大家好,又见面了,我是你们的朋友全栈君。
-
gitee个人代码:https://gitee.com/HanFerm/gulimall
-
笔记-基础篇-1(P1-P28):https://blog.csdn.net/hancoder/article/details/106922139
-
笔记-基础篇-2(P28-P100):https://blog.csdn.net/hancoder/article/details/107612619
-
笔记-高级篇(P340):https://blog.csdn.net/hancoder/article/details/107612746
-
笔记-vue:https://blog.csdn.net/hancoder/article/details/107007605
-
笔记-elastic search、上架、检索:https://blog.csdn.net/hancoder/article/details/113922398
-
笔记-认证服务:https://blog.csdn.net/hancoder/article/details/114242184
-
笔记-分布式锁与缓存:https://blog.csdn.net/hancoder/article/details/114004280
-
笔记-集群篇:https://blog.csdn.net/hancoder/article/details/107612802
-
k8s、devOps专栏:https://blog.csdn.net/hancoder/category_11140481.html
-
springcloud笔记:https://blog.csdn.net/hancoder/article/details/109063671
-
笔记版本说明:2020年提供过笔记文档,但只有P1-P50的内容,2021年整理了P340的内容。请点击标题下面分栏查看系列笔记
-
声明:
- 可以白嫖,但请勿转载发布,笔记手打不易
- 本系列笔记不断迭代优化,csdn:hancoder上是最新版内容,10W字都是在csdn免费开放观看的。
- 离线md笔记文件获取方式见文末。2021-3版本的md笔记打完压缩包共500k(云图床),包括本项目笔记,还有cloud、docker、mybatis-plus、rabbitMQ等个人相关笔记
-
本项目其他笔记见专栏:https://blog.csdn.net/hancoder/category_10822407.html
学到高级篇已经击败90%的人了,加油
一、Elastic Search
ES笔记:https://blog.csdn.net/hancoder/article/details/113922398
二、公用工具
商品发布只是可以上架了,上架后才可被检索
Feign
远程调用源码
// ReflectiveFeign
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (!"equals".equals(method.getName())) {
if ("hashCode".equals(method.getName())) {
return this.hashCode();
} else {
return "toString".equals(method.getName()) ? this.toString() : ((MethodHandler)this.dispatch.get(method)).invoke(args);
}
} else {
// 处理equals方法
try {
Object otherHandler = args.length > 0 && args[0] != null ? Proxy.getInvocationHandler(args[0]) : null;
return this.equals(otherHandler);
} catch (IllegalArgumentException var5) {
return false;
}
}
}
// SynchronousMethodHandler.JAVA;
public Object invoke(Object[] argv) throws Throwable {
// 传过来的数据,构造 RequestTemplate,里面body有数据
RequestTemplate template = this.buildTemplateFromArgs.create(argv);
Options options = this.findOptions(argv);
// 重试器,要注意重复调用、接口幂等性。可以写重试器自己的实现
Retryer retryer = this.retryer.clone();
while(true) {
try {
// 执行后得到响应,解码得到bean
return this.executeAndDecode(template, options);
} catch (RetryableException var9) {
RetryableException e = var9;
try {
retryer.continueOrPropagate(e);
} catch (RetryableException var8) {
Throwable cause = var8.getCause();
if (this.propagationPolicy == ExceptionPropagationPolicy.UNWRAP && cause != null) {
throw cause;
}
throw var8;
}
}
}
}
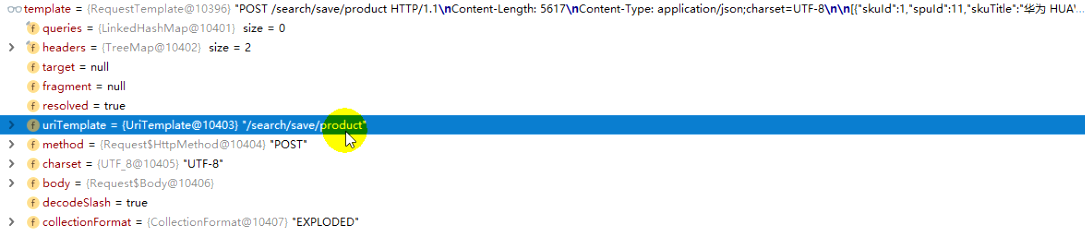

body里是数据,feign将bean转为了 json
Object executeAndDecode(RequestTemplate template, Options options) throws Throwable {
// 构造出请求
Request request = this.targetRequest(template);
if (this.logLevel != Level.NONE) {
// 打印日志
this.logger.logRequest(this.metadata.configKey(), this.logLevel, request);
}
long start = System.nanoTime();
Response response;
try {
// 执行。client是LoadBalancerFeignClient。跳转到远程
response = this.client.execute(request, options);
