大家好,又见面了,我是你们的朋友全栈君。
最近在研究目标检测这个方向,看到网上有很多的人脸识别帖子,所以也想着上上手看看。当时是做了三个模型出来,第一个就是网上很通用普遍的opencv+简单三层cnn网络来实现的,说实话效果真的一般吧!具体的下面再细细陈述。第二个是把三层cnn网络换成了残差网络。因为自己刚好也是学习了残差网络。就想着生搬硬套过来,但效果说实话很迷,时好时坏,把我是整蒙逼了,后面也会提的。最后一个是用opencv+MTCNN+FaceNet来实现的,效果就比较好了,训练速度快,检测人脸的准确率也比前两个模型更好。我接下来会写三篇文章来一一介绍!
首先来说说第一个烂大街的模型,代码量很少,其实也很容易理解。但是我在网上找demo的时候真的是踩了不少的坑,不知道是作者故意而为之还是有些人本来就是copy其他人的,自己还偷懒没有跑,反正就是自己下载的几个demo跑的时候都报错,还是自己一行一行的看,改正了一些bug之后才跑出来的。说到这儿,我就想强调一句:我们互联网工作者应该有自己的工作原则嘛:对待项目代码应该一丝不苟,决不祸害别人!此处默默给自己厚颜无耻的点赞哈哈哈哈哈哈哈。我给大家分享的代码绝对是经得起推敲的,如若打脸,本人绝不接受(傲娇脸.jpg)开个玩笑哈,我会把一些常见bug给贴出来避免大家踩坑,当然如若大家还有bug,也可以积极留言,我看到了会给大家回复的嘿嘿。
我下面将会按照如下几点来写:
- 前期环境配置
- 人脸检测
- 训练模型
- 人脸识别
我会在每一小节里面把相应的知识点普及给大家。
1. 前期环境配置
之所以写这一小节,是因为自己真的是在这一小节踩了不少坑,让我很蛋疼,所以不想让大家也跟着遭殃。
- Python3.6 (虽然现在都到了3.7了,但我仍是觉得3.6是目前比较稳定的一个版本,2.7版本都要舍弃了,所以大家不要再使用这个版本了) Anaconda5.2
- opencv (如果使用pip安装,即:pip install opencv-python 这里面版本号没有限制)
- scipy1.2.1 (这个一定要注意呀,使用pip install scipy安装这个包的时候,一般都会安装1.3+的版本,在我这个程序里面就会报错了,因为我是使用了1.2版本里面的方法,在1.3版本里面该方法舍弃了)
- tensorflow1.9
- keras2.2.0
- sklearn
- USB摄像头一枚,这个是很关键啦!没有这个任你的技术再牛逼拍不到人脸也无济于事啊
配置大概是这些了,可能有的没写出来,可能就需要大家踩一些坑配置了(此处是不是要啪啪打脸了啊)
2. 人脸检测
由于本模型主要是使用opencv这个API完成人脸检测包括人脸识别的,有一句话叫:工欲善其事必先利其器,即要想使用opencv,就必须先知道其能干什么,怎么做。于是API的重要性便体现出来了。就本例而言,使用到的函数很少,也就普通的读取图片,灰度转换,显示图像,简单的编辑图像罢了。
1)读取图片
只需要给出待操作的图片的路径即可。
import cv2
image = cv2.imread(imagepath)2)灰度转换
灰度转换的作用就是:转换成灰度的图片的计算强度得以降低。因为现在的彩色图片都是三通道的数据,不做任何处理,数据量会很大,对于我们学生用的机子来说hold不住。
import cv2
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
灰色图片大概就是这样的。
3)画图
opencv 的强大之处的一个体现就是其可以对图片进行任意编辑,处理。
下面的这个函数最后一个参数指定的就是画笔的大小。其实就是要把检测到的人脸边框给描出来。
import cv2
cv2.rectangle(image,(x,y),(x+w,y+w),(0,255,0),2)大概如下图所示,大家请不要垂涎我的美色哈哈哈哈哈哈哈(狗头保命)

4)显示图像
编辑完的图像要么直接的被显示出来,要么就保存到物理的存储介质。
import cv2
cv2.imshow("Image Title",image)5)获取人脸识别训练数据
看似复杂,其实就是对于人脸特征的一些描述,这样opencv在读取完数据后很据训练中的样品数据,就可以感知读取到的图片上的特征,进而对图片进行人脸识别。
import cv2
face_cascade = cv2.CascadeClassifier(r'./haarcascade_frontalface_default.xml')里面的xml文件非常关键,可以说是这个模型的核心了,就是靠它才能获取到人脸数据的。它是opencv在GitHub上共享出来的具有普适的训练好的数据。我们可以直接的拿来使用。
训练数据参考地址:
https://github.com/opencv/opencv/tree/master/data/haarcascades
6)探测人脸
说白了,就是根据训练的数据来对新图片进行识别的过程。
import cv2
# 探测图片中的人脸
faces = face_cascade.detectMultiScale(
