大家好,又见面了,我是你们的朋友全栈君。
本篇文章主要对比赛流程中的各个环节进行展开说明,并对笔者践行过的代码及更改的地方进行记录。如哪里有侵权请联系笔者进行删除。另外在这里对比赛举办方表示感谢 ~ ~
其中开源代码会在整理后放在github上,并给出相应的链接,这里先留一个小尾巴~ ~
相关有用的链接如下:
- 口罩、安全帽识别比赛踩坑记(一) 经验漫谈及随想
- 比赛官方开发环境指导
- Dockerfile官方文档
- OpenVINO官方文档
- SSD 论文详解
- YOLO V3论文详解
- SSD 代码实现 (tensorflow 版)
- YOLO V3 代码实现(tensorflow 版): 正在整理中~
- YOLO V3 代码实现(darknet 版):正在整理中~
—————————————————————————————————————————————–
1. 赛前准备
赛前的准备包括了两部分,一部分是熟悉 VSCode 的界面和代码的编译调试,一部分是通过官方给出的行人检测的 Demo 跑一遍整个过程,熟悉一下 pipeline。
1.1 熟悉编译环境
这次官方提供了两个在线编译的环境,一个是 jupyter notebook,另一个是 VSCode,因为笔者之前一直采用的 Pycharm 作为 IDE,据查的攻略说更贴近后者,所以就使用的 VSCode 作为编辑器。
安装和初始配置过程见: 配置python3.6.8 + VSCode
个人感觉 VSCode的界面看着更舒适些,但一个严重的缺陷是没有 console 功能,代码无法实时试错,这个缺陷让使用惯 Pycharm 和 matlab 的我就很难受。也不知道为啥网上那些骨灰级的程序猿都一边倒向 VSCode,也许是在 C++ 上另有一番神奇之处?还望知道的大大给我解解惑,让我也长长见识(好吧,我感觉能看到这里的可能也没几个知道的家伙,毕竟前言的贴图已经把大佬的目光阻隔住了…)
1.2 熟悉pipeline
这次比赛最大的特点就是它不像我们平时在实验室那种“空谈”性质的 pipeline ——跑完模型,直接得结果。而是增加了算法工业化落地时所必需的加速和优化性能的环节,以及封装成一个产品的环节。通过跑了一遍官方给的用 ODA(object detection API)中的 SSD-InceptionV2 模型实现对行人检测的 Demo,我梳理了整个比赛所需要做的工作。包含以下部分:
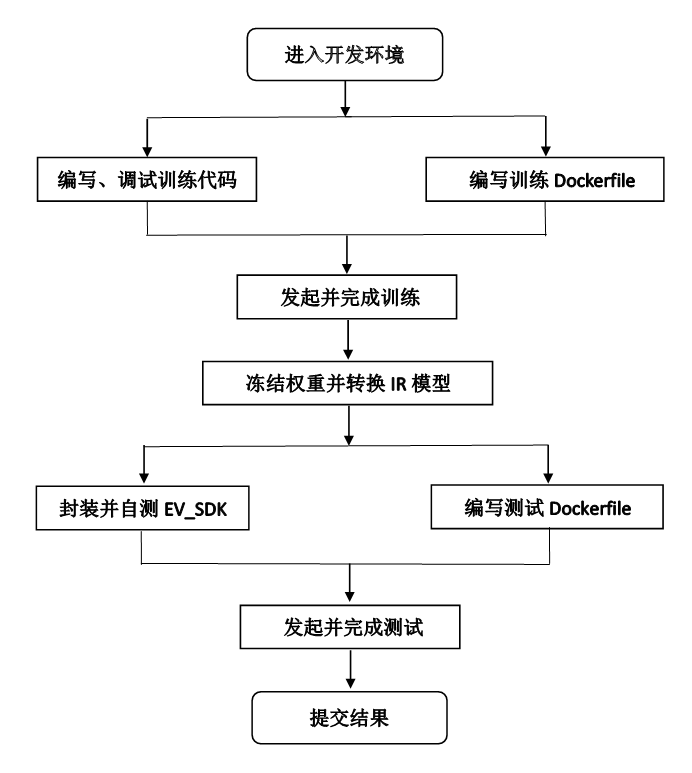
 其中的几个环节备注如下:
其中的几个环节备注如下:
- Dockerfile:是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。因为在线服务器的环境,需要构建镜像来使用不同的框架。具体见 2.5.2节。
