大家好,又见面了,我是你们的朋友全栈君。
陈迪豪,第四范式先知平台架构师。个人兴趣广泛,在开源社区比较活跃,维护了1600+ star的容器Web管理平台Seagull。大二加入了小米做Android移动端开发,然后有幸学习到后端基础架构技术,参与了HBase、ZooKeeper等社区开发,并且开源了NewSQL依赖的全局严格递增timestamp服务chronos,对分布式存储有一定了解。后来加入云服务创业公司UnitedStack,负责存储、容器、大数据业务,参与了OpenStack、Docker、Ceph等开源项目,在Austin OpenStack Summit上分享了Cinder多后端存储相关的技术,期间也获得了AWS Solution Architect认证。目前从事云深度学习方向,负责深度学习平台的架构和实现,对容器调度系统Kubernetes和深度学习框架TensorFlow有一定了解。
我是第四范式的架构师陈迪豪,我们从14年就开始做机器学习,现在机器学习特别火,让我们也感到很困惑,因为大家把跟计算机有关的都说成是智能,或者是AI。根据我的经验,标题里有AI的分享,10个可能超过8个都有点忽悠人。但是昨天于老师的“小诗机”和洪强宁教授的chatbots都讲得特别好,根据8/10原则我是有点压力的。今天给大家介绍一下AI相关算法实现,希望大家理解它的实现,对真正的人工智能或者机器学习有一些新的理解。
我是ECUG的新人,首先自我介绍一下。我在13到14年参与了HBase和Hadoop的开发,之后去做OpenStack,也是社区的贡献者,大家看得出来我前两年做的是Infrastructure。我最近在做TensorFlow和机器学习相关的东西。我也是一个开源项目Seagull的作者,现在在第四范式做先知平台的架构师。今天的议题有三个:
-
人工智能与机器学介绍
-
机器学习算法原理与实现
-
云机器学习平台架构实践
人工智能与机器学习介绍


图 1 这些是人工智能吗
机械自动化。昨天洪教授讲到了第一工业革命就是蒸汽机,第二次是流水线。其实很早以前我们就有机械自动化,我们就用电控制舵机做一些重复的操作。但是最近我们看到了更多是把机械自动化描述成人工智能工厂。然而很多工厂只是用到了机械,但是却被描述成智能工厂。
字符串生成。前一阵子还发生一个笑话,Facebook他们生成字符串的应用有个bug,导致生成乱码,却被媒体宣称为机器人自己发明的一种语言,它们在交流。其实并不是,在那种模型里面他们用机器学习生成字符串,但生成字符串并不需要人工智能,还有很多别的方法。
验证码识别。还有比较可笑的验证码识别,这也是很多年前的技术了,但被某电视台的新闻栏目,宣称他们抓获了全球第一例人工智能黑客技术犯罪,其实是有人提供验证码自动识别的服务而已。
作为我们行业内的人来看,这些都不是人工智能,只是满足PR或者行业投资的需求,从技术实现的角度,这些绝大部分都不是人工智能。
图1的右边是我生成的一个Numpy数组,可以用表示一个AlphaGo的模型。有人以为AlphaGo会自己跟自己下棋,并且自学了围棋的规则,甚至开玩笑说自己悄悄地用网络对战平台和别人下棋。但从专业的角度来看,AlphaGo只是这样一个多维数组,里面有很多浮点数代表了模型的权重。如果把AlphaGo打印出来,它就是一个数组,它的输入就是一个表示棋盘的Tensor,输出是下子的概率和赢棋的概率。而且AlphaGo围棋的规则是程序员编码硬实现的,包括怎么判断游戏的输赢。这些都是目前人工智能或者说机器学习不可能解决的。


图2 机器学习定义
我们来看一下人智能它比较经典的定义,这是一本机器学习教材,作者Mitchell被公认是机器学习之父。它对机器学习的定义:一个计算机程序,它在某一个task里面,根据以前的经验experience,可以通过计算来提高performance。总结一下就是:在一定的场景里面,我们定义一个指标,如果我们有标记好的数据,也就是样本,然后通过计算得到一个模型。模型的输入是样本,输出是预测的概率。所谓的机器学习就是一个计算的过程,无论是训练还是预测。