gray,
scaleFactor = 1.15,
minNeighbors = 5,
minSize = (5,5),
flags = cv2.cv.CV_HAAR_SCALE_IMAGE
)我们可以随意的指定里面参数的值,来达到不同精度下的识别。返回值就是opencv对图片的探测结果的体现。
处理人脸探测的结果
结束了刚才的人脸探测,我们就可以拿到返回值来做进一步的处理了。但这也不是说会多么的复杂,无非添加点特征值罢了。
import cv2
print "发现{0}个人脸!".format(len(faces))
for(x,y,w,h) in faces:
cv2.rectangle(image,(x,y),(x+w,y+w),(0,255,0),2)okay,以上就介绍完了一些必备函数,包括人脸检测的函数。那我们就是要来讲这个模型了,讲模型其实很好讲,首先获取训练数据,然后写好模型训练,最后检测效果即可。按照这个顺序来,我们先讲讲如何来收集人脸数据。
我们只要收集两个人的图片即可,考虑到大家的笔记本电脑配置,每个人只要收集200张图片即可。文件名记为get_face.py,代码如下:
def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):
cv2.namedWindow(window_name)
# 视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
cap = cv2.VideoCapture(camera_idx)
# 告诉OpenCV使用人脸识别分类器
data_path = "haarcascade_frontalface_default.xml"
classfier = cv2.CascadeClassifier(data_path)
# 识别出人脸后要画的边框的颜色,RGB格式
color = (0, 255, 0)
num = 0
while cap.isOpened():
ok, frame = cap.read() # 读取一帧数据
if not ok:
break
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 将当前桢图像转换成灰度图像
# 人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0: # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
# 将当前帧保存为图片
img_name = '%s/%d.jpg ' %(path_name, num)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image)
num += 1
if num > catch_pic_num: # 如果超过指定最大保存数量退出循环
break
# 画出矩形框
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
# 显示当前捕捉到了多少人脸图片了,这样站在那里被拍摄时心里有个数,不用两眼一抹黑傻等着
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame ,'num:%d' % (num) ,(x + 30, y + 30), font, 1, (255 ,0 ,255) ,4)
# 超过指定最大保存数量结束程序
if num > catch_pic_num:
break
# 显示图像
cv2.imshow(window_name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
那就是这块儿了,大家很清楚的看到,这个save_path文件夹里面保存的就是你拍的照片,因为你要保存两个人的照片,所以你到时候要跑两次这个程序,文件夹名称也要相应改变,收集两个人的照片。CatchPICFromVideo()函数里0, 199参数表示的是图片的序列号,即是0到199的200张图片。大致就是这样,程序跑起来的时候,大家记得不要动,乖乖的看向镜头保持微笑哈哈哈哈哈,大幅度的做一些夸张动作,拍出来的照片你会发现你死的心都有,这是来自一个过来人的忠心建议。
拍出来 照片大概就是这样,还有一点要注意:就是你的照片一定要连续,不要偷懒搞复制粘贴弄出来一大堆副本,比如900副本.jpg这种形式,顺序不连续程序会报错的。
3. 训练模型
数据拿到了,接下来就是要写模型训练了。本模型是采用了3个卷积操作+1个全连接操作实现的,关于卷积操作,这儿就默认你是和我一样精通卷积操作的大佬了啊哈哈哈哈哈哈哈哈。我这儿有一篇文章讲的还不错,不熟悉的推荐给大家看看:
https://www.zhihu.com/question/39022858
模型代码如下:
def build_model(self, dataset, nb_classes=2):