- 权重冻结:将原本模型的权重值.weights或.ckpt转换为.pb文件。pb是protocol(协议) buffer(缓冲)的缩写。TensorFlow训练模型后存成的pb文件,是一种表示模型(神经网络)结构的二进制文件,不带有源代码,也一般无法映射成源代码。pb文件作为SavedModel的一部分,可以加载回TensorFlow进行部署或进一步训练。具体见 2.5.3 节。
- IR转换:将.pb文件转换为openvino模型进行推理加速,内含 .xml、.bin 和 .mapping 文件。在将算法工业化落地时需要加速和优化模型性能,OpenVINO是英特尔基于自身现有的硬件平台开发的一种可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,支持各种英特尔平台的硬件加速器上进行深度学习,并且允许直接异构执行。具体见 2.5.4 节。
- SDK封装:SDK即“软体开发工具包”,一般是一些被软件工程师用于为特定的软件包、软件框架、硬件平台、操作系统等建立应用软件的开发工具的集合。通俗点是指由第三方服务商提供的实现软件产品某项功能的工具包。通常SDK是由专业性质的公司提供专业服务的集合,比如提供安卓开发工具、或者基于硬件开发的服务等。也有针对某项软件功能的SDK,如推送技术、图像识别技术、移动支付技术、语音识别分析技术等,在互联网开放的大趋势下,一些功能性的SDK已经被当作一个产品来运营。开发者不需要再对产品的每个功能进行开发,选择合适稳定的SDK服务并花费很少的经历就可以在产品中集成某项功能。SDK相当于开发集成工具环境,API就是数据接口。在SDK环境下调用API数据。具体见 2.6节。
2. 比赛经过
首先查看本次比赛的数据集和评分标准。
2.1 数据集
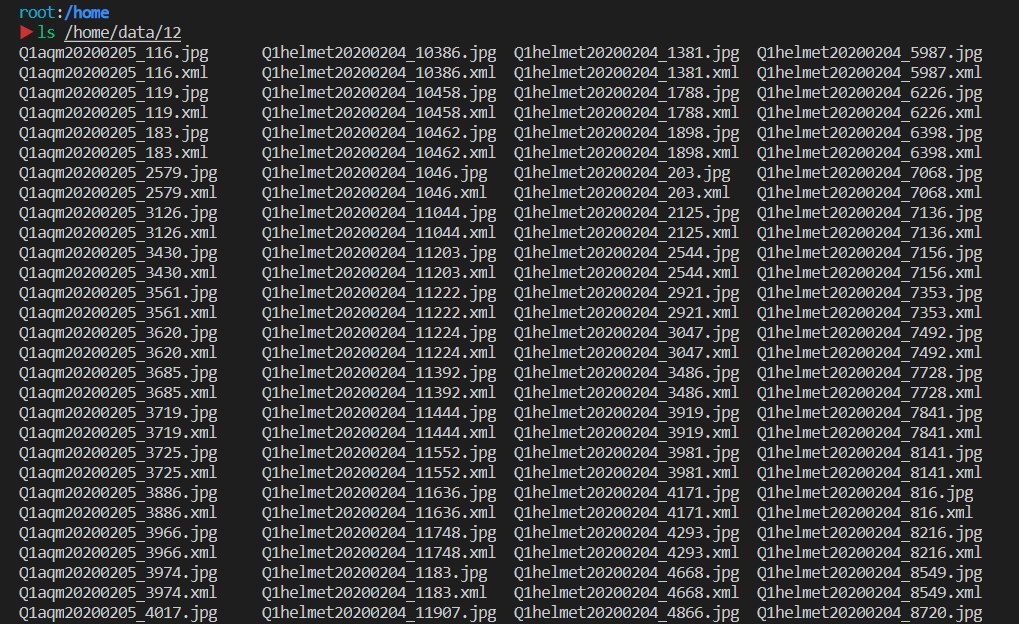
口罩和安全帽的数据集都是不可见的,官方给出了100张样例图片,训练集和测试集都是内网存储,我们是在外网操作样例,然后指定地址会有关联。以下是 ls 出的样例存储,可以发现 xml 和图片是一起存放的。

每一类的训练集大约10000张,测试集5000张;采用VOC2007的标注格式,水平框;图片既有 jpg,也有 png;口罩 labels 和安全帽 labels 如下(安全帽会有各种颜色的安全帽以及对人脸和人身的标注,方便各种算法的实施,比如先对人身再对头盔的二次标注(猜测))。
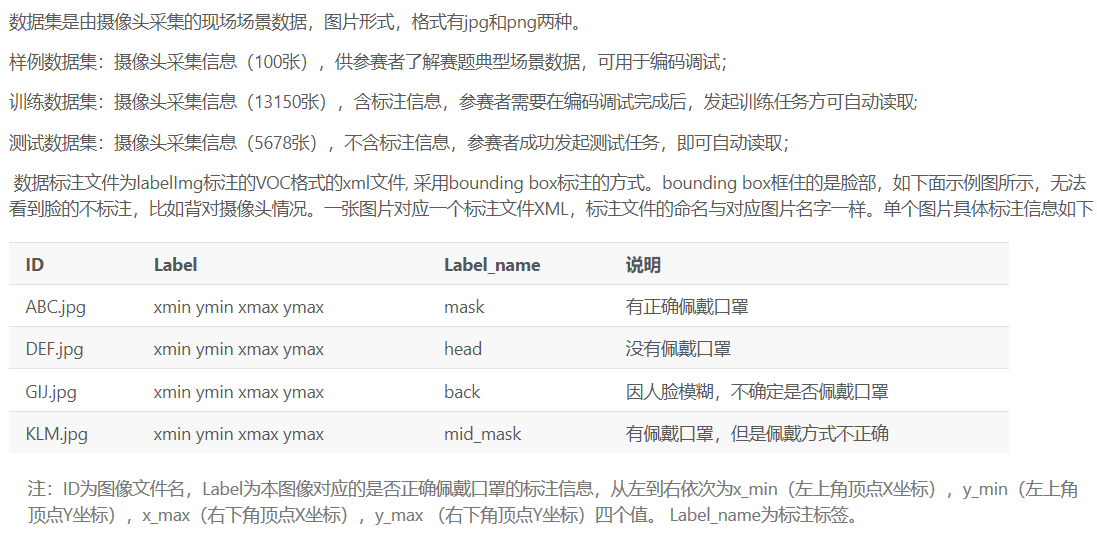
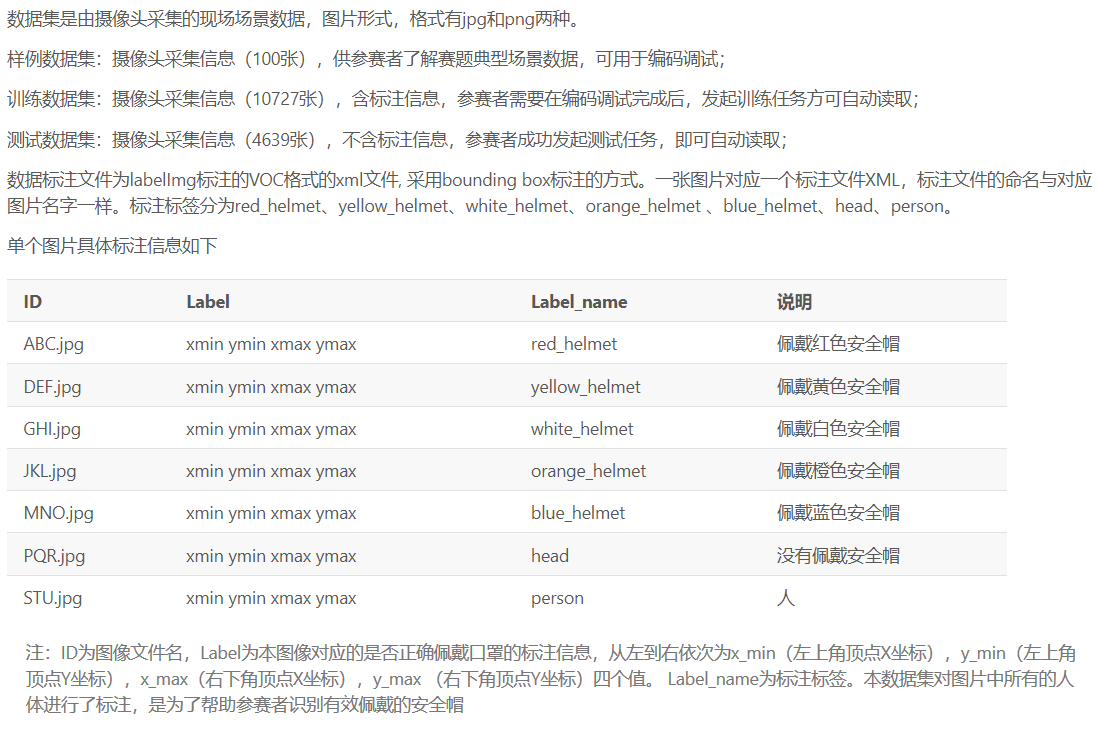
明确了官方给出的数据集样式及labels,就可以对数据集进行各种预处理,不同的模型要求的处理结果不一样,我把这部分的具体内容放在 github 里分别来谈。但可以看到的是,无论哪种模型,都会经历先转化为 VOC2007 的格式,然后或者如 yolov3 将 xml 里的坐标、labels 等信息按照顺序转化为 .txt 的行,方便 train.py 中读取;或者如 SSD 里那样将 xml 转化为 csv,然后再转化为 tfrecord 方便读取。
