大家好,又见面了,我是你们的朋友全栈君。
写在前面:我是「云祁」,一枚热爱技术、会写诗的大数据开发猿。昵称来源于王安石诗中一句
[ 云之祁祁,或雨于渊 ],甚是喜欢。写博客一方面是对自己学习的一点点总结及记录,另一方面则是希望能够帮助更多对大数据感兴趣的朋友。如果你也对
数据中台、数据建模、数据分析以及Flink/Spark/Hadoop/数仓开发感兴趣,可以关注我的动态 https://blog.csdn.net/BeiisBei ,让我们一起挖掘大数据的价值~
每天都要进步一点点,生命不是要超越别人,而是要超越自己! (ง •_•)ง
一、前言
之前写了篇面经 《一个月面试近20家大中小厂,在互联网寒冬突破重围,成功上岸!》,有不少小伙伴留言和私信我关于大数据学习路线,以及咨询我一些关于有工作经验想转行大数据的问题,只言片语也讲不清,我花了一个月整理了一份我当初学习的大数据学习路线,从最基础的大数据集群搭建开始,希望能帮助到大家。
不过在开始之前,我还是希望大家能想清楚,如果自己很迷茫,为了什么原因想往大数据方向发展,还有就是我就想问一下,你的专业是什么,对于计算机/软件,你的兴趣是什么?
是计算机专业,对操作系统、硬件、网络、服务器感兴趣?
是软件专业,对软件开发、编程、写代码感兴趣?
还是数学、统计学专业,对数据和数字特别感兴趣?
欢迎大家在评论区留言讨论 ( •̀ ω •́ )✧
这其实也就关系到大数据的三个发展方向:
- 平台搭建/优化/运维/监控
- 大数据开发/设计/架构
- 数据分析/挖掘
现如今,正式为了应对大数据的这几个特点,开源的大数据框架越来越多,越来越强,先列举一些常见的:
文件存储:Hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
流式、实时计算:Storm、Spark Streaming、Flink
K-V、NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务:Zookeeper
集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习:Mahout、Spark MLLib
数据同步:Sqoop
任务调度:Oozie
……
眼花了吧,上面的有30多种吧,别说精通了,全部都会使用的,估计也没几个。
就我个人而言,主要目前是在第二个方向(开发/设计/架构),那我就从大数据的发展史讲起。由于自己经验有限,本文内容参考了圈内不少老师的观点,供大家参考和互相学习。
二、大数据的发展史
关于大数据的发展史,我觉得骆俊武老师在《AI 时代,还不了解大数据?》一文中讲的非常清楚。大数据在它近三十年的发展史中,共经历了5个阶段。
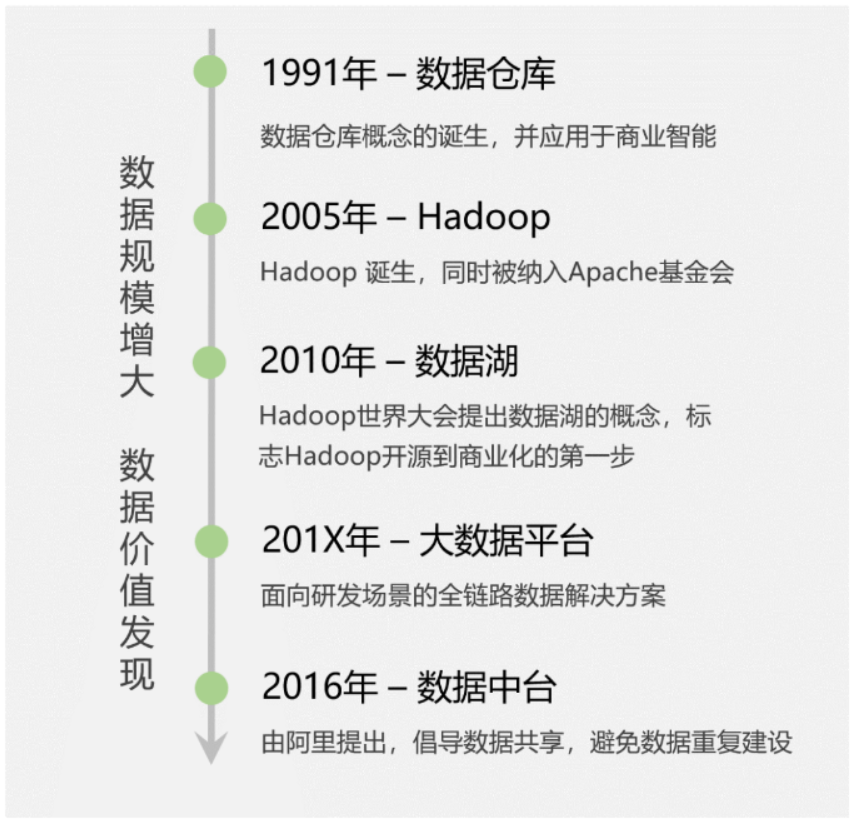

2.1 启蒙阶段:数据仓库的出现
20世纪90年代,商业智能(也就是我们熟悉的BI系统)诞生,它将企业已有的业务数据转化成为知识,帮助老板们进行经营决策。比如零售场景中:需要分析商品的销售数据和库存信息,以便制定合理的采购计划。