response = response.toBuilder().request(request).requestTemplate(template).build();
} catch (IOException var16) {
if (this.logLevel != Level.NONE) {
this.logger.logIOException(this.metadata.configKey(), this.logLevel, var16, this.elapsedTime(start));
}
throw FeignException.errorExecuting(request, var16);
}
。。。
公共返回类R
因为是个hashmap,所以setData不成功
public class R<T> extends HashMap<String,Object>{
// 把setData重写成PUT
public R setData(Object data){
put("data", data);
return this;
}
public <T> T getData(TypeReference<T> typeReference){
// get("data") 默认是map类型 所以再由map转成string再转json
Object data = get("data");//得到list,list每个值是map类型
// list<Map>转json
String s = JSON.toJSONString(data);
// json转list<T>
return JSON.parseObject(s, typeReference);
}
}
在其他处是new TypeReference<List<T>>
data的值对应的是List,而list的每个值是map
三、商城系统首页
P136
页面与静态资源处理
不使用前后端分离开发了,管理后台用vue
页面在课件位置: 【尚硅谷公众号-回复谷粒商城-高级篇-资料源码.zip\代码\html】
静态资源处理
nginx发给网关集群,网关再路由到微服务
静态资源放到nginx中,后面的很多服务都需要放到nginx中
html\首页资源\index放到gulimall-product下的static文件夹
把index.html放到templates中
pom依赖
导入thymeleaf依赖、热部署依赖devtools使页面实时生效
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
关闭thymeleaf缓存,方便开发实时看到更新
thymeleaf:
cache: false
suffix: .html
prefix: classpath:/templates/
web开发放到web包下,原来的controller是前后分离对接手机等访问的,所以可以改成app,对接app应用
渲染一级分类菜单
刚导入index.html时,里面的分类菜单都是写死的,我们要访问数据库拿到放到model中,然后在页面foreach填入
thymeleaf笔记:https://blog.csdn.net/hancoder/article/details/113945941
@GetMapping({
"/", "index.html"})
public String getIndex(Model model) {
//获取所有的一级分类
List<CategoryEntity> catagories = categoryService.getLevel1Catagories();
model.addAttribute("catagories", catagories);
return "index";
}
页面遍历菜单数据
<li th:each="catagory:${catagories}" >
<a href="#" class="header_main_left_a" ctg-data="3" th:attr="ctg-data=${catagory.catId}"><b th:text="${catagory.name}"></b></a>
</li>
渲染三级分类菜单
@ResponseBody
@RequestMapping("index/catalog.json")
public Map<String, List<Catelog2Vo>> getCatlogJson() {
Map<String, List<Catelog2Vo>> map = categoryService.getCatelogJson();
return map;
}
@Override
public Map<String, List<Catelog2Vo>> getCatelogJson() {
List<CategoryEntity> entityList = baseMapper.selectList(null);
// 查询所有一级分类
List<CategoryEntity> level1 = getCategoryEntities(entityList, 0L);
Map<String, List<Catelog2Vo>> parent_cid = level1.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 拿到每一个一级分类 然后查询他们的二级分类
List<CategoryEntity> entities = getCategoryEntities(entityList, v.getCatId());
List<Catelog2Vo> catelog2Vos = null;
if (entities != null) {
catelog2Vos = entities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), l2.getName(), l2.getCatId().toString(), null);
// 找当前二级分类的三级分类
List<CategoryEntity> level3 = getCategoryEntities(entityList, l2.getCatId());
// 三级分类有数据的情况下
if (level3 != null) {
List<Catalog3Vo> catalog3Vos = level3.stream().map(l3 -> new Catalog3Vo(l3.getCatId().toString(), l3.getName(), l2.getCatId().toString())).collect(Collectors.toList());
catelog2Vo.setCatalog3List(catalog3Vos);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
