大家好,又见面了,我是你们的朋友全栈君。
文章目录
原博客地址:
https://www.cnblogs.com/LXP-Never/p/13620804.html
1.语音交互
你知道苹果手机有几个麦克风吗?
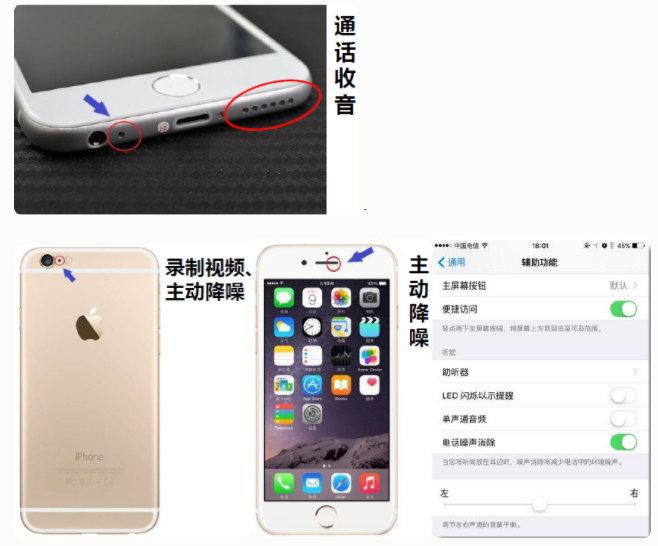

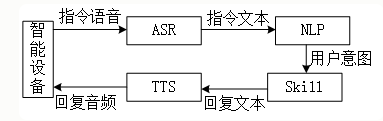
语音交互(
VUI)是指人与人/设备通过自然语音进行信息传递的过程。
语音交互的优势:
- 输入效率高。语音输入的速度是传统键盘输入方式的3倍以上。例如:语音电视选台、远场语音交互、语音支持组合指令输出(“播放周星驰电影、要免费的、4星以上的”)
- 使用门槛低。人类本就是先有语音再有文字,对于那些无法用文字交互的人来说,语音交互学习成本低,能带来极大的便利。例如:还不会打字的小孩,或者不方便打字的老人家
- 解放双手和双眼,更安全。 例如:车载场景通过语音点播音乐和导航,医疗场景(医生在操作设备的时候,可能还需要记录病例)
传递更多的声学信息。声纹、性别、年龄、情感等。
语音交互的劣势
- 信息接收效率低。 例如:文字能快速阅览概括信息,语音的话必须听完才能理解。
- 复杂的声学环境
- 心理负担。交互方式不一样,例如:不太愿意通过语音来进行交互,特别是在一些公共场合
人机语音交互发展
- 1952年,贝尔实验室,阿拉伯数字识别系统Audrey
- 1962年,IBM-Shoebox
- …
- 2011年,iphone4s,Siri问世
- 2014年,win8,Cortana
- 2014年,Amazon发布echo音箱
- 2016年,Google发布GoogleHom
应用场景 - 免提通话
- 电话/视频会议
- 手机——Siri、小爱同学
- 车载
- 智能音响——Amazon
- 家居——电视语音点台
总结起来就是:家里、车里、路上。
2. 复杂的声学环境
现实中的语音交互系统,无一例外的会受到各种环境不利因素的影响,极大影响了交互成功率和用户体验。
- 方向性干扰
- 环境噪声(散射噪声)
- 远讲产生的混响
- 声学回声
痛点:人和机器都听不清
一个成功的语音交互产品,意味着对语音交互的场合和使用模式无约束。
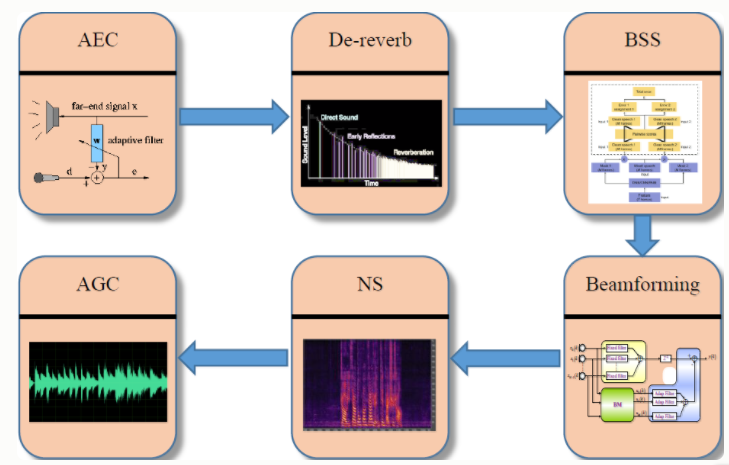
前端语音信号处理的意义:
- 面对噪声、干扰、声学回声、混响等不利因素的影响,运用信号处理、机器学习等手段,提高目标语音的信噪比或主观听觉感受,增强语音交互后续环节的稳健性。
- 让人听清:更高的信噪比,更好的主观听觉感受和可懂度,更低的处理延时。
- 让机器听清:更好的声学模型适配,更高的语音识别性能。
总结:语音信号处理的目标,是为了让人和机器更容易听清语音,让语音交互更加自然和无约束。

2.1 声学回声消除
消除设备自身产生的回声干扰,最早应用于全双工语音通信、视频会议,在语音交互中起到打断唤醒的作用
主要模块
- 时延估计(需要把参考信号和输入信号中跟参考信号高度相关的,时间上对齐)