图3 机器学习应用
图3是一些典型的机器学习应用。给我1000张标记为猫的照片,得到一个识别猫的模型,并且正确率越高越好。给我1000万盘围棋的棋局,得到一个AlphoGo模型。给我信用卡的历史操作记录,得到一个反欺诈模型。
怎么得到这个模型其实是最复杂的。数据往往是非结构化的,有各种类型,我们没有一个得到模型的统一方式。而且有些是分类模型(识别猫),有些是生成的模型(GAN),它们的应用场景都不一样。
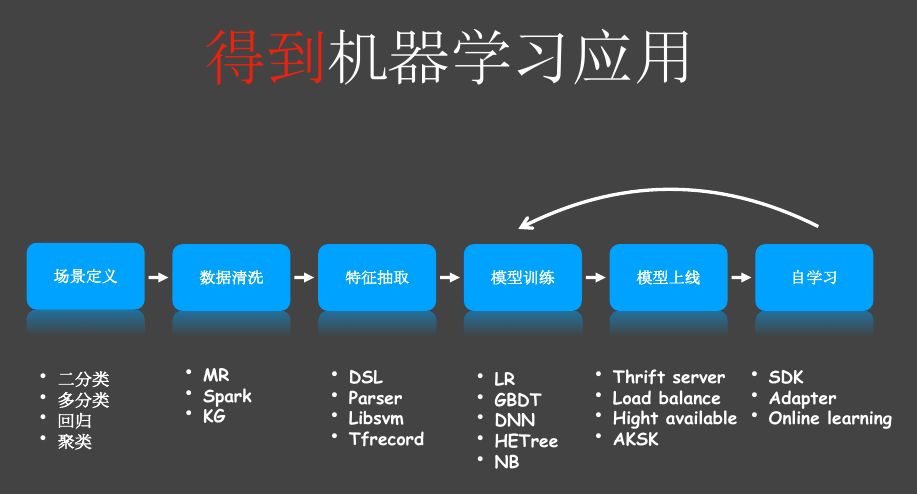
图4 得到机器学习应用1
模型的训练过程很复杂。我们都知道给我1000张猫的图片,能得到一个识别猫的模型。问题是能不能训练出一个比GoogleNet或者ResNet效果更好的模型。真正做机器学习应用的,都需要做到图4中的过程,并不是说给我猫的图片就可以得到很好的模型。一般的过程,包括这几个部分:
定义模型的使用场景,也就是业务逻辑。场景定义有很多种,包括二分类,多分类。很多时候我们在做一些银行的业务,目标是提高利润。但这并不是机器学习业务能理解的东西。假设这是一个营销的业务,系统会给用户发送理财产品推荐的短信。我们把场景定义成二分类,即推荐什么样的理财产品用户的购买概率更高,对这个理财产品可以做模型预测,即买或是不买的概率。
数据清洗。数据清洗跟传统的大数据处理其实没什么区别,有些特征可能需要补全或者去掉。用到的技术就是,MR(MapReduce)或者Spark,还会用到Knowledge Graph的领域知识。
特征抽取。我们要从数据里生成一些特征,特征其实也是数据的字段,但只是用于机器学习。例如数据里可能有人的性别和年龄,但生成的特征可能是几十万维甚至几百万维的。例如对于线性模型,我们不能将原始数据直接放进去。怎么做特征抽取呢?这跟后面使用的模型框架有关,我们必须生成框架支持的格式。在真正做的时候我么会定义一个特征抽取的DSL,用户通过简单的描述就可以将生成Spark任务。对DSL我们做了一个AST的parser,可以支持像libsvm或者TensorFlow的TFRecord格式。
模型训练。在训练的时候选择就很多了,业界已经证明的一些机器学习算法有LR、GBDT、DNN、NB(Naive Bayes)等。还有我们自研的将离散值转连续值的算法HETreeNet,因为树模型对连续值支持更好。我们可以使用不同的框架,例如TensorFlow就是一个很好的DNN框架。
模型上线。模型上线以后就是一个服务,我们可以部成一个微服务或者单机起的一个进程。我们目前用Thrift server。上线以后同样要解决例如负载均衡和高可用的问题,还有认证授权,我们使用AKSK的加密方法。
自学习。跟普通的应用不一样,大部分机器学习模型都是有时效性的。例如头条里面的推荐,最近一个月大家都在关注娱乐,那么娱乐特征可能是重要的,那我们就要拿增量的数据来继续训练模型。这里我们就需要一些SDK的功能,还要支持不同的数据源。模型训练可能是离线的,我们从Database里取出数据就可以了,在自学习时可能就要接Kafka或者一些Streaming的数据。我们模型的框架还支持online learning,也就是在线更新模型权重。
今天会花比较多时间给大家介绍两部分,第一个是机器学习的算法,第二是怎么搭建一个机器学习的平台。
机器学习算法

图5 逻辑回归1
机器学习的算法很多,这里不能一一介绍。主要给大家介绍逻辑回归的实现。现在DNN很火,大家都在聊DNN、CNN、LSTM。做图像、自然语言还有语音处理这些非结构化的数据里面会用到CNN或者LSTM。但在我的工作场景里面,大部分都是银行的业务,我们用的最多的模型是LR(逻辑回归),包括我同事在百度凤巢做的CTR预估。不同的机器学习算法都可以解决像二分类或者回归的问题,但实现原理和针对的数据是不一样的。如果大家有看AlphaZero论文,就知道它的算法并不是用逻辑回归,而是用ResNet,等一下会介绍AlphaZero的实现。但是这里面有一个问题,我们可不可以用逻辑回归来代替ResNet?答案是可以的,其实AlphaGo是一个蒙特卡洛搜索和一个NN神经网络,之所以不用逻辑回归是由于逻辑回归是一个线性模型,没有很强的表达能力,如果我们的特征做的足够复杂,也可以训练一下模型LR-based的AlphaZero模型,但肯定达不到DeepMind的效果了。
这里介绍一下逻辑回归的实现。LR是一个监督模型,也就是必须要有训练样本。 LR也是一个线性模型,就是说你给的特征是有线性关系的,例如我们训练一个模型,可以根据年龄来预测收入。我们通常认为年龄越高收入越高,其实并不是这样的,例如超过了60岁,年龄跟收入是成反比的,这里就不能只用年龄了作为特征。它是高性能的,等一下会介绍,只需要做一个加法就可以了。LR是高性能的,因为一次预测只需一次加法运算,这跟神经网络要做矩阵的乘法和加法是不一样的。LR的可解析性强,它的每个权重都是人可以理解的,有一定的含义。LR的扩拓展性强,很容易实现一个分布式的LR,支持亿万维的特征。即使是TensorFlow也无法支持这么高维度的模型。

图6 逻辑回归2
图6是一个例子。逻辑回归需要的样本是用数字编码好的,我们原始的输入可能是字符串,男和女,或者是一个英文,这就需要特征抽取进行编码。像年龄,刚才提到了,因为逻辑回归是一个线性的模型,因此并不会把年龄作为特征,这里简单做了一个分桶。这里有一个隐藏的含义,假设年龄0到30,预测它的收入是大于50万,两者是线性相关的。如果是成正比的话,这个权重就会大于0,年龄越大这个权重得到的越大,实际上并不是这样的,做机器学习里面有很对trick,比如说这个分桶不一定有效的,我们把它做成多分桶的,甚至每一岁做一个特征,这里可能就有80个特征。这是一个简单的例子,如果我们可以收集到这样一些样本,把它进行0-1编码,我们就可以训练一个LR的模型。实际上模型是什么?DNN的模型是一个矩阵,而LR的模型就是一维的数组,数组的长度跟特征的维度一样多的,每个特征都对应一个权重。

