大家好,又见面了,我是你们的朋友全栈君。
大数据篇:三大指标
上一篇文章中文章讲了如何用服务等级协议(SLA)来评估我们的系统,并讲解了几个常用的SLA指标
今天我们来讲分布式系统中另外几个基本概念
可扩展性(Scalability)
先从我们为什么需要分布式系统说起。原因是我们系统的数据量越来越大,从原来的GB到TB到现在的PB级,单机已经无法胜任这样的工作了。
工作中也常有这样的场景,随着业务变得原来越复杂,之前设计的系统无法处理日渐增长的负载。这时,我们就需要增加系统的容量。
分布式系统的核心就是可扩展性。
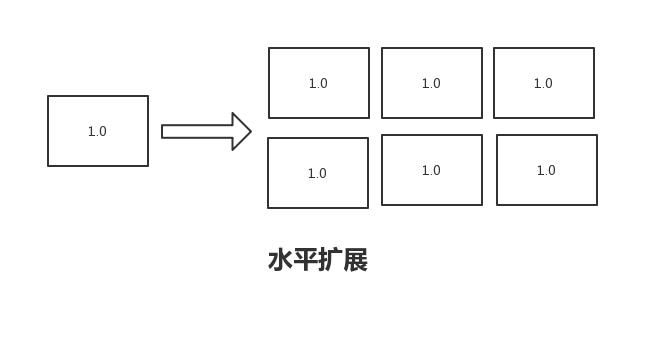
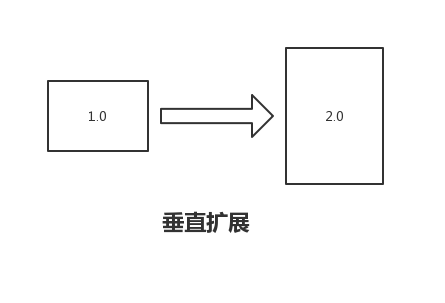
最基本且最流行的增加系统容量的模型由两种:水平扩展(Horizontal Scaling)、垂直扩展(Vertical Scaling)。
所谓的水平扩展,就是指在现有的系统中增加新的机器节点。

垂直扩展是指不改变机器数量,通过增加现有机器的性能,比如增加机器的内存。
举个例子:假设你是一个包工头。你有5个人手,他们每人一小时平均可以搬500块砖,那么一个小时最多搬5人×500块×1小时=2500块/小时。
如果你要使这个系统的负荷量增加一倍,用水平扩展的方式,我们可以讲雇佣人数加倍到10个人,或者使现在的人搬砖速度加倍。
到此,你是不是发现水平扩展的适用范围更广,操作更加的简单,并且会提升系统的可用性(Availability)。
如果你的系统部署在AWS或者其他主流的云服务器上,你会发现只需要点几个按钮,就可以轻松的增加一个新的节点。
但是,无节制的增加机器数量会带来许多问题,例如加大的系统的运维、系统间的通讯更加复杂,出错的几率更大,更难保持数据一致性。
与之相反,垂直扩展并没有使系统变得更加复杂,控制系统的代码也不需要做调整,但是它受到的限制也比较多。多数情况,单个机器的性能提升是有限的。而且受制于摩尔定律(-当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会提升一倍。换言之,每一美元所能买到的电脑性能,将每隔18-24个月翻上一倍以上 来源:百度百科),提高机器的性能往往比购买新的机器更加的昂贵。
所以在工作中,我们要对这两种模式进行取舍,要具体情况具体分析。
在大数据时代,数据增长速度越来越快,数据规模越来越大,对数据存储系统的扩展性要求也会越来越高。
传统的关系型数据库因为表与表之间地数据关联,经常会进行Join操作,所有数据放在单机系统中,很难支持水平扩展。而NoSql(非关系数据库)型的数据库天生支持水平扩展,所有这类存储系统应用越来越广,如:Redis、MongoDB等。
一致性(Consistency)
一般来说分布式系统的节点可用性会比整个系统的可用性低。
假设我们需要构建一个系统达到了99.999%的可用性(每年约有5分钟不可用),而单个节点的可用性为99.9%(每年约有8小时的宕机时间)。那么这时我们能想到的便是多增加几个结点,即使其中几个节点宕机,也有部分节点可以使用,这样系统的可用性就会提高了。
这时当节点不断增加,我们怎样保证不同节点同一时间接收和输出的数据是一致的呢?下面我讲解下一致性。
要保证分布式系统的内的机器节点有相同的信息,就需要机器间,定期同步。
然而,发送的消息并不一定是成功的,比如节点宕机、脑裂等。因此,一致性也是一个非常重要的概念。
