大家好,又见面了,我是你们的朋友全栈君。
根据Hadoop官网的相关介绍和实际使用中的软件集,将Hadoop生态圈的主要软件工具简单介绍下,拓展对整个Hadoop生态圈的了解。
这是Hadoop生态从Google的三篇论文开始的发展历程,现已经发展成为一个生态体系,并还在蓬勃发展中….

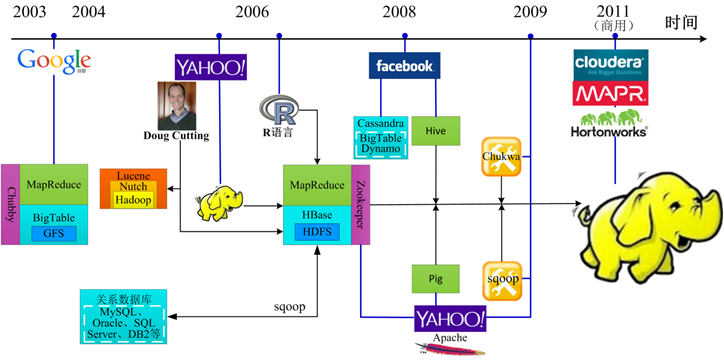
这是官网上的Hadoop生态图,包含了大部分常用到的Hadoop相关工具软件
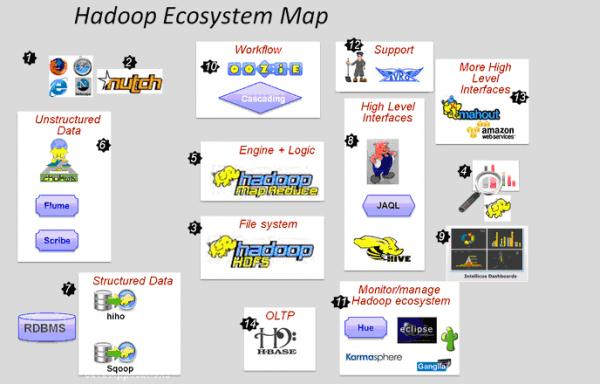
这是以体系从下到上的布局展示的Hadoop生态系统图,言明了各工具软件在体系中所处的位置
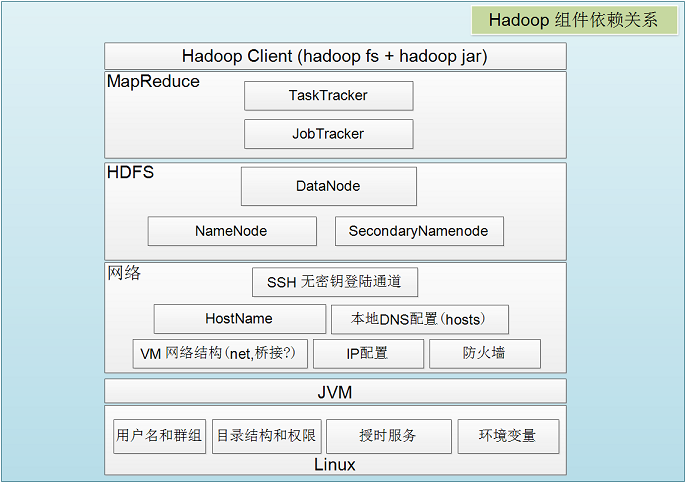
这张图是Hadoop在系统中核心组件与系统的依赖关系
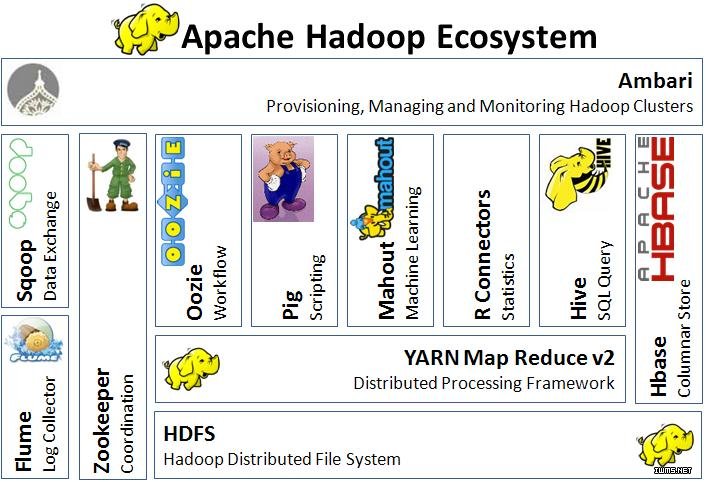
下面就是简单介绍Hadoop生态圈中的一些工具
官网原文:
What Is Apache Hadoop?
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
The project includes these modules:
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Other Hadoop-related projects at Apache include:
Ambari™: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly manner.
Avro™: A data serialization system.
Cassandra™: A scalable multi-master database with no single points of failure.
Chukwa™: A data collection system for managing large distributed systems.
