大家好,又见面了,我是你们的朋友全栈君。


之前已经介绍的变量分析:
①相关分析:一个连续变量与一个连续变量间的关系。
②双样本t检验:一个二分分类变量与一个连续变量间的关系。
③方差分析:一个多分类分类变量与一个连续变量间的关系。
④卡方检验:一个二分分类变量或多分类分类变量与一个二分分类变量间的关系。
本次介绍:
线性回归:多个连续变量与一个连续变量间的关系。
其中线性回归分为简单线性回归和多元线性回归。
/ 01 / 数据分析与数据挖掘
数据库:一个存储数据的工具。因为Python是内存计算,难以处理几十G的数据,所以有时数据清洗需在数据库中进行。
统计学:针对小数据的数据分析方法,比如对数据抽样、描述性分析、结果检验。
人工智能/机器学习/模式识别:神经网络算法,模仿人类神经系统运作,不仅可以通过训练数据进行学习,而且还能根据学习的结果对未知的数据进行预测。
/ 02 / 回归方程
01 简单线性回归
简单线性回归只有一个自变量与一个因变量。
含有的参数有「回归系数」「截距」「扰动项」。
其中「扰动项」又称「随机误差」,服从均值为0的正态分布。
线性回归的因变量实际值与预测值之差称为「残差」。
线性回归旨在使残差平方和最小化。
下面以书中的案例,实现一个简单线性回归。
建立收入与月均信用卡支出的预测模型。
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
from statsmodels.formula.api import ols
# 消除pandas输出省略号情况及换行情况
pd.set_option(‘display.max_columns’, 500)
pd.set_option(‘display.width’, 1000)
# 读取数据,skipinitialspace:忽略分隔符后的空白
df = pd.read_csv(‘creditcard_exp.csv’, skipinitialspace=True)
print(df.head())
读取数据,数据如下。

对数据进行相关性分析。
# 获取信用卡有支出的行数据
exp = df[df[‘avg_exp’].notnull()].copy().iloc[:, 2:].drop(‘age2’, axis=1)
# 获取信用卡无支出的行数据,NaN
exp_new = df[df[‘avg_exp’].isnull()].copy().iloc[:, 2:].drop(‘age2’, axis=1)
# 描述性统计分析
exp.describe(include=’all’)
print(exp.describe(include=’all’))
# 相关性分析
print(exp[[‘avg_exp’, ‘Age’, ‘Income’, ‘dist_home_val’]].corr(method=’pearson’))
输出结果。

发现收入(Income)和平均支出(avg_exp)相关性较大,值为0.674。
使用简单线性回归建立模型。
# 使用简单线性回归建立模型
lm_s = ols(‘avg_exp ~ Income’, data=exp).fit()
print(lm_s.params)
# 输出模型基本信息,回归系数及检验信息,其他模型诊断信息
print(lm_s.summary())
一元线性回归系数的输出结果如下。

从上可知,回归系数值为97.73,截距值为258.05。
模型概况如下。
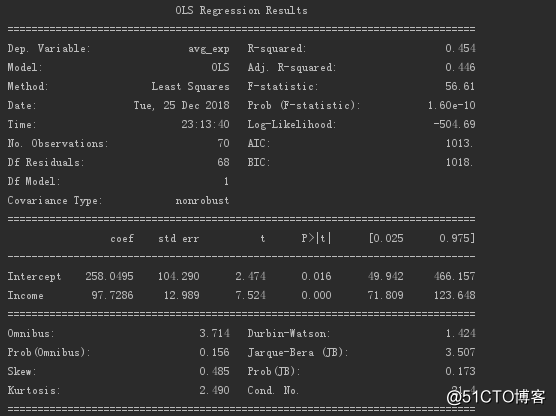
其中R²值为0.454,P值接近于0,所以模型还是有一定参考意义的。
使用线性回归模型测试训练数据集,得出其预测值及残差。
# 生成的模型使用predict产生预测值,resid为训练数据集的残差
print(pd.DataFrame([lm_s.predict(exp), lm_s.resid], index=[‘predict’, ‘resid’]).T.head())
输出结果,可与最开始读取数据时输出的结果对比一下。

