大家好,又见面了,我是你们的朋友全栈君。
Broad Learning System (BLS,宽度学习系统)是澳门大学的陈俊龙教授在2017年TNNLS上基于随机向量函数链接神经网络(RVFLNN)和单层前馈神经网络(SLFN)提出的一种单层增量式神经网络。这个模型相比于传统的深层网络模型,它在保证一定精度的同时,具有快速、简洁,同时支持增量式的在线模型更新等比较好的性质。我在复现以后发现模型在一些数据集上的表现确实是不错的,在与陈教授做了关于一些模型细节讨论后,打算开这篇博客按照论文里的内容系统的介绍一下这个模型。在博客的最后会附上我写的 BLS模型 python 代码链接还有论文里公布的matlab代码链接,感兴趣的可以试一试效果
目录
一、BLS简介 与 随机向量函数链接神经网络
深层结构神经网络在许多领域得到应用,并在大规模数据处理上取得了突破性的成功。目前,最受欢迎的深度网络是深度信任网络(Deep Belief Networks,DBN),深度玻尔兹曼机器(Deep Boltzmann Machines,DBM)和卷积神经网络(Convolutional neural Networks,CNN)等。虽然深度结构网络非常强大,但大多数网络都被极度耗时的训练过程所困扰。其中最主要的原因是,上述深度网络都结构复杂并且涉及到大量的超参数,这种复杂性使得在理论上分析深层结构变得极其困难。另一方面,为了在应用中获得更高的精度,深度模型不得不持续地增加网络层数或者调整参数个数。
宽度学习系统提供了一种深度学习网络的替代方法,同时,如果网络需要扩展,BLS模型可以通过增量学习高效重建,避免了大规模耗时的网络训练。BLS从模型上来看,可以看做是随机向量函数链接神经网络的一个变种和推演算法。我们先来看看 RVFLNN模型

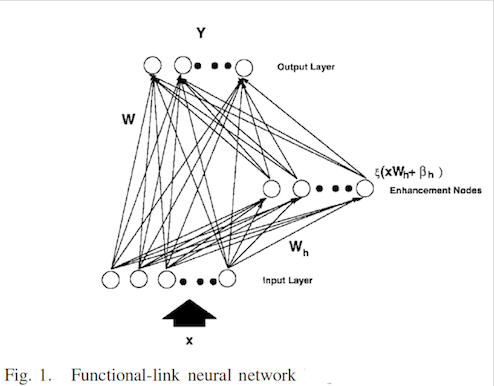