- 线性回声消除(回声消除的核心,设计一组线性自适应滤波器,消除设备自身产生的回声,同时尽可能的保护近端语音不要受到损伤)
- 双讲检测(控制在线性回声消除阶段,究竟什么时刻该做什么事情,有以下几种状态:只有远讲回声信号存在、既有远讲回声信号又有近端的语音信号、
- 残余回声抑制(把前面线性回声消除部分没有消除干净遗漏过来的残余回声,做进一步回声消除)
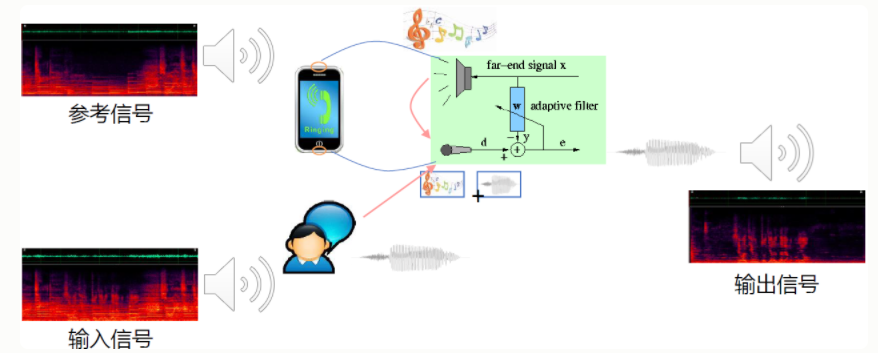
- 参考信号:近端扬声器播放的语音信号(没有经过污染的纯净语音),远端输入信号,近端输出信号
- 输入信号:麦克风接收到的输入信号(参考信号的回声+近端说话语音)
- 输出信号:近端说话语音信号
2.2 解混响
混响是由语音的多径效应所产生,在数学表达上是一个近场的纯净语音信号去卷积一个房间的冲击响应函数(RIR),这样的话能得到一个混响的语音信号。我们希望把混响的干扰因素消除掉,技术上有以下几种方法:
- 盲反卷积法[NeelyandAllen,1979]:直接去估计房间冲击响应函数的逆函数,如果把RIR当做是一个滤波器的话,我们直接去估计RIR的一个逆滤波器,然后把逆滤波器作用在带有混响的语音上,就得到了纯净语音信号。(“盲”:即没有任何的先验信息(既不知道原始信号的统计信息,也不知道房间的冲击响应函数),这种情况下想要恢复原始语音信号是非常困难的,所以我们只能假设完全没有噪声的场景,并且假设房间的冲击响应函数RIR是不变的,只有在这种比较严格的假设之下,才能得到相对较好的结果,但是这种假设在我们的实际情况当中是不会得到满足的,所以这种技术缺陷也是比较明显的)
- 加权预测误差[WPE,Takuya,2012]:因为语音信号具有线性预测特性(如果把语音信号当做是一系列采样点信号的话,那么下一个采样点可以用当前时刻以及当前时刻之前的若干采样点的值去预测出下一个时刻采样点的值),WPE认为混响可以分为早期混响和晚期混响,早期混响对于我们人的听觉感受系统没有负向作用,相反可能还有正面作用;晚期混响相对于房间冲击响应的拖尾的声音。那么加权预测误差则是希望估计一个最优的线性预测滤波器,这个滤波器的作用能够将房间冲击响应函数消除晚期混响的影响,多用于多通道。适用于单通道和多通道场景,多通道效果更好。
麦克风阵列波束形成:混响是多路径反射到达麦克风的,所以入射方向是全向的入射,而语音是方向性的入射,所以可以设计一个波束,拾取手机语音入射方向的语音。这样其他方向的混响就会被抑制
深度学习用于解混响[Han,2015]:通过DAE、DNN、LSTM或者GAN,实现频谱映射,端到端映射:带有干扰的语音信号频谱直接映射成为纯净语音信号的频谱,mask(掩膜,适用于乘性噪声):在当前的一个时频点上,是有效语音多还是带噪语音多,如果有效语音多则提取,如果带噪语音多则抑制。
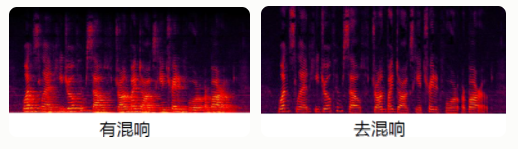
2.3 语音分离
旨在解决“鸡尾酒会”问题,人类具有这样一种能力,当我们身处多个说话人环境里面,比如:鸡尾酒会,人们可以很容易聚焦我们感兴趣的声音,而当前却没有哪个机器算法能达到人的这种专注注意力的能力,这个问题就引领了语音分离这个方向领域的推进