显然,商业智能离不开数据分析,它需要聚合多个业务系统的数据(比如交易系统、仓储系统),再进行大数据量的范围查询。而传统数据库都是面向单一业务的增删改查,无法满足此需求,这样就促使了数据仓库概念的出现。
传统的数据仓库,第一次明确了数据分析的应用场景,并采用单独的解决方案去实现,不依赖业务数据库。
2.2 技术变革:Hadoop诞生

2000年左右,PC互联网时代来临,同时带来了海量信息,很典型的两个特征:
- 数据规模变大:Google、雅虎等互联网巨头一天可以产生上亿条行为数据。
- 数据类型多样化:除了结构化的业务数据,还有海量的用户行为数据,以图像、视频为代表的多媒体数据。
很显然,传统数据仓库无法支撑起互联网时代的商业智能。2003年,Google公布了3篇鼻祖型论文(俗称「谷歌三驾马车」),包括:分布式处理技术MapReduce,列式存储BigTable,分布式文件系统GFS。这3篇论文奠定了现代大数据技术的理论基础。
苦于Google并没有开源这3个产品的源代码,而只是发布了详细设计论文。2005年,Yahoo资助Hadoop按照这3篇论文进行了开源实现,这一技术变革正式拉开了大数据时代的序幕。
Hadoop相对于传统数据仓库,有以下优势:
- 完全分布式,可以采用廉价机器搭建集群,完全可以满足海量数据的存储需求。
- 弱化数据格式,数据模型和数据存储分离,可以满足对异构数据的分析需求。
随着Hadoop技术的成熟,2010年的Hadoop世界大会上,提出了「数据湖」的概念。
关于数据湖的理论,大家可以看我的这篇博客。
初探数据湖(Data Lake),到底有什么用?让我们来一窥究竟…
企业可以基于Hadoop构建数据湖,将数据作为企业的核心资产。由此,数据湖拉开了Hadoop商业化的大幕。
2.3 数据工厂时代:大数据平台兴起
商用Hadoop包含上十种技术,整个数据研发流程非常复杂。为了完成一个数据需求开发,涉及到数据抽取、数据存储、数据处理、构建数据仓库、多维分析、数据可视化等一整套流程。这种高技术门槛显然会制约大数据技术的普及。
此时,大数据平台(平台即服务的思想,PaaS)应运而生,它是面向研发场景的全链路解决方案,能够大大提高数据的研发效率,让数据像在流水线上一样快速完成加工,原始数据变成指标,出现在各个报表或者数据产品中。
2.4 数据价值时代:阿里提出数据中台
2016年左右,已经属于移动互联网时代了,随着大数据平台的普及,也催生了很多大数据的应用场景。
此时开始暴露出一些新问题:为了快速实现业务需求,烟囱式开发模式导致了不同业务线的数据是完全割裂的,这样造成了大量数据指标的重复开发,不仅研发效率低、同时还浪费了存储和计算资源,使得大数据的应用成本越来越高。
极富远见的马云爸爸此时喊出了「数据中台」的概念,「One Data,One Service」的口号开始响彻大数据界。数据中台的核心思想是:避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能业务。
关于阿里数据中台,可以参考这篇转载自谭虎、陈晓勇老师的:
三、大数据方面核心技术有哪些?