四、Nginx
本来想把nginx另写一篇,csdn不给审核,说翻墙。。。我服了
在hosts中设置192.168.56.10 gulimall.com
利用nginx转到网关(记得关防火墙)
1、Nginx+网关+openFeign的逻辑
要实现的逻辑:本机浏览器请求gulimall.com,通过配置hosts文件之后,那么当你在浏览器中输入gulimall.com的时候,相当于域名解析DNS服务解析得到ip 192.168.56.10,也就是并不是访问java服务,而是先去找nginx。什么意思呢?是说如果某一天项目上线了,gulimall.com应该是nginx的ip,用户访问的都是nginx
请求到了nginx之后,
- 如果是静态资源
/static/*直接在nginx服务器中找到静态资源直接返回。 - 如果不是静态资源
/(他配置在/static/*的后面所以才优先级低),nginx把他upstream转交给另外一个ip192.168.56.1:88这个ip端口是网关gateway。- (在upstream的过程中要注意配置
proxy_set_header Host $host;)
- (在upstream的过程中要注意配置
到达网关之后,通过url信息断言判断应该转发给nacos中的哪个微服务(在给nacos之前也可以重写url),这样就得到了响应
而对于openFeign,因为在服务中注册了nacos的ip,所以他并不经过nginx
2、Nginx配置文件
nginx.conf:
- 全局块:配置影响nginx全局的指令。如:用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process故障等
- events块:配置影响 Nginx 服务器与用户的网络连接,常用的设置包括是否开启对多 work process下的网络连接进行序列化,是否允许同时接收多个网络连接,选取哪种事件驱动模型来处理连接请求,每个 word process 可以同时支持的最大连接数等。
- http块:
- http全局块:配置的指令包括文件引入、MIME-TYPE 定义、日志自定义、连接超时时间、单链接请求数上限等。错误页面等
- server块:这块和虚拟主机有密切关系,虚拟主机从用户角度看,和一台独立的硬件主机是完全一样的。每个 http 块可以包括多个 server 块,而每个 server 块就相当于一个虚拟主机。
- location1:配置请求的路由,以及各种页面的处理情况
- location2
3、Nginx+网关配置
-
修改主机hosts,映射
gulimall.com到192.168.56.10。关闭防火墙 -
修改nginx/conf/nginx.conf,将
upstream映射到我们的网关服务upstream gulimall{ # 88是网关 server 192.168.56.1:88; } -
修改
nginx/conf/conf.d/gulimall.conf,接收到gulimall.com的访问后,如果是/,转交给指定的upstream,由于nginx的转发会丢失host头,造成网关不知道原host,所以我们添加头信息location / { proxy_pass http://gulimall; proxy_set_header Host $host; } -
配置gateway为服务器,将域名为
**.gulimall.com转发至商品服务。配置的时候注意 网关优先匹配的原则,所以要把这个配置放到后面- id: gulimall_host_route uri: lb://gulimall-product predicates: - Host=**.gulimall.com
不一定非要按我的来
conf.d/gulimall.conf
监听来自gulimall:80的请求,
- 对于以/static开头的请求,就是找 /usr/share/nginx/html这个相对路径。
- 为什么找那个?因为我们映射了docker外面的/mydata/data/nginx/html某一列到这个目录,所以在docker中就是去这找静态资源
- 其他的请求,转发到http://gulimall 这个upstream ,并且由于nginx的转发会丢失
host头(host头是HTTP1.1开始新增的请求头),造成网关不知道原host,所以我们添加头信息
nginx.conf
在这里最重要的是这个再转给网关的配置
这个地方因为可能把后面视频的内容也挪过来了所以写的比较乱,也懒得改了,总之就是分为/static拦截和/拦截,将/拦截转发到upstream gulimall即可,转发时代上请求头
Nginx的原理其实就是 NIO-select/read+线程池 ,很多中间件/框架的原理都是这个
nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
include /etc/nginx/conf.d/*.conf; # 包含了哪些配置文件
}
conf.d/gulimall.conf
server {
listen 80;
server_name gulimall.com *.gulimall.com;
location /static {
root /usr/share/nginx/html;
}
#charset koi8-r;
#access_log /var/log/nginx/log/host.access.log main;
location / {
proxy_pass http://gulimall;
proxy_set_header Host $host; #
}
upstream gulimall{
# 88是网关
server 192.168.56.1:88;
}
include /etc/nginx/conf.d/*.conf; # 包含了哪些配置文件
}
测试:http://gulimall.com/api/product/attrgroup/list/1
http://localhost:88/api/product/attrgroup/list/1
请求结果相同
此时请求接口和请求页面都是gulimall.com
五、压力测试
JVM参数、工具、调优笔记:https://blog.csdn.net/hancoder/article/details/108312012
Jmeter
下载:https://jmeter.apache.org/download_jmeter.cgi
创建测试计划,添加线程组
线程数==用户
ramp-up 多长时间内发送完
添加-取样器-HTTP请求
添加-监听器-查看结果树
添加-监听器-汇总报告
Jmeter Address Already in use错误解决
报错原因:
1、windows系统为了保护本机,限制了其他机器到本机的连接数.