- 听觉场景分析法[俄亥俄大学 王德亮教授,2004]:将听觉场景分析引入到了计算领域,因此有了Computational Auditory Scene Analysis (CASA),主要关注的并不仅仅的是语音分离还有语音和其他噪声或音频的分离。技术思路:把鸡尾酒会问题变成一个二分类问题,这个二分类结果称为理想二值掩膜,在时频单元上,噪声占主导,则IBM的值为0;如果目标语音占主导,则IBM的值为1,。这样一来语音分离问题就变成了一个二分类问题。可以通过监督学习来实现,
- 非负矩阵分解[LeeandSeung,2001]:基于统计独立假设,语音信号的稀疏性与谐波特性,把带有干扰的混合语音信号的频谱分解成为一个特征矩阵乘以另一个系数矩阵,那么之后属于不同声源的那些信号的特征就会很自然的聚集到一起,这样一来我们把属于干扰源的特征所对应的系数矩阵进行掩蔽,
- 多通道技术: 固定波束形成(fix beamforming)、自适应波束形成(adaptive beamforming)、独立成分分析(ICA),本质上都是在多通道的场景下,通过一些空间信息和信号的统计独立假设,去估算一个最优的波束(要么提取目标说话人方向的声音,要么屏蔽干扰说话人方向的声音)
基于深度学习的语音分离 - Deep clustering [Hershey, 2016]:通过深度学习的手段,把每一个时频单元结合他的上下文信息把它映射到一个新的空间当中,那么在这个新的空间当中属于同一个说话人的时频单元距离会比较小,可以比较容易的聚类到一起。
- Deep attractor network [Luo and Chen, 2017]:
- Permutation invariant training [Yu, 2017]:解决了置换问题(分离出来的语音信号的顺序)和输出维度问题(不知道有几个声源的情况下)
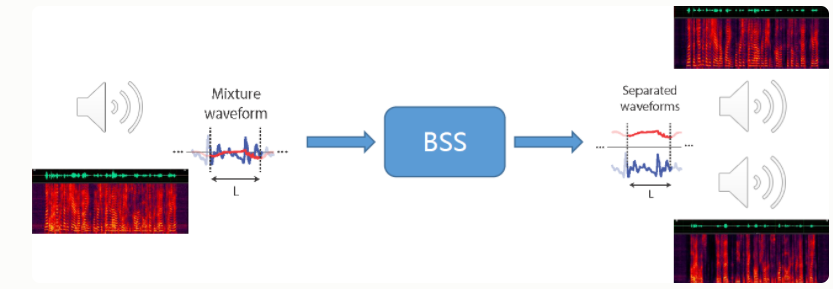
2.4 波束形成
波束形成技术多用于多通道语音增强、信号分离、去混响、声源定位,
原理:通过空间信息来区分不同位置说话人语音,麦克风阵列形成波束只接受目标说话人语音,其他方向进行屏蔽。

主要技术
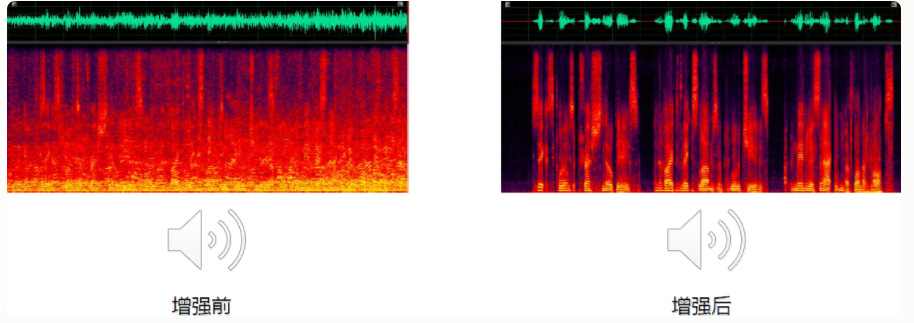
2.5 噪声抑制
消除或抑制环境噪声,增强语音信号
- 基于统计模型的方法(GMM…)
- 最小均方误差MMSE、最大似然估计ML、最大后验估计MAP
- 基于子空间的方法(MUSIC算法)
- 利用语音和噪声的不相关性,借助特征值/奇异值分解手段分解到子空间处理
- 语音增强的核心在于噪声估计
- 递归平均、最小值追踪、直方图统计是比较常用的噪声估计手段
- 基于深度学习的语音增强方法
- 两大类方法:Masking && Mapping
- 通过DNN、CNN、RNN或者GAN,在频域或时域实现(多为频域)
2.6幅度控制
作用:自动调整信号的动态范围
