大家好,又见面了,我是你们的朋友全栈君。
写在前面
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和文献引用请见1000个问题搞定大数据技术体系
解答

HDFS 存储大量小文件有什么问题?
小文件是指文件大小小于 HDFS 上 Block 大小的文件。 这样的文件会给 Hadoop 的扩展性和性能带来严重问题。
首先,在HDFS中,任何 Block、文件或者目录在内存中均以对象的形式存储,每个对象约占 150Byte。
如果有100000个小文件,每个小文件占用一个 Block,则 NameNode 大约需要2GB空间。
如果存储1亿个小文件,则 NameNode 需要约20GB空间。这样一来, NameNode 的内存容量严重制约了集群的扩展。
其次,访问大量小文件的速度远远小于访向几个大文件。
HDFS 最初是为流式访问大文件而开发的,如果访问大量小文件,则需要不断地从一个 DataNode跳到另个 DataNode,严重影响了性能,导致最后处理大量小文件的速度远远小于处理同等大小的大文件的速度。
每个小文件要占用一个 Slot,而 Task 启动将耗费大量时间,从而导致大部分时间都耗费在启动和释放 Task 上。
要想解决小文件的问题,就要想办法减少文件数量,降低 NameNode的压力。
通常有两种解决方法:一种是用户程序合并,另一种是从机制上支持小文件的合并。
用户程序合并
Hadoop自身提供了三种解决方案: HadoopArchive、 SequenceFile 和 CombineFileInputFormat
HadoopArchive
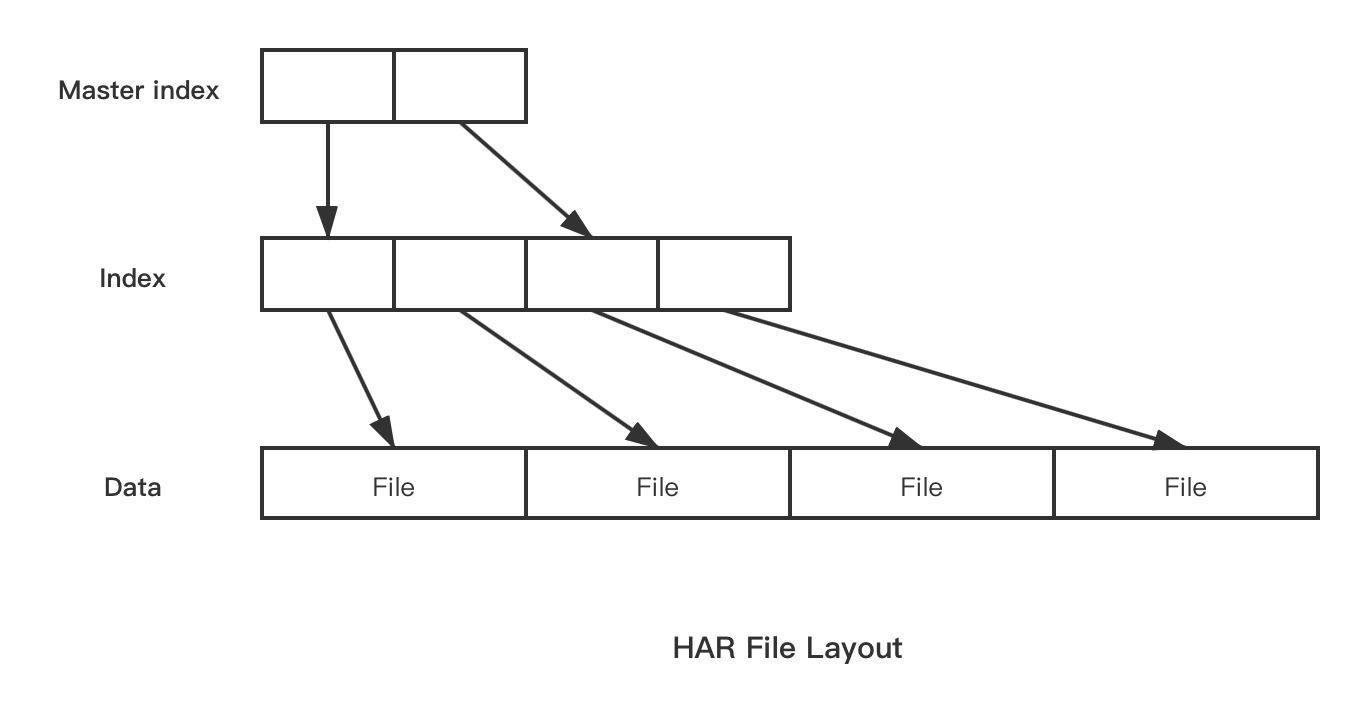
归档为*.har文件,该文件的内部结构如图所示。
创建存档文件的问题
- 存档文件的源文件目录及源文件都不会自动删除,需要手动删除。