大数据的概念比较抽象,而大数据技术栈的庞大程度将让你叹为观止。
大数据技术的体系庞大且复杂,基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据仓库、机器学习、并行计算、可视化等各种技术范畴和不同的技术层面。首先给出一个通用化的大数据处理框架,主要分为下面几个方面:数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。
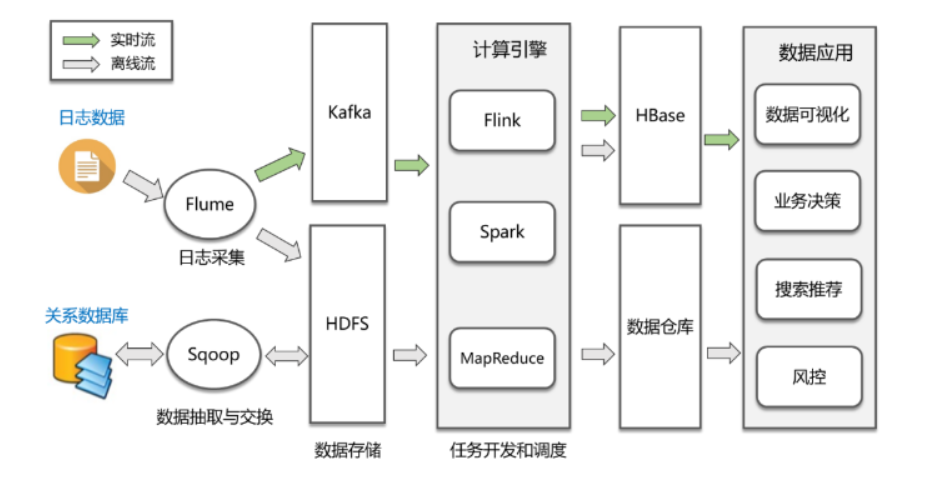
- 数据采集:这是大数据处理的第一步,数据来源主要是两类,第一类是各个业务系统的关系数据库,通过Sqoop或者Cannal等工具进行定时抽取或者实时同步;第二类是各种埋点日志,通过Flume进行实时收集。
- 数据存储:收集到数据后,下一步便是将这些数据存储在HDFS中,实时日志流情况下则通过Kafka输出给后面的流式计算引擎。
- 数据分析:这一步是数据处理最核心的环节,包括离线处理和流处理两种方式,对应的计算引擎包括MapReduce、Spark、Flink等,处理完的结果会保存到已经提前设计好的数据仓库中,或者HBase、Redis、RDBMS等各种存储系统上。
- 数据应用:包括数据的可视化展现、业务决策、或者AI等各种数据应用场景。
通过上述的内容,可能大家对大数据都有了初步的了解,接下来就是核心的部分,因为任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。大数据所需学习的内容纷繁复杂,难度较大,有一个合理的大数据学习路线图帮忙理清思路就显得尤为必要。
1. Java 语言
以Java语言为基础掌握面向对象编程思想所涉及的知识,以及面向对象编程,然后主流的SSM、Spring Boot等开源框架最好也能掌握。
2. MySQL 数据库
MySQL数据库掌握关系型数据库的原理,主要是各种复杂SQL语句的编写,这会对后面学Hive数仓的HQL起到事半功倍的效果。
3. Linux 操作系统
因为大数据相关软件都是在Linux上运行的,所以Linux要学习的扎实一些,学好Linux对你快速掌握大数据相关技术会有很大的帮助,能让你更好的理解Hadoop、Hive、HBase、Spark等大数据软件的运行环境和网络环境配置,能少踩很多坑,学会Shell就能看懂脚本这样能更容易理解和配置大数据集群。
4. Hadoop 技术学习
这是现在流行的大数据处理平台几乎已经成为大数据的代名词,所以这个是必学的。Hadoop里面包括几个组件HDFS、MapReduce和Yarn。
HDFS是存储数据的地方就像我们电脑的硬盘一样文件都存储在这个上面,MapReduce是对数据进行处理计算的,它有个特点就是不管多大的数据只要给它时间它就能把数据跑完,但是时间可能不是很快所以它叫数据的批处理。Yarn是体现Hadoop平台概念的重要组件有了它大数据生态体系的其它软件就能在Hadoop上运行了,这样就能更好的利用HDFS大存储的优势和节省更多的资源,比如我们就不用再单独建一个Spark的集群了,让它直接跑在现有的HadoopYarn上面就可以了。
4.1 学会百度与Google
不论遇到什么问题,先试试搜索并自己解决。Google首选,翻不过去的,就用百度吧。
4.2 参考资料首选官方文档
特别是对于入门来说,官方文档永远是首选文档。相信搞这块的大多是文化人,英文凑合就行,实在看不下去的,请参考第一步。
4.3 先让Hadoop跑起来
Hadoop可以算是大数据存储和计算的开山鼻祖,现在大多开源的大数据框架都依赖Hadoop或者与它能很好的兼容。
关于Hadoop,你至少需要搞清楚以下是什么:
Hadoop 1.0、Hadoop 2.0 MapReduce、HDFS NameNode、DataNode
JobTracker、TaskTracker Yarn、ResourceManager、NodeManager
自己搭建Hadoop,请使用第一步和第二步,能让它跑起来就行。建议先使用安装包命令行安装,不要使用管理工具安装。另外:Hadoop1.0知道它就行了,现在都用Hadoop 2.0。
4.4 试试使用Hadoop
HDFS目录操作命令;上传、下载文件命令;提交运行MapReduce示例程序;
打开Hadoop WEB界面,查看Job运行状态,查看Job运行日志。知道Hadoop的系统日志在哪里。
4.5 你该了解它们的原理了
MapReduce:如何分而治之;HDFS:数据到底在哪里,什么是副本;Yarn到底是什么,它能干什么;NameNode到底在干些什么;ResourceManager到底在干些什么;
4.6 自己写一个MapReduce程序
请仿照WordCount例子,自己写一个(照抄也行)WordCount程序,打包并提交到Hadoop运行。你不会Java?Shell、Python都可以。如果你认真完成了以上几步,恭喜你,你的一只脚已经进来了。呐,下面是我Hadoop专题的系列博客,希望能帮助到你打怪兽哈!…(* ̄0 ̄)ノ
【Hadoop】(三)资源管理器 YARN 和分布式计算框架 MapReduce
【Hadoop】(四)Hadoop 序列化 及 MapReduce 序列化案例实操
【Hadoop】(五)MapReduce 如何解决数据倾斜问题
【Hadoop】(六)详解 HDFS 的数据流 (面试重点)
后面大数据技术栈的专题博客,我就不一一展开了,都是干货!
