大家好,又见面了,我是你们的朋友全栈君。
对网站而言,数据是最宝贵的资源,硬件可以购买,软件可以重构,但是数据(用户数据,交易数据,商品数据)一旦丢失,对网站的打击可以说是毁灭性的。
数据高可用性
数据高可用性包括如下几个方面的含义
数据持久性
保证数据可以持久存储,在各种情况下都不会出现数据丢失。为了实现数据持久性,不但在写入数据是需要写入持久性存储,还需要将数据备份到一个或多个副本,存放在不同的物理存储设备上,在某个存储故障发生是,数据不会丢失。
数据可访问性
在多份数据副本分别存放在不同存储设备的情况下,如果一个数据存储设备损坏,就需要将数据访问切换到另一个数据存储设备上,如果这个过程不能很快完成(终端用户几乎没有延迟感知),或者在完成过程中需要停止终端用户访问数据,那么这段时间数据是不可访问的。
数据一致性
在数据有多份副本的情况下,如果网络、服务器或者软件出现故障,会出现部分副本写入成功、部分副本写入失败,这也就造成了各个副本中的数据不一致,数据内容冲突。
具体来说,数据一致性又分为如下几点
数据强一致性
各个副本的数据在物理存储中总是一致的;数据更新操作结果和操作响应总是一致的,即操作相应通知更新失败,那么数据一定没有被更新,而不是处于不确定的状态(可能被更新,也可能没有被更新)。
数据用户一致
数据在物理存储中的哥哥副本的数据可能是不一致的,但是终端用户在访问时,通过纠错和校验机制,可以确定一个一致且正确的数据返回给用户。
数据最终一致
这是数据一致性中最弱的一种,即物理存储的数据可能是不一致的,终端用户访问的数据可能也是不一致的(同一用户连续访问,结果不同;或者不用用户通过是访问,结果不同),但系统经过一段时间的自我修复和修正,数据最终会达到一致。
由于难以满足数据强一致性,网站通常会综合成本、技术、业务场景等条件,结合应用服务和其他数据监控与纠错功能,是存储系统达到用户一致,保证用户访问数据的最终正确性。
CAP原理
CAP原理认为,提供数据服务的存储系统无法同时满足数据一致性(Consistency)、数据可用性(Availbility)、分区耐受性(Patition Tolerance,系统具有跨网络分区伸缩性)这三个条件,如图

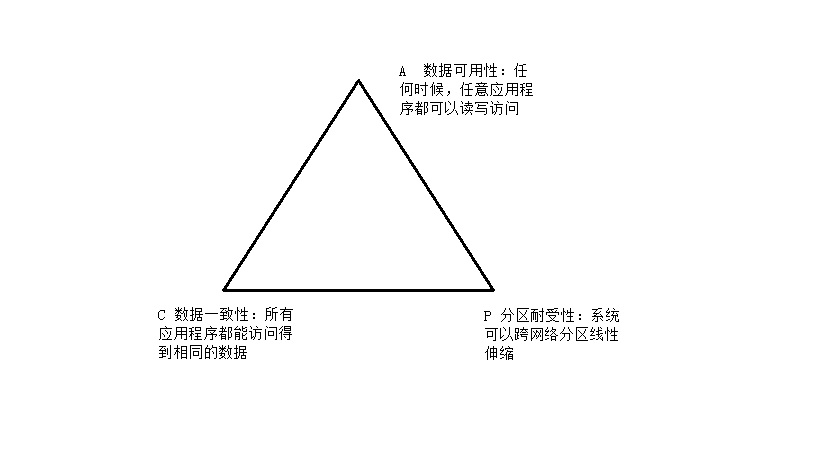
在大型网站,数据规模总是急剧扩张的,因此可伸缩性即分区耐受性必不可少,规模变大以后,机器数量也会变得庞大,这时网络和服务器故障就会频繁出现,要想保证应用可用,就必须保证分布式处理系统的高可用性。所以在大型网站中,通常会选择强化分布式存储系统的可用性(A)和伸缩性(P),而在某种程度上放弃一致性(C)。一般来说,数据不一致通常出现在系统高并发或者集群状态不稳定(故障恢复、集群扩容…)的情况下,应用系统给需要分不是数据处理系统的数据不一致性有所了解并进行某种意义上的补偿和纠错,一笔I安出现系统数据不正确。
”双十一“期间,活动第一分钟就会出现千万级独立用户访问,这种极端的高并发场景对数据处理系统造成了巨大压力,较弱的数据一直想导致出现部分商品超卖现象(交易成功的商品数量>库存数量)
CAP原理对于可伸缩的分布式系统的设计具有重要意义,在系统设计开发过程中昂,不恰当地迎合各种需求,企图打造一个完美的产品,可能会使设计陷入两难境地,难以为继。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144636.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