2、TCP/IP 可释放已关闭连接并重用其资源前,必须经过的时间。关闭和释放之间的此时间间隔通称 TIME_WAIT 状态或两倍最大段生命周期(2MSL)状态。此时间期间,重新打开到客户机和服务器的连接的成本少于建立新连接。减少此条目的值允许 TCP/IP 更快地释放已关闭的连接,为新连接提供更多资源。如果运行的应用程序需要快速释放和创建新连接,而且由于 TIME_WAIT 中存在很多连接,导致低吞吐量,则调整此参数。
修改操作系统注册表
1、打开注册表:运行-regedit
2、直接输入找到HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TCPIP\Parameters
3、右击Parameters新建 DWORD32值,name:TcpTimedWaitDelay,value:30(十进制) ——> 设置为30秒回收(默认240)
4、新建 DWORD值,name:MaxUserPort,value:65534(十进制) ——> 设置最大连接数65534
注意:修改时先选择十进制,再填写数字。
5、重启系统
Jconsole、JvisualVM
JVM写到别处:https://blog.csdn.net/hancoder/article/details/105210258
看这个视频的真的有没学过JVM的吗。。。
同样贴上之前的JVM学习笔记:https://blog.csdn.net/hancoder/article/details/108312012
运行状态:
- 运行:正在运行
- 休眠:sleep
- 等待:wait
- 驻留:线程池里面的空闲线程
- 监视:阻塞的线程,正在等待锁
要监控GC,安装插件:工具-插件。可用插件-检查最新版本 报错的时候百度“插件中心”,改个JVM对应的插件中心url.xml.z
安装visual GC
优化
- SQL耗时越小越好,一般情况下微秒级别
- 命中率越高越好,一般情况下不能低于95%
- 锁等待次数越低越好,等待时间越短越好
- 中间件越多,性能损失雨大,大多都损失在网络交互了
视频教程中的测试结果

| 压测内容 | 压测线程数 | 吞吐量/s | 90%响应时间 | 99%响应时间 |
|---|---|---|---|---|
| Nginx(浪费CPU) | 50 | 2120 | 10 | 1204 |
| Gateway(浪费CPU) | 50 | 9200 | 9 | 21 |
| 简单服务(返回字符串) | 50 | 9850 | 8 | 48 |
| 首页一级菜单渲染 | 50 | 350 | 260 | 491 |
| 首页菜单渲染(开缓存) | 50 | 465 | 119 | 306 |
| 首页菜单渲染(开缓存、优化数据库、关日志) | 50 | 465 | 127 | 304 |
| 三级分类数据获取 | 50 | 4 | 13275 | 13756 |
| 三级分类(优化业务) | 50 | 15 | 4092 | 5891 |
| 首页全量数据获取 | 50 | 2.7 | 24014 | 26556 |
| 首页全量数据获取(动静分类) | 50 | 4.9 | 14913 | 16421 |
| Nginx+GateWay | 50 | |||
| Gateway+简单服务 | 50 | 3000 | 28 | 67 |
| 全链路(Nginx+GateWay+简单服务) | 50 | 650 | 84 | 537 |
product微服务的 -Xmx1024m -Xms1024m -Xmn512m
Nginx动静分离
由于动态资源和静态资源目前都处于服务端,所以为了减轻服务器压力,我们将js、css、img等静态资源放置在Nginx端,以减轻服务器压力
-
静态文件上传到 mydata/nginx/html/static/index/css,这种格式
-
修改index.html的静态资源路径,加上static前缀
src="/static/index/img/img_09.png" -
修改
/mydata/nginx/conf/conf.d/gulimall.conf如果遇到有
/static为前缀的请求,转发至html文件夹location /static { root /usr/share/nginx/html; } location / { proxy_pass http://gulimall; proxy_set_header Host $host; }
优化三级分类
优化前
对二级菜单的每次遍历都需要查询数据库,浪费大量资源
优化后
仅查询一次数据库,剩下的数据通过遍历得到并封装
//优化业务逻辑,仅查询一次数据库
List<CategoryEntity> categoryEntities = this.list();
//查出所有一级分类
List<CategoryEntity> level1Categories = getCategoryByParentCid(categoryEntities, 0L);
Map<String, List<Catalog2Vo>> listMap = level1Categories.stream().collect(Collectors.toMap(k->k.getCatId().toString(), v -> {
//遍历查找出二级分类
List<CategoryEntity> level2Categories = getCategoryByParentCid(categoryEntities, v.getCatId());
List<Catalog2Vo> catalog2Vos=null;
if (level2Categories!=null){
//封装二级分类到vo并且查出其中的三级分类
catalog2Vos = level2Categories.stream().map(cat -> {
//遍历查出三级分类并封装
List<CategoryEntity> level3Catagories = getCategoryByParentCid(categoryEntities, cat.getCatId());
List<Catalog2Vo.Catalog3Vo> catalog3Vos = null;
if (level3Catagories != null) {
catalog3Vos = level3Catagories.stream()
.map(level3 -> new Catalog2Vo.Catalog3Vo(level3.getParentCid().toString(), level3.getCatId().toString(), level3.getName()))
.collect(Collectors.toList());
}
Catalog2Vo catalog2Vo = new Catalog2Vo(v.getCatId().toString(), cat.getCatId().toString(), cat.getName(), catalog3Vos);
return catalog2Vo;
}).collect(Collectors.toList());
}
return catalog2Vos;
}));
return listMap;
六、redisson分布式锁与缓存
笔记写到了别处:https://blog.csdn.net/hancoder/article/details/114004280
七、检索
建立微服务和检索相关代码写到了https://blog.csdn.net/hancoder/article/details/113922398 末尾
八、异步编排
线程基础百度吧
异步编排参考网上链接即可:https://blog.csdn.net/weixin_45762031/article/details/103519459
CompletableFuture介绍
Future是Java 5添加的类,用来描述一个异步计算的结果。你可以使用isDone方法检查计算是否完成,或者使用get阻塞住调用线程,直到计算完成返回结果,你也可以使用cancel方法停止任务的执行。
虽然Future以及相关使用方法提供了异步执行任务的能力,但是对于结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果。阻塞的方式显然和我们的异步编程的初衷相违背,轮询的方式又会耗费无谓的CPU资源,而且也不能及时地得到计算结果,为什么不能用观察者设计模式当计算结果完成及时通知监听者呢?
