大家好,又见面了,我是你们的朋友全栈君。
本节教程将继续介绍SQL基础知识中的SELECT相关的一些知识,包括基础语法、多表连接、去重、排序、子查询等等SELECT方面的基础知识。
SELECT是SQL中使用的比较多的,主要是用于筛选数据,获取满足某些条件的数据,既可以是单条数据,也可以是多条数据,还可以是统计数据或者分组数据等等,后续教程将会一一介绍。
1. SELECT基础语法
SELECT语法基础
SELECT在SQL中主要是用于获取满足条件的数据的,期基本的语法格式如下:
SELECT <ITEM_LIST>
FROM <TABLE_LIST>
WHERE <WHERE_CLAUSE>
ORDERBY <ORDER_BY_CLAUSE>语法格式说明:
SELECT:用于查询、筛选数据
FORM:筛选数据的来源(表、视图、自查询)
WHERE:筛选数据的过滤条件(非必须,根据需要添加)
ORDER BY:用于对选择的结果集数据进行排序(非必须,根据需要添加)
ITEM_LIST:需要选取的对应的数据的列信息
TABLE_LIST:需要选取的数据表,一个或者多个,既可以是表,也可以是视图,还可以是自查询
WHERE_CLAUSE:获取数据的时候的过滤条件,只选取满足条件的数据即可,可以没有条件,即获取所有的数据
ORDER_BY_CLAUSE:结果集的排序条件,可以按照一个字段或者多个字段排序
使用示例
该示例使用SCOTT用户下的EMP员工用户信息表:
SELECT N.EMPNO, N.ENAME, N.JOB, N.MGR, N.HIREDATE, N.SAL, N.COMM, N.DEPTNO
FROM SCOTT.EMP N
WHERE N.SAL > 2000
ORDERBY N.EMPNO ASC;以上SQL主要是用于获取SCOTT.EMP表中的薪水大于2000的相关的员工信息,并且对获得的结果集按照员工编号升序排列

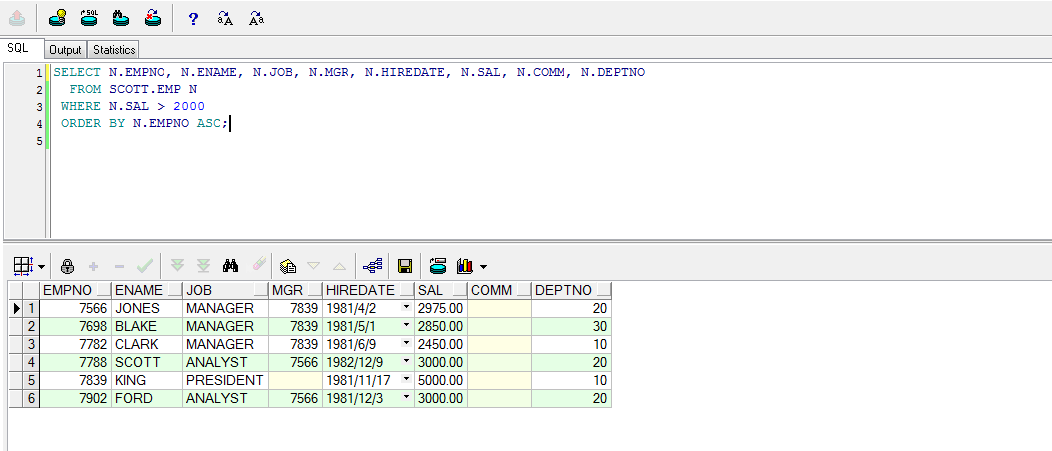
备注:在实际的使用中,可以给表或者视图起个别名,例如上例中的SCOTT.EMP表的别名是N,在SELECT中便可以使用该别名来代替表名来获得对应的表中的列信息,比直接使用表名方便。
2. SELECT常用技巧
去重DISTINCT
在实际工作中,有时可能查询的数据结果集中会存在重复数据,此时可以使用DISTINCT关键字来去掉重复记录:
未去掉重复记录 :
SELECT N.ENAME, N.JOB, N.DEPTNO FROM EMP N WHERE N.SAL > 2000;
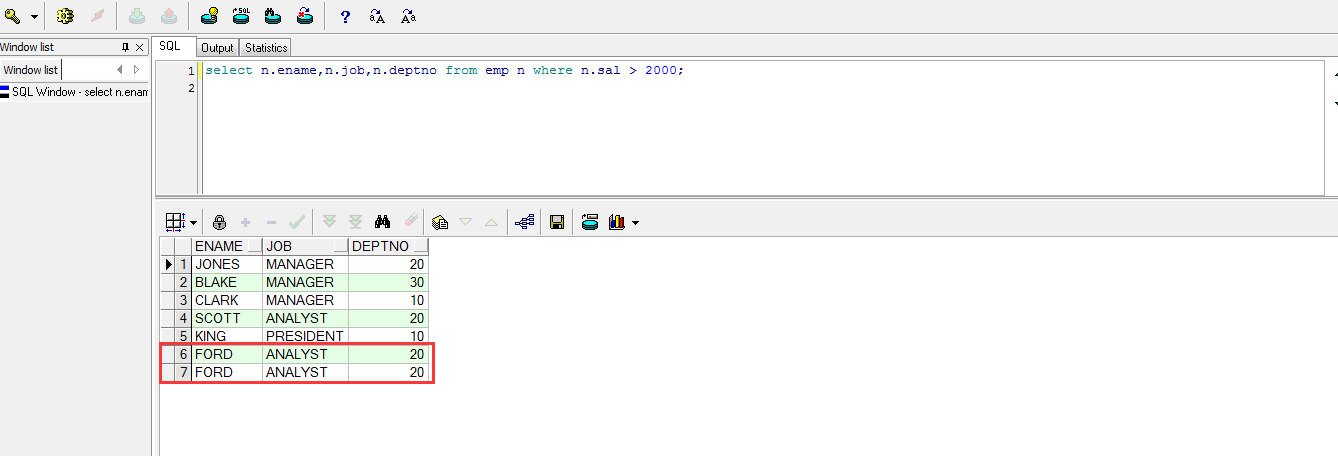
使用DISTINCT关键字去掉重复记录之后的查询:
SELECTDISTINCT N.ENAME, N.JOB, N.DEPTNO FROM EMP N WHERE N.SAL > 2000;