RVFLNN模型是 Yoh-Han Pao教授在1992年提出来的一个浅层网络模型,其基本思路就是将原始的输入数据做一个简单的映射之后,作为另一组输入,与原先的输入数据一起作为输入训练得到输出。BLS利用的也是这种浅层模型,将其变化成如下形式
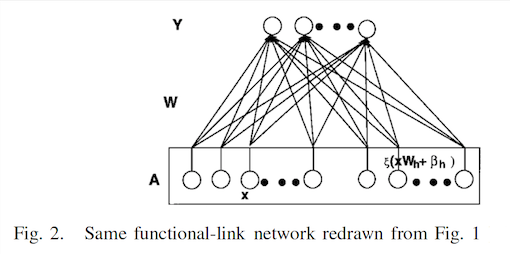
BLS的基本结构就类似于Fig. 2 ,我们看出BLS为了保证训练速度,设计成了一个单层的网络,直接由输入层经过一个 W W W 矩阵映射到了输出层。当然BLS还用到了很多其他的概念,比如动态逐步更新算法、岭回归的伪逆求解、稀疏自编吗以及SVD分解等。这一章节我们先简单认识了一下BLS的网络结构,接下来我会逐个介绍上面BLS用到的上面几种方法,再介绍BLS的基本模型和增量模型。
##二、相关方法
1.1 岭回归的伪逆算法
伪逆是BLS用于求解网络权重 W W W 的方法,伪逆的岭回归求解模型形式如下
a r g m i n W : ∣ ∣ A W − Y ∣ ∣ v σ 1 + λ ∣ ∣ W ∣ ∣ u σ 2 arg min_{W}: ||AW-Y||^{\sigma_{1}}_{v}+\lambda ||W||^{\sigma_{2}}_{u} argminW:∣∣AW−Y∣∣vσ1+λ∣∣W∣∣uσ2
这里的 u , v u,v u,v 表示的是一种范数正则化,当 σ 1 = σ 2 = u = v = 2 \sigma_{1} = \sigma_{2} = u =v =2 σ1=σ2=u=v=2 时,上式其实就是一个岭回归模型。BLS的网络参数 W W W 就是根据上式求解出来的。我们可以从岭回归得到下式
W = ( λ I + A A T ) − 1 A T Y W = (\lambda I+AA^{T})^{-1}A^{T}Y W=(λI+AAT)−1ATY
一个矩阵的二范数伪逆如下
A + = l i m λ − > 0 ( λ I + A A T ) − 1 A T A^{+} = lim_{\lambda -> 0}(\lambda I+AA^{T})^{-1}A^{T} A+=limλ−>0(λI+AAT)−1AT