2.2 评分标准和输出规范
2.2.1 评分标准
在构建模型时,一定要先明确评分标准,这次比赛的评分标准是 F1-scores 占比 75%,FPS 占比 20%, 硬件能耗值 5%, 构成一个总体的 scores。

F1- scores
目标检测或者分类中最常见的衡量指标是准确率(你给出的结果有多少是正确的)和召回率(正确的结果有多少被你给出了),当然我们希望检索结果 Precision 越高越好,同时 Recall 也越高越好,但事实上这两者在某些情况下是有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么 Precision 就是100%,但是 Recall 就很低;而如果我们把所有结果都返回,那么比如Recall 是 100%,但是 Precision 就会很低。因此在不同的场合中需要自己判断希望 Precision 比较高或是 Recall 比较高。如果是做实验研究,可以绘制 Precision-Recall 曲线来帮助分析。
而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。F-Measure 是 Precision 和 Recall 加权调和平均:

当参数α=1时,就是最常见的F1,也即

可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
举个例子某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F1-scores = 70% * 50% * 2 / (70% + 50%) = 58.3%
FPS
FPS 是图像领域中的定义,是指画面每秒传输帧数,通俗来讲就是指动画或视频的画面数。其是测量用于保存、显示动态视频的信息数量。每秒钟帧数愈多,所显示的动作就会愈流畅。其中的 f 就是 Frame(画面、帧),p 就是 Per(每),s 就是 Second(秒)。用中文表达就是多少帧每秒,或每秒多少帧。电影是24fps,通常简称为24帧。
比赛这里指平均每秒检测多少张图片。
2.2.2 输出规范
口罩和安全帽的输出规范除了 name 以外都差不多。
{
"objects": [
{
"xmin": 320,
"ymin": 430,
"xmax": 500,
"ymax": 700,
"name": "mid_mask"
},
{
"xmin": 320,
"ymin": 430,
"xmax": 500,
"ymax": 700,
"name": "mask"
}
]
}
2.3 模型的选择和使用
