大家好,又见面了,我是你们的朋友全栈君。


introduction
RCNN首次将卷积操作引入检测领域用于提取特征,然而现有的深度卷积网络需要输入固定尺寸的图片,这个需求可能会导致对于任意scale/size的图片的识别精确度下降。【深度卷积神经网络由卷积层和全连接层组成,卷积层对于任意大小的图片都可以进行卷积运算提取特征,输出任意大小的特征映射,而全连接层由于本身的性质需要输入固定大小的特征尺度,所以固定尺寸的需求来自于FC层,即使对输入图片进行裁剪、扭曲等变换,调整到统一的size,也会导致原图有不同程度失真、识别精度受到影响】SPPNet提出了**“空间金字塔池化”**消除这种需求,不管图像大小是多大,在整张图片上只需要计算一次,就可以得到整幅图像的特征图,经过池化都会输出一个固定长度的表征。
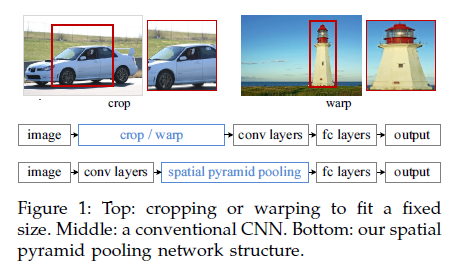
图1所示是图像特征提取方法的不同,之前的方法对图片进行CROP,导致图片中的物体可能不全,只有一部分,或者warp导致图像变形。而作者的方法不需要对图片作这种预处理,在卷积层和全连接层之间加入SPP 层(空间金字塔池化层),对卷积层的输出进行池化,起到一个信息聚合作用,从而避免在一开始对输入图片进行Crop、Warp,产生固定长度的输出,之后再输入到全连接层。
Spatial pyramid pooling (SPP)将图片由粗粒度到细粒度划分为不同的层级,然后聚合它们得局部特征。在CNN出现之前,SPP一直是分类和检测等系统中的重要部分,然而在CNN出现之后,还没有人在CNN背景下对SPP进行研究。SPP与CNN比较有几个特点:
- SPP对于任意大小而输入都能产生固定长度的输出,在之前深度网络中使用的滑动窗口池化不能。
- SPP使用多层级空间箱,而滑动窗口池仅仅使用单个窗口size,多层级池化已经被证明对于物体形变具有鲁棒性。
- 由于输入尺寸的灵活性,SPP可以聚集不同尺度提取的特征。实验表明这些因素对于提高识别准确度有帮助。
训练方法:同一个epoch采用固定size的输入,下一个epoch将输入size切换为另一个size。相比于传统的single size 训练方法,一样可以收敛并且测试精度更高。
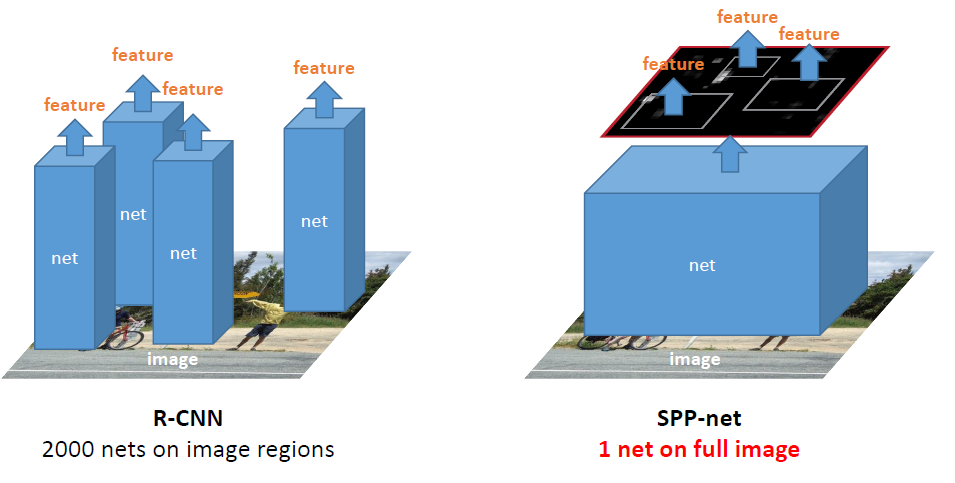
SPP可以对各种深度CNN网络起到加速计算的作用,在整张图片上只计算一次卷积,然后使用SPP在feature map上提取特征,比起R-CNN速度要快24-102倍,使用较新的fast proposal method –EdgeBoxes 0.5秒就可以处理一张图片,接近于现实生活中应用。