这个公式就是我们后续需要用到的伪逆求解方法
1.2 函数链接神经网络的动态逐步更新算法
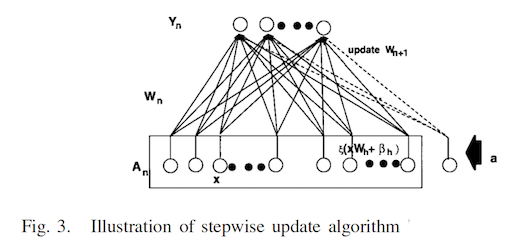
动态逐步更新算法是一种用于函数链接神经网络增量更新网络权重的算法,BLS的网络更新主要用到的也是这一方法。我们先将Fig. 2中的 A A A 矩阵表示为 [ X ∣ ξ ( X W h + β h ) ] [X|\xi(XW_{h}+\beta_{h}) ] [X∣ξ(XWh+βh)] ,这里 A A A 是经过扩展后的输入矩阵。 A n A_{n} An 表示一个 n x m nxm nxm 的矩阵,则当新的节点增加如下图
我们用 A n + 1 = [ A n ∣ a ] A_{n+1}=[A_{n}|a] An+1=[An∣a] 表示上述输入矩阵, A n + 1 A_{n+1} An+1 的伪逆可以计算如下
[ A n + − d b T b T ] \begin{bmatrix}A^{+}_{n}-db^{T}\\ b^{T}\end{bmatrix} [An+−dbTbT]
这里 d = A n + a d = A^{+}_{n}a d=An+a
b T = [ ( c ) + i f c ≠ 0 ( 1 + d T d ) − 1 d T A n + i f c = 0 ] b^{T}=\begin{bmatrix}(c)^{+} & if c\neq 0 \\ (1+d^{T}d)^{-1}d^{T}A^{+}_{n} & if c = 0\end{bmatrix} bT=[(c)+(1+dTd)−1dTAn+ifc=0ifc=0]
c = a − A n d c = a-A_{n}d c=a−And
新的权重 W W W 更新如下
W n + 1 = [ W n − d b T Y n b T Y n ] W_{n+1}=\begin{bmatrix}W_{n}-db^{T}Y_{n}\\ b^{T}Y_{n}\end{bmatrix} Wn+1=[Wn−dbTYnbTYn]