图7 逻辑回归3
当我们来一个新的样本,知道他的性别男,年龄27岁。怎么预测他的收入是不是大于50呢?逻辑回归的算法很简单了,数据维度跟特征维度是一样,乘以样本,把对应维度里面的值相加。如果场景是二分类,经过激活函数得到一个值,大于1的我们就认为是1;如果它是一个回归的问题,就不需要激活函数了,得到的就是一个预测值。
LR是很简单的,前面我们看到图象分类,AlphaGo的下棋都可以用这个简单的模型。包括我们做的信用卡的反欺诈,可以把用户信息、消费记录,包括消费的时间地点进行编码。更复杂的情况,我们把年龄和性别做一个组合,会生成新的特征,即男30到60岁,女30到60岁等。我们可能会发现只有在特定的性别和年龄的组合上,权重才是更高的。我们如果把原始特征这样编码,LR学不出这种非线性的变换,这个时候需要有更强大的特征工程能力,可以对这种特征做任意的组合,或者根据我们的业务经验生成更好的特征。以前在凤巢的时候就是不断地做特征,不断地加,最后发现效果特别好的特征,最后准确率就提高了。现在大家都说DNN可以自动调参,但在真实场景下这个过程是不可避免的。即使用很复杂的模型,我们的特征不做分桶交叉,也很难得到很好的模型。
如果是做图像处理,我们就在每一维里记录图像的像素值,然后把像素值最为一个特征。如果做图象分类,肯定不会用逻辑回归,因为图象的特征,它并不是跟你的目标线性相关的,我们只能用更复杂的模型如CNN和DNN来表达这种能力。
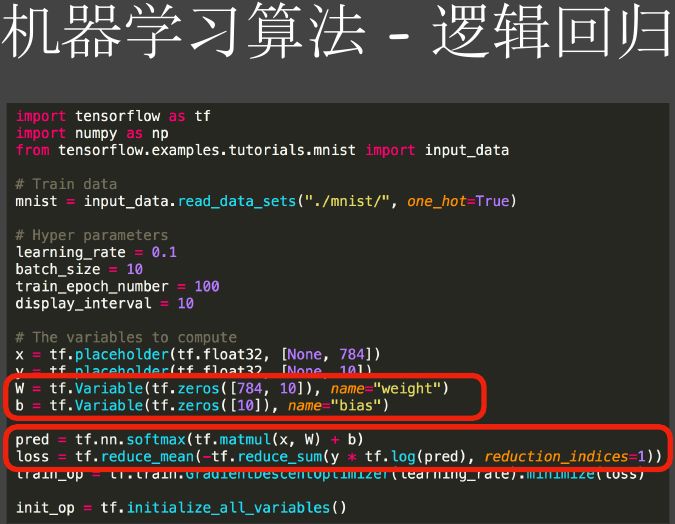
图8 逻辑回归3
怎么实现逻辑的回归?如果用TensorFlow实现就很简单,图8就是一个完整的实现逻辑回归模型,可以把图片加载进来进行多分类。标出来的部分(第一个红框)定义了一些Variable,这里面就是我们的所谓的模型,这里定义了一个矩阵,维度是784×10。为什么784?因为我们用的数据集是手写的数据识别的数据集,大小是28×28,它的象素就有784个,它的模型也是784,因为它是10分类,它的模型其实就是784×10,把这个分类模型打印出来,得到的是一个矩阵,有784行,每一行有10列。
下面(第二个红框所示)定义的是我们模型训练的方法,我们可以定义不同的损失函数。 给一个模型,不同的权重乘以图片的输入,再跟真实的Label来比,它们相差多少,不同模型可以用不同的指标。图像分类我们经常会用这种交叉商;如果是一个回归的问题,例如相乘以后得到一个预测收入(前文的例子),这边是实际的收入,我们怎么描述它们的差别,我们可以做一个相减,然后求平方或者绝对值。这里是为了让TesnorFlow知道你怎么描述loss,tenserflow有一个自己求梯度的系统,会给你求函数的梯度,让模型往梯度最低的地方走,然后让loss降低,loss越低表示预测值和真实值相差越小。实际上我们可以自己实现一个自动求梯度的框架。

图9 逻辑回归4
总结一下,逻辑回归是一个简单而强大的机器学习算法,广泛用于推荐系统,CTR等场景。LR是一个线性模型,所以使用前需要一些特征工程的步骤。LR的模型是一维数组,数组里面的权重可以用浮点数或者双精度浮点数来表示,数组的长度和特征的维度相同。LR要定义loss函数作为指标,如CrossEntropy。LR训练时要优化loss,流行的方法是梯度下降算法,它有很多优化器,比如Adagrad优化器。 LR特别容易训练,预测的性能特别高,也很容易实现分布式训练。怎么实现分布式训练呢?一般我们会有一个Parameter server,存它的模型,它的模型就是数组,我们把这个存起来,这个模型可以很大。Parameter server在工程上就是一个KV数据库,可以用HBase,如果单机放得下也会用Redis,甚至在内存里面也可以实现Parameter server。一般不会用NoSQL去实现, 昨天洪教授也提到了权重更新可能很频繁,并不需要每训练一次就把真实的值写到NoSQL里面,写到NoSQL里面会落盘,但我们并没有一致性的要求。实际上我们很多Parameter server都是基于内存实现的,它挂了会有丢数据的情况,但我们可以定期做snapshot,保证只有最新数据就可以了,哪怕挂了通过重新训练也可以达到类似的效果。

