大家好,又见面了,我是你们的朋友全栈君。
NSGA3算法及其MATLAB版本实现
- 一丶NSGA3和NSGA2的一些参考资料
其实我在github上找到了NSGA3 matlab实现的一个非常好的版本,大家可以我的主页去下载,MOEAs,希望对大家有所帮助,干货贴在前面,这个不是我写的,是我搜到fork到自己仓库的。
看懂NSGA3之前,了解的NSGA2的话更有帮助,这个博士写的带约束的NSGA2的matlab版本很不错(9个非约束的测试问题和5个带约束的测试问题),大家想了解NSGA3的最好先看看。
1. Constrained NSGA2:
https://cn.mathworks.com/matlabcentral/fileexchange/49806-matlab-code-for-constrained-nsga-ii-dr-s-baskar–s-tamilselvi-and-p-r-varshini
再来介绍一下Deb大神的实验室公开发布的代码链接,里面有大神实验室的nsga2各种版本的代码(主要是c语言实现的)
- Kalyanmoy Deb的实验室网站:
http://www.egr.msu.edu/~kdeb/codes.shtml
鉴于初学者都需要一个能跑限起来的程序,不受打击,又很烦某CS某DN上无耻的要shoufei下载,我发一个网址,大家自行去下吧,这个代码比较简单,当然也有逻辑上的瑕疵,但是对于初学者够用了(天天996,实在没空更新和回复,大家见谅,估计有很多用这个解决多目标柔性作业车间调度这种问题的,建议学完了去看我后面贴的清华博士(袁源)的博士论文吧,这个不会给源码的,首先自己觉得代码洗的很烂,懒得回去改了,发出来献丑,其次,开源不是这么开源的,真花功夫投入的理解源码的,其实我发的这些东西够用了):
https://yarpiz.com/
谢谢已经有大神们公布了他们所理解的nsga3的代码,至今为止(2018.1.2),我能找到的NSGA3算法的代码有两个版本(Deb团队尚未公布NSGA3标准版本的代码),有读者能找到其他版本的话,希望可以共享链接(谢谢):
1- Yarpiz团队的matlab版本(归一化有一点问题,后面会讲到),有和一个同学讨论了一下,这个版本问题挺大的,建议大家直接看MOEA-dev,这个版本先归一化再非支配排序,其实应该先非支配排序然后再归一化的,感谢这个同学的指出,我贴出来是因为这个版本代码风格很好,MOEA可能不适合第一次接触遗传算法的 同学:
http://cn.mathworks.com/matlabcentral/fileexchange/60678-nsga-iii-in-matlab
2- 台湾师范大学教授写的一个C语言版本:
http://web.ntnu.edu.tw/~tcchiang/publications/nsga3cpp/nsga3cpp.htm
对了这是NSGA3两篇论文下载链接:
1.An Evolutionary Many-Objective Optimization Algorithm Using Reference-point Based Non-dominated Sorting Approach,Part I: Solving Problems with Box Constraints.
http://www.egr.msu.edu/~kdeb/papers/k2012009.pdf
2.An Evolutionary Many-Objective Optimization Algorithm Using Reference-point Based Non-dominated Sorting Approach, Part II: Handling Constraints and Extending to an Adaptive Approach.
http://www.egr.msu.edu/~kdeb/papers/k2012010.pdf
好了,进入正题,我们直接开始介绍一下NSGA3(读到这里我希望大家对NSGA2已经很了解了,加油~),NSGA3与NSGA2的算法框架大致相同,只是在选择机制有所不同。NSGA2用拥挤距离对同一非支配等级的个体进行选择(拥挤距离越大越好),而NSGA3用的是基于参考点的方法对个体进行选择。NSGA3采用基于参考点的方法就是为了解决在面对三个及其以上目标的多目标优化问题时,如果继续采用拥挤距离的话,算法的收敛性和多样性不好的问题(就是得到的解在非支配层上分布不均匀,这样会导致算法陷入局部最优)。
-
二丶NSGA3的基本流程
NSGA-III 首先定义一组参考点。然后随机生成含有 N 个(原文献说最好与参考点个数相同)个体的初始种群,其中 N 是种群大小。接下来,算法进行迭代直至终止条件满足。在第 t 代,算法在当前种群 Pt的基础上,通过随机选择,模拟两点交叉(Simulated Binary Crossover,SBX)和多项式变异 产生子代种群 Qt。Pt和 Qt的大小均为 N。因此,两个种群 Pt和 Qt合并会形成种群大小为 2N 的新的种群 Rt=Pt∪Qt。
为了从种群 Rt中选择最好的 N 个解进入下一代,首先利用基于Pareto支配的非支配排序将 Rt分为若干不同的非支配层(F1,F2等等)。然后,算法构建一个新的种群St,构建方法是从 F1开始,逐次将各非支配层的解加入到 St,直至 St的大小等于 N,或首次大于 N。假设最后可以接受的非支配层是 L层,那么在 L+ 1 层以及之后的那些解就被丢弃掉了,且 St\ FL中的解已经确定被选择作为 Pt+1中的解。Pt+1中余下的个体需要从 FL中选取,选择的依据是要使种群在目标空间中具有理想的多样性。
这一段我举个例子说明一下,比如你的N设置为100,那么Pt大小为100,Qt是Pt交叉和变异后的个体,Qt的数目也是100,那么Rt=Pt∪Qt,Rt数目是两百,现在只要从这两百中选100个个体进行下一轮迭代。
那么怎么从这两百个选一百个呢?NSGA的思想首先是把所有解进行分非支配排序,这里目标值越小越好,甲三个目标值是(2,3,5),乙的三个目标是(4,3,5),丙的三个目标是(3,3,4),那么给甲和丙在F1层即等级为1,F2层是乙,等级为2,以此类推。假如一共有8层非支配层(F1,F2,。。。,F8),你选到F1+F2+F3+…+F7时候已经有90个个体了,而F8层有20个个体,那么怎么在F8选这10个个体,即怎么在F8里的20个选十个,NSGA2用的是基于拥挤距离的方法,而NSGA3用的是基于参考点的方法。( St\ FL里面,St就是这里的F1到F7的所有个体的总和,F8就是FL,St\ FL这个符号意思就是已经被选择的F1到F7所有个体)
在原始NSGA-II中,FL中具有较大拥挤距离的解会优先被选择。然而,拥挤距离度量并不适合求解 MaOPs(三个及更多目标的多目标优化问题)。因此 NSGA-III 不再采用拥挤距离,而是采用了新的选择机制(这个机制就是NSGA3与2之间的最大区别之处),该机制会通过所提供的参考点,对 St中的个体进行更加系统地分析,以选择 FL中的部分解进入 Pt+1。


