大家好,又见面了,我是你们的朋友全栈君。
- 安装肖涵博士的bert-as-service:
pip install bert-serving-server
pip install bert-serving-client - 下载训练好的Bert中文词向量:
https://storage.proxy.ustclug.org/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip - 启动bert-as-service:
找到bert-serving-start.exe所在的文件夹(我直接用的anaconda prompt安装的,bert-serving-start.exe在F:\anaconda\Scripts目录下。)找到训练好的词向量模型并解压,路径如下:G:\python\bert_chinese\chinese_L-12_H-768_A-12
打开cmd窗口,进入到bert-serving-start.exe所在的文件目录下,然后输入:
bert-serving-start -model_dir G:\python\bert_chinese\chinese_L-12_H-768_A-12 -num_worker=1
即可启动bert-as-service(num_worker好像是BERT服务的进程数,例num_worker = 2,意味着它可以最高处理来自 2个客户端的并发请求。)
启动后结果如下:
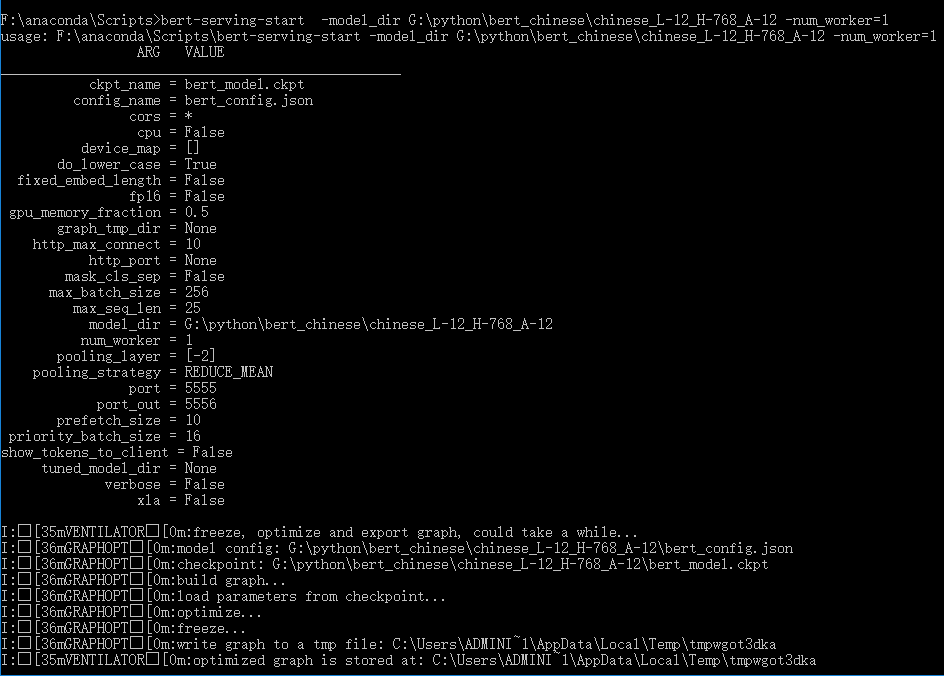

此窗口不要关闭,然后在编译器中即可使用。 - 获取Bert预训练好的中文词向量:
from bert_serving.client import BertClient
bc = BertClient()
print(bc.encode([“NONE”,“没有”,“偷东西”]))#获取词的向量表示
print(bc.encode([“none没有偷东西”]))#获取分词前的句子的向量表示
print(bc.encode([“none 没有 偷 东西”]))#获取分词后的句子向量表示
结果如下:其中每一个向量均是768维。


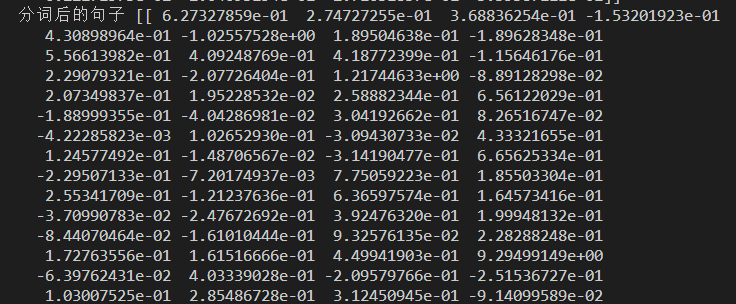
可以看出分词并不会对句子的向量产生影响。
参考文章:
1.https://blog.csdn.net/zhonglongshen/article/details/88125958
2.https://www.colabug.com/5332506.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144010.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