结合评分标准可以看到,这次比赛主要考虑精度因素,次要考虑速度问题,所以在我熟悉的几个模型中可以尝试使用 Faster R-CNN+FPN 的 spp 版可能效果更好,但因笔者前一个比赛使用的是 Faster R-CNN 模型,想尝试尝试新的模型,且业界普遍的说法是做人脸检测都用SSD及其变形的算法,而YOLO V3性能是好过SSD的。所以一开始选择的是 YOLO V3 的 tensorflow 版实现,后来发现这个版本生成的权重是 .ckpt 的,而 openvino 转换所要求的前置权重是 .pb,纵观网上所有的大神攻略,虽然找到了将 .ckpt 转 .pb 的,但因转化代码其中要求明确输入所有的 模型输出节点名称,这里存在了两个坑导致权重无法有效转换,耗时两天无法解决。
后遂直接采用 YOLO V3 的 darknet 版实现,这也是原作者的实现方法,这次训练和内部测试倒是一马平川,但困难出现在了封装 EV_SDK上,官方给出的模板是行人检测 SSD-Inceptionv2 的 SDK,我凭借微薄的一点大学计算机基础里学 C 的积累,在捣鼓了三天后虽然外部测试给出结果了,但精确度是 0.0000,召回率 0.0002 的成绩告诉我,问题应该是出在四个部分。
- 封装过程中没有将 openvino 模型中的输出格式与封装代码匹配上,包括坐标、置信度、labels的顺序问题;
- 输出应该是 id=479 的 Result 层,但因为没有 output port 导致只能从 YoloRegion 层输出,而这样的 YoloRegion 层有三个,分别对应 13×13 ,26×26 , 52×52 的 feature map,我却只能够从最后一个
13×13 这一个层输出,如下图示;- YOLO V3 的坐标在训练时经过了变换,那么在封装时应该还要经过反变换,但我没有这一步;
- YOLO V3 训练后的代码没有 NMS 过程,我自行添加只能添加在 Result 层,而非 openvino 模型实际输出的 YoloRegion 层,这就导致了后面的检测结果绝大多数检测框是冗余的。

后来又不肯放弃心心念念捣鼓了半个多月的 YOLO V3,就首先在生成openvino推理模型前加了 NMS 的代码,又仔细研究openvino模型的输出格式,根据其重写了对应的SDK中算法实例的输出格式。这回成绩倒是提高了一些,精度是 0.2,召回率 0.05左右,再用常见的调参方法炼丹完,忙活一通,成绩丝毫没变化。这应该问题是出在openvino推理后的输出层默认成了上图中的 id = 478(只有这里有output层),而这儿的feature map是13×13,其余还有两个尺度的feature map在其他id层,却没有output层(PS:这个xml里的东西修改了没啥用,我本地试了,给另外两个加上output层或者直接把output层改到 id=479 的层直接报系统错误),这就导致了我这个检测时候的尺度很单一,且是最小的那种尺度,跟人脸的大小不符。