-
三丶算法关键步骤
- Normalize objectives目标归一化部分(原文Algorithm 1 步骤14)

以下讲解需要注意的地方:
步骤2:Compute ideal point(计算理想点):即求解这一代种群所有目标的最小值。比如甲三个目标值是(2,3,5),乙的三个目标是(4,3,5),丙的三个目标是(3,3,4),那么 ideal point为(2,3,4)。
步骤3: Translate objectives(把所有个体的目标值减去 ideal point): 即甲三个目标值是(0,0,1),乙的三个目标是(2,0,1),丙的三个目标是(1,0,0)。
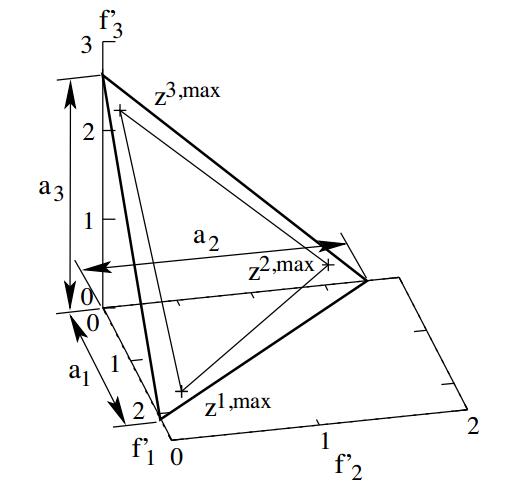
步骤4: Compute extreme points(计算极值点): 这是最难理解的一步。
它的意思就是使得这个这方程最小的向量就是我们要找的极值点,这点比较难理解,我慢慢解释,拿三个目标的例子来说明,我们先看下图,这所谓的极值点指的啥?
其实就是图中的z1,max z2,max he z3,max三个点,它们各自和原点(即 ideal point)组成的三条线,这三条线就可以组成一个面,这个面和三个坐标轴的交点就是我们最终要求解的截距a1,a2和a3。找到截距后我们,用截距来按照下面的方程进行归一化:
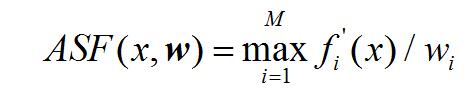
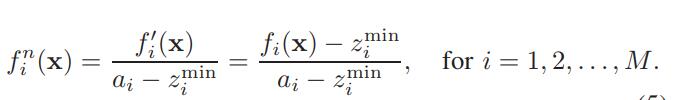
我们把三个目标值范围不一样的问题称为非归一化类的问题,这个大家可以参考这篇博士论文:袁源. 基于分解的多目标进化算法及其应用[D]. 清华大学, 2015. 这个大神在里面提出另一个归一化的思路,有兴趣可以了解。
归一化这个步骤本身很好理解。难理解的地方是怎么找到这个极值点。我们还是举三个目标的问题作为例子,我们初始化种群后,会得到很多个体,他们的目标值可能是(1,3,0.3),(2,6,0.3),(0.1,0.2,3)等等,如果有一些点如果在一个目标上的值很大,在另外两个目标上的值很小,这些点就更靠近这个坐标轴,这个就是所谓的 extreme points,目标就是找到在一个方向上值很大,另外两个目标值很小的点,三个目标的问题话对应我们可以找到三个这样的 extreme points。比如在ASF方程中,固定第一个坐标轴,(1,0.2,0.3)/(1,10e-6, 10e-6),这个时候最大的肯定是0.3这个方向,在固定第一个坐标轴时。我们在群体中找到另外两个目标中小的那个。比如(1,0.6,0.3)在ASF后变为0.610e6,(1,0.2,0.3)在ASF后变为0.310e6,(1,0.1,0.2)在ASF后变为0.210e6,这三个点那个作为extreme points最为合适,我想现在你肯定知道了,0.210e6是最小的,对应(1,0.1,0.2)是最合适的。这就是原文Thereafter, the extreme point in each objective axis is identified by finding the solution (x ∈ St) that makes the following
achievement scalarizing function minimum with weight vector w being the axis direction这句话的意思,也是NSGA3算法最难理解的一步。
6: Compute intercepts aj for j = 1, . . . , M,得到了极值点,就可以构建超平面计算截距了,怎么求?台湾师范大学教授那个C版本的NSGA3有详细说明,我直接复制了
// Given a NxN matrix A and a Nx1 vector b, generate a Nx1 vector x
