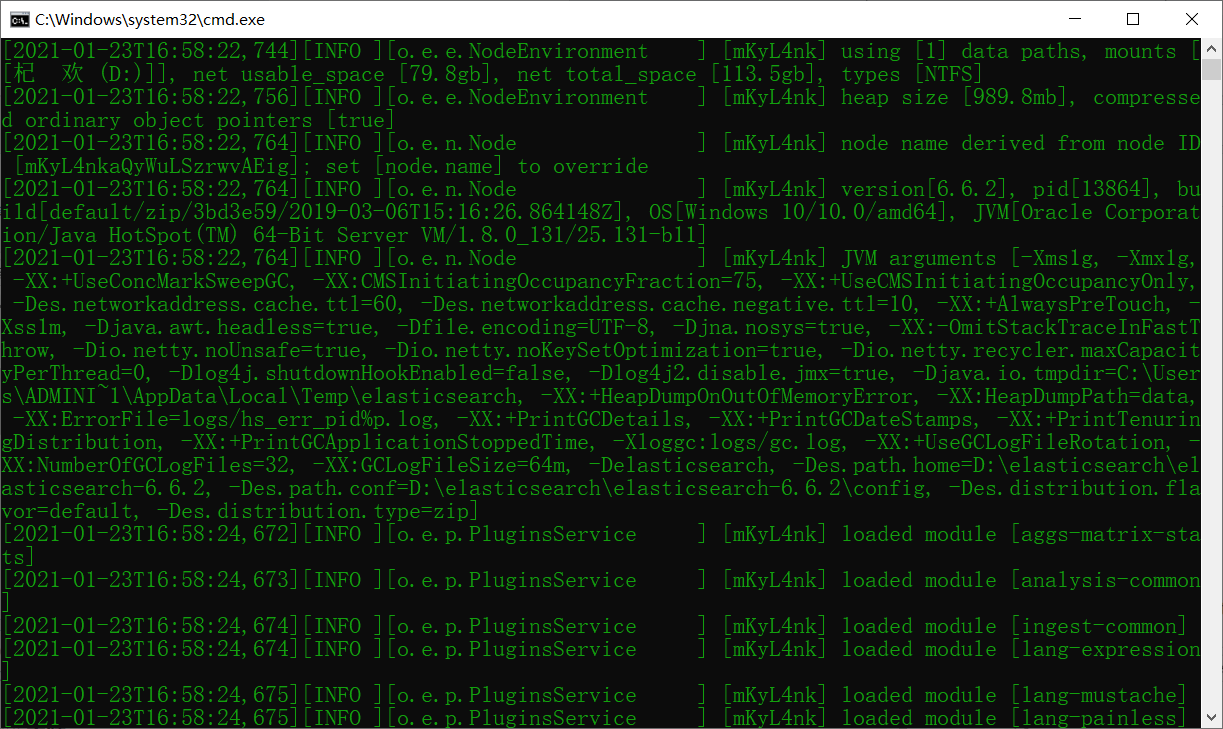
启动完成之后,通过地址:http://localhost:9200/ 进行访问
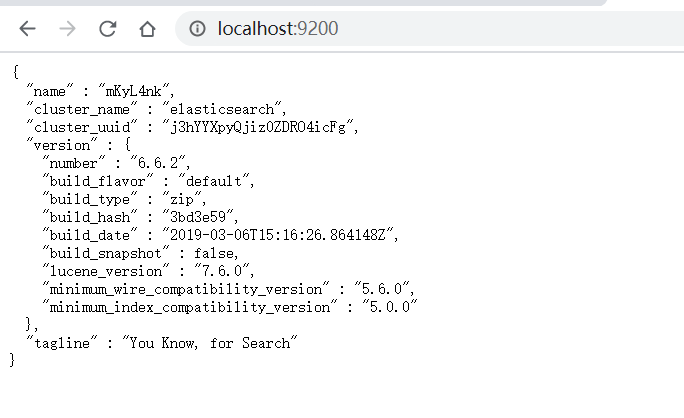
出现如上结果,就是 Elasticsearch 安装成功了。
2、windows下ElasticSearch-head插件安装使用
ElasticSearch-head 是一款能连接 ElasticSearch搜索引擎、提供可视化的操作页面、对ElasticSearch搜索引擎进行各种设置和数据检索功能的管理插件。
如在head插件页面编写RESTful接口风格的请求,就可以对ElasticSearch中的数据进行增删改查、创建或者删除索引等操作。有点类似于使用navicat工具连接MySQL之类的关系型数据库,然后对数据库进行操作。
