大家好,又见面了,我是你们的朋友全栈君。
损失函数或者代价函数的目的是:衡量模型的预测能力的好坏。
损失函数(Loss function):是定义在单个训练样本上的,也就是就算一个样本的误差,比如我们想要分类,就是预测的类别和实际类别的区别,是一个样本的哦,用L表示。
代价函数(Cost function):是定义在整个训练集上面的,也就是所有样本的误差的总和的平均,也就是损失函数的总和的平均,有没有这个平均其实不会影响最后的参数的求解结果。
模型在训练阶段会拟合出一个函数,其中的函数是包含参数的。
损失函数或者代价函数越小越好,也就说明预测值和标签的值越接近,模型的预测能力越强。但是如何才能让损失函数或者代价函数的值得到优化,换句话说,优化的就是模型拟合出的函数参数,通过寻找合适参数实现模型的预测能力变强的梦想,如何寻找优秀的参数值,那就需要梯度下降出场解救模型能力。


左侧就是梯度下降法的核心内容,右侧第一个公式为假设函数,第二个公式为损失函数。
左侧 表示假设函数的系数,为学习率。;右侧是模型拟合出来的函数,其中和是模型的参数,经过训练集每次训练模型得到的,梯度更新通过梯度下降法实现。
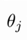
对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:

梯度下降的目的:寻找拟合函数参数的最优值。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144847.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