接下来我讲解几个常见的一致性模型:强一致性(Strong Consistency)、弱一致性(Weak Consistency)、最终一致性(Eventual Consistency)。
- 强一致性:系统中的某个数据被成功更新后,后续任何数据的读取操作都将得到更新后的值。所有在任意时刻。同一系统所有节点中的数据是一样的。
- 弱一致性:系统中的某个数据被更新后,后续对该数据的读取操作可能得到更新后的值,也可能是更改前的值。但经够“不一致的时间窗口”后,读取到的值都是更新后的值。
- 最终一致性:最终一致性可以说是弱一致性的特例。系统保证在没有新的更新条件下,最终的所有访问都是最新的值。
上面的表述可能有些过于官方了,下面我来详细讲解下。
在强一致性系统中,只要某个数据的值有更新,这个数据的副本都要进行同步,以保证这个更新被传播到所有备份的数据库中,直到这个过程结束,才允许服务器来读取这个数据(这里有点像锁一样)。
所以必定会牺牲掉一部分延迟性,而且对于全局时钟的要求很高。举个例子:Google Cloud的Cloud Spanner就是一款强一致性的全球分布式企业级数据库服务。
在最终一致性系统中,我们无需等待数据更新到所有节点就可以获取。尽管不同的进程读同一数据,可能读到不同的结果,但是最终还是可以读取到同一数据。
很多认为银行间转账应该是强一致性,但是其实并不然。
举个例子,张三给李四转500块钱,张三扣款了,但是李四并不一定会收到500块钱。这里便会产生一个不一致性的时间窗口:张三扣款,而李四没有收到钱的时候。
另一个例子:你在12306系统上买票,也不是强一致性。

如果你买票的时候你发现票剩余5张,你发起订票请求,系统提示你“正在排队,现在还有5张票,前方还有10人在购买”。
这时你可能就会去查询订单详情,因为系统没有立即返回你成功或者失败。如果有人退了一张票,那么这张票会立即回到票池。这里也存在一个时间窗口。
但是5张票,只会卖给5人,不会卖给第6个人,这就是最终一致性(“最终所有数据都会同步”);
持久性(Durability)
数据持久性(Data Durability)意味着数据一旦被成功存储就可以一直使用,即使宕机、节点下线或数据损坏也是如此。
不同分布式数据拥有不同级别的持久性。有些系统支持机器(节点)级别的持久性,有些支持集群的持久性。有些压根没有持久性。
想要提高持久性,复制是一个非常好的做法,同一数据存储在不同节点上,即使节点无法连接,数据仍然可以从其他节点读取。
除了数据持久性还有另一个重要的持久性概念:消息持久性。在分布式系统中,节点之间需要经常相互发送消息去同步以保证一致性。对于重要的系统,常常不会允许任何消息丢失。
分布式系统间的消息通讯一般由分布式消息服务完成,如:Kafka,RabbitMq等。这些消息服务都支持不同级别的消息送达可靠性。消息持久性大致包含两个方面:1.当消息服务节点发生了错误,已经发生的消息仍然会在错误解决之后被处理。2.如果一个消息队列声明了持久性,那么即使队列在消息发送后掉线,仍然会在重新上线之后收到这条消息。
总结
上一篇我们讲了可用性、延迟性、准确性与这篇文章中的一致性、持久性、扩展性。我们不难发现一个系统想要在不牺牲某一指标的前提下,让每个指标都达到最好,是几乎不可能的。
下期预告:CAP理论
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/143048.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
