大家好,又见面了,我是你们的朋友全栈君。
目录
- 预备知识
- 多目标优化问题的解
- NSGA-II 简介
- 快速非支配排序
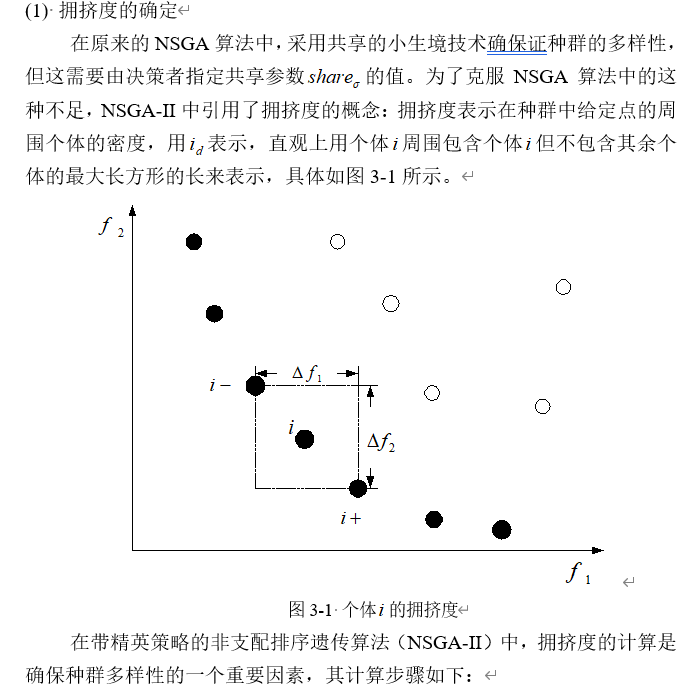
- 拥挤度
- 精英策略
- 部分代码展示
1.预备知识
多目标优化的相关知识:https://blog.csdn.net/haha0332/article/details/88634378
支配:假设小明9岁,50斤,小红8岁,45斤,小明无论是岁数还是体重都比小红大,所以小明支配小红。
互不支配:假设小明7岁,50斤,小红8岁,45斤,小明岁数比小红小,但体重比小红大,所以小明和小红互不支配。
帕累托集:在这个集合中,任意两个解互不支配。
非支配排序:将一组解分成n个集合:rank1,rank2…rankn,每个集合中所有的解都互不支配,但ranki中的任意解支配rankj中的任意解(i<j).
2.多目标优化问题的解
在单目标优化问题中,通常最优解只有一个,而且能用比较简单和常用的数学方法求出其最优解。而在多目标优化问题中,各个目标之间相互制约,可能使得一个目标性能的改善往往是以损失其他目标性能为代价,不可能存在一个使所有目标性能都达到最优的解(这就意味着这两个目标可能存在较大的负相关性),所以对于多目标优化问题,其解通常是一个非劣解的集合–帕累托解集。
在存在多个帕累托最优解的情况下,如果没有关于问题更多的信息,那么很难选择哪个解更可取,因此所有的帕累托最优解都可以被认为使同等重要的。由此可知,对于多目标优化问题,最重要的任务使找到尽可能多的关于该优化问题的帕累托最优解。因而,在多目标优化中主要完成以下两个任务:
(1)找到一组尽可能接近帕累托最优域的解
(2)找到一组尽可能不同的解
第一个任务使在任何优化工作中都必须做到的,收敛不到接近真正帕累托最优解集的解是不可取的,只有当一组解收敛到接近真正帕累托最优解,才能确保该组解近似最优的这一特性。
除了要求优化问题的解要收敛到近似帕累托最优域,求得的解也必须均匀的分布在帕累托最优域上。一组在多个目标之间好的协议解是建立在一组多样解的基础上。简单来说就是一组解中的差异性越大,这组解视为越好。
3.NSGA2算法的简介
多目标遗传算法是用来分析和解决多目标优化问题的一种进化算法,其核心就是协调各个目标函数之间的关系,找出使得各个目标函数都尽可能达到比较大的(或者比较小的)函数值的最优解集。在众多目标优化的遗传算法中,NSGA2算法是影响最大和应用范围最广的一种多目标遗传算法。在其出现后,由于它简单有效以及比较明显的优越性,使得该算法已经成为多目标优化问题中的基本算法之一。
介绍NSGA2,首先来介绍以下NSGA算法。
NSGA通过基于非支配排序的方法保留了种群中的优良个体,并且利用适应度共享函数保持了群体的多样性,取得了非常良好的效果。但实际工程领域中发现NSGA算法存在明显不足,这主要体现在如下3个方面:
(1)非支配排序的高计算复杂性。非支配排序算法一般要进行mN^3次搜索(m是目标函数的数目,体重和年龄可以被视为两个目标函数,N是一组解的大小),搜索的次数随着目标函数数量和种群大小的增加而增多。
(2)缺少精英策略。研究结果表明,引用精英策略可以加快遗传算法的执行,并且还助于防止优秀的个体丢失。
(3)需要指定共享参数share,在NSGA算法中保持种群和解的多样性方法都是依赖于共享的概念,共享的主要问题之一就是需要人为指定一个共享参数share。
为了克服非支配排序遗传算法(NSGA)的上述不足,印度科学家Deb于2002年在NSGA算法的基础上进行了改进,提出了带精英策略的非支配排序遗传算法(Elitist Non-Dominated Sorting Genetic Algorithm,NSGA-II),NSGA-II 算法针对NSGA的缺陷通过以下三个方面进行了改进[16]:
- 提出了快速非支配的排序算法,降低了计算非支配序的复杂度,使得优化算法的复杂度由原来的 降为 ( 为目标函数的个数, 为种群的大小)。