# 构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
self.model = Sequential()
# 以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
self.model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=dataset.input_shape)) # 1 2维卷积层
self.model.add(Activation('relu')) # 2 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 5 池化层
self.model.add(Dropout(0.25)) # 6 Dropout层
self.model.add(Convolution2D(64, 3, 3, border_mode='same')) # 7 2维卷积层
self.model.add(Activation('relu')) # 8 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 11 池化层
self.model.add(Dropout(0.25)) # 12 Dropout层
self.model.add(Flatten()) # 13 Flatten层
self.model.add(Dense(512)) # 14 Dense层,又被称作全连接层
self.model.add(Activation('relu')) # 15 激活函数层
self.model.add(Dropout(0.5)) # 16 Dropout层
self.model.add(Dense(nb_classes)) # 17 Dense层
self.model.add(Activation('softmax')) # 18 分类层,输出最终结果
# 输出模型概况
self.model.summary()因为是用keras写的,所以看起来比较简洁。
训练模型的函数也很简洁
sgd = SGD(lr=0.01, decay=1e-6,
momentum=0.9, nesterov=True) # 采用SGD+momentum的优化器进行训练,首先生成一个优化器对象
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy']) # 完成实际的模型配置工作这儿再说一点,我们知道如果要判别两个人是谁,训练的时候肯定是要给两个人的照片分类的,比如A标记为0,B标记为1。此模型也是如此来训练的,在load_face.py中的load_dataset()函数里有一行代码就是如此,代码如下:
# 标注数据,'ChengJianxin'文件夹下都是我的脸部图像,全部指定为0,另外一个文件夹下是同学的,全部指定为1
labels = np.array([0 if label.endswith('Chengjianxin') else 1 for label in labels])此文件的该处地方也是需要大家修改的,即把“Chengjianxin”改为自己文件夹的名称。
如果你要做多人识别的话,也是在这处地方做手脚的,我这儿就标记了0和1,所以大家很自然的知道我是做两人识别的,如果你要多识别一些人,就多做一些标记就行了。
最后还有一处地方需要修改,就是train.py文件的主函数部分:
# 此处文件地址是你收集的图片的文件夹地址
dataset = Dataset('D:\PyCharm-Community\Workplace\Face_Recognition\\face_data')
dataset.load()
model = Model()
model.build_model(dataset)
model.train(dataset)
# 此处地址是你保存训练好模型的地址
model.save_model(file_path='D:\PyCharm-Community\Workplace\Face_Recognition\\face_data\model\jianxin_face_model.h5')
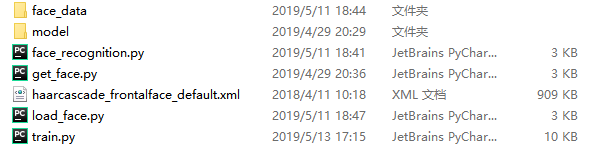
model.evaluate(dataset)有两处地址,大家一看便知。可能写到这,大家还不清楚我这个项目有几个Py文件,如下图所示:
4. 人脸识别
模型训练好了,最后就可以拿照片来测试了。
文件名叫:Face_recognition.py,代码如下:
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id\r\n" % (sys.argv[0]))
sys.exit(0)
# 加载模型
model = Model()
model.load_model(file_path='D:\PyCharm-Community\Workplace\Face_Recognition\model\jianxin_face_model.h5')