5. 数据仓库 Hive
这个东西对于会SQL语法的程序猿来说简直就是神器,它能让你处理大数据变的很简单,不会再费劲的编写MapReduce程序。
通过前面的学习,我们已经了解到了,HDFS是Hadoop提供的分布式存储框架,它可以用来存储海量数据,MapReduce是Hadoop提供的分布式计算框架,它可以用来统计和分析HDFS上的海量数据,而Hive则是SQL On Hadoop,Hive提供了SQL接口,开发人员只需要编写简单易上手的SQL语句,Hive负责把SQL翻译成MapReduce,提交运行。
简单点来说就是,Hive的底层是MapReduce,你只要写HQL(和SQL差不了多少)就完事了! Σ(っ °Д °;)っ
此时,你的“大数据平台”是这样的 ( •̀ ω •́ )✧

6. 数据采集 Sqoop / Flume / DataX
Sqoop主要用于把MySQL里的数据导入到Hadoop里的。当然你也可以不用这个,直接把MySQL数据表导出成文件再放到HDFS上也是一样的,当然生产环境中使用要注意MySQL的压力。
Flume是一个分布式的海量日志采集和传输框架,因为“采集和传输框架”,所以它并不适合关系型数据库的数据采集和传输。Flume可以实时的从网络协议、消息系统、文件系统采集日志,并传输到HDFS上。因此,如果业务有这些数据源的数据,并且需要实时的采集,那么就应该考虑使用Flume。
阿里开源的DataX也非常好用,有兴趣的可以研究和使用一下。
如果你完成了上面的学习,此时,你的“大数据平台”应该是这样的(^∀^●)ノシ
7. 快一点吧 Spark
其实大家都已经发现Hive后台使用MapReduce作为执行引擎,实在是有点慢。Spark SQL 应运而生,它是用来弥补基于MapReduce处理数据速度上的缺点,它的特点是把数据装载到内存中计算而不是去读慢的要死进化还特别慢的硬盘。
特别适合做迭代运算,所以算法流们特别稀饭它。它是用scala编写的。Java语言或者Scala都可以操作它,因为它们都是用JVM的。
你还需要:
-
掌握Spark的运行原理与架构,熟悉Spark的各种应用场景
-
掌握基于Spark RDD的各种算子的使用
-
掌握Spark Streaming针对流处理的底层原理
-
熟练应用Spark SQL对各种数据源处理
-
熟练掌握Spark机器学习算法库
-
达到能够在掌握Spark的各种组件的基础上,能够构建出大型的离线或实时的业务项目
是不是有些慌张,哈哈哈,慢慢学啊,Spark 超级重要!(;´д`)ゞ
对了,别忘啦,此时你顺便需要熟悉(掌握)两门新语言了,惊喜吧!(ಥ _ ಥ)

8. 数据传输 Kafka
这是个比较好用的队列工具,队列是干吗的?排队买票你知道不?数据多了同样也需要排队处理,这样与你协作的其它同学不会叫起来,你干吗给我这么多的数据(比如好几百G的文件)我怎么处理得过来。
你别怪他因为他不是搞大数据的,你可以跟他讲我把数据放在队列里你使用的时候一个个拿,这样他就不在抱怨了马上灰流流的去优化他的程序去了,因为处理不过来就是他的事情,而不是你给的问题。ㄟ( ▔, ▔ )ㄏ
这时,使用Flume采集的数据,不是直接到HDFS上,而是先到Kafka,Kafka中的数据可以由多个消费者同时消费,其中一个消费者,就是将数据同步到HDFS上。
目前 Flume + Kafka,在实时流式日志的处理非常常见,后面再通过Spark Streaming等流式处理技术,就可完成日志的实时解析和应用。
如果你完成了上面的学习,此时,你的“大数据平台”应该是这样的(^∀^●)ノシ
从前面的学习,已经掌握了大数据平台中的数据采集、数据存储和计算、数据交换等大部分技能,而这其中的每一步,都需要一个任务(程序)来完成,各个任务之间又存在一定的依赖性,比如,必须等数据采集任务成功完成后,数据计算任务才能开始运行。如果一个任务执行失败,需要给开发运维人员发送告警,同时需要提供完整的日志来方便查错。
10. 任务调度 Oozie / Azkaban
不仅仅是分析任务,数据采集、数据交换同样是一个个的任务。这些任务中,有的是定时触发,有点则需要依赖其他任务来触发。当平台中有几百上千个任务需要维护和运行时候,仅仅靠crontab远远不够了,这时便需要一个调度监控系统来完成这件事。调度监控系统是整个数据平台的中枢系统,类似于AppMaster,负责分配和监控任务。
你的“大数据平台”升级了 (ง •_•)ง!