常用的两种方法
- 动态范围控制(Dynamic Range Control)
- 自动增益控制(Automatic Gain Control)
2.7 前端信号处理的技术路线
传统的前端信号处理方案
处理依据——“规则”
- 客观物理模型,即声音传播的物理规律
- 语音信号的时域、频域和空域特性
针对不同的干扰因素,采用不同的信号处理算法以加以解决
优化目标: 抑制干扰信号,提取目标信号
优化准则: MSE(Mean Square Error)准则
信号处理与深度学习相结合的方案
处理依据——“规则+学习”
- 客观物理模型
- 语音信号的时域、频域、空域特性
- 海量音频数据先验信息
既保留了声音传播的物理规律和信号本身的时域、频域、空域特性,又引入了先验数据统计建模的方法。
优化准则:MSE准则
基于深度学习的前后端联合优化方案
处理依据——“端到端联合建模”
- 输入多通道麦克风信号,输出语音识别结果
- 利用近场数据,仿真得到海量的带有各种干扰的训练数据
- 将前端信号处理与后端ASR声学模型联合建模,用一套深度学习模型完成语音增强和语音识别任务。
优化准则:识别准确率
3. 参考
深蓝学院《语音信号处理》课件
奥本海姆,《信号与系统》,电子工业出版社
奥本海姆,《离散时间信号处理》(Discrete Time Signal Processing, Third Edition)
赵力,《语音信号处理》,机械工业出版社
郑君里,《信号与系统》,电子工业出版社,高等教育本科国家级规范教材
韩纪庆,《语音信号处理》,机械工业出版社
张贤达,《现代信号处理》,清华大学出版社
张贤达,《矩阵分析与应用》,清华大学出版社
VanTrees,检测、估计和调制理论(IV)《Optimumarrayprocessing》
4 .推荐开源项目
Athena-signal:建议大家下载运行一下,有SEC、NS、波束形成、GSC实际应用的代码
Python for Signal Processing:《Python for Signal Processing: Featuring IPythonNotebooks》对应源码,包含信号处理12大类(采样定理、傅里叶变换、滤波器等)、随机过程15大类(高斯马尔科夫、最大似然等)
Speex:A Free Codec For Free Speech。专门语音编解码而设计的,包含超过9种算法:AEC、NS、VAD等,不过现在被Opus替代。
Google WebRTC:一个免费的开放式项目,通过简单的API为浏览器和移动应用程序提供实时通信(RTC)功能。
VOICEBOX: Speech Processing Toolbox for MATLAB:语音处理工具箱,由MATLAB程序组成。超过100个函数,包含语音增强、ASR等在内。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144811.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