# 框住人脸的矩形边框颜色
color = (0, 255, 0)
# 捕获指定摄像头的实时视频流
cap = cv2.VideoCapture(0)
# 人脸识别分类器本地存储路径
cascade_path = "D:\opencv\\build\etc\haarcascades\haarcascade_frontalface_default.xml"
# 循环检测识别人脸
while True:
ret, frame = cap.read() # 读取一帧视频
if ret is True:
# 图像灰化,降低计算复杂度
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
else:
continue
# 使用人脸识别分类器,读入分类器
cascade = cv2.CascadeClassifier(cascade_path)
# 利用分类器识别出哪个区域为人脸
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
# 截取脸部图像提交给模型识别这是谁
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
faceID = model.face_predict(image)
print("faceID", faceID)
# 如果是“我”
if faceID == 0:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
# 文字提示是谁
cv2.putText(frame, 'Chengjianxin',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字号
(255, 0, 255), # 颜色
2) # 字的线宽
else:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
cv2.putText(frame, 'Nobody',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
2, # 字号
(255, 0, 0), # 颜色
2) # 字的线宽
pass
cv2.imshow("Face Recognition", frame)
# 等待10毫秒看是否有按键输入
k = cv2.waitKey(10)
# 如果输入q则退出循环
if k & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()其中有3处地方需要修改
# 加载模型
model = Model()
model.load_model(file_path='D:\PyCharm-Community\Workplace\Face_Recognition\model\jianxin_face_model.h5')模型地址改成你自己的。
# 人脸识别分类器本地存储路径
cascade_path = "D:\opencv\\build\etc\haarcascades\haarcascade_frontalface_default.xml"这个xml文件地址也改成你自己的,前面的get_face.py也是这样。
# 如果是“我”
if faceID == 0:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
# 文字提示是谁
cv2.putText(frame, 'Chengjianxin',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
1, # 字号
(255, 0, 255), # 颜色
2) # 字的线宽
else:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness=2)
cv2.putText(frame, 'Nobody',
(x + 30, y + 30), # 坐标
cv2.FONT_HERSHEY_SIMPLEX, # 字体
2, # 字号
(255, 0, 0), # 颜色
2) # 字的线宽这里面的文字提示改成你自己的就行了。
至于其运行原理,我就不讲了,我在代码里注释的很详细了。
运行结果如下:
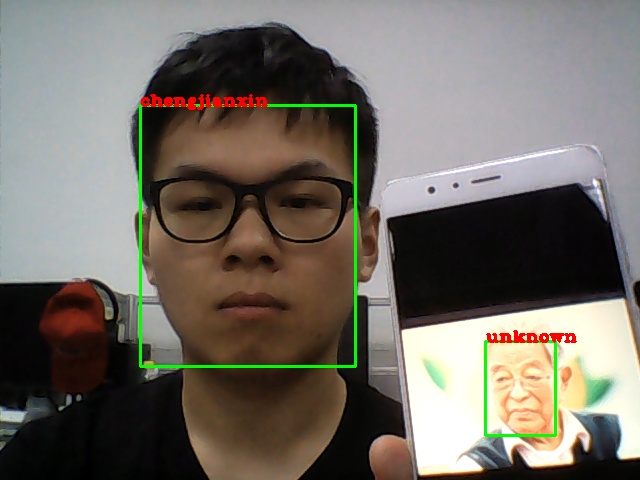
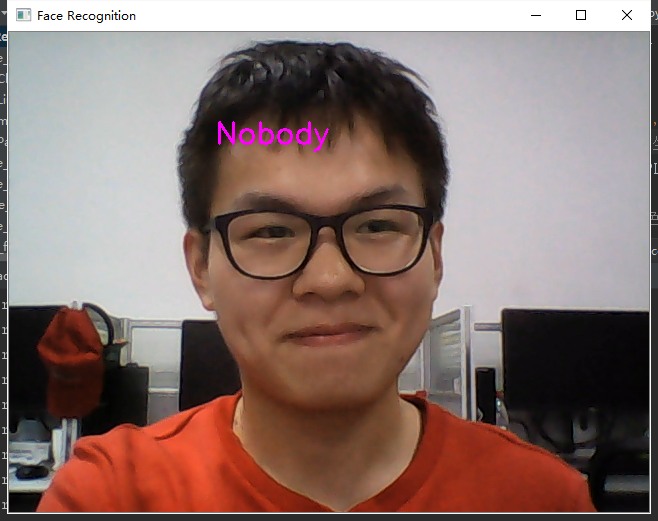
经验告诉大家:不要做夸张表情,请保持冷漠脸!!!
由于这个系列项目涉及到了一朋友的毕业设计,就不公开了,大家实在想要,直接私信我吧!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143736.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