- 存档的过程实际是一个 MapReduce 过程,所以需要 Hadoop 的 MapReduce 的支持
- 存档文件本身不支持压缩。
- 存档文件一旦创建便不可修改,要想从中删除或者増加文件,必须重新建立存档文件
- 创建存档文件会创建原始文件的副本,所以至少需要有与存档文件容量相同的磁盘空间
关于 Archive 的详情可以参考我的另一篇博客——一篇文章搞懂 HDFS 的 Archive 到底是什么
SequenceFile
详情请见我的另一篇博客——一篇文章搞懂 SequenceFile 到底是什么以及该怎么用
CombineFileInputFormat
CombineFileInputFormat是一种新的 InputFormat,用于将多个文件合并成一个单独的 Split。另外,它会考虑数据的存储位置。
通用合并方法
业界针对数据的不同特征,有一些合并优化的方法,可以降低文件数量、提高存储性能。
WebGIS 解决方案
在地理信息系统中,为了方便传输,通常将数据切分为KB大小的文件存储在分布式文件系统中。
论文结合 WebGIS 数据的相关特征,将相邻地理位置的小文件合并成个大的文件,并为这些文件构建索引。
论文中将小于 16MB 的文件当作小文件进行合并处理,将其合并成 64MB 的 Block 并构建索引。
BlueSky 解决方案
BlueSky 是中国电子教学共享系统,主要存放的是教学所用的 PPT 文件和视频文件,存放的载体为 HDFS 分布式存储系统。
在用户上传 PPT 文件的同时,系统还会存储些文件的快照。用户请求 PPT 时可以先看到这些快照,以决定是否继续浏览。
用户对文件的请求具有很强的关联性。当用户浏览 PPT 时,其他相关的 PPT 和文件也会在短时间内被访问,因而文件的访问具有相关性和本地性。
TFS解决方案