最后发现这里是真的无能为力了,就又中规中矩的采用了 SSD-Inceptionv2,这个的好处在于有官方给出的 SDK 封装程序,只用改动简单的几个地方就可以完成封装和测试过程。 坏处也是显而易见的,虽然源论文作者口口声声说超越这个超越那个,但我一看到他在论文中恰似不经意间提到的 “召回率比较低”,心里就蒙上了一层阴影。果然一检测完,一魔改完,准确度都达到 0.5 多快 0.6 了,召回率在 0.2左右… 当然, SSD 再低我感觉也不至于这么低的召回率,应该还是哪里有问题,但因为无法查看数据集,思考了半天也没找出问题源头。望有些想法的大大能告诉小白一声 ~ ~
2.4 训练和测试代码
见 github ~ ~
2.5 周边文件
这部分文件是数据集预处理部分、训练和测试之外的代码,包含了构建编译环境的库文件列表、构建镜像的 Dockerfile 指令、权重转换和 IR 转换的代码和指令,以及 shell 命令。
2.5.1 requirements.txt
这部分没啥说的,是将代码中所需要的库文件进行罗列,然后在 Dockerfile 和 shell 命令中书写指令 pip install 一下。
tensorflow-gpu==1.13.2
opencv-python==4.1.1
pandas
matplotlib
pillow
seaborn
tensorboard
2.5.2 Dockerfile
构建镜像的目的是为特定的程序提供特定的软件运行环境,而 Dockerfile 就是构建镜像的源代码,Docker 程序根据这份源代码在镜像中安装、拷贝文件、设置环境变量。在这个项目的开发中,包括两个 Dockerfile,分别用于构建训练代码运行环境和 EV_SDK 运行环境。
FROM 10.9.0.187/algo_team/cuda10.0-cudnn7.4.2-dev-ubuntu16.04-opencv4.1.1-tensorflow1.13-openvino2020r1-workspace
# 创建默认目录,训练过程中生成的模型文件、日志、图必须保存在这些固定目录下,训练完成后这些文件将被保存
RUN mkdir -p /project/train/src_repo && mkdir -p /project/train/result-graphs && mkdir -p /project/train/log && mkdir -p /project/train/models
# 安装训练环境依赖端软件,请根据实际情况编写自己的代码
COPY . /project/train/src_repo/
RUN python3.6 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r /project/train/src_repo/requirements.txt