HBase™: A scalable, distributed database that supports structured data storage for large tables.
Hive™: A data warehouse infrastructure that provides data summarization and ad hoc querying.
Mahout™: A Scalable machine learning and data mining library.
Pig™: A high-level data-flow language and execution framework for parallel computation.
Spark™: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation.
Tez™: A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. Tez is being adopted by Hive™, Pig™ and other frameworks in the Hadoop ecosystem, and also by other commercial software (e.g. ETL tools), to replace Hadoop™ MapReduce as the underlying execution engine.
ZooKeeper™: A high-performance coordination service for distributed applications.
译文:
什么是Apache hadoop?
Apache Hadoop项目是以可靠、可扩展和分布式计算为目的而发展而来的开源软件
Apache Hadoop 软件库是一个允许在集群计算机上使用简单的编程模型来进行大数据集的分布式任务的框架。它是设计来从单服务器扩展到成千台机器上,每个机器提供本地的计算和存储。相比于依赖硬件来实现高可用,该库自己设计来检查和管理应用部署的失败情况,因此是在集群计算机之上提供高可用的服务,没个节点都有可能失败。
该项目包括模块:
Hadoop Common :通用的工具来支持其他的Hadoop模块
Hadoop Distributed FileSystem(HDFS):一个提供高可用获取应用数据的分布式文件系统
Hadoop YARN;Job调度和集群资源管理的框架
Hadoop MapReduce:基于YARN系统的并行处理大数据集的编程模型
其他Hadoop相关的项目:
Ambari:一个基于web的工具,用来供应、管理和监测Apache Hadoop集群包括支持Hadoop HDFS、Hadoop MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop。Ambari 也提供一个可视的仪表盘来查看集群的健康状态(比如热图),并且能够以一种用户友好的方式根据其特点可视化的查看MapReduce、pig和Hive 应用来诊断其性能特征。
Avro :数据序列化系统。
Cassandra :可扩展的多主节点数据库,而且没有单节点失败情况。
Chukwa : 管理大型分布式系统的数据收集系统
HBase ; 一个可扩展的分布式数据库,支持大表的结构化数据存储
Hive : 一个提供数据概述和AD组织查询的数据仓库
Mahout :可扩展大的机器学习和数据挖掘库
Pig :一个支持并行计算的高级的数据流语言和执行框架
Spark : 一个快速通用的Hadoop数据的计算引擎。spark 提供一个简单和富有表现力的编程模型并支持多领域应用,包括ETL、机器学习、流处理 和图计算。
Tez : 一个通用的数据流处理框架,构建在Hadoop YARN上,提供一个有力的灵活的引擎来执行一个任意的DAG任务来处理数据(批处理和交互式两种方式)。Tez 可以被Hive、Pig和其他Hadoop生态系统框架和其他商业软件(如:ETL工具)使用,用来替代Hadoop MapReduce 作为底层的执行引擎。
ZooKeeper :一个应用于分布式应用的高性能的协调服务。
/****************************************************************************/
Ambari监控页面:
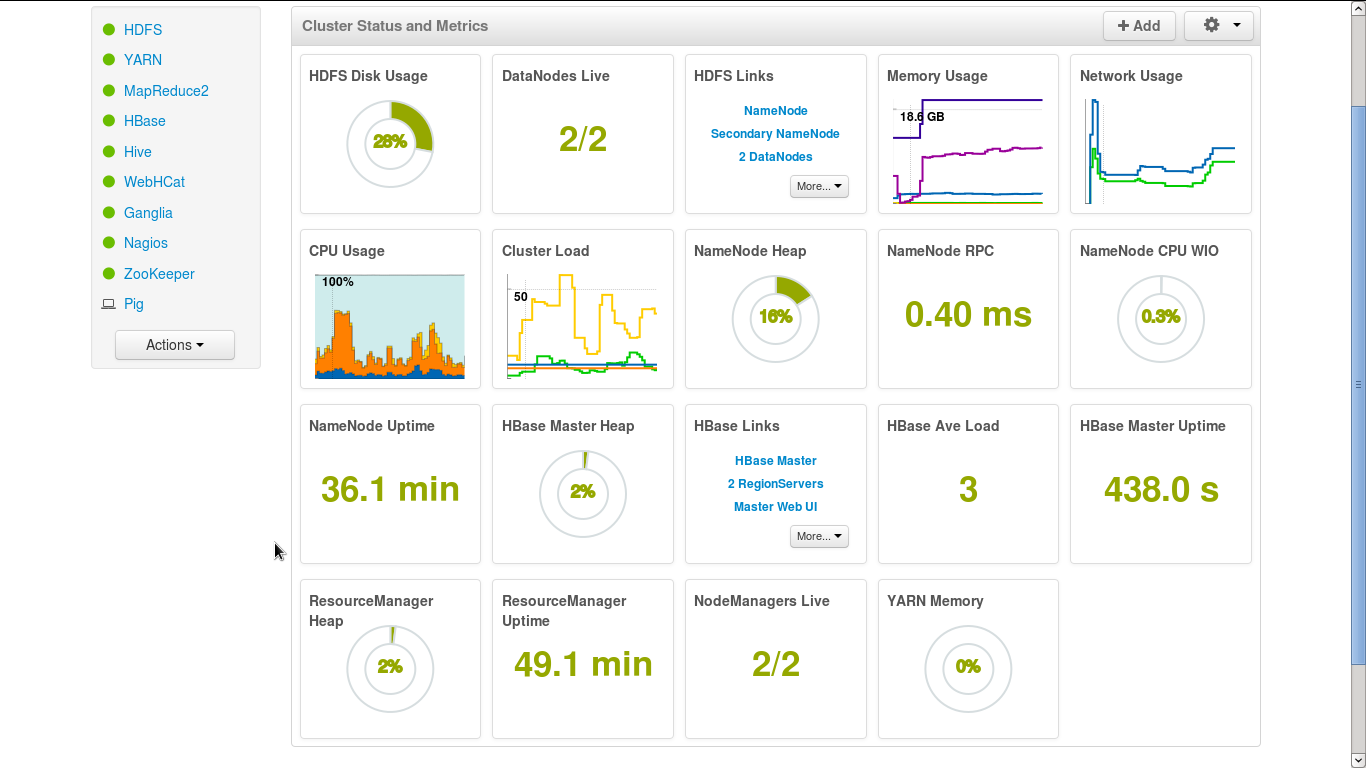
官网原文:
The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs.
Ambari enables System Administrators to:
Provision a Hadoop Cluster
Ambari provides a step-by-step wizard for installing Hadoop services across any number of hosts.
Ambari handles configuration of Hadoop services for the cluster.
Manage a Hadoop Cluster
Ambari provides central management for starting, stopping, and reconfiguring Hadoop services across the entire cluster.
Monitor a Hadoop Cluster
Ambari provides a dashboard for monitoring health and status of the Hadoop cluster.