1.3 稀疏自编码与SVD分解
除了上面两种方法,BLS里面还会用到稀疏自编码和SVD分解,这两个方法是大家熟知和广泛运用的,在BLS中稀疏自编码主要用于产生映射节点和特征节点时的权重更新,SVD用于网络模型的结构简化。这两部分对于BLS模型来说不是必须的,在与陈教授的交流中他提到使用稀疏自编码会使结果好一些,但我个人认为稀疏自编码的训练会使得BLS的训练速度下降,所以我在后面的python代码中并没有使用这一方法。SVD分解在BLS的中实际上是PCA方法应用,去除了一些无用的纬度信息。我有一篇博客专门介绍了SVD之类的矩阵分解方法,想要了解的话可以去看一下,在这里就不再赘述了
二、Broad Learning System
2.1 Broad Learning Model
我们不考虑增量,首先来了解一下BLS的基本模型。BLS的输入矩阵 A A A 是由两部分组成的:映射节点(mapped feature)和增强节点(enhenced feature),对于映射节点我们记为 Z Z Z,它由原数据矩阵经过线性映射和激活函数变换得到
这里的 W , β W,\beta W,β 矩阵都是随机产生的,我们可以将 n n n 次映射变化得到的映射节点记为 Z n = [ Z 1 , Z 2 , . . . , Z n ] Z^{n}=[Z_{1},Z_{2},…,Z_{n}] Zn=[Z1,Z2,...,Zn]。同样的,增强节点是由映射节点经过线性映射和激活函数变换得到的
因此,宽度学习的模型可以表示为如下线性形式
下图展示了BLS的两种形式,在论文中,陈教授证明了这两种形式本质上是相同的,之后的讲解都会以第一种形式为例进行讲解
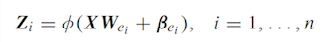
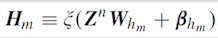
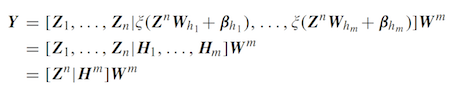