很多语言,比如Node.js,采用回调的方式实现异步编程。Java的一些框架,比如Netty,自己扩展了Java的 Future接口,提供了addListener等多个扩展方法;Google guava也提供了通用的扩展Future;Scala也提供了简单易用且功能强大的Future/Promise异步编程模式。
作为正统的Java类库,是不是应该做点什么,加强一下自身库的功能呢?
在Java 8中, 新增加了一个包含50个方法左右的类: CompletableFuture,提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,提供了函数式编程的能力,可以通过回调的方式处理计算结果,并且提供了转换和组合CompletableFuture的方法。
创建异步对象
CompletableFuture 提供了四个静态方法来创建一个异步操作。
static CompletableFuture<Void> runAsync(Runnable runnable)
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
没有指定Executor的方法会使用ForkJoinPool.commonPool() 作为它的线程池执行异步代码。如果指定线程池,则使用指定的线程池运行。以下所有的方法都类同。
- runAsync方法不支持返回值。
- supplyAsync可以支持返回值。
计算完成时回调方法:当CompletableFuture的计算结果完成,或者抛出异常的时候,可以执行特定的Action。主要是下面的方法:
public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action);
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action);
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action, Executor executor);
public CompletableFuture<T> exceptionally(Function<Throwable,? extends T> fn);
whenComplete可以处理正常和异常的计算结果,exceptionally处理异常情况。BiConsumer<? super T,? super Throwable>可以定义处理业务
whenComplete 和 whenCompleteAsync 的区别:
- whenComplete:是执行当前任务的线程执行继续执行 whenComplete 的任务。
- whenCompleteAsync:是执行把 whenCompleteAsync 这个任务继续提交给线程池来进行执行。
方法不以Async结尾,意味着Action使用相同的线程执行,而Async可能会使用其他线程执行(如果是使用相同的线程池,也可能会被同一个线程选中执行)
public class CompletableFutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture future = CompletableFuture.supplyAsync(new Supplier<Object>() {
@Override
public Object get() {
System.out.println(Thread.currentThread().getName() + "\t completableFuture");
int i = 10 / 0;
return 1024;
}
}).whenComplete(new BiConsumer<Object, Throwable>() {
@Override
public void accept(Object o, Throwable throwable) {
System.out.println("-------o=" + o.toString());
System.out.println("-------throwable=" + throwable);
}
}).exceptionally(new Function<Throwable, Object>() {
@Override
public Object apply(Throwable throwable) {
System.out.println("throwable=" + throwable);
return 6666;
}
});
System.out.println(future.get());
}
}
handle 方法
handle 是执行任务完成时对结果的处理。
handle 是在任务完成后再执行,还可以处理异常的任务。
public <U> CompletionStage<U> handle(BiFunction<? super T, Throwable, ? extends U> fn);
public <U> CompletionStage<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn);
public <U> CompletionStage<U> handleAsync(BiFunction<? super T, Throwable, ? extends U> fn,Executor executor);
线程串行化方法
thenApply 方法:当一个线程依赖另一个线程时,获取上一个任务返回的结果,并返回当前任务的返回值。
thenAccept方法:消费处理结果。接收任务的处理结果,并消费处理,无返回结果。
thenRun方法:只要上面的任务执行完成,就开始执行thenRun,只是处理完任务后,执行 thenRun的后续操作
带有Async默认是异步执行的。这里所谓的异步指的是不在当前线程内执行。
public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn, Executor executor)
public CompletionStage<Void> thenAccept(Consumer<? super T> action);
public CompletionStage<Void> thenAcceptAsync(Consumer<? super T> action);
public CompletionStage<Void> thenAcceptAsync(Consumer<? super T> action,Executor executor);
public CompletionStage<Void> thenRun(Runnable action);
public CompletionStage<Void> thenRunAsync(Runnable action);