Ambari leverages Ambari Metrics System for metrics collection.
Ambari leverages Ambari Alert Framework for system alerting and will notify you when your attention is needed (e.g., a node goes down, remaining disk space is low, etc).
Ambari enables Application Developers and System Integrators to:
Easily integrate Hadoop provisioning, management, and monitoring capabilities to their own applications with the Ambari REST APIs.
译文:Apache Ambari 项目的目标是通过开发提供、管理和监测Hadoop集群的软件使得hadoop的管理更简单。
Ambari 提供了直观的,易于使用的hadoop 管理的WEB 接口依赖于他自己的RESTful API。
Ambari 帮助系统管理员:
1.提供Hadoop集群
Ambari 提供一步步的向导来安装任意数量主机的hadoop 服务群。
Ambari 管理集群的Hadoop服务群的配置
2.管理Hadoop集群
Ambari 提供控制管理整个集群的启动、停止、和重新配置Hadoop服务群
3.监测Hadoop集群
Ambari 提供了仪表盘来监测Hadoop的健康和Hadoop集群的状态
Ambari利用Ambari度量系统来度量数据收集
Ambari利用Ambari警报框架为系统报警,当你需要注意时通知你(比如:一个节点挂掉、剩余磁盘不足等等).
Ambari 为应用开发人员和系统集成商提供了:
通过使用Ambari REST 的API很容易整合Hadoop提供、管理和监测的能力到他们自己的应用中
当前最新版本:The latest release Ambari 2.0.0
/****************************************************************************/
Avro 简介:
官网原文:
Apache Avro™ is a data serialization system.
Avro provides:
Rich data structures.
A compact, fast, binary data format.
A container file, to store persistent data.
Remote procedure call (RPC).
Simple integration with dynamic languages. Code generation is not required to read or write data files nor to use or implement RPC protocols. Code generation as an optional optimization, only worth implementing for statically typed languages.
译文:
Avro 是数据序列化系统
Avro 提供:
1.富数据结构。
2.紧凑、快速、二进制的数据格式化。
3.一个容器文件来存储持久化数据。
4.远程过程调用
5.简单的集成了动态语言,代码生成不再需要读写数据文件也不再使用或集成RPC协议。代码生成作为一个可选选项,仅仅值得静态语言实现
比较详细的介绍请点这里。
官方原文:
Schemas
Avro relies on schemas. When Avro data is read, the schema used when writing it is always present. This permits each datum to be written with no per-value overheads, making serialization both fast and small. This also facilitates use with dynamic, scripting languages, since data, together with its schema, is fully self-describing.
When Avro data is stored in a file, its schema is stored with it, so that files may be processed later by any program. If the program reading the data expects a different schema this can be easily resolved, since both schemas are present.
When Avro is used in RPC, the client and server exchange schemas in the connection handshake. (This can be optimized so that, for most calls, no schemas are actually transmitted.) Since both client and server both have the other’s full schema, correspondence between same named fields, missing fields, extra fields, etc. can all be easily resolved.