- 引入了精英策略,扩大了采样空间。将父代种群与其产生的子代种群组合在一起,共同通过竞争来产生下一代种群,这有利于是父代中的优良个体得以保持,保证那些优良的个体在进化过程中不被丢弃,从而提高优化结果的准确度。并且通过对种群所有个体分层存放,使得最佳个体不会丢失,能够迅速提高种群水平。
- 引入拥挤度和拥挤度比较算子,这不但克服了NSGA算法中需要人为指定共享参数 的缺陷,而且将拥挤度作为种群中个体之间的比较准则,使得准Pareto域中的种群个体能均匀扩展到整个Pareto域,从而保证了种群的多样性。
4.快速非支配排序
在NSGA算法中采用的是非支配排序方法,该方法的计算复杂度是O( mN^3),而在NSGA-II算法中采用快速非支配排序的方法,其计算复杂度仅O(mN2)。下面,简要说明二者计算复杂度的由来:
(1) 非支配排序算法的计算复杂度:
为了对优化对象的个数为m,种群规模大小为N的种群进行非支配排序,每一个个体都必须和种群中其它的个体进行比较,从而得出该个体是否被支配,这样每个个体就总共需要 次的比较,需要O(mN )的计算复杂度。当这一步骤完成之后,继续找出第一个非支配层上的所有个体,这需要遍历整个种群,其总的计算复杂度就是O( mN^2)。在这一步中,所有在第一个非支配层中的个体都被寻找到,为了找到随后各个等级中的个体,重复前面的操作。可以看到,在最坏的情况下(每一层级上只有一个个体),完成对整个种群所有个体的分级,这种算法的计算复杂度为O( mN3)。
(2) 快速非支配排序算法的计算复杂度:
对于种群中每一个个体 i,都设有两个参数ni和Si,ni是种群中支配个体i的解的个体数量,Si是被个体i 支配的解的个体的集合。
- 找出种群中所有ni=0的个体,将它们存入当前非支配集合rank1中;
- 对于当前非支配集合rank1中的每一个个体 j,遍历它所支配的个体集合Sj,将集合Sj中每一个个体 t的 nt都减去1,即支配个体t的解的个体数量减1(因为支配个体 的个体j已经存入当前非支配集 中),如果 nt-1=0,则将个体t存入另一个集H;
- 把rank1作为第一级非支配个体的集合,所以在rank1中的解个体是最优的。它只支配个体,而不受其他任何个体所支配,对该集合内所有个体都赋予相同的非支配序 ,然后继续对集合H作上述分级操作,并也赋予相应的非支配序,直到所有的个体都被分级,即都被赋予赋予相应的非支配序。
每一次迭代操作,即上述快速非支配排序算法步骤的1)和2)需要N次计算。于是,整个迭代过程的计算复杂度最大是N^2。这样,整个快速非支配排序算法的计算复杂度就是: mN2
5.拥挤度
手打好痛苦,还有各种公式不让我打,直接用word打了复制上来吧。



6.精英策略
NSGA-II算法引入了精英策略,以防止在种群的进化过程中优秀个体的流失,通过将父代种群与其产生的子代种群混合后进行非支配排序的方法,能够有较好地避免父代种群中优秀个体的流失。精英策略的执行步骤如图3-2所示: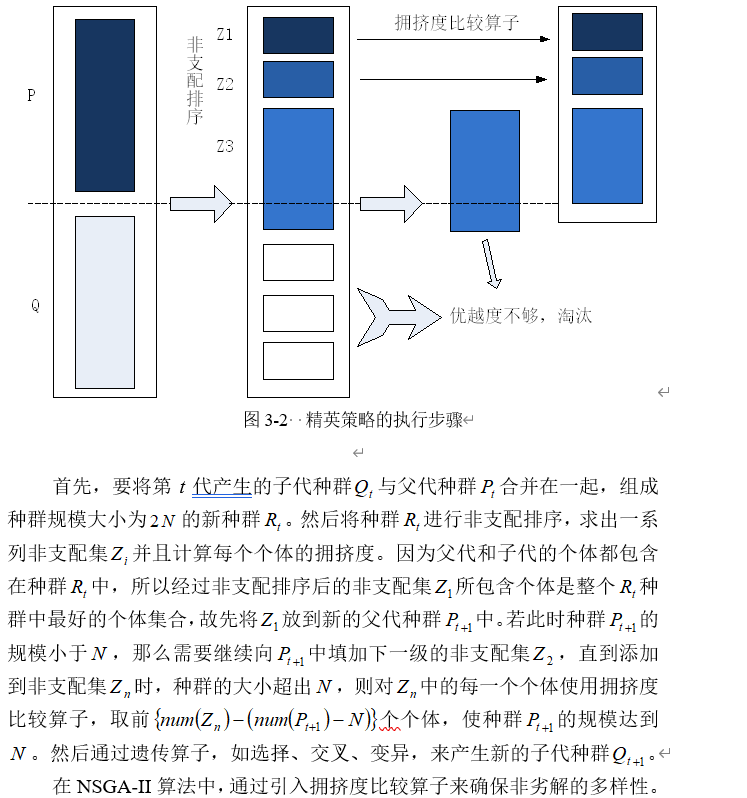

**7.部分代码展示**
```java
/*
* nsga2的选择部分
*/
public static Population nsga2(Population father, Population child) { // 两代种群的所有个体都参与筛选
HashMap<Integer, Individual> fatherAndChild = new HashMap<Integer, Individual>();
//father.map放入的是父代的所有个体
fatherAndChild.putAll(father.map);
Population.MAXSIZE是该种群的最大大小
for (int i = 0; i < Population.MAXSIZE; i++) {
//父代和子代一起进行筛选
fatherAndChild.put(i + father.map.size(), child.map.get(i));
}