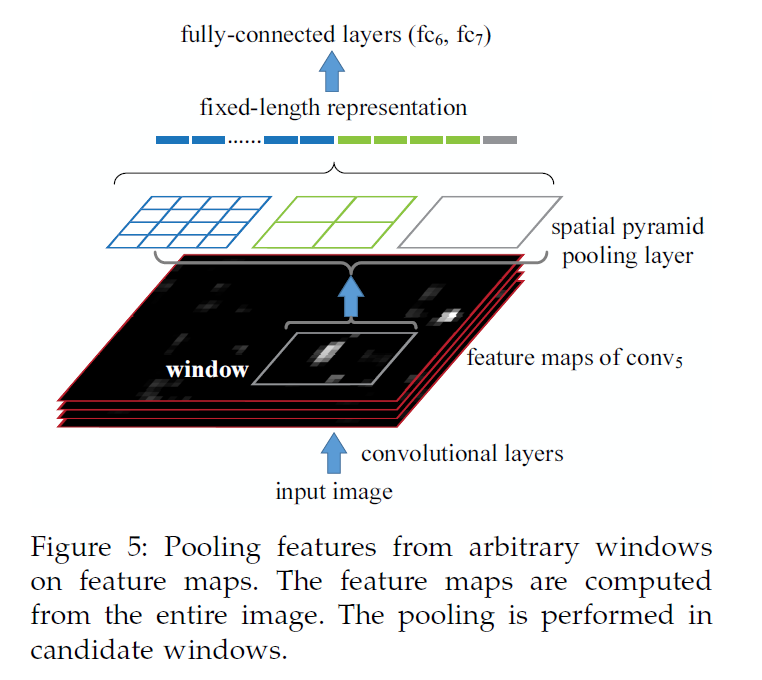
Spatial pyramid Pooling Layer
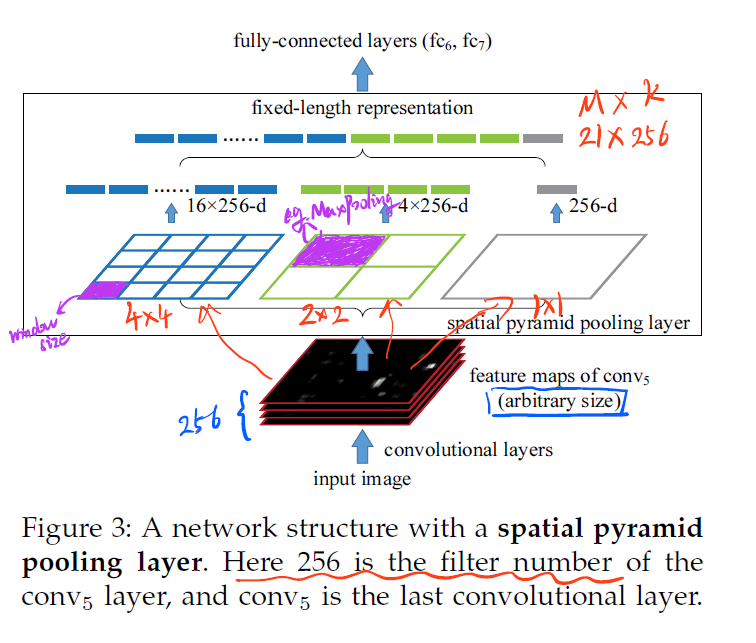
卷积层接受任意大小的输入,但它们产生不同大小的输出。分类器(SVM/softmax)或全连接层需要固定长度向量的输入,这样的向量可以通过词袋(BoW)方法生成,该方法将特征聚合在一起。SPP改进了BoW,因为它可以通过在**局部空间池(local spatial bins)**来维护空间信息。这些空间存储单元的大小与图像大小成比例,因此无论图像大小如何,存储单元的数量都是固定的。这与之前深层网络的滑动窗口池形成对比,后者的滑动窗口数量取决于输入大小。
图3,在每个空间单元中,汇集每个单元(window size)的响应过滤器(在本文中,我们使用最大池化)。空间金字塔池的输出为kM维的向量,K表示最后一层卷积的滤波器数量,M代表l个level的金字塔池化 总共的块(bins)数量。上图中,K=256,M=21(4×4+2×2+1)
在上图中,使用了三级SPP。假设conv5层有256个特征映射。然后在SPP层:
- 首先,将每个特征映射通过1×1的金字塔池化为一个值(灰色),从而形成256-d向量。
- 然后,将每个特征映射通过2×2的金字塔池化为4个值(绿色),并形成一个4×256-d向量。
- 类似地,每个特征映射为16个值(蓝色),并形成一个16×256-d向量。
- 将上述3个向量串联起来形成1-d向量(21x256d)。
- 最后,这个一维向量像往常一样进入FC层。
Multi-Size Training
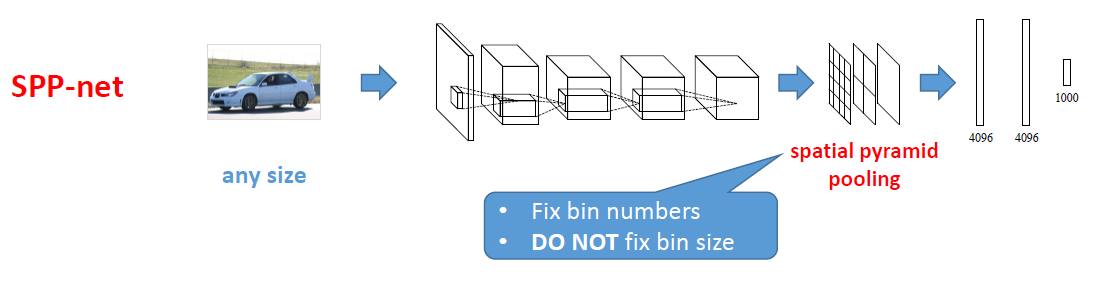
SPPNet supports any sizes due to the use of SPP
在SPP中,接受不同尺寸作为输入,应将不同尺寸输入到网络中,以增加网络在训练期间的鲁棒性。
然而,为了训练过程的有效性,仅使用224×224和180×180图像作为输入。使用共享参数训练两个网络,180-网络和240-网络。
作者复制了ZFNet[3]、AlexNet[4]和Overfeat[5],修改如下(后面的数字是conv层编号):
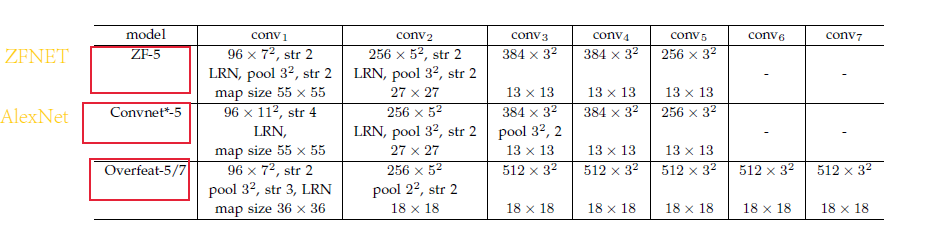
Replicated Model as Baseline
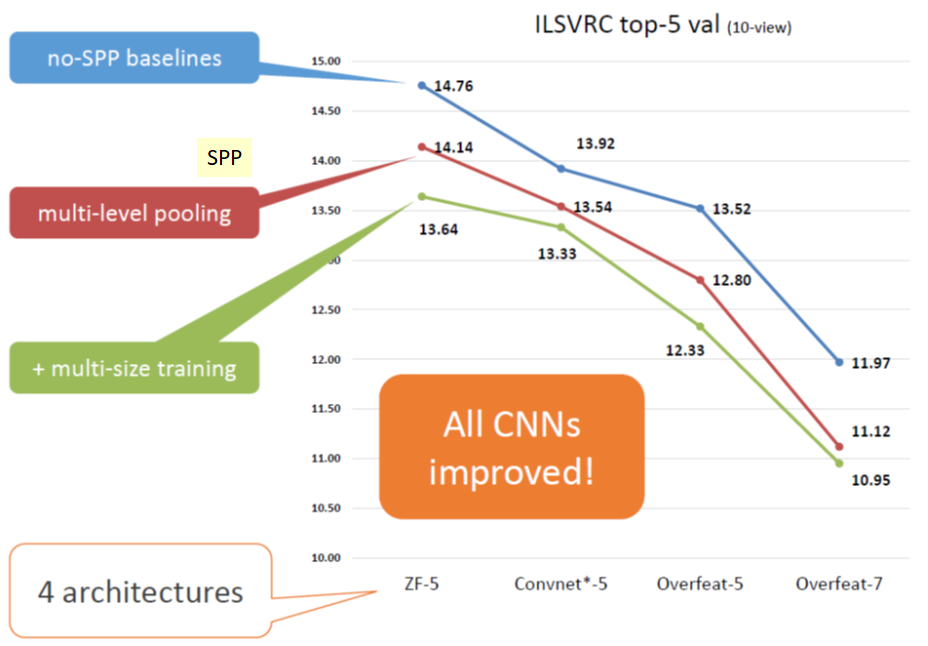
Top-5 Error Rates for SPP and Multi-Size Training
这里使用四级SPPNet和金字塔{6×6,3×3,2×2,1×1}。