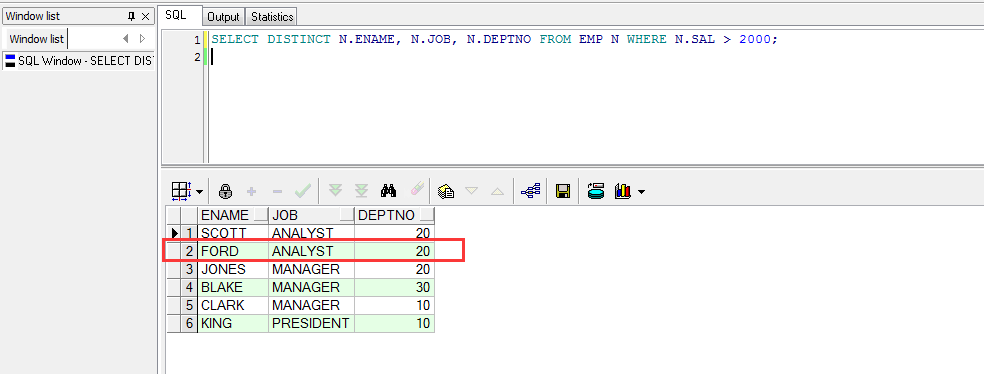
可以看到重复的记录只会显示一条了。
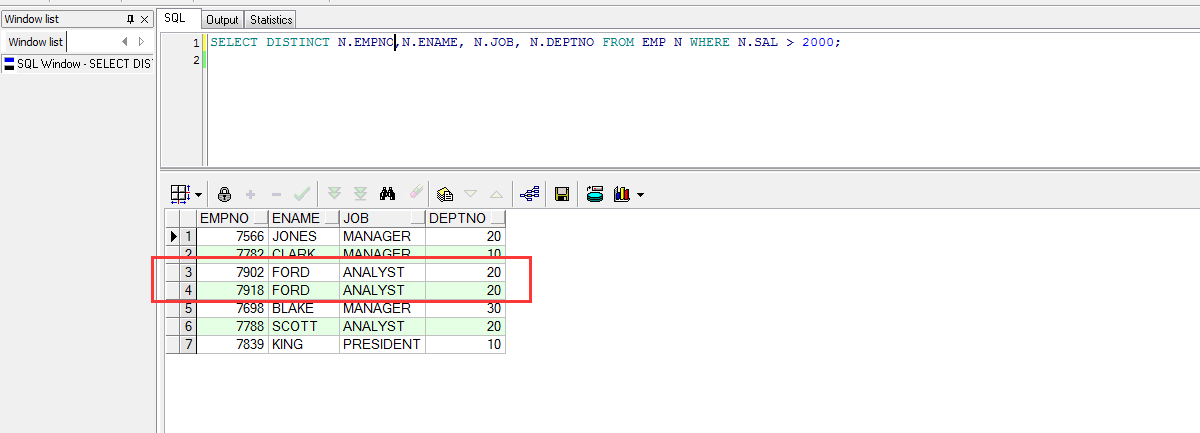
说明:重复的数据是所有的列数据一致,要是有不一致的数据列,则不是重复数据。非重复数据即使使用了DISTINCT之后也不会去掉重复记录。如下图所示,:
SELECTDISTINCT N.EMPNO,N.ENAME, N.JOB, N.DEPTNO FROM EMP N WHERE N.SAL > 2000;
排序 ORDER BY
如果需要对SELECT的结果集进行排序操作,就需要使用到ORDER BY关键字了。一般ORDER BY是和 ASC(升序)、DESC(降序)一起使用的,常用的排序就这两种,可以按照一个字段来排列,也可以按照多个字段排列:
SELECT N.EMPNO, N.ENAME, N.JOB, N.DEPTNO
FROM SCOTT.EMP N
WHERE N.SAL > 2000
ORDERBY n.empno asc;
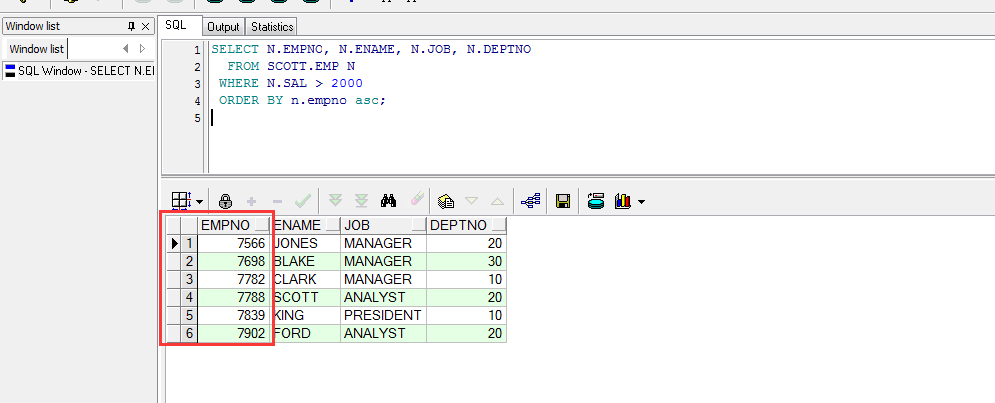
上图中的脚本就是对结果集按照员工编号升序排列的(降序使用DESC)
说明:对于查询的数据量比较大的操作进行排序操作会消耗一定的系统资源,影响查询效率,因此在使用的时候需要根据实际情况来确定是否需要进行排序操作。
UNION和UNION ALL