图10 AlphaZero
AlphaZero是AlphaGo最近的升级版。大家看pr稿上说AlphaGo用了一些人类的知识,而AlphaZero则摒弃了人类的知识,通过自我博弈得到更好的效果。其实AlphaZero只是把棋局预测输赢的部分用一个神经网络替代了。AlphaGo每下一步棋该怎么评判这一步棋好不好?AlphaGo里面有一个快速走子网络,输入一个棋局,预测一下这个点,看赢的概率是多少?这个快速走子网络是用一些人工的规则,例如以前根据人类的棋局得到一个公式,不一定是神经网络。输入棋局然后输出一个结果,这一部分以前是依赖于人类的一些历史棋局。而AlphaZero变化的部分是把规则给去掉,不用以前人类的数据,而是用神经网络,让神经网络学习。如果我们只给一个棋局,我们正在比赛,下一个下棋,不管用CNN还是什么,不可能知道这个棋赢的概率多少。所以在AlphaZero里面,每个样本产生出来,不可能每下一步棋就生成一个样本,然后告诉你下这步棋赢的概率,而是必须把整盘棋下完,这里面有700步棋,一直让它自动下,下完以后,最后赢了,那么这700步棋里面赢的概率会加1,最后是用统计的方法。
AlphaZero里面的算法最重要的是蒙特卡罗树搜索,把它打印出来是神经网络。其实也可以用简单的模型来替代。AlphaZero使用蒙特卡罗树定义围棋规则,例如机器人不知道我已经下子的地方不能再下,这是在写代码的时候写死的。
AlphaZero是有监督的学习,并不是无师自通,或者自我博弈。其实自我博弈一开始随便下,下了一些棋局,根据这些棋局来学习的,但它比其他监督学习好的地方是不需要人类去标数据。它这个学习相当于模仿前面的棋局,用神经网络很容易做,把AlphaGo以前训练好的棋局,然后写一个DNN,得到一个跟以前棋局下法拟合地最好的模型。
AlphaZero用到了增强学习,自己跟自己下,把赢棋的那部分拿出来,认为这部分是好的样本。然后去学好的样本,得到一个新的模型,新的模型与旧的模型对比,赢出来的就作为一个新的好样本。它其实是用了一个增强学习,生成更好的样本,而且是用有监督学习的方法生成这个样本。大家不要觉得它很神奇,它并不是真的掌握了围棋的规则,其实都是计算出来的。但计算很有技巧,样本不是随便给的,也不是人类最顶尖的棋局给他,而是自己跟自己比,把赢的棋局作为样本。其实训练了很多的模型,有的模型训练完了以后效果不如前一个模型,到后面直接扔了。
最后怎么表达这个模型呢?给一个棋局要怎么告诉我赢棋的概率是多少?里面是用一个ResNet,它的好处是层数可以做得特别多。这个模型就是一个function,输入特征,也就是当前棋局的形势,输出概率。这个效果比我们用专家规则好。
AlphaGo只适用于Combination game。零和,即一定会有输赢,没有合作的机制;完全信息,即双方都可以看到棋局;无随机,即每一个操作都是确定的。它不能迁移到德州扑克,麻将之类的游戏。

图11 MinMax
这里介绍博弈论里面比较简单的算法,通过简单的MinMax算法,然后过渡到AlphaGo的蒙特卡罗树搜索。每个圆圈表示你的下法,可以选择左边或者右边。当你选择到左边或者右边以后,对手也可以选择左边到右边。这个棋局很小,我们可以枚举所有可能的情况。我们的目标是让最终得分最高。显然正无穷是最高分,但是上一局是对手的回合,对手看到正无穷肯定只会选10,下一回合我会在10和5中选择10,但到再下一句对手会选择-10。
这种博弈的游戏并不是自己找一个最优解就可以了,你得考虑对方。对方有可能很傻,直接让你赢,也有可能跟你一样聪明。在这个游戏里面我们既可以枚举所有情况,也可以用一个MinMax的算法找最优解。这个算法很好理解,在某个阶段是对手的回合,我们假设对手很聪明的,总会选择最低分(min)。我们的回合里面就在可以选择的范围里面选择一个最高分(max)。假设对手是很聪明的,就会选择一个更低分的给我。如果我们玩这个游戏,我们一开始应该选择右边,这里就达到了博弈论里面的纳什均衡点。我们做出决策,对手也做出决策,当双方不能通过改变决策拿到一个更优解的时候,我们就达到了一个均衡点。这是解决博弈论里面的算法,你要遍历所有的情况才能找到最优解。大家听到过alpha-beta剪枝,其实就是优化MinMax的算法,不需要每个值都算一遍。