2.1 ElasticSearch-head安装前置条件
ES5以上版本安装 ElasticSearch-head 需要安装 node 和 grunt。
2.1.1 安装node
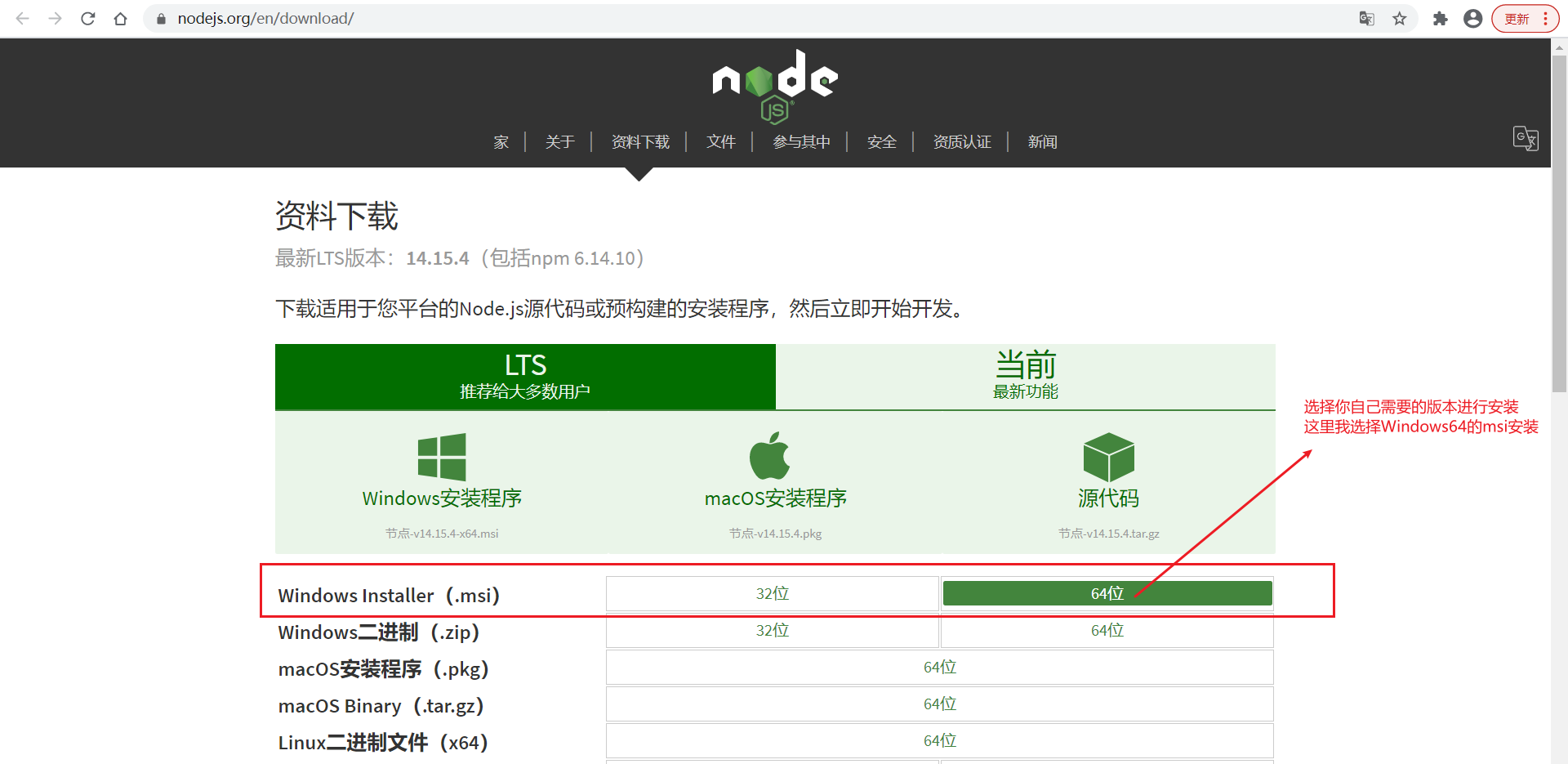
node下载地址:https://nodejs.org/en/download/
选择自己需要的版本安装(这里我选择使用:Windows Installer(.msi) 的方式下载)
双击msi文件安装就行

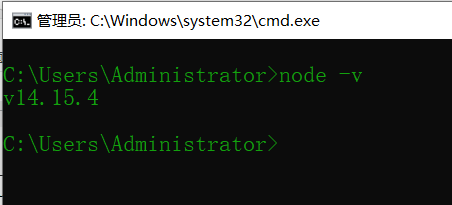
安装完成之后,打开命令窗口(Windows + R输入CMD),输入 node -v 查看安装版本
2.1.2 安装grunt
打开命令窗口(Windows + R输入CMD),然后输入命令安装grunt:
npm install -g grunt-cli
然后等它下载完成
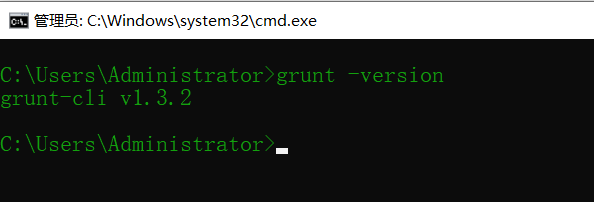
下载完成之后,输入 grunt -version 查看安装版本
2.2 ElasticSearch-head安装
elasticsearch-head 是一款开源软件,elasticsearch5.0之后,elasticsearch-head不做为插件放在其plugins目录下,而是被托管在github上面。
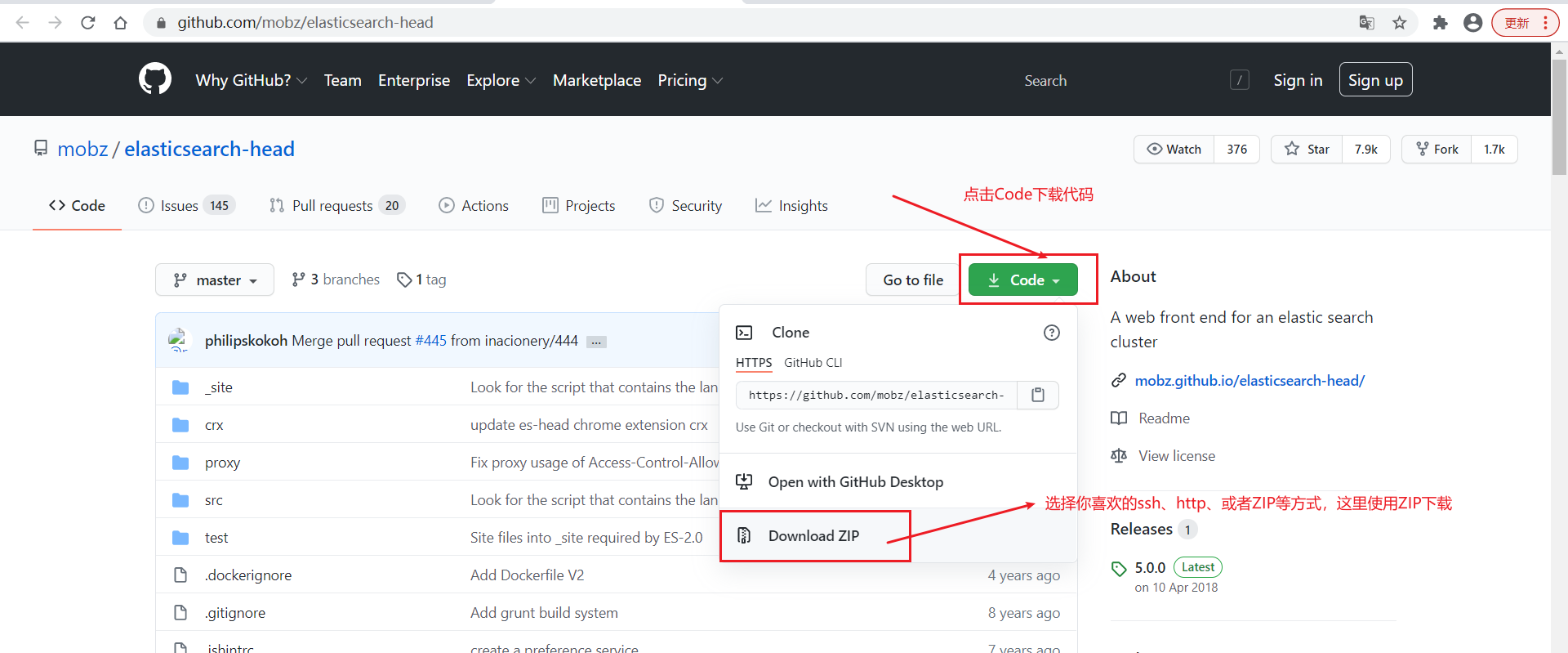
ElasticSearch-head的github下载地址:https://github.com/mobz/elasticsearch-head
从GitHub上把代码拉下来,这里选择ZIP格式:
下载成功之后是一个 elasticsearch-head-master.zip 压缩文件包
双击解压之后目录:
使用ElasticSearch-head配置
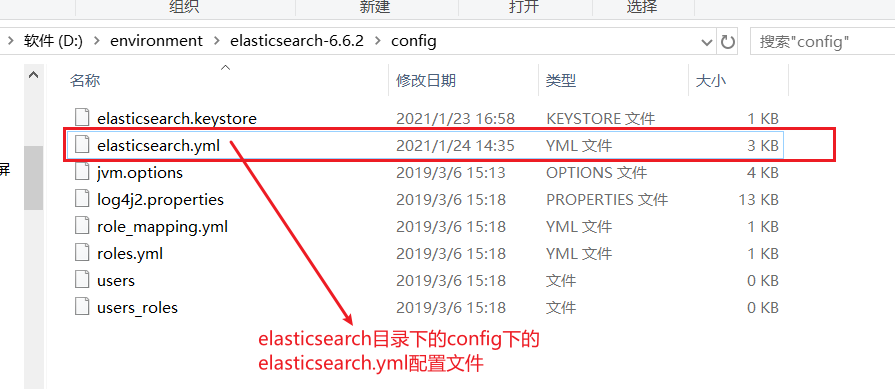
- 打开之前安装的ElasticSearch文件目录,目录下的config目录,修改其中的
elasticsearch.yml文件,在文件末尾添加以下配置:
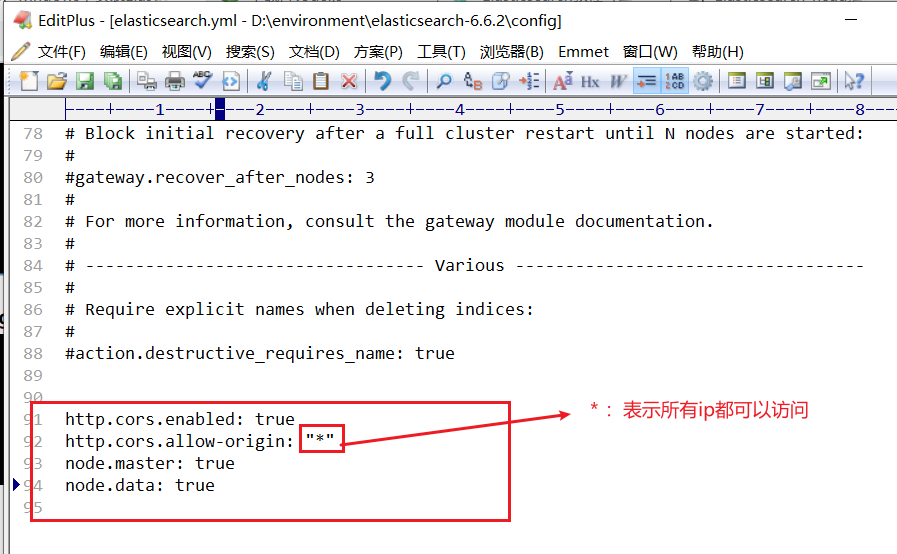
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
如图:
然后重启Elasticsearch服务器(重启:elasticsearch.bat)
elasticsearch.yml 其他的一些配置信息:
| 属性名 | 描述 |
|---|---|
| network.host | 允许访问的ip地址(0.0.0.0:允许任何ip来访问) |
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
- 打开刚刚下载的
Elasticsearch-head文件的elasticsearch-head-master目录下的Gruntfile.js文件
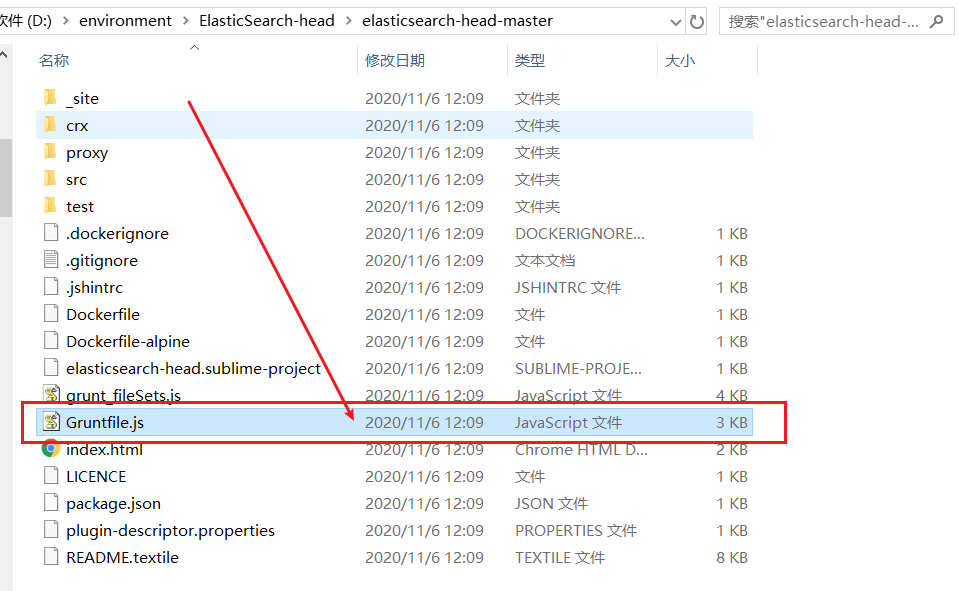
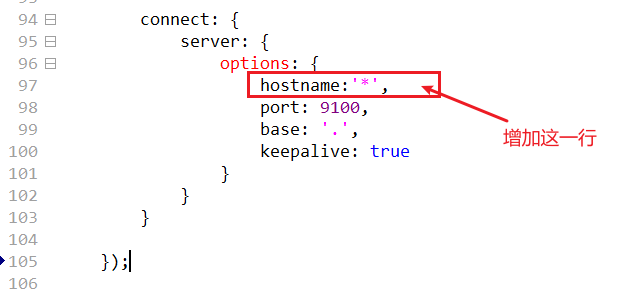
编辑该文件,修改Connect下的Server的options,添加如下内容:
hostname:'*'
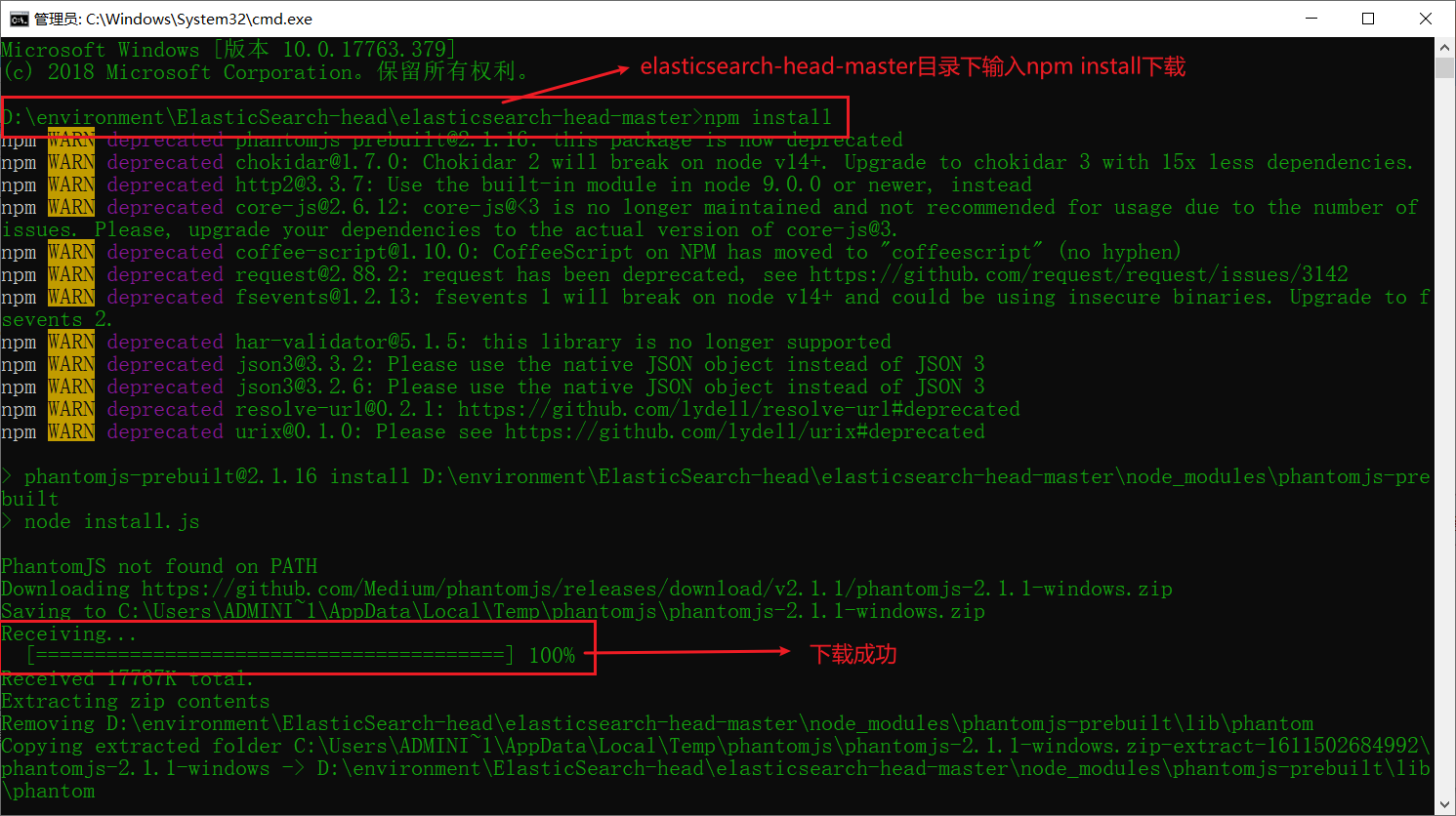