如上所示,仅使用SPP,所有模型的错误率都有所降低。通过多尺寸训练,错误率进一步降低。(10 view指10次crop test,包括在四个corner+中心+相应的水平翻转进行的crop)
SPPNet in Object Detection
以上的内容都是在讲解SPPNet的作用和使用方法,具体到目标检测领域,SPPNet在卷积得到的特征映射上对于每个建议框的映射区域(由selective search等方法产生)进行空间金字塔池化输出固定长度的向量并送入全连接层,有以下步骤:
- 与RCNN一样,Selective Search 用于产生2K个region proposals(bounding boxes)
- 输入图像使用ZFNet(之前图表有说明)经过SPPNet仅仅一次
- 最后一层卷积得到整张特征映射,找到每个建议框对应的映射区域,输入SPP layer 得到固定长度的特征向量,然后再输入FC layer。
注意:SPP从feature map中提取对应候选bounding box的特征,而RCNN直接从图像中提取。
SPPNet for Object Detection
在每一个建议框对应的映射区域被spp处理之后、输入到FC层,接着SVM和Bounding Box回归也被添加,因此这不是一个end to end 的结构。
检测算法
作者使用选择性搜索的“快速”模式来为每幅图像生成大约2,000个候选窗口。然后,调整图像大小使min(w,h)=s,并从整个图像中提取特征映射。使用ZF-5(单尺寸训练)的SPP模型。在每个候选窗口中,使用一个4级空间金字塔(1×1,2×2,3×3,6×6,共50个box)来汇集特征。这将为每个窗口生成12,800d(256×50)的固定长度表征。这些表征输入到全连接层。然后,与R-CNN一样,针对这些特征为每个类别训练一个二进制线性支持向量机分类器。我们使用地面实况窗口来生成正样本。负样本是那些与正窗口重叠最多30%的样本(由(IOU)比率测量)。如果任何负样本与另一个负样本重叠超过70%,则删除该负样本。应用标准的硬负样本挖掘来训练SVM。此步骤迭代一次,训练所有20个类别的支持向量机只需不到1个小时。在测试中,使用分类器对候选窗口进行评分。然后,对评分窗口使用NMS。
Training the Network(参考2)

Single-size training