public CompletionStage<Void> thenRunAsync(Runnable action,Executor executor);
九、商品详情
添加hosts内容 192.168.56.10 item.gulimall.com
修改网关 使item路由到product
复制详情页的html到product,静态文件放到nginx
(1) 商品详情VO
观察我们要建立怎样的VO

@Data
public class SkuItemVo {
/*** 1 sku基本信息的获取:如标题*/
SkuInfoEntity info;
boolean hasStock = true;
/*** 2 sku的图片信息*/
List<SkuImagesEntity> images;
/*** 3 获取spu的销售属性组合。每个attrName对应一个value-list*/
List<ItemSaleAttrVo> saleAttr;
/*** 4 获取spu的介绍*/
SpuInfoDescEntity desc;
/*** 5 获取spu的规格参数信息,每个分组的包含list*/
List<SpuItemAttrGroup> groupAttrs;
/*** 6 秒杀信息*/
SeckillInfoVo seckillInfoVo;
}
@ToString
@Data
public class ItemSaleAttrVo{
private Long attrId;
private String attrName;
/** AttrValueWithSkuIdVo两个属性 attrValue、skuIds */
private List<AttrValueWithSkuIdVo> attrValues;
}
@ToString
@Data
public class SpuItemAttrGroup{
private String groupName;
/** 两个属性attrName、attrValue */
private List<SpuBaseAttrVo> attrs;
}
(2) sql构建
我们观察商品页面与VO,可以大致分为5个部分需要封装。1 2 4比较简单,单表就查出来了。我们分析3、5
我们在url中首先有sku_id,在从sku_info表查标题的时候,顺便查到了spu_id、catelog_id,这样我们就可以操作剩下表了。
分组规格参数
在5查询规格参数中
pms_product_attr_value根据spu_id获得spu相关属性pms_attr_attrgroup_relation根据catelog_id获得属性的分组
<!-- 封装自定义结果集 -->
<resultMap id="SpuItemAttrGroupVo" type="com.atguigu.gulimall.product.vo.SpuItemAttrGroup">
<result column="attr_group_name" property="groupName" javaType="string"></result>
<collection property="attrs" ofType="com.atguigu.gulimall.product.vo.SpuBaseAttrVo">
<result column="attr_name" property="attrName" javaType="string"></result>
<result column="attr_value" property="attrValue" javaType="string"></result>
</collection>
</resultMap>
<select id="getAttrGroupWithAttrsBySpuId" resultMap="SpuItemAttrGroupVo">
SELECT pav.`spu_id`, ag.`attr_group_name`, ag.`attr_group_id`, aar.`attr_id`, attr.`attr_name`,pav.`attr_value`
FROM `pms_attr_group` ag
LEFT JOIN `pms_attr_attrgroup_relation` aar ON aar.`attr_group_id` = ag.`attr_group_id`
LEFT JOIN `pms_attr` attr ON attr.`attr_id` = aar.`attr_id`
LEFT JOIN `pms_product_attr_value` pav ON pav.`attr_id` = attr.`attr_id`
WHERE ag.catelog_id = #{catalogId} AND pav.`spu_id` = #{spuId}
</select>
@Override
public List<SpuItemAttrGroup> getAttrGroupWithAttrsBySpuId(Long spuId, Long catalogId) {
// 1.出当前Spu对应的所有属性的分组信息 以及当前分组下所有属性对应的值
// 1.1 查询所有分组
AttrGroupDao baseMapper = this.getBaseMapper();
return baseMapper.getAttrGroupWithAttrsBySpuId(spuId, catalogId);
}
sku售卖属性
在3查询售卖参数中,
为什么是spu的销售属性,而不是sku的销售属性:url是skuID,但是销售属性要显示所有spu的sku[],为了提前看有无货、快速获得其他的sku_id。
从
pms_sku_info查出该spuId对应的skuId
根据spu获取销售属性对应的所有值。首先知道spu是没有销售属性的,而是spu对应sku[]的销售属性
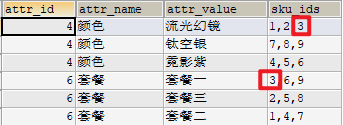
根据各种选项决定一个sku是如何做到的?我们可以利用一下ES的倒排索引。比较难想到,先正序看一下吧
pms_sku_info根据spu得到所有sku_id[]pms_sku_sale_attr_value根据sku得到销售属性- 查询出来之后需要根据属性attr_id分组,分组要查询的列得在group by之后出现过,或者查询的列是用分组函数聚合出的。
- 而
GROUP_CONCAT就把没分组的列都聚合到一起。比如分组后name为zs的对应id有1、2、3,那么GROUP_CONCAT(id)该列就是123 - 而聚合后如果有重复值,比如id有1,2,2,那么就可以用
DISTINCT聚合成1,2 - 最后
GROUP_CONCAT(DISTINCT info.sku_id) sku_ids
- 而
查询得到的结果特别像ES中的倒排索引
