大家好,又见面了,我是你们的朋友全栈君。
原文: On word embeddings
作者: Sebastian Ruder
译者: KK4SBB 审校:王艺
责编:何永灿,关注人工智能,投稿请联系 heyc@csdn.net 或微信号 289416419
目录
- 词向量的来历
- 词向量模型
- 语言建模概述
- 经典的神经语言模型
- C&W模型
- Word2Vec
- CBOW
- Skip-gram
非监督式学习得到的词向量(word embedding)已经成功地应用于许多NLP的任务中,它常被誉为是一项利器。实际上,在许多NLP任务中,词向量已经完全地取代了传统的分布特征,比如布朗聚类和LSA特征。
去年的ACL和EMNLP大会基本被词向量方法所霸占,甚至有人戏称EMNLP更合理的解释应该是Embedding Methods in Natural Language Processing,词向量方法在自然语言处理中的应用。今年的ACL大会给词向量开辟了两场论坛。
对初学者而言,用词向量来计算词语的语义关系非常容易,NLP方向的深度学习演讲经常把国王 – 男人 + 女人 ≈ 王后的例子作为开篇。最近,Communications of the ACM上的一篇文章将词向量奉为是NLP取得重大突破的第一功臣。
本文是有关词向量系列文章的第一篇,我们希望全面地介绍一下词向量的方法。在此系列文章中,我们会提到多篇词向量模型相关的文献,重点突出几个模型、实际应用例子以及词向量方法的若干特点,后续的文章中还会介绍多语种的词向量模型和效果评估工作。
本篇文章将基于当前使用的词向量方法展开介绍。虽然其中许多的模型已经被人们充分地讨论过了,但我们希望在过去和现有的研究中讨论并调研它们的价值,能给我们提供新的见解。
术语约定:在本文中,我们将用词向量(word embeddings)来指代词语在低维向量空间的稠密表征。在英语中,它还可以被称作word vectors或是distributed representations。我们主要关注的是神经网络词向量,即通过神经网络模型学习得到的词向量。
词向量的来历
自上世纪90年代开始,特征空间模型就应用于分布式语言理解中。在当时,许多模型用连续型的表征来表示词语,包括潜在语义分析(Latent Semantic Analysis)和潜在狄利克雷分配(Latent Dirichlet Allocation)模型。这篇文章详细介绍了词向量方法在那个阶段的发展。
Bengio等人在2003年首先提出了词向量的概念,当时是将其与语言模型的参数一并训练得到的。Collobert和Weston则第一次正式使用预训练的词向量。Collobert和Weston的那篇里程碑式的论文A unified architecture for natural language processing不仅将词向量方法作为处理下游任务的有效工具,而且还引入了神经网络模型结构,为目前许多方法的改进和提升奠定了基础。词向量的真正推广要归因于Mikolov等人于2013年开发的Word2vec,word2vec可以训练和使用词向量。在2014年,Pennington等人发布了GloVe,这是一套预训练得到的完整词向量集,它标志着词向量方法已经成为了NLP领域的主流。
词向量方法是无监督式学习的少数几个成功应用之一。它的优势在于不需要人工标注语料,直接使用未标注的文本训练集作为输入。输出的词向量可以用于下游的业务处理。
词向量模型
一般来说,神经网络将词表中的词语作为输入,输出一个低维度的向量表示这个词语,然后用反向传播的方法不断优化参数。输出的低维向量是神经网络第一层的参数,这一层通常也称作Embedding Layer。
生成词向量的神经网络模型分为两种,一种是像word2vec,这类模型的目的就是生成词向量,另一种是将词向量作为副产品产生,两者的区别在于计算量不同。若词表非常庞大,用深层结构的模型训练词向量需要许多计算资源。这也是直到2013年词向量才开始被广泛用于NLP领域的原因。计算复杂度是使用词向量方法需要权衡的一个因素,我们在后面还有讨论。
两种模型的另一个区别在于训练的目标不同:word2vec和GloVe的目的是训练可以表示语义关系的词向量,它们能被用于后续的任务中;如果后续任务不需要用到语义关系,则按照此方式生成的词向量并没有什么用。另一种模型则根据特定任务需要训练词向量。当然,若特定的任务就是对语言建模,那么两种模型生成的词向量非常相似了。
顺便提一下,word2vec和GloVe在NLP中的地位就相当于VGGNet在机器视觉中的地位,都能够通过简单的训练生成有用的特征。
为了便于比较,我们约定以下符号:假设训练文本集含有T个文本w1, w2, w3 … , wt,词表V的大小是|V|。每个词语对应一个输入词向量vw(即Embedding Layer的向量),维度是d,输出一个词向量v’w(另一个词向量)。目标函数用Jθ表示,其中θ表示模型的参数,对每个输入值x输出一个得分fθ(x)。
语言建模概述
词向量模型与语言模型非常紧密地交织在一起。语言模型的质量评估是基于它们对词语用概率分布的表征能力。事实上,许多最先进的词向量模型都在攻坚的任务就是已有一串词语序列,预测下一个出现的词语将会是什么。词向量模型也常用perplexity指标进行评测,这项基于交叉熵的指标也是借鉴了语言建模。
在进入词向量模型之前,让我们先来简单地回顾一下基础的语言建模问题。
语言模型的任务通常是假设我们已经观察到了n个词语,预测下一个出现的词语是wt的概率,即p(wt|wt-1, … wt-n+1)。按照Markov链的假设,我们可以用每个词出现的概率值的乘积来估计这篇文章或者这句话的概率:
p(w1,⋯,wT)= ∏i p(wi|wi-1,⋯,wi−n+1)
在基于n-gram的语言模型中,我们可以基于n-gram出现的频率来计算词语的概率:


若设置n=2,就是bigram模型,当n=5并且使用Kneser-Ney平滑时,则是带平滑的5-gram,后者常被作为语言模型的baseline。Stanford的这个幻灯片详细比较了其中的细节。
在神经网络中,我们用softmax层也实现了同样的功能:
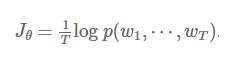
其中h是网络倒数第二层的输出向量(图1所示网络模型的隐藏层),v’w是词语w的词向量。注意,尽管v’w表示了词语w,但是它与输入词向量vw并没有太多关联,因为两者做的乘积各不相同(vw与一个索引向量相乘,而v’w与h相乘)。

图1 一种神经语言模型(Bengio,2006)
我们需要在神经网络的输出层计算每个词语w的概率。这里可以用两个矩阵相乘来高效地完成上述计算,其中一个矩阵是h,另一个权重矩阵的行由词表V中每个词语w对应的v’w向量组成。然后把得到的向量送入softmax层,softmax层将向量“压缩”成词典V中每个词语的概率分布。
注意,softmax层只考虑前n个词语(与之前的n-gram不同):常用的神经语言模型LSTM模型将这n个词语所表示的状态打包编码为一个状态h,而Bengio的神经语言模型将前n个词语拼接后送入前馈网络层,细节部分我们将在下一节讨论。
先记住softmax的概念,因为后续许多词向量模型都会用到它。
模型在每一步t都试图给正确的词语wt预测出最大的概率值。最终,模型希望整个文档集的平均log概率值最大化:
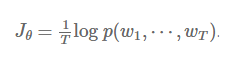
类似的,基于马科夫链的模型也希望在给定前n个词语计算当前词语的概率值时,整个文档的所有词语的log概率均值最大化:
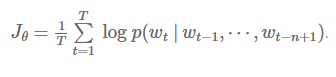
在测试阶段抽样词语时,我们既可以以贪心法在每一步选择概率值 p(wt|wt-1⋯wt-n+1)最大的词语,或是用定向搜索(Beam Search)的方法。这个过程可以像Karpathy’s Char-RNN提到的生成任意文本序列,或是作为序列预测任务的一部分,其中LSTM作为解码器使用。
经典的神经语言模型
Bengio等人在2003年提出的一种经典神经语言模型是含有一个隐藏层的前馈神经网络,用来预测序列中的下一个词语,如图2所示。