2.2 BLS的增量形式:增强节点的增加
对于一些情况,BLS直接训练后可能无法达到理想的性能,这时候就可以考虑增加增加节点的个数,比如,我们增加 p p p 个增强节点 ,分别记 A m = [ Z n ∣ H m ] A^{m}= [Z^{n}|H^{m}] Am=[Zn∣Hm] 和 A m + 1 = [ A m ∣ ξ ( Z n W h m + 1 + β h m + 1 ) ] A^{m+1}=[A^{m}|\xi (Z^{n}W_{h_{m+1}}+\beta_{h_{m+1}})] Am+1=[Am∣ξ(ZnWhm+1+βhm+1)],根据我们之前提到的动态逐步更新算法,我们可以有
( A m + 1 ) + = [ ( A m ) + − D B T B T ] (A^{m+1})^{+}=\begin{bmatrix}(A^{m})^{+}-DB^{T}\\ B^{T}\end{bmatrix} (Am+1)+=[(Am)+−DBTBT]
这里 D = ( A m ) + ξ ( Z n W h m + 1 + β h m + 1 ) D = (A^{m})^{+}\xi(Z^{n}W_{h_{m+1}}+\beta_{h_{m+1}}) D=(Am)+ξ(ZnWhm+1+βhm+1)
B T = [ ( C ) + i f C ≠ 0 ( 1 + D T D ) − 1 D T A n + i f C = 0 ] B^{T}=\begin{bmatrix}(C)^{+} & if C\neq 0 \\ (1+D^{T}D)^{-1}D^{T}A^{+}_{n} & if C = 0\end{bmatrix} BT=[(C)+(1+DTD)−1DTAn+ifC=0ifC=0]
C = ξ ( Z n W h m + 1 + β h m + 1 ) − A m D C = \xi (Z^{n}W_{h_{m+1}}+\beta_{h_{m+1}})-A^{m}D C=ξ(ZnWhm+1+βhm+1)−AmD