// such that Ax = b.
//
// Use this to get a hyperplane for a given set of points.
// Example.
// Given three points (-1, 1, 2), (2, 0, -3), and (5, 1, -2).(这里就是我们的extreme point)
// The equation of the hyperplane is ax+by+cz=d, or a'x +b'y + c'z = 1.
// So we have
//
// (-1)a' + b' + 2c' = 1.
// 2a' - 3c' = 1.
// 5a' + b' -2c' = 1.
//
// Let A be { {-1, 1, 2}, {2, 0, -3}, {5, 1, -2} } and b be {1, 1, 1}.
// This function will generate x as {-0.4, 1.8, -0.6},
// which means the equation is (-0.4)x + 1.8y - 0.6z = 1, or 2x-9y+3z+5=0.
//
// The intercepts are {1/-0.4, 0, 0}, {0, 1/1.8, 0}, and {0, 0, 1/-0.6}.
这步还要注意的是,万一这个超平面构建不起来咋办?袁源. 基于分解的多目标进化算法及其应用里有提示在4.2.4章节里,我截个图:

7: Normalize objectives (fn) using Equation 5
- Normalize objectives目标归一化部分很关键,基于参考点的选择部分一样重要,这部分也难理解最好的还是NSGA3原文献里algorithm4那个选择过程的伪代码最好理解,反而前面E.Niche-preservation operation 里写复杂了,还是老样子直接放伪代码,难理解的地方主要有两个。

第一点是:其实和这个
其实完全等同,指的是一个意思。
所以 指的是层中,即层之前的所有非支配层中和参考点 j 关联的个体数。
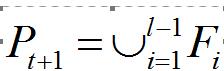
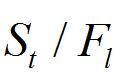
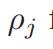
第二点: 原文明确告诉你:
这个意思就是在层中和参考点关联的个体数,即小生镜数。
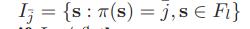

第三点: 理解上面之后就简单了许多:先看看中有没和关联的个体,没有的话换一个
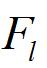
如果中有至少一个与关联的个体,那么还要分两种情况
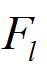
如果,即中没有与关联的个体,那么选距离最短的那个到中,否则,随机选取一个个体到中。当然上诉两种情况都是在层中选。直到大小也等于原本种群的大小。
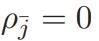
- 四丶一些多目标遗传算法的代码
其实我在github上找到了NSGA3 matlab实现的一个非常好的版本,大家可以我的主页去下载,MOEAs,希望对大家有所帮助,这个博客排版什么的我太粗糙了,大家体谅,其实就是归一化和选择这个两个步骤最难理解,我写详细了,研究过NSGA3的基本都能自己实现了,欢迎评论交流,祝好运!!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144254.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