<resultMap id="SkuItemSaleAttrVo" type="com.atguigu.gulimall.product.vo.ItemSaleAttrVo">
<result column="attr_id" property="attrId"></result>
<result column="attr_name" property="attrName"></result>
<collection property="attrValues" ofType="com.atguigu.gulimall.product.vo.AttrValueWithSkuIdVo">
<result column="attr_value" property="attrValue"></result>
<result column="sku_ids" property="skuIds"></result>
</collection>
</resultMap>
<select id="getSaleAttrsBySpuId" resultMap="SkuItemSaleAttrVo">
SELECT ssav.`attr_id`,ssav.`attr_name`,ssav.`attr_value`,
GROUP_CONCAT(DISTINCT info.`sku_id`) sku_ids
FROM `pms_sku_info` info LEFT JOIN `pms_sku_sale_attr_value` ssav
ON ssav.`sku_id` = info.`sku_id`
WHERE info.`spu_id` = #{spuId}
GROUP BY ssav.`attr_id`,ssav.`attr_name`,ssav.`attr_value`
</select>
(3) controller-service
@Controller
public class ItemController {
@Autowired
private SkuInfoService skuInfoService;
@RequestMapping("/{skuId}.html")
public String skuItem(@PathVariable("skuId") Long skuId, Model model)
throws ExecutionException, InterruptedException {
SkuItemVo vo = skuInfoService.item(skuId);
model.addAttribute("item", vo);
return "item";
}
}
@Override //SkuInfoServiceImpl @TableName("pms_sku_info")
public SkuItemVo item(Long skuId) {
SkuItemVo skuItemVo = new SkuItemVo();
//1、sku基本信息的获取 pms_sku_info
SkuInfoEntity skuInfoEntity = this.getById(skuId);
skuItemVo.setInfo(skuInfoEntity);
Long spuId = skuInfoEntity.getSpuId();
Long catalogId = skuInfoEntity.getCatalogId();
//2、sku的图片信息 pms_sku_images
List<SkuImagesEntity> skuImagesEntities = skuimagesService.list(new QueryWrapper<SkuimagesEntity>().eq("sku_id", skuId));
skuItemVo.setimages(skuimagesEntities);
//3、获取spu的销售属性组合-> 依赖1 获取spuId
List<SkuItemSaleAttrVo> saleAttrVos=skuSaleAttrValueService.listSaleAttrs(spuId);
skuItemVo.setSaleAttr(saleAttrVos);
//4、获取spu的介绍-> 依赖1 获取spuId
SpuInfoDescEntity byId = spuInfoDescService.getById(spuId);
skuItemVo.setDesc(byId);
//5、获取spu的规格参数信息-> 依赖1 获取spuId catalogId
List<SpuItemAttrGroupVo> spuItemAttrGroupVos=productAttrValueService.getProductGroupAttrsBySpuId(spuId, catalogId);
skuItemVo.setGroupAttrs(spuItemAttrGroupVos);
//TODO 6、秒杀商品的优惠信息
return skuItemVo;
}
(4) 优化:异步编排
因为商品详情是查多个sql,所以可以利用线程池进行异步操作,但是因为有的步骤需要用到第一步的spu_d结果等想你想,所以需要使用异步编排。
调用thenAcceptAsync()可以接受上一步的结果且没有返回值。
最后调用get()方法使主线程阻塞到其他线程完成任务。
@Override // SkuInfoServiceImpl
public SkuItemVo item(Long skuId) throws ExecutionException, InterruptedException {
SkuItemVo skuItemVo = new SkuItemVo();
CompletableFuture<SkuInfoEntity> infoFutrue = CompletableFuture.supplyAsync(() -> {
//1 sku基本信息
SkuInfoEntity info = getById(skuId);
skuItemVo.setInfo(info);
return info;
}, executor);
// 无需获取返回值
CompletableFuture<Void> imageFuture = CompletableFuture.runAsync(() -> {
//2 sku图片信息
List<SkuImagesEntity> images = imagesService.getImagesBySkuId(skuId);
skuItemVo.setImages(images);
}, executor);
// 在1之后
CompletableFuture<Void> saleAttrFuture =infoFutrue.thenAcceptAsync(res -> {
//3 获取spu销售属性组合 list