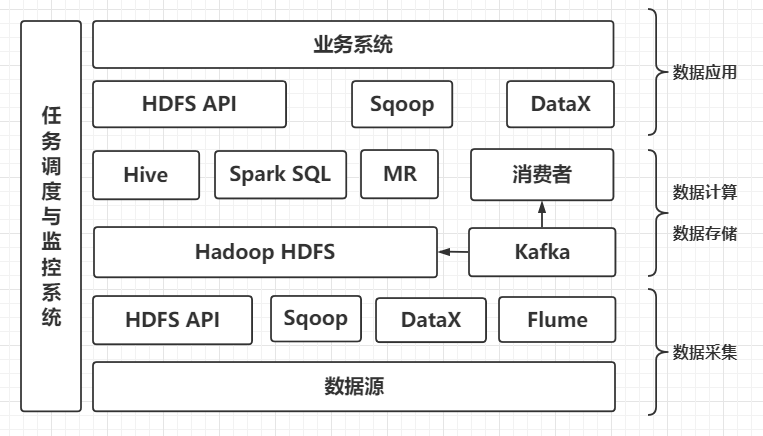
11. 实时数据的处理 Flink / Spark Streaming
在前面讲Kafka的时候提到了一些需要实时指标的业务场景,实时基本可以分为绝对实时和准实时,绝对实时的延迟要求一般在毫秒级,准实时的延迟要求一般在秒、分钟级。
对于需要绝对实时的业务场景,用的比较多的是Storm,对于其他准实时的业务场景,可以是Storm,也可以是Spark Streaming,简单业务场景 Kafka Streams 也能搞定,当然现在最火的是Flink 。
是不是晕了,这么多流式处理框架,我该怎么选择呢?::>_<::
看这里:Storm vs. Kafka Streams vs. Spark Streaming vs. Flink ,流式处理框架一网打尽!
你的“大数据平台”变得更加强大了 (●ˇ∀ˇ●)!
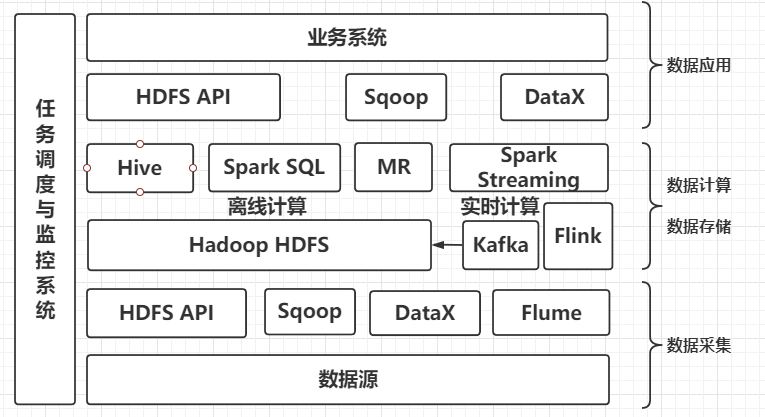
至此,你的大数据平台底层架构已经成型了,其中包括了数据采集、数据存储与计算(离线和实时)、数据同步、任务调度与监控这几大模块。接下来是时候考虑如何更好的对外提供数据了。
12. 数据对外(支撑业务)
离线:比如,每天将前一天的数据提供到指定的数据源(DB、FILE、FTP)等;离线数据的提供可以采用Sqoop、DataX等离线数据交换工具。
实时:比如,在线网站的推荐系统,需要实时从数据平台中获取给用户的推荐数据,这种要求延时非常低(50毫秒以内)。
根据延时要求和实时数据的查询需要,可能的方案有:HBase、Redis、MongoDB、ElasticSearch等。
分布式数据库HBase,这是Hadoop生态体系中的NOSQL数据库,它的数据是按照key和value的形式存储的并且key是唯一的,所以它能用来做数据的排重,它与MySQL相比能存储的数据量大很多。所以他常被用于大数据处理完成之后的存储目的地。
了解MongoDB及其它分布式数据库技术,能够掌握分布式数据库原理、应用场景、HBase数据库的设计、操作等,能结合Hive等工具进行海量数据的存储于检索。
OLAP分析:OLAP除了要求底层的数据模型比较规范,另外,对查询的响应速度要求也越来越高,可能的方案有:Impala、Presto、SparkSQL、Kylin。如果你的数据模型比较规模,那么Kylin是最好的选择。
即席查询:即席查询的数据比较随意,一般很难建立通用的数据模型,因此可能的方案有:Impala、Presto、SparkSQL。
这么多比较成熟的框架和方案,需要结合自己的业务需求及数据平台技术架构,选择合适的。原则只有一个:越简单越稳定的,就是最好的。
基于上述技术栈,你已经能完成一个大数据平台通用架构了,独当一面或许就是你吧 !