图12 蒙特卡洛搜索树
围棋可以这样做吗?刚才说了基于蒙特卡罗树,也是一个数的结构。这是一个棋盘,有361种可能,当我下某一个子时候,对方有360种可能,这样我们可以得到一个维度超高的树结构。假设计算能力足够,我们知道最后一个回合是输还是赢,我们假设对方让我输,就不选择这种方法了,每次都选择自己最优的,假设对手也让我选择输的,理论上可以用MinMax算法解决AlphaGo的问题。这个算法很简单,但是不能用在AlphaGo里面,因为它的维度很大,每个点都有300多个选择,300多层,几乎不可能遍历,即使有alpha-beta剪枝也解决不了。
图12就是一个蒙特卡罗搜索树。我们要在一定的computation budget里面,找到效果比较好的分支,我们可以自己模拟下棋,下完发现这一个分支赢了,那就认为这个可能是好的分支,但对方改变一下策略你可能就输了。蒙特卡罗树要解决的问题是怎么样找到一个好的分支,你可以尝试很多次,但是你不能无限次的尝试。换言之就是怎么权衡Exploration和Exploitation的问题。Exploration就是有的棋没有下过,所以会尽可能探索一下,但是却不可能穷尽。如果我们只有探索的策略,就是一个随机的策略,哪儿没有探索过就去探索一下,这种算法效率很低的,没有启发式的,就是盲目的探索,得到的有效的样本是很少的。Exploitation就是当我发现走这边可以赢,我尽可能前面都走这边,下面不断的稍微调整一下,把这一块都搞清楚了,以后如果继续都这样下,后面就会赢,探索空间很小,有些是没有探索过的。怎么解决这两个问题呢?比较简单的就是给一个权重,比如说0.01,我们每次生成一个随机数,1%的机会会去探索新的节点,否则就会利用旧的节点。
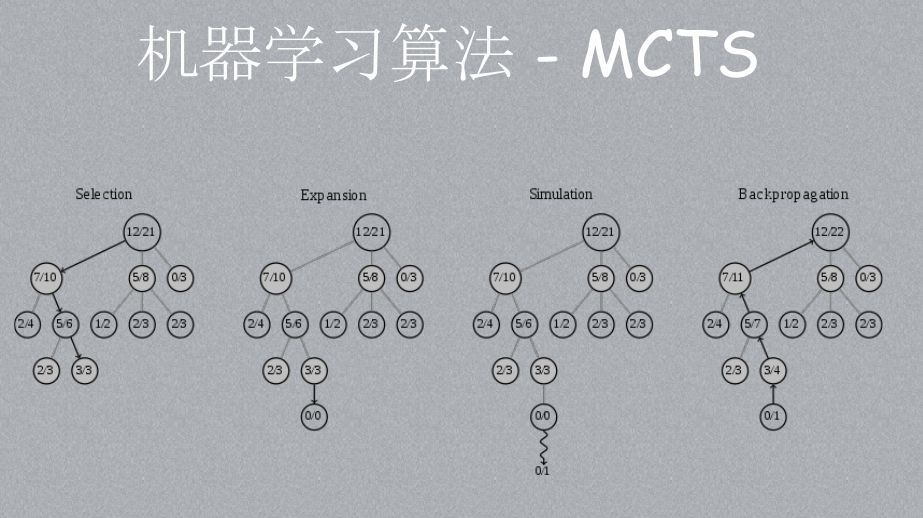
图13 蒙特卡洛搜索树
MCTS是一种启发式的搜索算法,在有限的计算空间里面可以找到相对好的结果。它这里并不一定能够给你找到绝对值。能不能证明AlphaGo一定是最好的下法?肯定不能,因为它并没有探索完。但是通过这种方法,找到了一种胜率又高,探索过的地方又比较多的算法。图13是原生的MCTS的四个阶段。包含了几个函数:
-
选择(selection),上面有一些数字,左边是赢的次数,右边是被访问的次数,父节点是子节点的和。例如最右边的节点是0/3,表示这个节点已经探讨过3次,但一次都没赢。例如围棋的第一步就下在边角,真正测试过边角的情况,测了几次,每次都输,这个时候下在边角的概率其实很低的,但是它的概率又不能低为0。MCTS会选择赢的概率大但访问次数不是很多的节点。例如这里选择了3/3节点。找赢的概率最大,并且访问次数不是很多的节点,
-
扩展(expansion),在刚才选节点里面增加一个新的节点,然后初始化为0/0。
-
模拟(simulation),用这个节点跑一次,相当于围棋里面真正下这一步了。我们这里用的是快速走子网络,下到这儿以后,我用一些专家规则让它跑,最后发现很可能到这儿是输的
-
反馈(Backpropagation)反馈到上面,这条路多访问一次,赢棋的次数并没有增加。
这是一种启发式的算法,访问次数也是一个参考的因素,若发现访问次数太低,会先忽略胜率,我去试一下看会不会赢。这就是数搜索里面的一种启发式算法,现在的计算能力很强,这种算法就很好的。
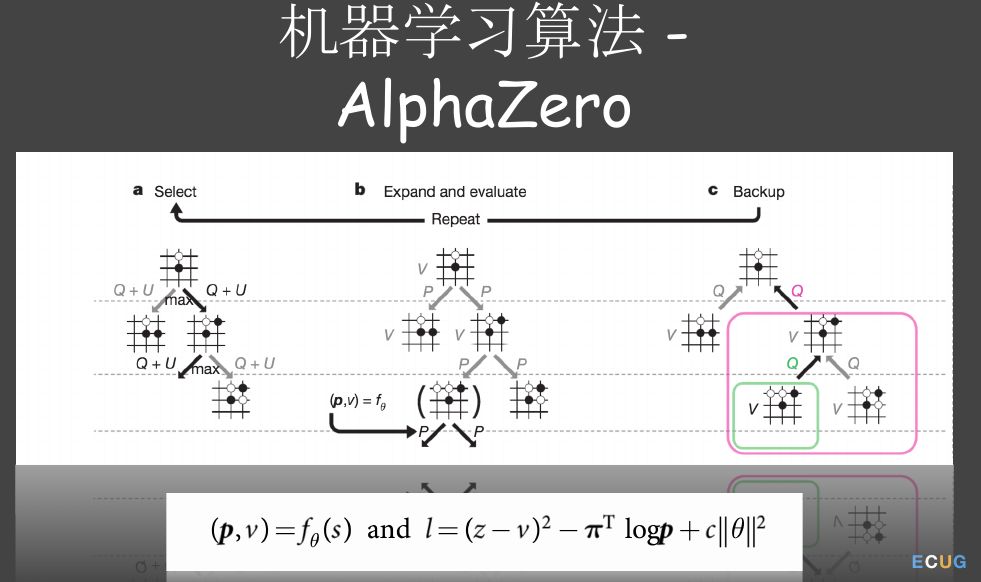
图14 AlphaZero
图14是从AlphaZero论文里面截取出来的,它也有四个阶段,名字与前文中的类似,因为它用的就是MCTS。一开始的神经网络的预测是很不准的,初始化会随机生成一些浮点数,乘起来发现赢棋概率和真实概率并不一样,我们就要训练这个模型,就需要生成样本。模型里面有一个值但不知道这个值好不好,就需要把整个棋局下完,如果赢概率就设为1,否则设为0。最后是loss函数的实现,这里用了两个神经网络,有两个权重,所以loss会有两部分。

图15 AlphaZero
图15中有一些公式和定义,这里不一一介绍了,大家可以感受一下。围棋是一棵树,怎么选节点考虑到两个因素,一是节点赢棋的概率,比如说70%的赢棋,赢棋概率越大,下次多选这个;C是一个常亮参数;P和V都是神经网络生成的参数。标准的UCB里面有一个权重(1/C),访问次数越大,UCB值越小;你的访问次数越小,这个值越大,大到一定的程度可能就不会考虑这个因素了,让他去多探索。除了这些还有一些优化,让它尽可能的早期的时候多探索。