图2 经典的神经语言模型(Bengio等,2003)
他们模型所使用的目标函数与我们在上一节介绍的通用目标函数类似(我们为了简化,忽略了其中的正则项):
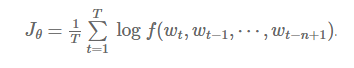
f(wt,wt-1,⋯,wt-n+1)是模型的输出值,即softmax层计算得到的概率p(wt|wt-1⋯wt-n+1),n是已经观测到的词语个数。
Bengio的论文是最早引入词向量概念的几篇论文之一。许多现在的方法都是在他搭建的框架的基础上逐步改进。他们模型的几个通用模块在如今的神经语言模型和词向量模型中仍可以看到。这几个模块就是:
1. Embedding Layer: 模型的这一层将索引向量与embedding矩阵相乘,生成词向量;
2. Intermediate Layer(s):一层或多层,生成输入层的中间表示,比如,用一个全连接层对前n个词语的词向量的拼接组合进行非线性变换;
3. Softmax Layer:模型的最后一层,生成每个词语的概率分布。
另外,Bengio的论文提出了两个建议,都被目前最好的模型所采纳了:
- 他们认为步骤2可以用LSTM模型取代,LSTM已经用于目前最好的模型[6,7]。
- 他们认为最后的softmax层是网络模型的主要瓶颈,因为softmax的计算量与词表V的大小成正比,通常在几十万到几百万的数量级。
因此,如何降低超大词表[9]在softmax层的运算量,成为了神经语言模型和词向量模型的主要挑战之一。
C&W模型
在Bengio的论文发表之后,词向量的研究停滞了很长一段时间,因为其需要大量计算资源,并且没有好的算法支持训练超大词表。
Collobert和Weston 4 (C&W来自于名字的首字母)在2008年发布的论文提到,当训练数据足够大时,训练得到的词向量自然能够包含相互之间句法和语义的信息,并且对下游任务的性能有提升。然后,他们在此基础上做了改进,于2011年发表了另一篇论文[8]。
他们重新选择了的目标函数,从而绕开了计算softmax的步骤:Bengio以交叉熵作为依据,在现有词语的情况下使得下一个词语出现的概率值最大,而Collobert和Weston的目标是使得正确的词语序列(此处的词语序列就是Bengio模型中的一个候选词序列)预测得分fθ高于错误的序列。因此,他们采用了pairwise的排序方法,公式如下所示:
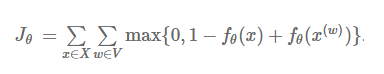
从文档集所有可能的窗口集合X中,采样得到包含n个词语的正确窗口集合x。对于每个窗口x,将序列中间的词语替换为词表中的另一个词语,组成一个不正确的窗口x(w)。他们现在的目标就是使得模型对正确窗口和不正确窗口的输出值的差距最大化。他们的模型结构如图3所示,不包括排序部分,与Bengio的模型类似。

图3 C&W模型结构(Collobert等,2011)
此模型生成的词向量已经包含了词语之间的许多关联,比如,国家名称的词向量被聚到了一起,语法相似的词语在向量空间的位置也很接近。虽然他们的排序目标函数不用计算复杂的softmax了,但他们仍然保留了全连接的隐藏层(图3中的* HardTanh*层),这部分也要消耗不少计算资源。可能因为这个原因,他们训练一个|V|=130000的数据集需要整整七个星期。
Word2Vec
接下来,我们介绍最广为人知的词向量模型:word2vec,它是Mikolov在2013年发表的两篇论文的核心。由于构建词向量是NLP深度学习模型的重要模块,word2vec也常被归为深度学习。但是,准确地说,word2vec并不归属于深度学习的范畴,因为它的模型结构既不深,也没有用到非线性(对比Bengio和C&W的模型)。
在Mikolov的第一篇论文中[2],他们提出了比之前模型计算量更小的两种模型结构来计算词向量。在第二篇论文中[3],他们在此结构的基础上添加新策略,进一步提升了训练速度和准确率。这种结构相比C&W和Bengio的模型有两大优势:
- 它抛弃了计算繁琐的隐藏层
- 它支持向语言模型中添加额外信息
他们的模型成功之处不仅仅在于这两方面的改进,更在于训练阶段的特殊策略,我在后续内容中会慢慢介绍。
我们分别来看一下这两种结构:
Continuous bag-of-words (CBOW)
语言模型的评价标准是能否正确预测下一个出现的词语,因此它所能利用的信息仅仅只是已经观察到的词语,而一个用于训练词向量的准确表示的模型则不受这方面的限制。于是,Mikolov利用目标词语wt前后各n个词语来进行预测,如图4所示。他们将此方法称为是连续词袋模型,因为用到了连续的表征,而与前后词语的位置顺序无关。