吨吨吨 ( ̄y▽, ̄)╭ !
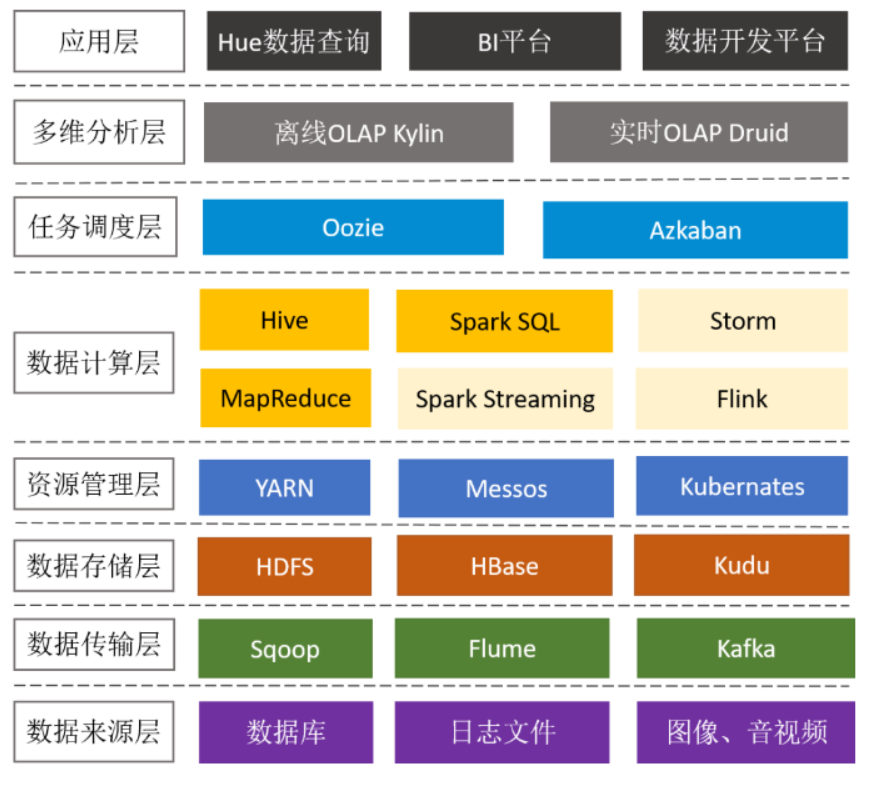
有些没提到的,我还在学,哈哈哈 (真的让人头秃啊 X﹏X)!
13. 机器学习 Spark MlLib
在我们的业务中,遇到的能用机器学习解决的问题大概这么三类:
- 分类问题:包括二分类和多分类,二分类就是解决了预测的问题,就像预测一封邮件是否垃圾邮件;多分类解决的是文本的分类;
- 聚类问题:从用户搜索过的关键词,对用户进行大概的归类。
- 推荐问题:根据用户的历史浏览和点击行为进行相关推荐。
大多数行业,使用机器学习解决的,也就是这几类问题。
入门学习线路:
-
数学基础(这里就要求数学好一点啦 =。=)
-
机器学习实战(Machine Learning in Action),前面学的Python派上用场了
-
Spark MlLib提供了一些封装好的算法,以及特征处理、特征选择的方法
机器学习确实牛逼高大上,也是我学习的目标。
至此,可以把机器学习部分也加进你的“大数据平台”了。
四、大数据下的数仓体系架构
数据仓库是从业务角度出发的一种数据组织形式,它是大数据应用和数据中台的基础。数仓系统一般采用下图所示的分层结构。
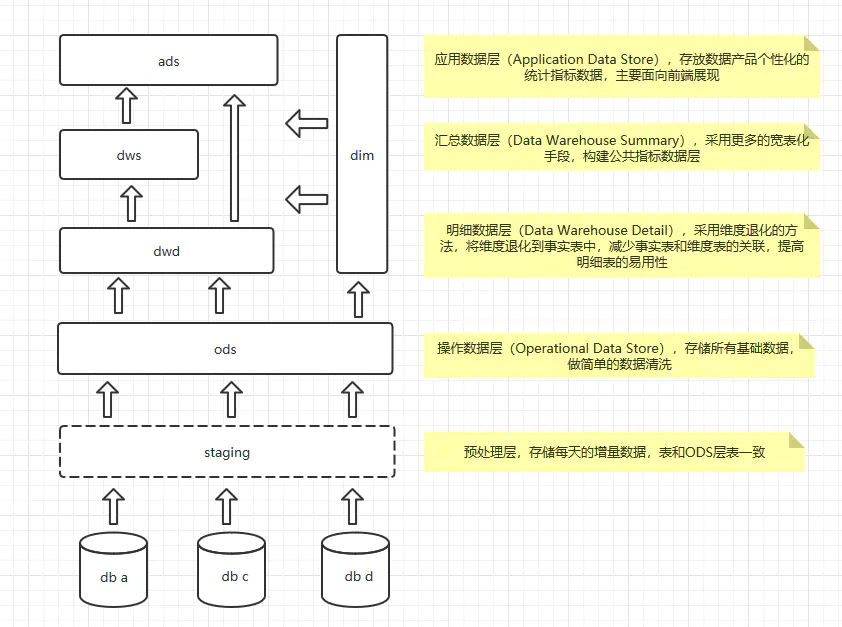
按照这种分层方式,我们的开发重心就在dwd层,就是明细数据层,这里主要是一些宽表,存储的还是明细数据;到了dws层,我们就会针对不同的维度,对数据进行聚合了,按道理说,dws层算是集市层,这里一般按照主题进行划分,属于维度建模的范畴;ads就是偏应用层,各种报表的输出了。
五、学习指南
首页,收下一本看书学习指南
其次,阿里云大数据 ACA 和 ACP (两个是阿里云的大数据认证,值得一考!)