Avro schemas are defined with JSON . This facilitates implementation in languages that already have JSON libraries.
译文:模式
AVro 依赖模式。Avro数据的读写操作是很频繁的,而这些操作都需要使用模式。这样就减少写入每个数据资料的开销,使得序列化快速而又轻巧。这种数据及其模式的自我描述方便于动态脚本语言,脚本语言,以前数据和它的模式一起使用,是完全的自描述。
当Avro 数据被存储在一个文件中,它的模式也一同被存储。因此,文件可被任何程序处理,如果程序需要以不同的模式读取数据,这就很容易被解决,因为两模式都是已知的。
当在RPC中使用Avro时,客户端和服务端可以在握手连接时交换模式(这是可选的,因此大多数请求,都没有模式的事实上的发送)。因为客户端和服务端都有彼此全部的模式,因此相同命名字段、缺失字段和多余字段等信息之间通信中需要解决的一致性问题就可以容易解决
Avro模式用JSON定义,这有利于已经拥有JSON库的语言的实现
官方原文:
Comparison with other systems
Avro provides functionality similar to systems such as Thrift, Protocol Buffers, etc. Avro differs from these systems in the following fundamental aspects.
Dynamic typing: Avro does not require that code be generated. Data is always accompanied by a schema that permits full processing of that data without code generation, static datatypes, etc. This facilitates construction of generic data-processing systems and languages.
Untagged data: Since the schema is present when data is read, considerably less type information need be encoded with data, resulting in smaller serialization size.
No manually-assigned field IDs: When a schema changes, both the old and new schema are always present when processing data, so differences may be resolved symbolically, using field names.
Apache Avro, Avro, Apache, and the Avro and Apache logos are trademarks of The Apache Software Foundation.
译文:
和其他系统的比较
Avro提供着与诸如Thrift和Protocol Buffers等系统相似的功能,但是在一些基础方面还是有区别的
1 动态类型:Avro并不需要生成代码,模式和数据存放在一起,而模式使得整个数据的处理过程并不生成代码、静态数据类型等等。这方便了数据处理系统和语言的构造。
2 未标记的数据:由于读取数据的时候模式是已知的,那么需要和数据一起编码的类型信息就很少了,这样序列化的规模也就小了。
3 不需要用户指定字段号:即使模式改变,处理数据时新旧模式都是已知的,所以通过使用字段名称可以解决差异问题。
当前最新版本:23 July 2014: Avro 1.7.7 Released
/****************************************************************************/
官方原文:
Cassandra is a highly scalable, eventually consistent, distributed, structured key-value store. Cassandra brings together the distributed systems technologies from Dynamo and the data model from Google’s BigTable. Like Dynamo, Cassandra is eventually consistent. Like BigTable, Cassandra provides a ColumnFamily-based data model richer than typical key/value systems.

Cassandra was open sourced by Facebook in 2008, where it was designed by Avinash Lakshman (one of the authors of Amazon’s Dynamo) and Prashant Malik ( Facebook Engineer ). In a lot of ways you can think of Cassandra as Dynamo 2.0 or a marriage of Dynamo and BigTable. Cassandra is in production use at Facebook but is still under heavy development.
译文:
Cassandra是一个高可扩展的、最终一致、分布式、结构化的k-v仓库,Cassandra将BigTable的数据模型和Dynamo的分布式系统技术整合在一起。与Dynamo类似,Cassandra最终一致,与BigTable类似,Cassandra提供了基于列族的数据模型,比典型的k-v系统更丰富。
Cassandra 被FaceBook在2008年开源,被Avinash Lakshman(是Amazon的Dynamo的作者之一)和Prashant Malik(FaceBook的工程师)设计,在很多方面,你可以把Cassandra看作Dynamo 2.0,或者Dynamo和BigTable的结合。Cassandra已经应用在FaceBook的生产环境中,但它仍然处于密集开发期
当前最新版本:The latest release of Apache Cassandra is 2.1.4 (released on 2015-04-01)
/****************************************************************************/
Chukwa架构图:
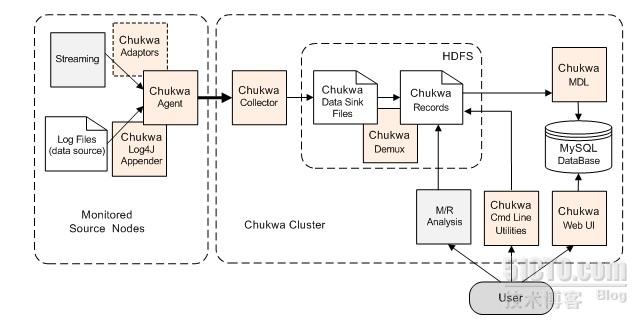
官方原文:
Chukwa is an open source data collection system for monitoring large distributed systems. Chukwa is built on top of the Hadoop Distributed File System (HDFS) and Map/Reduce framework and inherits Hadoop’s scalability and robustness. Chukwa also includes a flexible and powerful toolkit for displaying, monitoring and analyzing results to make the best use of the collected data.