图16 自动求导
用户在写tenserflow代码的时候只是把loss函数写上去了,但在训练的时候要让loss变低,需要求导。tenserflow其实做了这个事情,我们自己也可以做。这是很简单的数学问题,算子的求导在数学上已经有一个公式了(变量的加减乘除求导公式)。使用tenserflow时会定义很多的op(加减乘除),在op的实现里面就给你实现了求导的规则。把所有数学上可能用到的一些操作,把它的算法写出来,可能用到数学上面的链式法则。我们其实也可实现自动求导。梯度下降的方式其实就是求导完以后让所有权重加上梯度乘以learning rate。

图17 自动求导
我们自己做了求导的实现,发现用纯Python的实现会比tensorflow快很多,做10万次加法大概是12秒,用Miniflow大概是0.16秒。包括跑减法还有逻辑回归的训练,这是特定场景下的测试,没有考虑分布式和GPU。tenserflow后端是C++实现的,它的主要开销在python和C++的交互,这一步非常耗时,比纯python实现的op性能还要低很多。
云机器学习平台架构实现

图18 架构设计
只用tensorflow就可以搭建云机器学习平台了吗?tensorflow实现LR可以在单机上训练10亿维稀疏模型。大家知道10亿维的模型大小是一个十亿维的浮点数数组,如果内存够大我们可以支持更多,但是单机不可能支持10万亿维,因为10万亿维就是400T的量级,即使用分布式的训练也很难找到400T的内存。解决方案是考虑到定义模型时会初始化,没有出现过的值都用0表示,我们自己实现的框架样本格式可以很灵活。开源框架与自研框架的集成。
我们自己的平台架构设计里面要考虑的是支持开源的tenserflow,因为它很流行,我们可以在上面实现很多模型。另外我们自研的C++机器学习框架也要支持。
对异构计算集群的支持,比如DNN需要GPU。我们需要支持异构计算集群(CPU、GPU、虚拟机、云平台)。
最后一个是机器学习工作流的支持。机器学习的工作流是确定的,应该有更好的工具来支持。
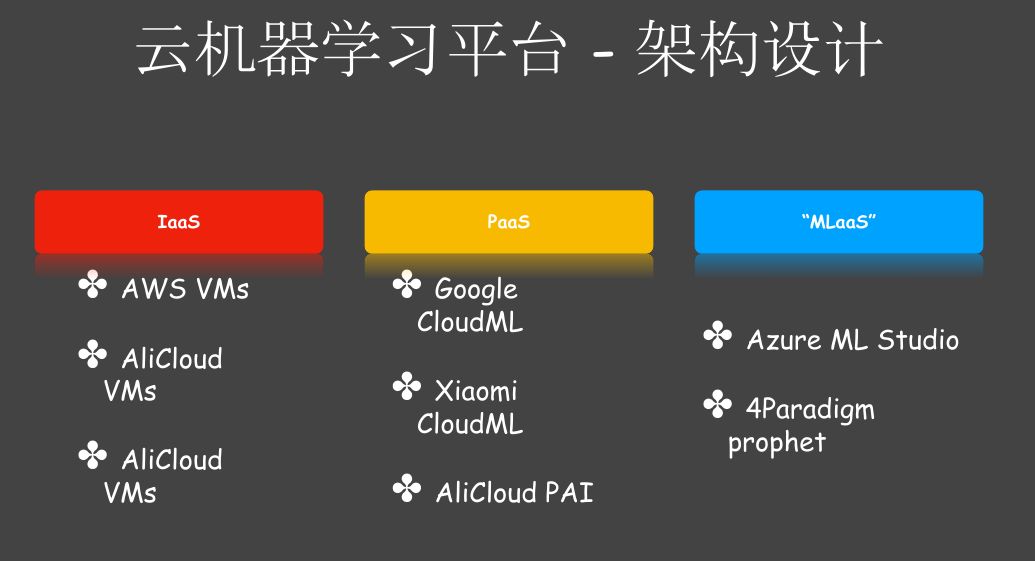
图18 架构设计2
机器学习平台分类有:
-
IaaS只提供虚拟机服务;
-
PaaS可以解决什么问题呢?你把代码写好提交到这个平台上面,它会给你起相应的运行环境,把模型训练出来。但并没有解决前面做数据清洗,特征抽取,包括自学习这些都没有包括。
-
MLaaS是介于PaSS和IaaS之间的,它有一个工作流的引擎。可以把整个机器学习工作流实现。
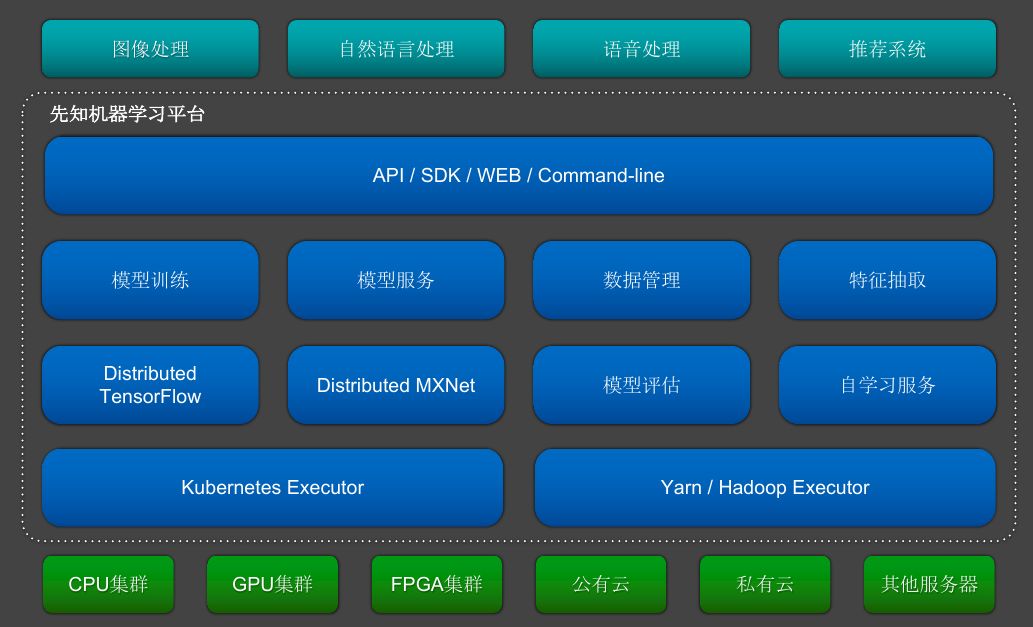
图19 机器学习平台
图19是我们自己实现的平台。上层是我们的业务,有非结构化的数据,有传统的推荐系统。底层是我们的计算资源,包括公有云、私有云、GPU。我们底层最依赖的是两个调度框架:Kubernetes Executor和Hadoop Executor。在调度框架上面实现我们的模型训练、模型服务、数据管理、特征抽取、模型评估、自学习服务,对外提供API。
如果我们只是要实现Google CloudML的功能,其实很简单。我们都知道Kubernete是一个通用的任务调度服务。对于tenserflow的运行环境我们打包成一个Docker镜像,并不直接用Kubernete的API,我们可以对API做一定的封装。