List<ItemSaleAttrVo> saleAttrVos = skuSaleAttrValueService.getSaleAttrsBuSpuId(res.getSpuId());
skuItemVo.setSaleAttr(saleAttrVos);
},executor);
// 在1之后
CompletableFuture<Void> descFuture = infoFutrue.thenAcceptAsync(res -> {
//4 获取spu介绍
SpuInfoDescEntity spuInfo = spuInfoDescService.getById(res.getSpuId());
skuItemVo.setDesc(spuInfo);
},executor);
// 在1之后
CompletableFuture<Void> baseAttrFuture = infoFutrue.thenAcceptAsync(res -> {
//5 获取spu规格参数信息
List<SpuItemAttrGroup> attrGroups = attrGroupService.getAttrGroupWithAttrsBySpuId(res.getSpuId(), res.getCatalogId());
skuItemVo.setGroupAttrs(attrGroups);
}, executor);
// 6.查询当前sku是否参与秒杀优惠
CompletableFuture<Void> secKillFuture = CompletableFuture.runAsync(() -> {
R skuSeckillInfo = seckillFeignService.getSkuSeckillInfo(skuId);
if (skuSeckillInfo.getCode() == 0) {
SeckillInfoVo seckillInfoVo = skuSeckillInfo.getData(new TypeReference<SeckillInfoVo>() {
});
skuItemVo.setSeckillInfoVo(seckillInfoVo);
}
}, executor);
// 等待所有任务都完成再返回
CompletableFuture.allOf(imageFuture,saleAttrFuture,descFuture,baseAttrFuture,secKillFuture).get();
return skuItemVo;
}
线程池参数:
- 20-50核心线程,200最大线程,1W长度等待队列
(5) 页面sku切换
页面上12 45渲染都比较简单,我们需要看看4是如何渲染的。
之前拿到的sku_ids是用,分隔的,
通过控制class中是否包换checked属性来控制显示样式,因此要根据skuId判断
- 选择的标签多个checked class,下面有个containers函数是判断当前的元素是否是当前sku的元素
<div class="box-attr clear" th:each="attr : ${item.saleAttr}">
<dl>
<dt>选择[[${attr.attrName}]]</dt>
<dd th:each="vals : ${attr.attrValues}">
<a class="sku_attr_value" th:attr="skus=${vals.skuIds}, class=${#lists.contains( #strings.listSplit(vals.skuIds,','), item.info.skuId.toString() )? 'sku_attr_value checked': 'sku_attr_value'}">
<!--<img src="/static/item/img/59ddfcb1Nc3edb8f1.jpg" />-->
[[${vals.attrValue}]]
</a>
</dd>
</dl>
</div>
显示处理完了,下面编写选中某个售卖属性后如何变化页面元素
实际上我觉得应该发送ajax请求更改页面元素。这里选用的是根据选中的售卖属性组合判断出sku_id
怎么找交集:
$(".sku_attr_value").click(function () {
var skus = new Array();
// 1.获取所有加了checked的属性
// 1.1 点击的元素加上自定义属性
$(this).addClass("clicked");
var curr = $(this).attr("skus").split(",");
// 当前被点击的所有sku组合的数组放进去
skus.push(curr)
// 去掉同一行所有的checked
$(this).parent().parent().find(".sku_attr_value").removeClass("checked");
// 注意这个a[class='sku_attr_value checked']
$("a[class='sku_attr_value checked']").each(function () {
// 把选择的元素的[sku_id]都放到skus中
skus.push($(this).attr("skus").split(","));
});
// 2.取出他们的交集 得到skuId 调用filter方法的一定是jQuery元素
var filterEle = skus[0];
for (var i = 1; i < skus.length; i++) {
// $(a).filter(b)就是求a b的交集
filterEle = $(filterEle).filter(skus[i]);
}
console.log(filterEle[0])
// 3.跳转
location.href = "http://item.gulimall.com/" + filterEle[0] + ".html";
});
十、认证服务
认证服务的笔记写到了另外一篇:https://blog.csdn.net/hancoder/article/details/114242184
笔记不易:
离线笔记均为markdown格式,图片也是云图,10多篇笔记20W字,压缩包仅500k,推荐使用typora阅读。也可以自己导入有道云笔记等软件中
阿里云图床现在每周得几十元充值,都要自己往里搭了,麻烦不要散播与转发

打赏后请主动发支付信息到邮箱 553736044@qq.com ,上班期间很容易忽略收账信息,邮箱回邮基本秒回
禁止转载发布,禁止散播,若发现大量散播,将对本系统文章图床进行重置处理。
技术人就该干点技术人该干的事
如果帮到了你,留下赞吧,谢谢支持
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144450.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