译文:
Chukwa 是一个监测大型分布式系统的开源数据收集系统。Chukwa 建立在HDFS和MapReduce上,继承了Hadoop的可扩展性和鲁棒性。为了更好的使用收集的数据,Chukwa也包含了一个灵活有力的工具包用来显示、监测和分析结果。
当前最新版本:Last Published: 2015-03-24 | Version: 0.6.0
/****************************************************************************/
HBase的体系结构图
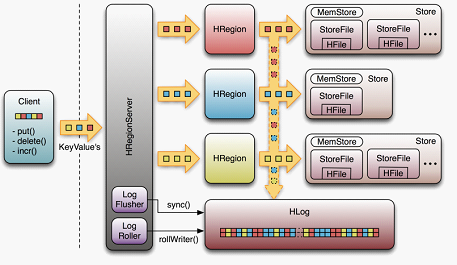
官方原文:
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
When Would I Use Apache HBase?
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables — billions of rows X millions of columns — atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google’s Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Features
Linear and modular scalability.
Strictly consistent reads and writes.
Automatic and configurable sharding of tables
Automatic failover support between RegionServers.
Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables.
Easy to use Java API for client access.
Block cache and Bloom Filters for real-time queries.
Query predicate push down via server side Filters
Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding options
Extensible jruby-based (JIRB) shell
Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
译文:Apache HBase是Hadoop 数据库,一个分布式,可扩展的大数据仓库
什么时候使用Apache HBase 呢?
当随机、实时读写你的大数据时就需要使用HBase。这个项目的目标是成为巨大的表(数十亿行 x 数百万列数据)的托管在商品硬件的集群上.
HBase是一个开源的,分布式,版本化,非关系的数据库,仿照自Google的BigTable(一个Chang et al开发的结构化数据的分布式存储系统),BigTable的分布式数据存储由GFS(Google File System)提供,HBase在Hadoop和HDFS上提供类似大表能力。
特点:
线性的和模块化的可扩展性。
严格一致的读和写。
自动和可配置的分区表。
方便的支持hadoop的MapReduce 的Jobs与HBase表的基类。
易于使用的JAVA API的客户端访问。
实时查询的块缓存和Bloom过滤器。
查询谓词下推通过服务器端过滤器。
Thrift网关和REST-ful的WEB服务,支持XML,ProtoBuf和二进制数据编码选项
可扩展的基于JRuby(JIRS)的shell
支持导出指标通过Hadoop的指标子系统到文件或神经节;或者通过JMX
当前最新版本:1.0.0
/****************************************************************************/
Hive:
hive原理图
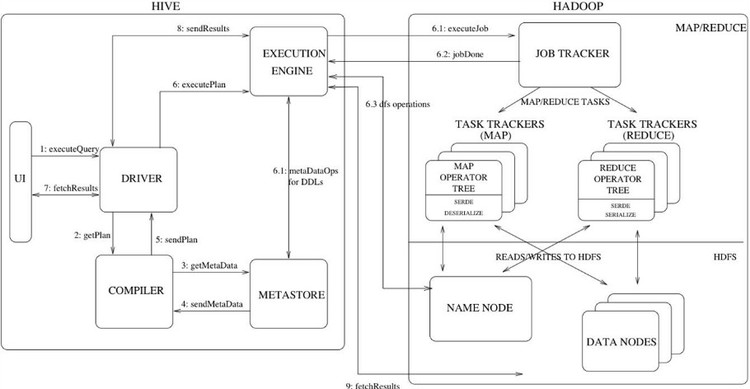
官方原文:
The Apache Hive ™ data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
译文:
Apache Hive数据仓库软件有利于查询和管理大数据集驻扎在分布式仓库上。Hive提供了机制保护数据上的结构并且查询数据使用的类似SQL的语言HiveQL。同时,当HiveQL表达这逻辑不方便或者效率低下时,这种语言也允许传统的MapReduce程序员添加他们自定义的mapper和reduce。
当前最新版本:8 March 2015: release 1.1.0 available
/****************************************************************************/
mahout算法适用场景

官方原文:
The Apache Mahout™ project’s goal is to build an environment for quickly creating scalable performant machine learning applications.
The three major components of Mahout are an environment for building scalable algorithms, many new Scala + Spark (H2O in progress) algorithms, and Mahout’s mature Hadoop MapReduce algorithms.