3. 在 elasticsearch-head-master 目录下输入CMD打开命令窗口,然后输入 npm instal 安装
下载时间比较久,需要耐心的打一把王者就ok了嘿嘿
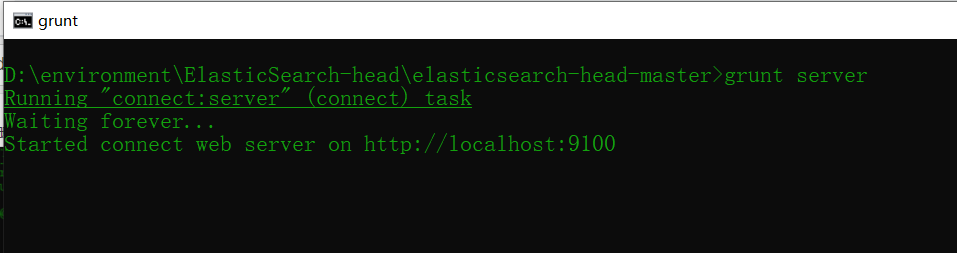
4. 然后执行 grunt server 或者 npm run start 运行 ElasticSearch-head 插件
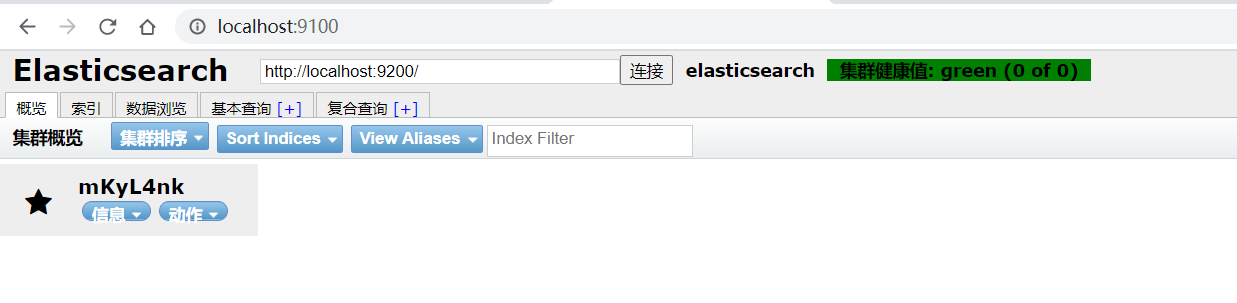
5. 通过地址:http://localhost:9100/ 访问
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/145093.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