新的权重 W W W 更新如下
W n + 1 = [ W n − D B T Y n B T Y n ] W^{n+1}=\begin{bmatrix}W^{n}-DB^{T}Y_{n}\\ B^{T}Y_{n}\end{bmatrix} Wn+1=[Wn−DBTYnBTYn]
根据上述 W W W 矩阵的更新迭代公式,我们可以得到BLS的增强节点增量算法

2.3 BLS的增量形式:映射节点的增加
映射节点的增加相比于增强节点的增加要略显复杂一点,首先我们记增加的映射节点为 Z n + 1 = ∅ ( X W e n + 1 + β e n + 1 ) Z_{n+1} = \varnothing(XW_{e_{n+1}}+\beta_{e_{n+1}}) Zn+1=∅(XWen+1+βen+1), 对应增加的增强节点不再使用之前的 W W W, 而是重新生成
这里的 H e x m H_{ex_{m}} Hexm是作为额外的节点增加到网络当中的,更新公式与上一小节的公式是相同的,这里不再重复,BLS的映射节点增量算法

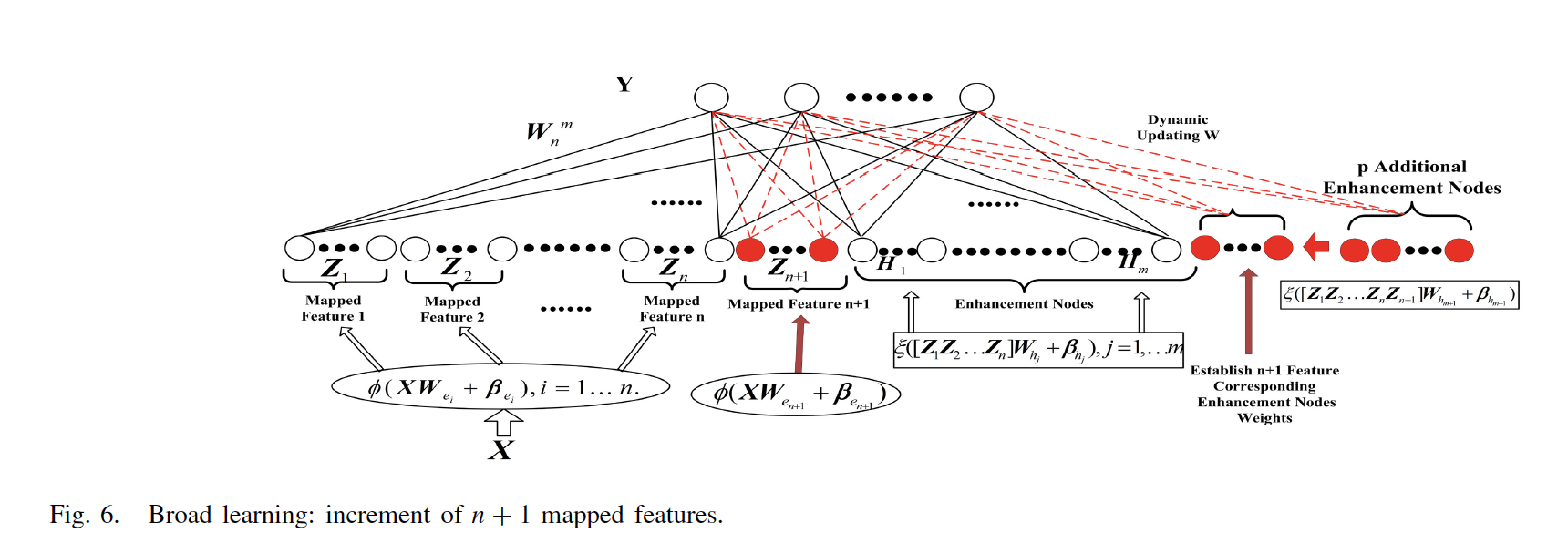

2.4 BLS的增量形式:输入数据的增加
输入数据的增加是BLS最重要的增量形式,我们记新增加的样本为 X a X_{a} Xa , A n m A^{m}_{n} Anm 表示 n n n 组映射节点 m m m 组增强节点的初始输入矩阵,那么对应于增加的数据的输入矩阵可以表示为
上式中的参数用的是初始网络中产生的参数,因此,我们可以将更新后的输入矩阵表示为
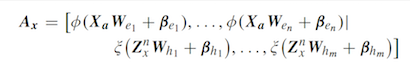
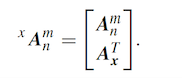
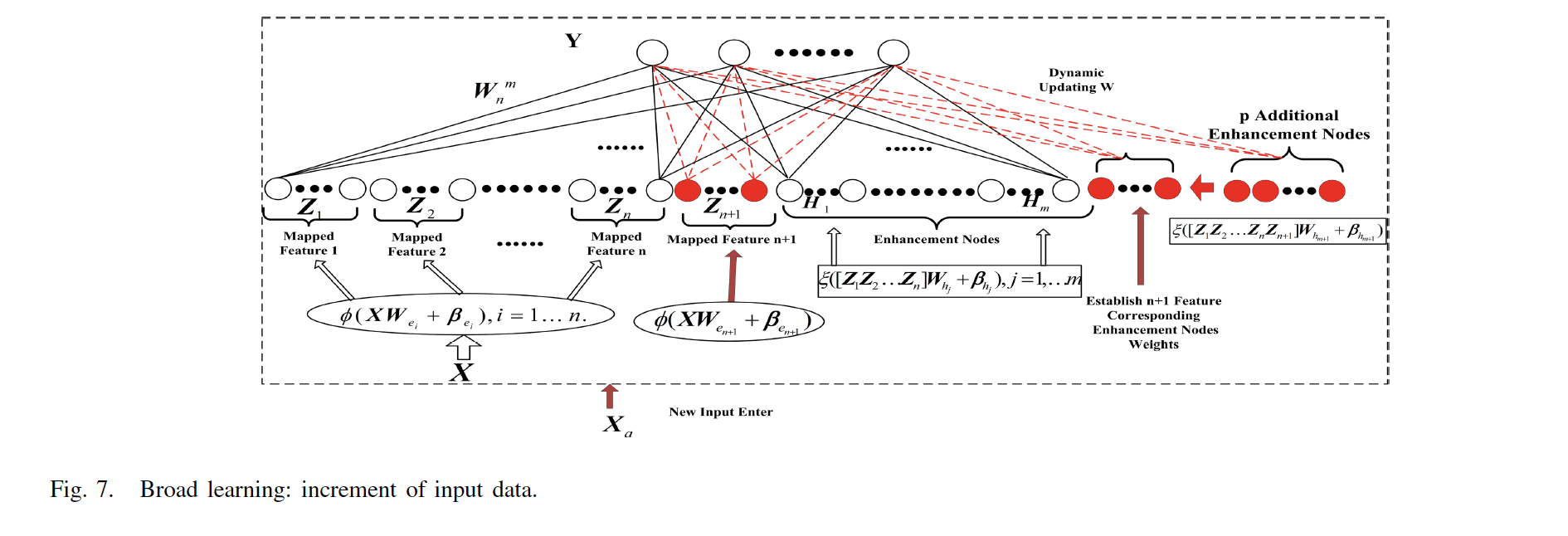
关于更新公式,原文的公式编辑的好像有点问题,我重新推了一遍,应该是下面的形式