译文:
mahout 项目目标是构建一个快速创建可扩展高性能的机器学习应用的环境。
mahout的三个主要的组件是构建可扩展的算法环境,大量Scala+Spark算法和Mahout的成熟的MapReduce算法。
2015.4.11 0.10版本发布
Apache Mahout introduces a new math environment we call Samsara, for its theme of universal renewal. It reflects a fundamental rethinking of how scalable machine learning algorithms are built and customized. Mahout-Samsara is here to help people create their own math while providing some off-the-shelf algorithm implementations. At its core are general linear algebra and statistical operations along with the data structures to support them. You can use it as a library or customize it in Scala with Mahout-specific extensions that look something like R. Mahout-Samsara comes with an interactive shell that runs distributed operations on a Spark cluster. This make prototyping or task submission much easier and allows users to customize algorithms with a whole new degree of freedom.
Mahout Algorithms include many new implementations built for speed on Mahout-Samsara. They run on Spark and some on H2O, which means as much as a 10x speed increase. You’ll find robust matrix decomposition algorithms as well as a Naive Bayes classifier and collaborative filtering. The new spark-itemsimilarity enables the next generation of cooccurrence recommenders that can use entire user click streams and context in making recommendations.
译文:
Mahout 引进了一个新的数学环境叫做Samsara,它的主题是通用的重建。它反映了可扩展的机器学习算法怎样构架和自定义的根本性反思。在提供现成的算法实现的同时,Mahout-Samsara帮助人们创建他们自己的数学。它的核心是一般线性代数和统计的操作随着数据结构来支持它们。你可以使用它作为一个库或者用Scala自定义它,Mahout-specific扩展看起来有些像R语言。Mahout-Samsara到达伴随一个互动的shell(在Spark集群上运行分布式操作)。这让原型机制造或者任务提交更容易并且允许用户在一个完整的心得自由度中自定义算法。
mahout算法包括许多新实现构建专为Mahout-Samsara。他们运行在spark上和一些H2O上,这意味着将会提速10倍以上,你将发现强大的矩阵分解算法和朴素贝叶斯分类器和协同过滤一样好。新的spark-itemsimilarity(spark的基于物品的相似)成为下一代共生的推荐可以使用整个用户点击流和上下文来进行推荐。
当前最新版本:0.10.0 released
/****************************************************************************/
Pig:
官方原文:
Apache Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets.
At the present time, Pig’s infrastructure layer consists of a compiler that produces sequences of Map-Reduce programs, for which large-scale parallel implementations already exist (e.g., the Hadoop subproject). Pig’s language layer currently consists of a textual language called Pig Latin, which has the following key properties:
Ease of programming. It is trivial to achieve parallel execution of simple, “embarrassingly parallel” data analysis tasks. Complex tasks comprised of multiple interrelated data transformations are explicitly encoded as data flow sequences, making them easy to write, understand, and maintain.
Optimization opportunities. The way in which tasks are encoded permits the system to optimize their execution automatically, allowing the user to focus on semantics rather than efficiency.
Extensibility. Users can create their own functions to do special-purpose processing.
译文:
Pig是由用于表达数据分析程序的高级语言来分析大数据集的平台,与基础平台耦合来评估这些程序。Pig程序的突出属性是他们的结构适合大量的并行化,这将使他们能够处理非常大的数据集。
当前,Pig的底层实现是由编译器产生序列的MapReduce程序,大量可扩展并行实现已经存在。Pig语言层当前由文本语言叫Pig Latin组成。Pig Litin拥有如下属性:
简易编程:实现简单的,难以并行的数据分析任务来并行执行是很平常的事。有多个相互关联的数据转换的复杂的任务是显示编码为数据流序列,使其易于写,理解和保持。
优化条件:这种方法(任务被编码为允许系统自动优化它们的执行)允许用户专注于语义更甚于效率。
可扩展性:用户可以创造谈们自己的方法来做特殊目的的处理。
当前最新版本是Apache Pig 0.14.0 包括 Pig on Tez, OrcStorage
/****************************************************************************/
官方原文:
Apache Spark™ is a fast and general engine for large-scale data processing.
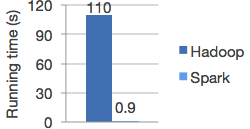
Speed:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.Spark has an advanced DAG execution engine that supports cyclic data flow and in-memory computing
Ease of Use:Write applications quickly in Java, Scala or Python.Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala and Python shells.
Generality:Combine SQL, streaming, and complex analytics.Spark powers a stack of high-level tools including Spark SQL, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Runs Everywhere:Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, S3.You can run Spark readily using its standalone cluster mode, on EC2, or run it on Hadoop YARN or Apache Mesos. It can read from HDFS, HBase, Cassandra, and any Hadoop data source.
