大家好,又见面了,我是你们的朋友全栈君。
NSGA2算法代码理解:
设置200个个体,目标函数为2个,决策变量的个数为30,首先初始化得到一个每个个体位于0~1之间的决策变量,利用ZDT1函数求得目标值,保存在数组中。
寻找非支配排序,在这200个个体中,选中一个个体,将这个个体和其余个体的目标函数值比较,如果没有一个个体可以支配他,那么就将其加入到非支配集合中
if individual(i).n == 0 %个体i非支配等级排序最高,属于当前最优解集,相应的染色体中携带代表排序数的信息
x(i,M + V + 1) = 1;
F(front).f = [F(front).f i];%等级为1的非支配解集
end
首先求出等级最高的非支配解集,然后遍历这个解集,找出每个解支配的个体,将被支配数量减1,看是否成为一个非支配,如果是则加入到新的非支配集合中,如此反复知道新集合为空。
将种群一分为2,随机选取最优的种群作为父代,然后交叉变异形成子代,接着合并子代和父代,采取精英策略,得到新的子代。
注意,如果原种群是200个,选取的合适繁殖的父代是100个,生成大约200个子代,合并再选取200个作为新的种群。
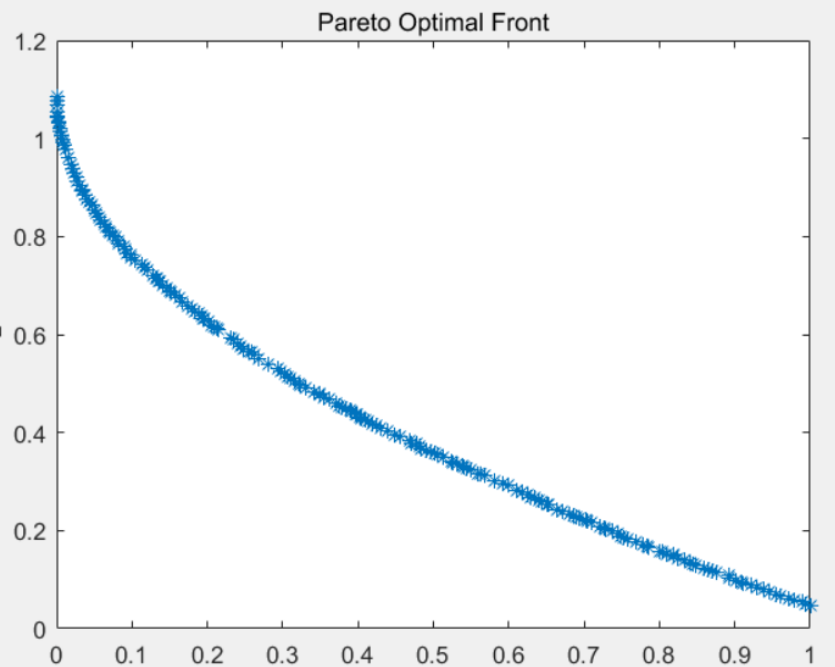

代码参考
https://blog.csdn.net/joekepler/article/details/80820240
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144681.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