UNION和UNION ALL都是用于将两个或者多个查询的结果集拼接到一起的,区别就在于UNION会对组合之后的结果集进行排序,去掉重复的记录;而UNION ALL不会对结果进行排序,如果有重复记录则正常展示。
UNION和UNION ALL拼接两个查询的时候需要要求两个或者多个查询结果的结果集的选取的列数和对应的数据类型都需要相同,否则无法正常执行查询。
UNION和UNION ALL使用示例,此处使用同一脚本进行测试,便于看出区别:
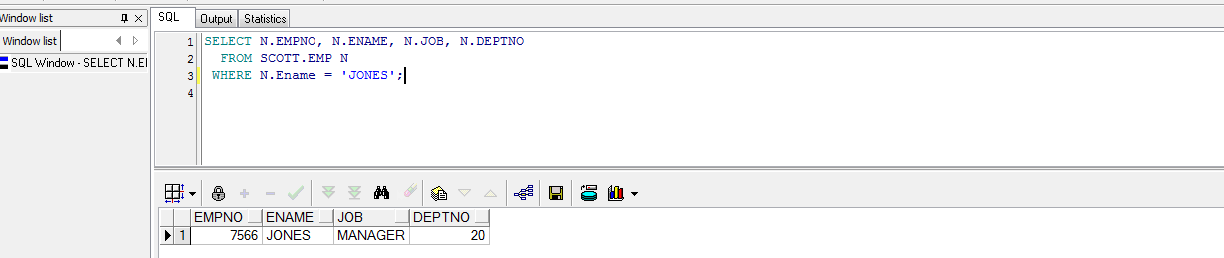
测试脚本,选取员工姓名为“JONES”的一条记录:
SELECT N.EMPNO, N.ENAME, N.JOB, N.DEPTNO
FROM SCOTT.EMP N
WHERE N.Ename = 'JONES';
使用UNION ALL的效果:
SELECT N.EMPNO, N.ENAME, N.JOB, N.DEPTNO
FROM SCOTT.EMP N
WHERE N.Ename = 'JONES'
UNIONALL
SELECT N.EMPNO, N.ENAME, N.JOB, N.DEPTNO
FROM SCOTT.EMP N
WHERE N.Ename = 'JONES'
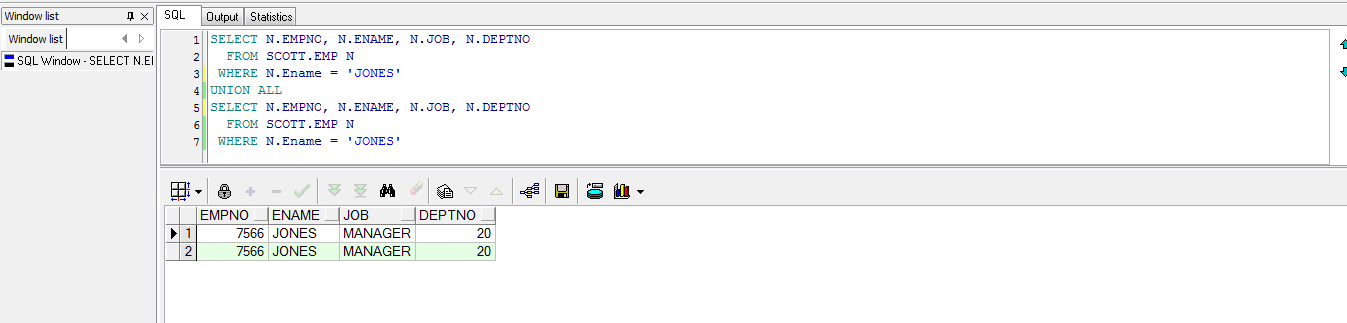
可以看到结果出现了两条一样的记录,而如果同样的脚本使用UNION来进行拼接的话,则会自动去掉重复的记录信息:
SELECT N.EMPNO, N.ENAME, N.JOB, N.DEPTNO
FROM SCOTT.EMP N
WHERE N.Ename = 'JONES'
UNION
SELECT N.EMPNO, N.ENAME, N.JOB, N.DEPTNO
FROM SCOTT.EMP N
WHERE N.Ename = 'JONES'
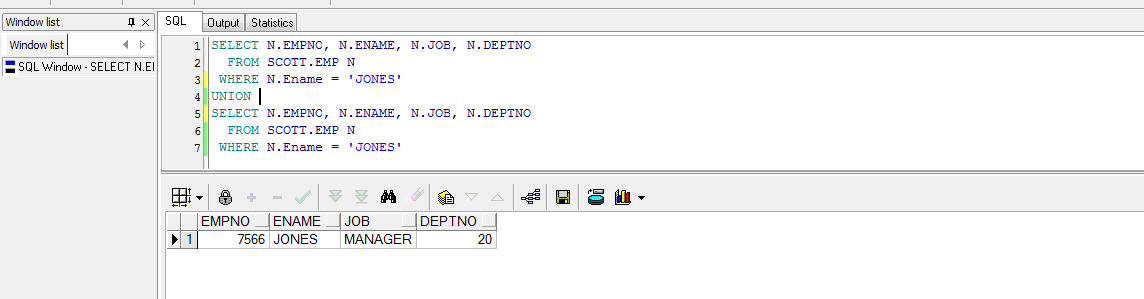
可以看到使用UNION拼接两个相同的SQL,但是结果并不会重复,即UNION会自动去掉结果集中重复的记录信息。
子查询的概念
什么叫“子查询”?子查询也是查询的一种,就是在一个查询结果集中使用的位于SELCET、FORM或者WHERE中的局部的查询,可以理解为子查询也是一个小的查询结果集,不过不能单独执行而已,必须嵌套于某个查询之内。
实际使用中,在某个查询语句中,如果需要使用子查询,则可以使用小括号 () 将某个查询括起来,作为外部查询的嵌套查询语句,该括号括起来的部分就叫做“子查询”
子查询的类型
子查询也是一个小的查询结果集,既可以返回多行数据,也可以返回单行数据。一般的,子查询可以用于SELECT结果列表,也可以用在FORM语句中,还可以使用在WHERE语句中作为过滤条件使用。不同的位置,对于子查询的要求也是不同的:
在SELECT列中:
位于SELECT列中的子查询,将其结果作为SELECT的一个列的值,因此该子查询匹配的每行结果只能返回一个单一的值,否则就会值过多错误。例如:
正确示例:
SELECT N.EMPNO,
N.ENAME,
N.JOB,
N.DEPTNO,
(select m.dname from SCOTT.Dept m
where m.deptno = N.DEPTNO)
FROM SCOTT.EMP N;
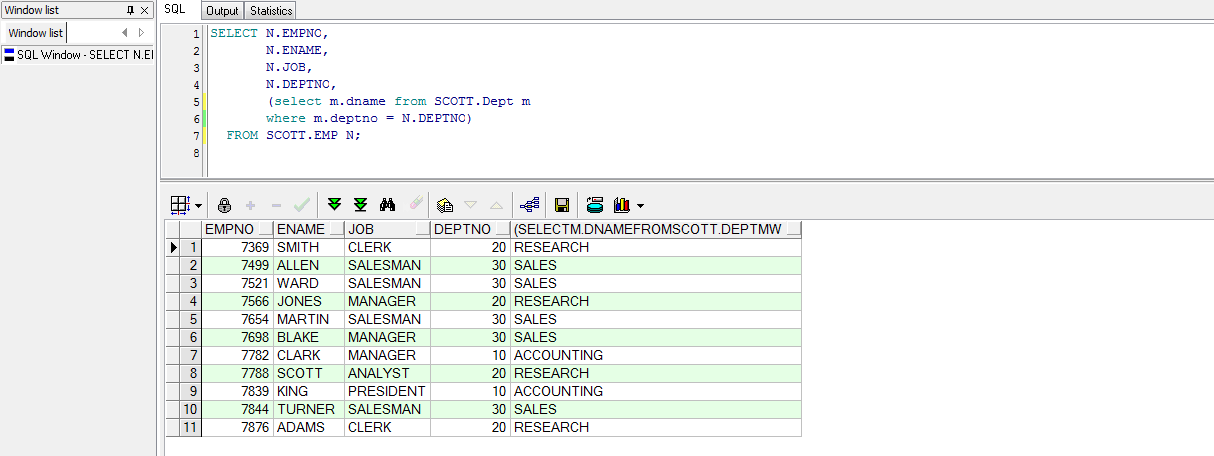
使用员工表的员工部门编号匹配部门表的部门编号,子查询用户获取员工对应的部门名称。可以看到此处的子查询只获取了一个部门名称,如果给该子查询再添加一个结果列,则该语句就无法执行了。
错误示例:
SELECT N.EMPNO,
N.ENAME,
N.JOB,
N.DEPTNO,
(select m.dname,m.deptno from SCOTT.Dept m
where m.deptno = N.DEPTNO)
FROM SCOTT.EMP N;
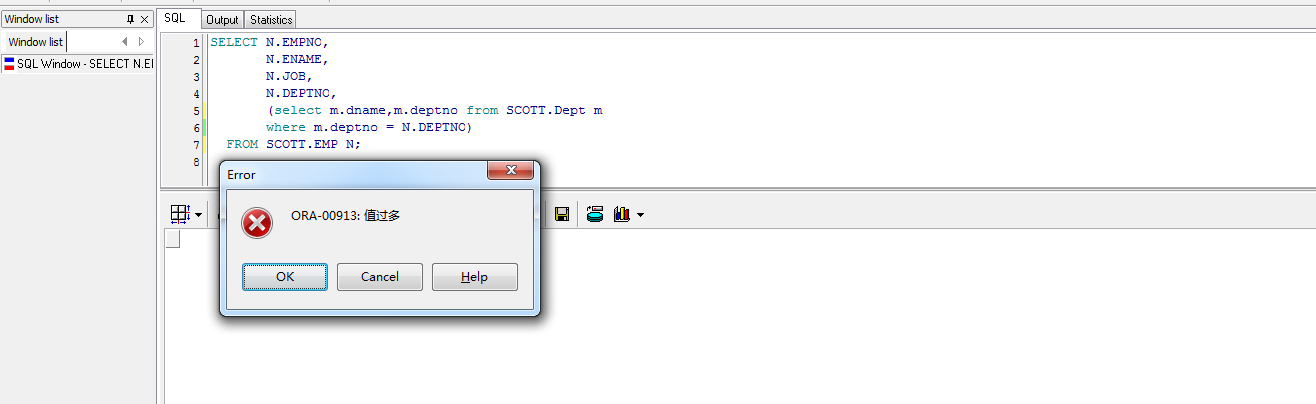
可以看到查询无法正常执行,报错,提示值过多。
位于FROM中的子查询,是将子查询的结果作为一个“表”来使用的,此时的子查询既可以选取多列,也可以返回多行,和使用表没有区别:
位于WHERE条件中的子查询,可以返回单一列的多行或者一行记录,具体的情况需要和前边的过滤条件相匹配,对于“=”子查询的情况只能返回一行;对于“IN”子查询的情况,可以返回一行或者多行记录