译文:
Spark是一个快速,一般性的进行大量可扩展数据的引擎。
速度:在内存中运行程序是Hadoop的100倍以上,或者在磁盘上的10倍以上。spark还有高级的有向无环图(DAG)执行引擎支持循环数据流和内存计算。
易于使用:可以凯苏的使用java、scala或者python编写程序。spark提供超过80个高水准的操作者使得很容易构建并行APP。并且你可以从scala和python的shell交互式使用它。
通用性:结合SQL,流和复杂的分析。spark 供给了高水平的栈工具包括Spark SQL,机器学习的MLlib,GraphX和Spark Streaming。你可以在同一个应用中无缝结合这些库。
到处运行:spark运行在Hadoop、Mesos、独立运行或者运行在云上,他可以获得多样化的数据源包括HDFS、Cassandra、HBase、S3。你可以容易的运行Spark使用它的独立集群模式,在EC2上,或者运行在Hadoop的YARN或者Apache的Mesos上。它可以从HDFS,HBase,Cassandra和任何Hadoop数据源。
快速
通用性
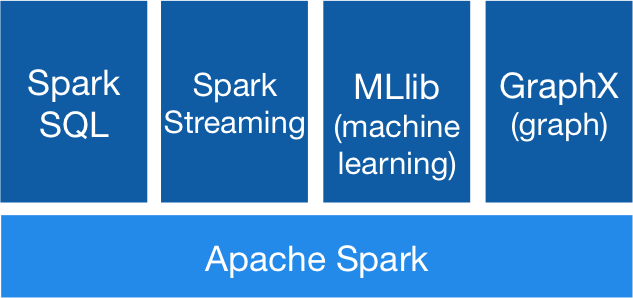
可到处运行

易于编程

当前最新版本是Spark 1.2.2 and 1.3.1 released
/****************************************************************************/
Tez:
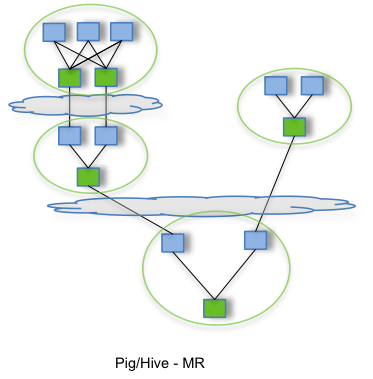
上图展示的流程包含多个MR任务,每个任务都将中间结果存储到HDFS上——前一个步骤中的reducer为下一个步骤中的mapper提供数据。
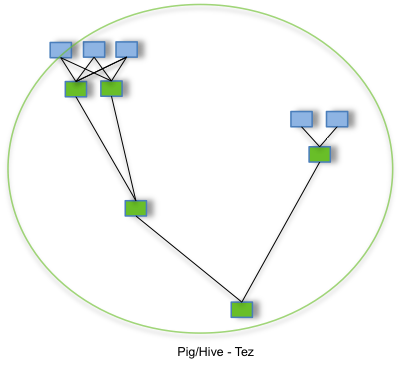
该图表展示了使用Tez时的流程,仅在一个任务中就能完成同样的处理过程,任务之间不需要访问HDFS
官方原文:
The Apache Tez project is aimed at building an application framework which allows for a complex directed-acyclic-graph of tasks for processing data. It is currently built atop Apache Hadoop YARN
The 2 main design themes for Tez are:
Empowering end users by:
Expressive dataflow definition APIs
Flexible Input-Processor-Output runtime model
Data type agnostic
Simplifying deployment
Execution Performance
Performance gains over Map Reduce
Optimal resource management
Plan reconfiguration at runtime
Dynamic physical data flow decisions
By allowing projects like Apache Hive and Apache Pig to run a complex DAG of tasks, Tez can be used to process data, that earlier took multiple MR jobs, now in a single Tez job as shown below.
译文:
Tez 项目目标是构建一个应用框架允许为复杂的有向无环图任务处理数据,当前构建在YARN上。
Tez的两个主要的设计主题是:
授权用户:
表达数据流定义的API
灵巧的输入输出处理器运行时模式
数据类型无关
简化部署
执行性能
提升MapReduce性能
最优化资源管理
运行时重置配置计划
动态逻辑数据流决议
通过允许项目向Hive和Pig来运行复杂的DAG认为,Tez可以被用于处理数据更简单处理多MapReduce Jobs,现在展示一个单一的Tez Job
Tez API包括以下几个组件:
- 有向无环图(DAG)——定义整体任务。一个DAG对象对应一个任务。
- 节点(Vertex)——定义用户逻辑以及执行用户逻辑所需的资源和环境。一个节点对应任务中的一个步骤。
- 边(Edge)——定义生产者和消费者节点之间的连接。
边需要分配属性,对Tez而言这些属性是必须的,有了它们才能在运行时将逻辑图展开为能够在集群上并行执行的物理任务集合。下面是一些这样的属性:
- 数据移动属性,定义了数据如何从一个生产者移动到一个消费者。
- 调度(Scheduling)属性(顺序或者并行),帮助我们定义生产者和消费者任务之间应该在什么时候进行调度。
- 数据源属性(持久的,可靠的或者暂时的),定义任务输出内容的生命周期或者持久性,让我们能够决定何时终止。
当前最新版本:Apache Tez 0.6.0
/****************************************************************************/
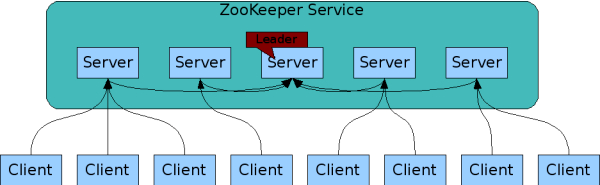
官方原文:
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
What is ZooKeeper?