如前人的工作一样,我们首先考虑接收裁剪成224×224图像的网络。裁剪的目的是数据增强。对于一个给定尺寸的图像,我们先计算空间金字塔池化所需要的块(bins)的大小。试想一个尺寸是a x a(也就是13×13)的conv5之后特征图。对于n x n块的金字塔级,我们实现一个滑窗池化过程,窗口大小为win = 上取整[a/n],步幅str = 下取整[a/n]. 对于l层金字塔,我们实现l个这样的层。然后将l个层的输出进行连接,输出给全连接层。图4展示了一个cuda卷积网络风格的3层金字塔的样例。(3×3, 2×2, 1×1)。
Multi-size training
有SPP的网络可以应用于任意尺寸,为了在训练时解决不同图像尺寸的问题,我们考虑一些预设好的尺寸。现在考虑这两个尺寸:180×180,224×224。我们使用缩放(resize)而不是裁剪,将前述的224×224的区域图像变为180×180大小。这样,不同尺度的区域仅仅是分辨率上的不同,而不是内容和布局上的不同。 对于接受180×180输入的网络,我们实现另一个固定尺寸的网络。本例中,conv5输出的特征图尺寸是a x a=10×10。我们仍然使用win = 上取整[a/n],str = 下取整[a/n],实现每个金字塔池化层。这个180网络的空间金字塔层的输出的大小就和224网络的一样了。这样,这个180网络就和224网络拥有一样的参数了。换句话说,训练过程中,我们通过使用共享参数的两个固定尺寸的网络实现了不同输入尺寸的SPP-net。
为了降低从一个网络(比如224)向另一个网络(比如180)切换的开销,我们在每个网络上训练一个完整的epoch,然后在下一个完成的epoch再切换到另一个网络(权重保留)。依此往复。实验中我们发现多尺寸训练的收敛速度和单尺寸差不多。
多尺寸训练的主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸。 除了上述两个尺度的实现,我们也在每个epoch中测试了不同的s x s输入,s是从180到224之间均匀选取的。后面将在实验部分报告这些测试的结果。
注意,上面的单尺寸或多尺寸方法只用于训练阶段。在测试阶段,是直接对各种尺寸的图像应用SPP-net的。
reference
1.https://medium.com/coinmonks/review-sppnet-1st-runner-up-object-detection-2nd-runner-up-image-classification-in-ilsvrc-906da3753679
2.https://blog.csdn.net/weixin_43624538/article/details/87966601
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143882.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