——-> 阿里云大数据开发实践 系列专题 (又名我在阿里云的大数据开发之路 )
下面,是我用阿里云的大数据开发组件设计的一套系统架构图和数仓分层模型图(具体的设计思路,有机会我会和大家再细说) 。
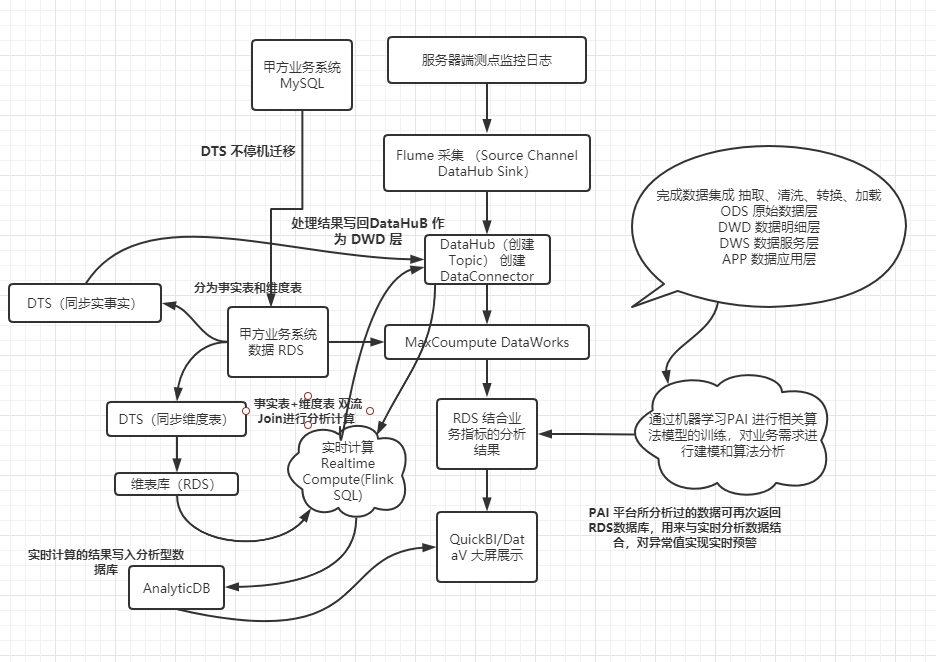
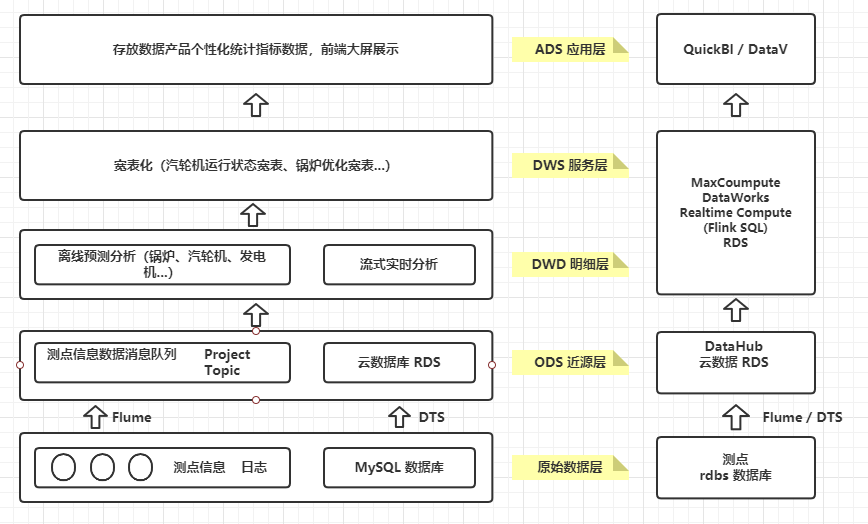
到这里,得强烈推荐阿里的这本书,《大数据之路:阿里巴巴大数据实践》 !精华大作啊!!