// 对每个个体进行处理,找出被它支配和支配它的个体
fatherAndChild.forEach((key,in)->{
//n是该个体被多少个体支配
in.n=0;
//dominate是该个体支配多少个体
in.dominate.clear();
});
fatherAndChild.forEach((key1,in)->{
fatherAndChild.forEach((key, o) -> {
if (((in.fitness1 < o.fitness1) && (in.fitness2 <o.fitness2))||((in.fitness1 <=o.fitness1) && (in.fitness2 < o.fitness2))||((in.fitness1 < o.fitness1) && (in.fitness2 <= o.fitness2)))// 找出in支配的个体放入dominate中
{
in.dominate.add(o);
}else
if (((in.fitness1 > o.fitness1) && (in.fitness2 > o.fitness2))||((in.fitness1 >= o.fitness1) && (in.fitness2 > o.fitness2))||((in.fitness1 > o.fitness1) && (in.fitness2 >= o.fitness2)))// 碰上一个支配in的个体就++n
{
in.n++;
}
});
});
ArrayList<ArrayList<Individual>> rank = new ArrayList<ArrayList<Individual>>();// 对种群进行分级别
// 外层的ArrayList是存放每一个rank,内层的ArrayList是存放该rank对应的个体
while (!fatherAndChild.isEmpty())// 本函数将所有个体进行分级,分级后放入rank数组中
{
ArrayList<Individual> po = new ArrayList<Individual>();// 用来存放第x rank的个体,这里的x是while的第x个循环
for (int i = 0; i < Population.MAXSIZE * 2; i++)// 对哈希表中的每个个体进行遍历
{
Individual indi = fatherAndChild.get(i);
if (indi == null)
continue;
if (indi.n == 0)// 如果发现该个体的n为0,即没有支配该个体的其他个体
{
po.add(indi);// 将该个体放入第n rank的集合中
fatherAndChild.remove(i);// 把该个体从哈希表中去除
// for (Individual in : indi.dominate) {
// --in.n;
// }
}
}
for(Individual indi:po)
for(Individual in:indi.dominate)
{
in.n--;
}
rank.add(po);// 该rank的所有个体都放入ArrayList后将该ArrayList放入对应rank的位置
}
// int t=0;
// for(ArrayList<Individual> arr:rank)
// {
// System.out.println(++t);
// for(Individual indi:arr)
// {
// System.out.println(indi.fitness1+" "+indi.fitness2);
// }
// }
// 查找哪个rank放入新生一代之后会超出MAXSIZE
int num = Population.MAXSIZE;
int index = 0;// 这是用来指示第几rank的
while (true) {
if (num - rank.get(index).size() > 0) {