RUN wget http://10.9.0.103:8888/group1/M00/00/02/CgkAZ15ibP2EQwGkAAAAAPNBqdc5432.gz -O /project/train/src_repo/pre-trained-model/ssd_inception_v2_coco_2018_01_28.tar.gz \
&& cd /project/train/src_repo/pre-trained-model/ \
&& tar zxf ssd_inception_v2_coco_2018_01_28.tar.gz -C ./ \
&& mv ssd_inception_v2_coco_2018_01_28/* ./

更详细的内容请参考Dockerfile官方文档
2.5.3 权重转换
权重转换是在训练完成后进行的,不同的模型训练生成的权重文件不一样,因而转换的代码也是不一样的,这部分也放在 github 里进行说明吧 ~ ~
2.5.4 IR 转换
IR 转换就是将生成的权重 .pb 文件转换为 openvino 模型以完成推理加速。这里贴出转换的命令代码,代码中的具体地址见相应 github。
- SSD (ODA) 部分
import sys
sys.path.append('/opt/intel/openvino_2020.1.023/deployment_tools/model_optimizer/')
import mo_tf
print(f'Exporting to OpenVINO...')
# 将模型转换成OpenVINO格式
proc = subprocess.Popen(['/opt/intel/openvino/deployment_tools/model_optimizer/mo_tf.py',
'--input_model', os.path.join(export_dir, 'frozen_inference_graph.pb'),
'--transformations_config', os.path.join(project_root, 'openvino_config/ssd_support_api_v1.14.json'),
'--tensorflow_object_detection_api_pipeline_config', os.path.join(project_root, 'pre-trained-model/ssd_inception_v2_coco.config'),
'--output_dir', os.path.join(save_dir, 'openvino'),
'--model_name', model_prefix,
'--input', 'image_tensor'])
proc.wait()
print('Saved.')