示例:
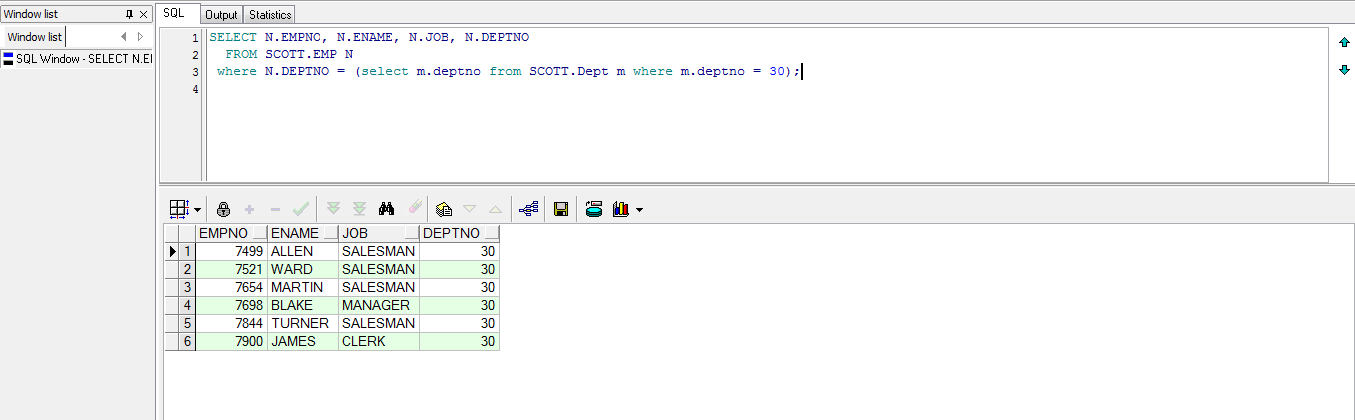
“=”子查询的情况
SELECT N.EMPNO, N.ENAME, N.JOB, N.DEPTNO
FROM SCOTT.EMP N
where N.DEPTNO = (select m.deptno from SCOTT.Dept m where m.deptno = 30);
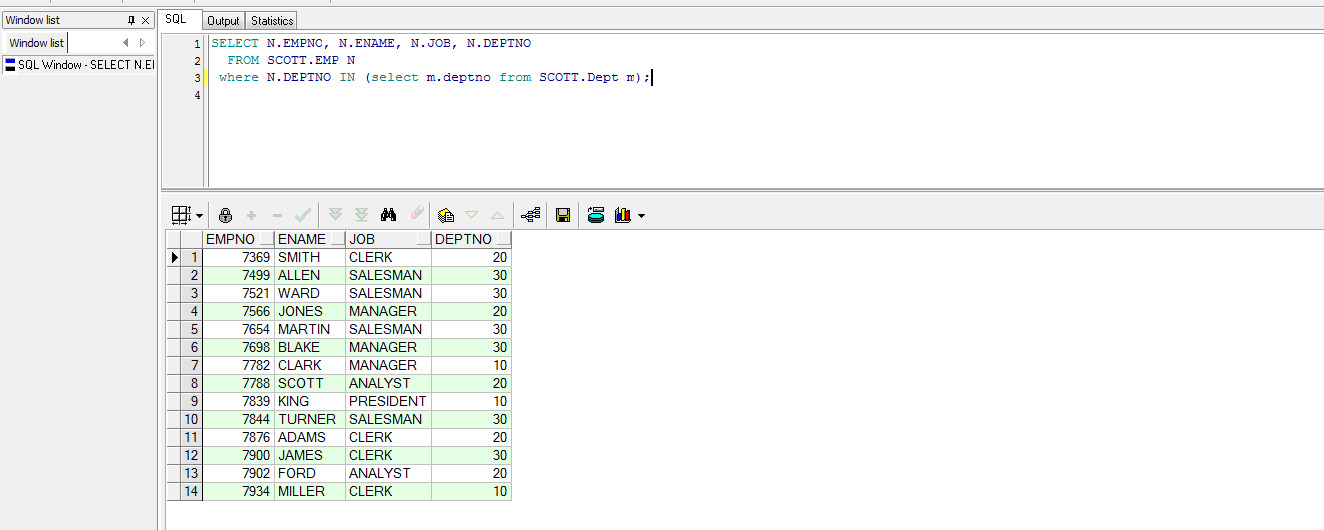
“IN”子查询的情况
SELECT N.EMPNO, N.ENAME, N.JOB, N.DEPTNO
FROM SCOTT.EMP N
where N.DEPTNO IN (select m.deptno from SCOTT.Dept m);
SQL 查询的相关知识到此基本就结束了,后续内容将会在其他章节继续介绍。
附录
a. 本系列教程为个人原创,基于实际工作中的使用情况及个人理解,仅供学习交流之用,有不足之处还望批评指正,希望共同提高
b. 本节教程使用的数据表均为Oracle数据库中Scott用户下的EMP(员工表)和DEPT(部门表)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/142810.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