TFS(Taobao File System)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的 Linux机器集群上,可为外部提供高可靠和高并发的存储访问。
TFS为淘宝提供海量小文件存储,通常文件大小不超过1MB, 满足了淘宝对小文件存储的需求, 被广泛应用在淘宝的各项应用中。
它采用了HA架构和平滑扩容, 保证了整个文件系统的可用性和扩展性。
同时扁平化的数据组织结构可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读/写性能。
小文件社区改进HDFS-8998
社区在HDFS上进行了改进,HDFS-8998提供了在线合并的方案。
HDFS自动启动一个服务,将小文件合并成大文件。
其主要架构如图所示。
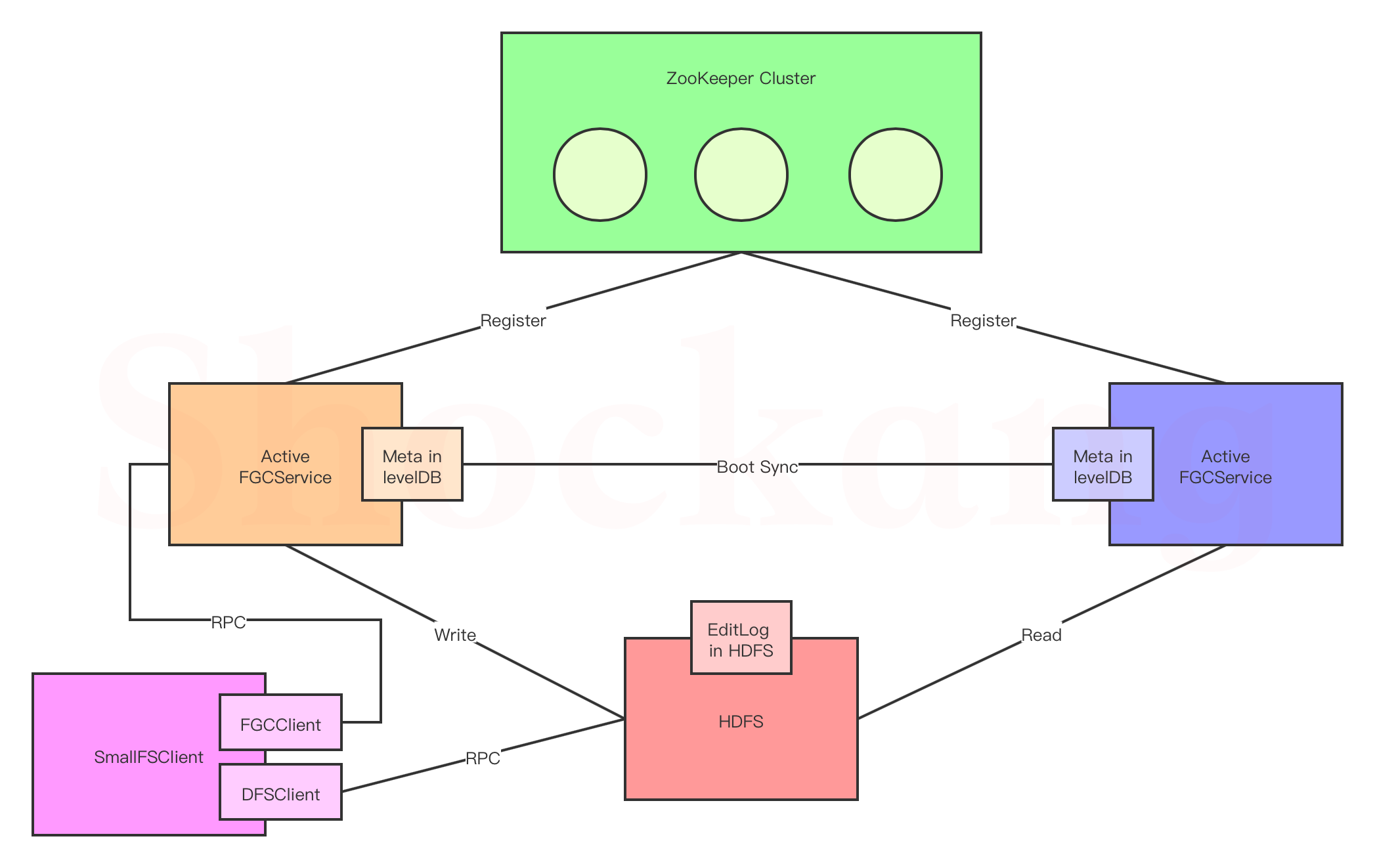
相比原生HDFS,新增一个 FGCServer 的后台服务,服务本身支持HA。元数据存储在 levelDB 中,文件和日志都存储在 HDFS 本身。
后台服务自动搜索小文件,合并符合规则的小文件到大文件。
小文件合并成大文件需要记录小文件在大文件里面的大小、偏移位置、对应关系等信息,这些元数据存储在 levelDB 中因为合并后原始文件的存储位置发生了变更,所以原HDFS的读写等接口的流程也发生了变更。
比如,要读取一个文件,需要先到 FGCServer 中获取小文件元数据、然后再到 HDFS 中获取对应的文件。
通过合并,减轻了 NameNode 的压力,增大了 HDFS 单个 NameNode 支持的文件个数。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144141.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