- YOLO V3 (Darknet版) 部分
python3 /opt/intel/openvino_2019.2.242/deployment_tools/model_optimizer/mo.py \
--framework tf --reverse_input_channels --data_type FP32 --input_shape [1,416,416,3] \
--input inputs --output output_boxes --tensorflow_use_custom_operations_config yolo_v3.json --input_model yolov3-voc.pb --model_name yolov3-voc-FP32
具体的转换细节见 OpenVINO官方文档 和 极市开发者平台文档说明 中<如何将模型转换成OpenVINO格式>部分。
转换成功后的报告输出如下:

2.5.5 Shell 命令
这个在代码中是以 .sh 结尾的文件,比如 start_train.sh 文件就是在训练时对整个过程中所要执行的指令进行整合打包,然后在外部或者 terminal 里直接用 bash /project/train/src_repo/start_train.sh 这一行命令即可运行。
#!/bin/bash
project_root_dir=/project/train/src_repo
dataset_dir=/home/data
log_file=/project/train/log/log.txt
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r /project/train/src_repo/requirements.txt \
&& echo "Preparing..." \
&& cd ${
project_root_dir}/tf-models/research/ && protoc object_detection/protos/*.proto --python_out=. \
&& echo "Converting dataset..." \
&& python3 -u ${
project_root_dir}/convert_dataset.py ${
dataset_dir} | tee -a ${
log_file} \
&& echo "Start training..." \
&& cd ${
project_root_dir} && python3 -u train.py --logtostderr --train_dir=training/ --pipeline_config_path=pre-trained-model/ssd_inception_v2_coco.config 2>&1 | tee -a ${
log_file} \
&& echo "Done" \
&& echo "Exporting and saving models to /project/train/models..." \
&& python3 -u ${
project_root_dir}/export_models.py | tee -a ${
log_file} \
&& echo "Saving plots..." \
&& python3 -u ${
project_root_dir}/save_plots.py | tee -a ${
log_file}
这里注意两个问题,一个是头部需书写 #!/bin/bash 以表明 bash 命令的运行;另一个是 Windows 下的 shell 命令和 Linux 下的是有一些区别的,比如换行的标识符不同,这会导致从一个系统上的代码复制到另一个系统上会出现 error。
2.6 EV_SDK 代码
因为这里的代码时纯 C++ 编写的,笔者琢磨半天,对此也不太懂,这里就只贴出官方例程中的代码目录,具体的一些测试和编写改动请参照 github 里的 ev_sdk 部分的 README.md 部分,官方虽然没有给出这个的写法,但说明还是很详细的 ~ ~。
ev_sdk
|-- 3rd # 第三方源码或库目录,发布时请删除
| |-- wkt_parser # 针对使用WKT格式编写的字符串的解析器
| |-- cJSON # c版json库,简单易用
| |-- darknet # 示例项目依赖的库
|-- CMakeLists.txt # 本项目的cmake构建文件
|-- README.md # 本说明文件
|-- model # 模型数据存放文件夹
|-- config # 程序配置目录
| |-- README.md # algo_config.json文件各个参数的说明和配置方法
| |-- algo_config.json # 程序配置文件
|-- include # 库头文件目录
| |-- ji.h # libji.so的头文件,理论上仅有唯一一个头文件
|-- lib # 本项目编译并安装之后,默认会将依赖的库放在该目录,包括libji.so
|-- src # 实现ji.cpp的代码
|-- test # 针对ji.h中所定义接口的测试代码,请勿修改!!!
3. 引用部分及文档补充
- .pb文件的解释:https://blog.csdn.net/u014264373/article/details/79943389
- openvino相关的解释:https://blog.csdn.net/shanglianlm/article/details/89286250
- SDK与API:https://www.jianshu.com/p/dd2eff92e8fc
- Dockerfile——构建镜像命令:https://www.runoob.com/docker/docker-dockerfile.html
- F1-scores:https://blog.csdn.net/kdongyi/article/details/82930913
- shell文件的书写:https://www.cnblogs.com/tinywan/p/6835531.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144920.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...