图4 连续词袋模型(Mikolov等,2013)
CBOW的目标函数与语言模型的仅有细微差别:
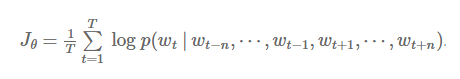
差别在于CBOW模型每一步接受到目标词语wt前后各n个词语,而不是给模型输入前n个词语。
Skip-gram
如果说CBOW模型可以被视为一个预知的语言模型,skip-gram则正好相反:CBOW是用周围的词语预测中间的目标词语,而skip-gram是用中间的词语来预测周围的词语,如图5所示。

图5 Skip-gram (Mikolov等, 2013)
所以,skip-gram的目标函数就是目标词语wt左右n个词语的log概率之和:
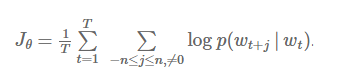
为了更直观地理解skip-gram模型计算 p(wt+j|wt)的过程,我们先来回顾一下softmax的计算公式:
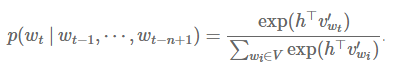
我们的场景是已知wt,计算附近词语wt+j出现的概率,而不是已知出现的前n个词语,预测wt出现的概率。因此,softmax的公式变形为:
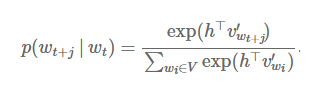
skip-gram结构并不需要表示中间状态h的隐藏层,那么h直接就是词语wt的词向量vwt。这也解释了为什么输入词向量vw和输出向量v’w的表示需要不一样,否则相当于向量的自乘了。将h替换为vwt得到:
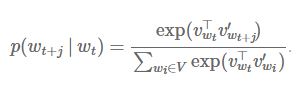
我们用的符号与Mikolov论文中的略有不同。在Mikolov的论文中wI表示中间的词语,wO表示其附近的词语。如果我们用wI替换wt,wO替换wt+j,就得到了Mikolov论文中的softmax公式:
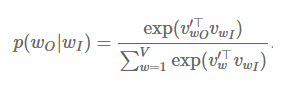
在下一期文章中,我们将讨论几种softmax的估算方法以及训练的技巧。还将介绍GloVe[5]方法,这是一种基于矩阵分解的词向量模型,以及词向量方法和分布语义方法之间的联系。
参考文献
-
Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A Neural Probabilistic Language Model. The Journal of Machine Learning Research, 3, 1137–1155. http://doi.org/10.1162/153244303322533223
-
Mikolov, T., Corrado, G., Chen, K., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. Proceedings of the International Conference on Learning Representations (ICLR 2013), 1–12.
-
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. NIPS, 1–9.
-
Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing. Proceedings of the 25th International Conference on Machine Learning – ICML ’08, 20(1), 160–167. http://doi.org/10.1145/1390156.1390177
-
Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1532–1543. http://doi.org/10.3115/v1/D14-1162
-
Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2016). Character-Aware Neural Language Models. AAAI. Retrieved from http://arxiv.org/abs/1508.06615
-
Jozefowicz, R., Vinyals, O., Schuster, M., Shazeer, N., & Wu, Y. (2016). Exploring the Limits of Language Modeling. Retrieved from http://arxiv.org/abs/1602.02410
-
Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural Language Processing (almost) from Scratch. Journal of Machine Learning Research, 12 (Aug), 2493–2537. Retrieved from http://arxiv.org/abs/1103.0398
-
Chen, W., Grangier, D., & Auli, M. (2015). Strategies for Training Large Vocabulary Neural Language Models, 12. Retrieved from http://arxiv.org/abs/1512.04906
想了解人工智能背后的那些人、技术和故事,欢迎关注人工智能头条:

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/142857.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