使用模型测试预测数据集的结果。
# 对待预测数据集使用模型进行预测
print(lm_s.predict(exp_new)[:5])
输出结果。

02 多元线性回归
多元线性回归是在简单线性回归的基础上,增加更多的自变量。
二元线性回归是最简单的多元线性回归。
其中一元回归拟合的是一条回归线,那么二元回归拟合的便是一个回归平面。
在多元线性回归中,要求自变量与因变量之间要有线性关系,且自变量之间的相关系数要尽可能的低。
回归方程中与因变量线性相关的自变量越多,回归的解释力度就越强。
若方程中非线性相关的自变量越多,那么模型解释力度就越弱。
可以使用调整后的R²(与观测个数及模型自变量个数有关)来评价回归的优劣程度,即评价模型的解释力度。
下面还是以书中的案例,实现一个多元线性回归。
分析客户年龄、年收入、小区房屋均价、当地人均收入与信用卡月均支出的关系。
# 使用多元线性回归建立模型
lm_m = ols(‘avg_exp ~ Age + Income + dist_home_val + dist_avg_income’, data=exp).fit()
print(lm_m.summary())
多元线性回归模型信息如下。
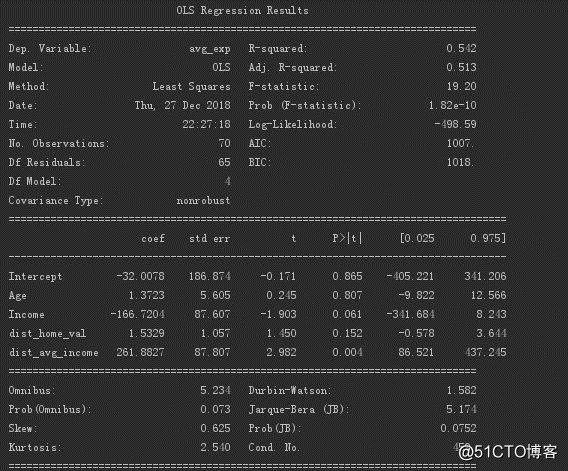
输出R²为0.542,调整R²为0.513。
方程显著性(回归系数不全为0)的检验P值为1.82e-10,接近于0,说明回归方程是有意义的。
客户年龄、小区房屋均价的回归系数都不显著。
年收入、当地人均收入的回归系数显著。
多元线性回归可以根据向前法、向后法、逐步法来对自变量进行筛选。
向前法就是不断加入变量去构建回归方程,向后法则是不断去除变量去构建回归方程,逐步法是两者的结合,又加入又删除的。
三种方法都是基于AIC准则(最小信息准则),其中AIC值越小说明模型效果越好,越简洁。
使用AIC准则能够避免变量的增加成为残差平方和减小的主要原因情况的发生,防止模型复杂度的增加。
本次采用向前回归法,不断加入变量,得到加入后变量的AIC值,最后找到解释力度最大的变量。
# 向前回归法
def forward_select(data, response):
“””data是包含自变量及因变量的数据,response是因变量”””
# 获取自变量列表
remaining = set(data.columns)
remaining.remove(response)
selected = []
# 定义数据类型(正无穷)
current_score, best_new_score = float(‘inf’), float(‘inf’)
# 自变量列表含有自变量时
while remaining:
aic_with_candidates = []
# 对自变量列表进行循环
for candidates in remaining:
# 构建表达式,自变量会不断增加
formula = “{} ~ {}”.format(response, ‘ + ‘.join(selected + [candidates]))
# 生成自变量的AIC解释力度
aic = ols(formula=formula, data=data).fit().aic
# 得到自变量的AIC解释力度列表
aic_with_candidates.append((aic, candidates))
# 对解释力度列表从大到小排序
aic_with_candidates.sort(reverse=True)
# 得到解释力度最大值(AIC值最小)及自变量
best_new_score, best_candidate = aic_with_candidates.pop()
# 1.正无穷大大于解释力度最大值 2.上一期实验的AIC值需大于下一期的AIC实验值,即添加变量越多,AIC值应该越小,模型效果越好
if current_score > best_new_score:
# 移除影响最大的自变量
remaining.remove(best_candidate)
# 添加影响较大的自变量
selected.append(best_candidate)
# 赋值本次实验的AIC值
current_score = best_new_score
print(‘aic is {},continue!’.format(current_score))
else:
print(‘forward selection over!’)
break
# 采用影响较大的自变量列表,对数据做线性回归
formula = “{} ~ {}”.format(response, ‘ + ‘.join(selected))
print(‘final formula is {}’.format(formula))
model = ols(formula=formula, data=data).fit()
return model
# 采用向前回归法筛选变量,利用筛选的变量构建回归模型
data_for_select = exp[[‘avg_exp’, ‘Income’, ‘Age’, ‘dist_home_val’, ‘dist_avg_income’]]
lm_m = forward_select(data=data_for_select, response=’avg_exp’)
print(lm_m.rsquared)
输出结果。
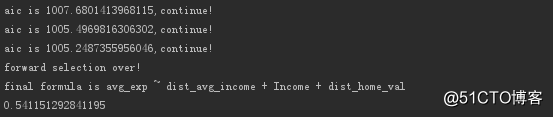
发现客户年龄(Age)被筛除了,最终得到线性回归模型。
/ 03 / 总结
这里只是构建了一下线性回归模型而已,只能说凑合着用。
后面还将对模型进行诊断,使得模型更具有参考价值。
未完待续…
··· END ···

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144156.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