图20 工作流
我们真正做一个业务,除了做训练,我们还需要做数据引入、特征抽取、模型评估。模型训练只是简单的部分。其实这一部分在小米的时候,我们让用户自己做的,自己做一些需求。在第四范式我们希望用户通过拖拽的方法定义一个工作流。工作流的算子应该是可拓展的。
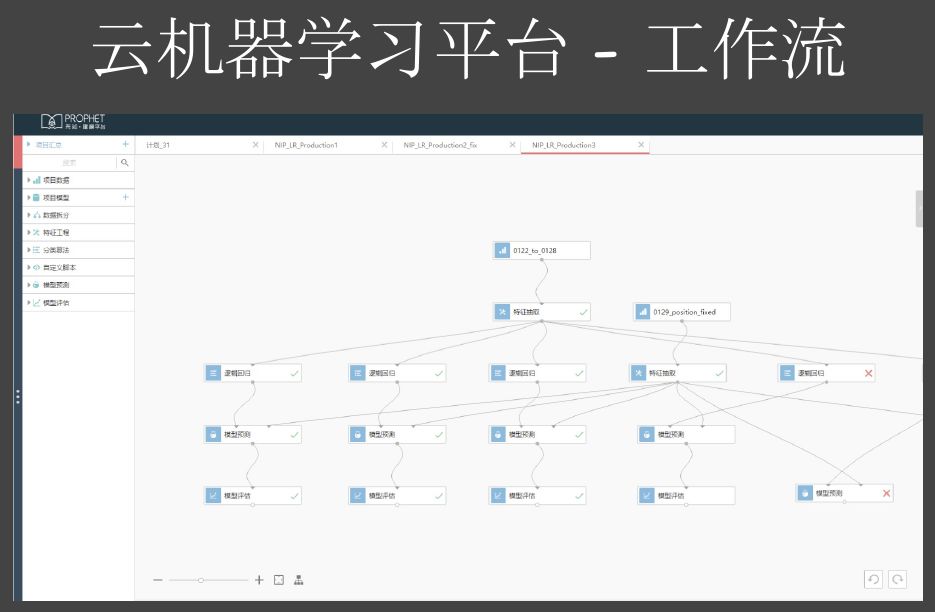
图21 工作流2
这是工作流的截图,没有做动画。这边有数据引入、数据拆分、特征工程、训练算法、模型预测,有几个模块,用户可以通过这个模块把算子拖出来。只要你懂这机器学习业务,不需要自己去写spark,不需要写LR算法的实现,你只要拖一个算子过来,把这个线连起来,单机跑一下,就可以完成机器学习的业务了。

图22 算子
我们设计上,希望算子通用的,可以解决任意的问题。机器学习其实是一种计算的方式,数据拆分特征抽取也是。我们定义了最简单的抽象接口,用户要实现自己的算子,只需要实现execute的方法就可以了。 我们现在大约提供了十种数据处理算子,十多种机器学习算子,以及三种autoML的算子。
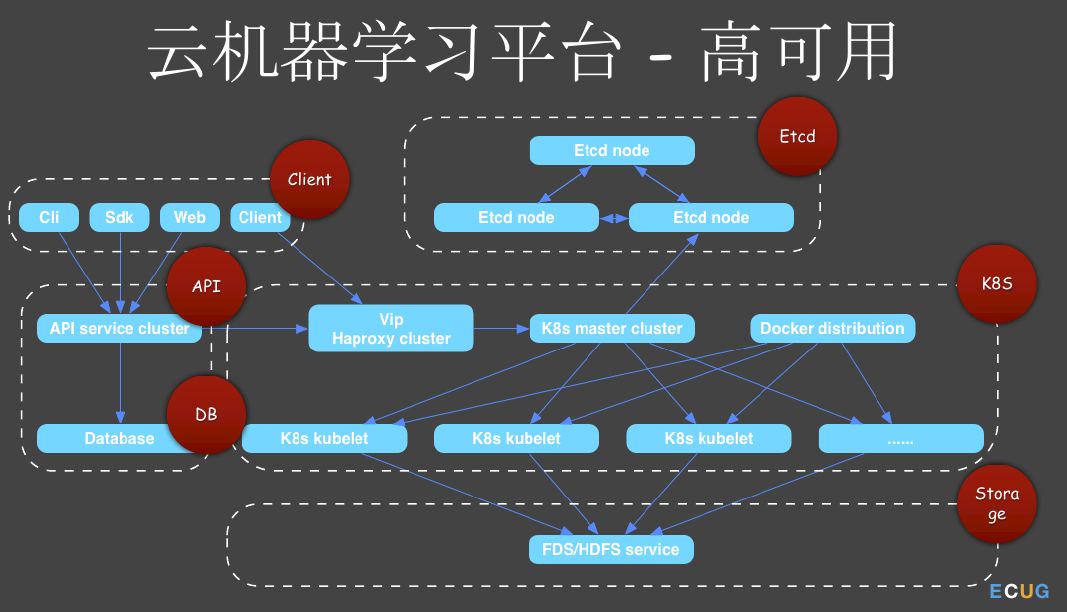
图23 高可用
我们在做平台的时候一定会考虑高可用和多租户。一个系统的高可用肯定是它各个组件的高可用。我们知道k8s依赖etcd,etcd本身有一个Raft协议,所以通过部署多个节点,它本身就是高可用的。用户实现的是一个API server,目前是一个java应用,依赖于Zookeeper或者是etcd实现的一个主从集群。DB我们用的是MySQL的高可用方案。