记输入的伪逆为
( x A n m ) − 1 = [ ( A n m ) + − B D T , B ] (^{x}A^{m}_{n})^{-1} = [(A^{m}_{n})^{+}-BD^{T},B] (xAnm)−1=[(Anm)+−BDT,B]
这里的 D T = A x T A n m + D^{T} = A_{x}^{T}A^{m+}_{n} DT=AxTAnm+
B = { ( C T ) + i f C ≠ 0 ( A n m ) + D ( I + D T D ) − 1 i f C = 0 B = \left\{\begin{matrix}(CT)^{+} & if C \neq 0 \\ (A^{m}_{n})^{+}D(I+D^{T}D)^{-1} & if C = 0 \end{matrix}\right. B={
(CT)+(Anm)+D(I+DTD)−1ifC=0ifC=0
同时, C = A x T − D T A n m C = A^{T}_{x}-D^{T}A^{m}_{n} C=AxT−DTAnm
网络权重 W W W 的更新公式为
x W n m = W n m + B ( Y a T − A x T W n m ) ^{x}W^{m}_{n} = W^{m}_{n} + B(Y^{T}_{a}-A^{T}_{x}W^{m}_{n}) xWnm=Wnm+B(YaT−AxTWnm)
基于更新公式,BLS输入增量的算法如下
到这里为止,其实BLS的基本模型包括增量部分就已经全部讲完了,在论文中还有一些关于PCA简化输入矩阵结构的内容,感兴趣的可以去论文中具体研究。

三、实验结果
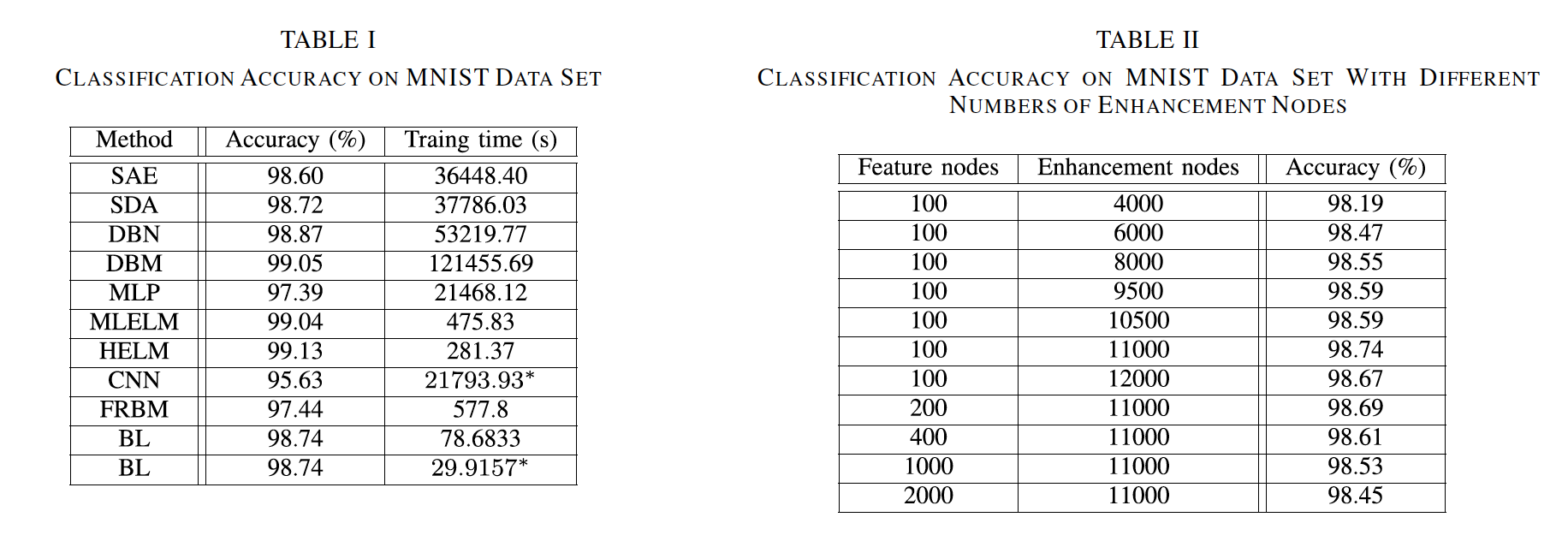
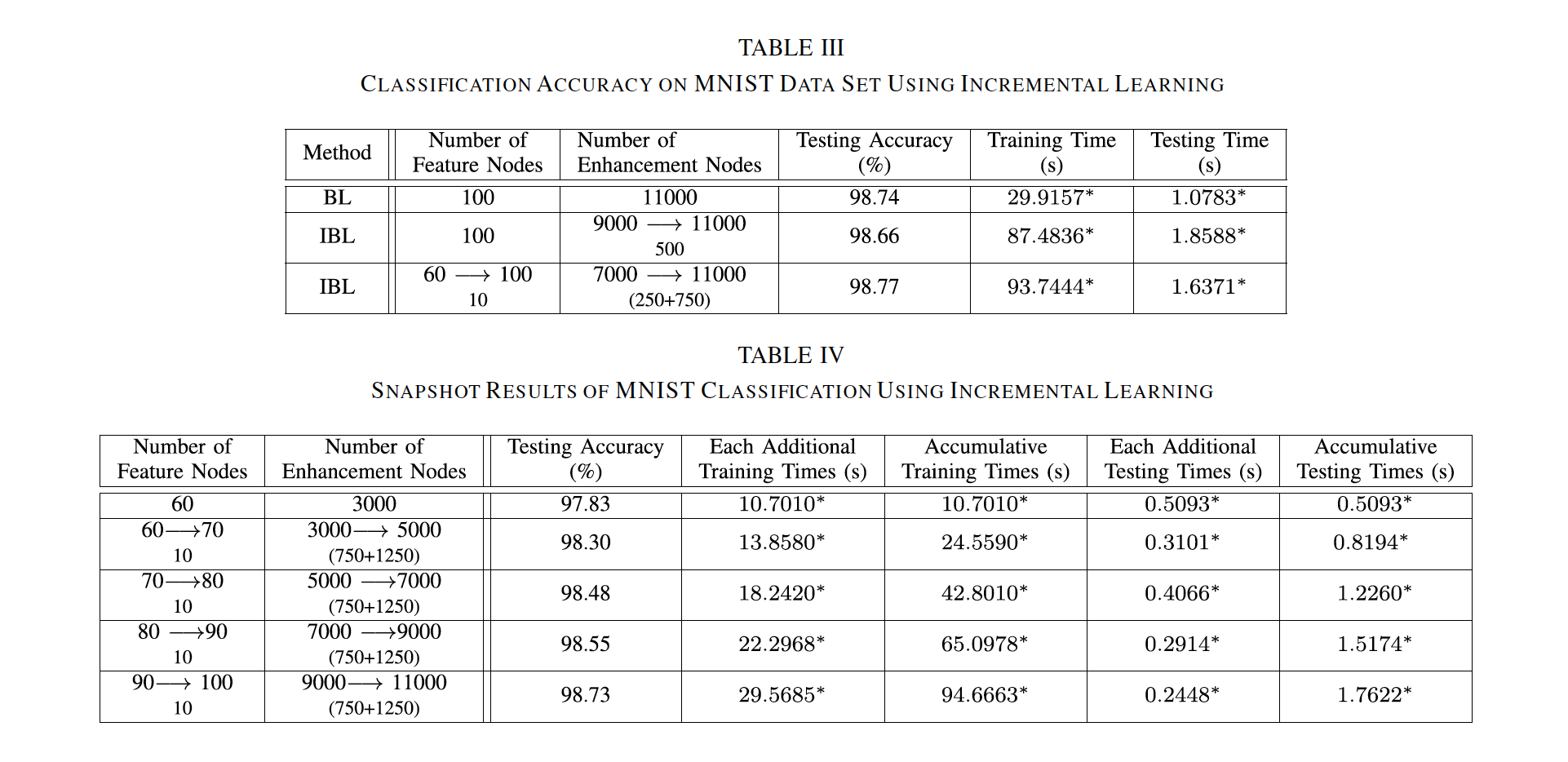
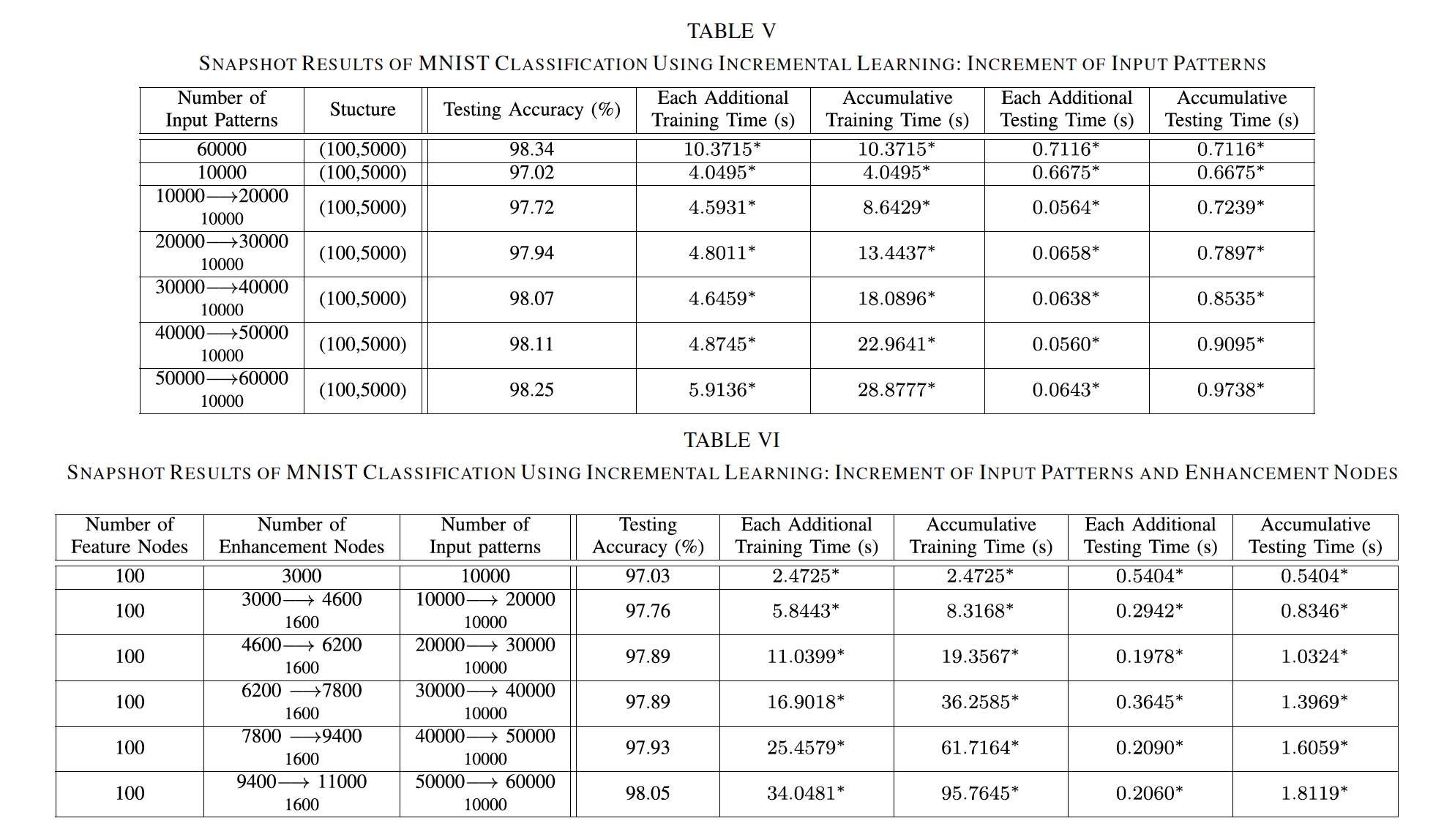
这里展示一些论文中的实验结果
3.1 Mnist数据集
3.2 NORB 数据集
四、代码链接
Matlab : http://www.fst.umac.mo/en/staff/pchen.html
python : https://github.com/LiangjunFeng/Broad-Learning-System
##参考文献
[1] Chen C, Liu Z. Broad Learning System: An Effective and Efficient Incremental Learning System Without the Need for Deep Architecture.[J]. IEEE Transactions on Neural Networks & Learning Systems, 2017, 29(1):10-24.
[2] Pao Y H, Park G H, Sobajic D J. Learning and generalization characteristics of the random vector functional-link net[J]. Neurocomputing, 1994, 6(2):163-180.
[3]Igelnik B, Pao Y H. Stochastic choice of basis functions in adaptive function approximation and the functional-link net[J]. IEEE Trans Neural Netw, 1995, 6(6):1320-1329.
五、更多资源下载
微信搜索“老和山算法指南”获取更多下载链接与技术交流群

有问题可以私信博主,点赞关注的一般都会回复,一起努力,谢谢支持。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143253.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