num = num - rank.get(index).size();
++index;
} else {
break;
}
}
// 找出该rank
ArrayList<Individual> po = rank.get(index);
//System.out.println("最后一层有"+po.size()+"个");
// 对该rank根据fitness1的大小进行排序,根据fitness2也可以
po.sort((Individual o1, Individual o2) -> { // TODO Auto-generated method stub
// int i = o1.fitness1 > o2.fitness1 ? 1 : -1;
// return i;
if(o1.fitness1>o2.fitness1)
return 1;
else if(o1.fitness1<o2.fitness1)
return -1;
return 0;
}
);
//归一化
double fitness1sum=0,fitness2sum=0;
int numSum=0;
for(Individual o:po)
{
fitness1sum+=o.fitness1;
fitness2sum+=o.fitness2;
numSum+=o.uav.size();
}
// 对该rank的每一个个体计算其distance
for (int i = 0; i < po.size(); i++) {
if (i == 0 || i == po.size() - 1) {
po.get(i).distance = (float) Double.MAX_VALUE;
} else {
po.get(i).distance = (float) (Math.abs((po.get(i - 1).fitness1 - po.get(i + 1).fitness1)/fitness1sum)
+ Math.abs(po.get(i - 1).fitness2 - po.get(i + 1).fitness2)/fitness2sum
);
}
}
// 对该rank根据distance大小进行排序
po.sort((Individual o1, Individual o2) -> {
// TODO Auto-generated method stub
// int i = o1.distance > o2.distance ? -1 : 1;
// return i;
if(o1.distance>o2.distance)return -1;
else if(o1.distance<o2.distance)return 1;
return 0;
});
// 将所有选中的个体放入新的ArrayList中
ArrayList<Individual> newpo = new ArrayList<Individual>();
for (int i = 0; i < index; i++) {
newpo.addAll(rank.get(i));
}
// 同上
for (int i = 0; i < num; i++) {
newpo.add(po.get(i));
}
//System.out.println("放入"+num+"个");
// 创建一个种群,将刚才筛选出的所有个体作为该种群的组成部分
Population pp = new Population();
for (int i = 0; i < Population.MAXSIZE; i++) {
pp.map.put(i, newpo.get(i));
}
return pp;// 返回该种群
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144209.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...