图24 多租户
平台是给企业或者其他云平台用户用的,所以要实现多租户。有两个概念:认证和授权。认证我们支持多种方式:用户名/密码,AK/SK,后者是一种更高的认证方式。LDAP是满足企业用户的需要。授权使我们自己实现的RBAC的方法。
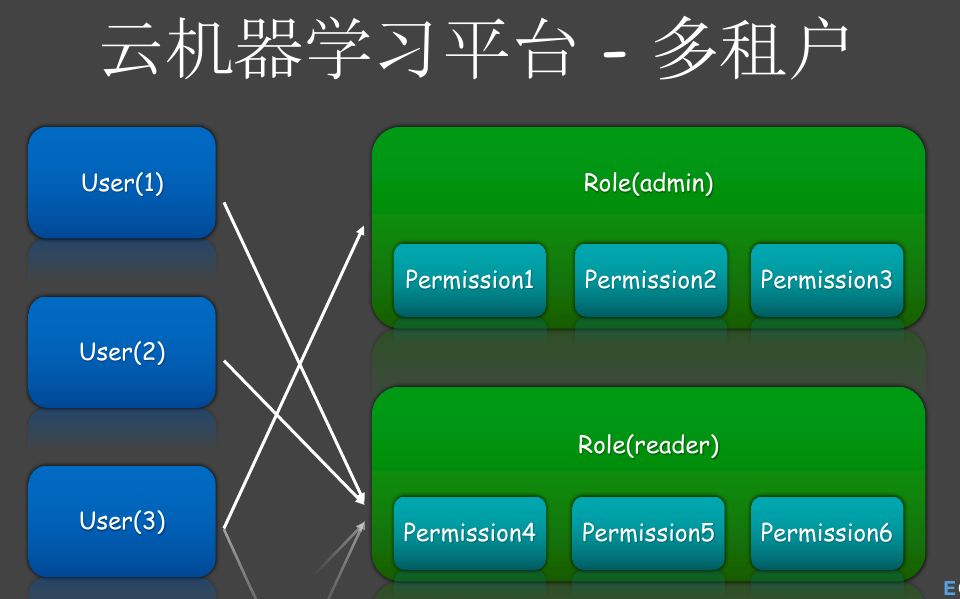
图25 多租户2
为什么要用RBAC呢?我们把用户和权限分开了,没有在数据库写死哪个用户有什么权限,而是在数据插入用户跟role的关系,role里面维护role和permission的关系。
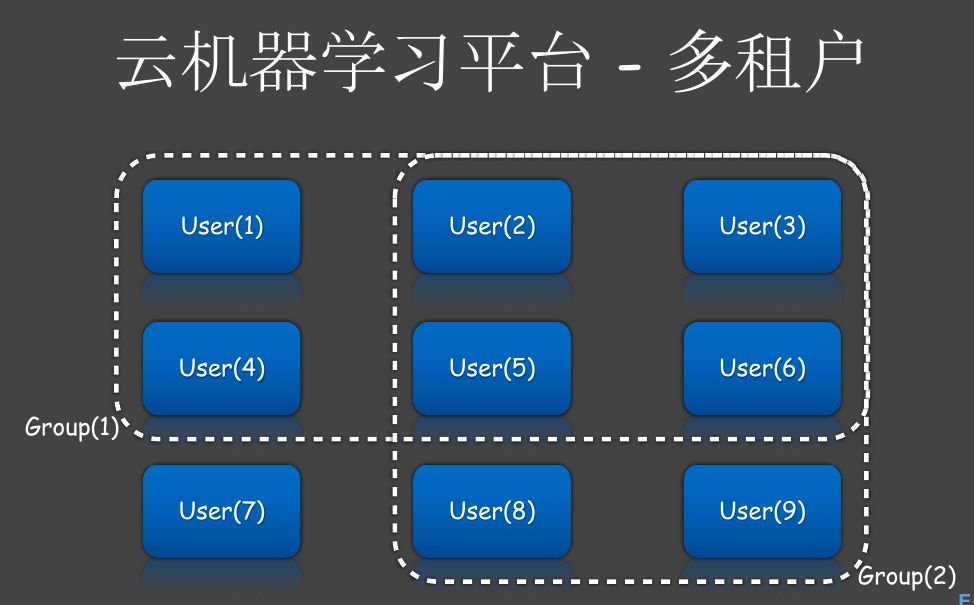
图26 多租户3
我们并没有把组和权限有糅合在一起,组是一个单独的概念。我们有一个Group表,有一个user和group的relation表。组和user其实都是一个entity,我们可以对entity进行授权。所以组跟permission是一个解耦的关系。
最后总结一下,搭建完整的云深度学习平台需要有良好的架构,还需要实现高性能、高可用、授权认证等功能组件,希望大家对底层基础架构和算法原理有进一步的了解,看完这次分享也有一定的收获,谢谢。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144912.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...