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them ,which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
译文:
ZooKeeper是一个尝试来开发和保持一个开源的来提供高可靠的分布式协调的服务。
什么是ZooKeeper?
ZooKeeper 是一个集中服务,保持配置信息,命名和提供分布式同步并且提供组服务。所有这些种服务被分布式应用用于某些形式或其他。每次它们实现这大量的工作修复Bug并比赛的情况是不可避免的。由于这些种服务的实现不同,应用最初通常吝啬它们,使得它们忍受在变化的存在和难以管理。甚至在正确时,当应用部署时,不同的实现导致管理负责。
当前最新版本:10 March, 2014: release 3.4.6 available
/****************************************************************************/
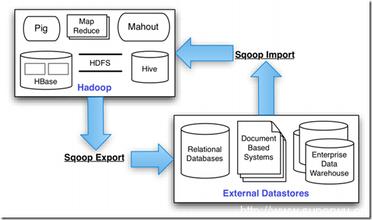
sqoop工作流程:
官方原文:
Apache Sqoop
Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
Sqoop successfully graduated from the Incubator in March of 2012 and is now a Top-Level Apache project: More information
Latest stable release is 1.4.5 (download, documentation). Latest cut of Sqoop2 is 1.99.5 (download, documentation). Note that 1.99.5 is not compatible with 1.4.5 and not feature complete, it is not intended for production deployment.
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
/****************************************************************************/
flume:
flume工作流程:
官方原文:
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
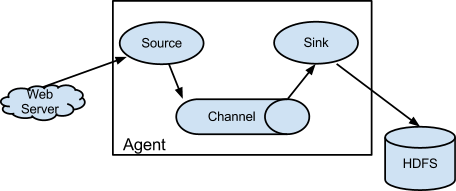
译文:Flume是一个分布式、可靠的、高可用的有效收集、聚合和转移大量日志文件的服务。它拥有简单灵活的基于数据流的体系结构。它是鲁棒性的,拥有容错可调的可靠性机制、故障转移和恢复机制。使用简单可扩展的可以在线分析应用的数据模型
日志收集
Flume最早是Cloudera提供的日志收集系统,目前是Apache下的一个孵化项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
数据处理
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
当前最新版本:November 18, 2014 – Apache Flume 1.5.2 Released
/****************************************************************************/
Impala
Impala的原理图
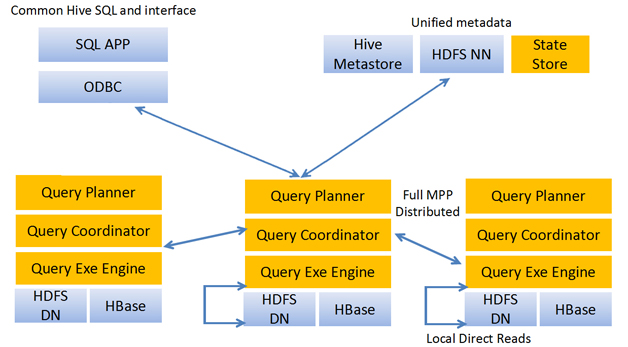
Impala架构分析
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。那么Impala如何实现大数据的快速查询呢?在回答这个问题前,需要先介绍Google的Dremel系统,因为Impala最开始是参照 Dremel系统进行设计的。
Dremel是Google的交互式数据分析系统,它构建于Google的GFS(Google File System)等系统之上,支撑了Google的数据分析服务BigQuery等诸多服务。Dremel的技术亮点主要有两个:一是实现了嵌套型数据的列存储;二是使用了多层查询树,使得任务可以在数千个节点上并行执行和聚合结果。列存储在关系型数据库中并不陌生,它可以减少查询时处理的数据量,有效提升 查询效率。Dremel的列存储的不同之处在于它针对的并不是传统的关系数据,而是嵌套结构的数据。Dremel可以将一条条的嵌套结构的记录转换成列存储形式,查询时根据查询条件读取需要的列,然后进行条件过滤,输出时再将列组装成嵌套结构的记录输出,记录的正向和反向转换都通过高效的状态机实现。另 外,Dremel的多层查询树则借鉴了分布式搜索引擎的设计,查询树的根节点负责接收查询,并将查询分发到下一层节点,底层节点负责具体的数据读取和查询执行,然后将结果返回上层节点。
在Cloudera的测试中,Impala的查询效率比Hive有数量级的提升。从技术角度上来看,Impala之所以能有好的性能,主要有以下几方面的原因。
-
- Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
- 省掉了MapReduce作业启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多。
- Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
- 通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销。
- 用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
- 使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
翻译自Apache官网上的文档,因英语水平和专业水平有限,翻译不当之处还希望交流指教。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143487.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