然后,看下前辈整理的大数据开源框架学习指南(很详细,我偷懒不想画了つ﹏⊂)
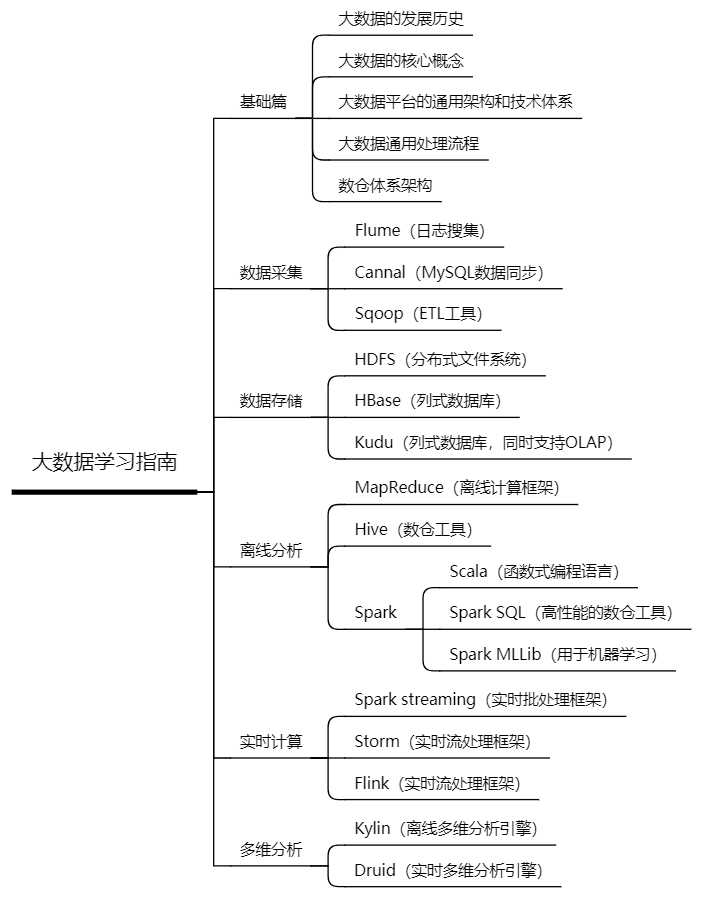
写在最后,毕竟博主入行也就两年时间。然后对于一些小伙伴的问题,我尽量,针对不同的人给一些不同的建议。
对应届生
个人觉得应届生应该打好基础,大学本科一般都会开设数据结构,算法基础,操作系统,编译原理,计算机网络等课程。这些课程一定要好好学,基础扎实了学其他东西问题都不大,而且好多大公司面试都会问这些东西。如果你准备从事IT行业,这些东西对你会很有帮助。
至于学什么语言,我觉得对大数据行业来说,Java还是比较多。有时间有兴趣的话可以学学Scala,这个语言写Spark比较棒。
集群环境一定要搭起来。有条件的话可以搭一个小的分布式集群,没条件的可以在自己电脑上装个虚拟机然后搭一个伪分布式的集群。一来能帮助你充分认识Hadoop,而来可以在上面做点实际的东西。你所有踩得坑都是你宝贵的财富。
然后就可以试着写一些数据计算中常见的去重,排序,表关联等操作。
然后我有个小伙伴,今年某211大数据专业毕业,刚来杭州实习两周就上线了两个数仓的任务了,我奉他为( ﹁ ﹁ ) ~→最强实习生(他和我得瑟,比他早来的实习生还在打杂…),哈哈哈。
对有工作经验想转行的
主要考察三个方面,一是基础,二是学习能力,三是解决问题的能力。
基础很好考察,给几道笔试题做完基本上就知道什么水平了。
学习能力还是非常重要的,毕竟写Javaweb和写Mapreduce还是不一样的。大数据处理技术目前都有好多种,而且企业用的时候也不单单使用一种,再一个行业发展比较快,要时刻学习新的东西并用到实践中。
解决问题的能力在什么时候都比较重要,数据开发中尤为重要,我们同常会遇到很多数据问题,比如说最后产生的BI数据对不上,一般来说一份最终的数据往往来源于很多原始数据,中间又经过了N多处理。要求你对数据敏感,并能把握问题的本质,追根溯源,在尽可能短的时间里解决问题。
基础知识好加强,换工作前两周复习一下就行。学习能力和解决问题的能力就要在平时的工作中多锻炼。社招的最低要求就上面三点,如果你平日还自学了一些大数据方面的东西,都是很好的加分项。
以上是个人的一些经历和见解,希望能帮到你 (๑•̀ㅂ•́)و✧。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/142775.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
