大家好,又见面了,我是你们的朋友全栈君。
如何处理大规模的快数据集
大数据指的是创建的数据和供分析的数据的数量与速率迅速增加。
此趋势的主要驱动因素是不断增加的信息数字化。采集设备的数量和类型以及其他数据生成机制无时无刻不在增加。
大数据源包括来自仪表传感器、卫星和医疗图像的流数据,来自安全摄像机的视频以及派生自金融市场和零售运营的数据。上述来源的大数据集可以包含千兆字节或百万兆字节的数据,并且每天以兆字节或千兆字节的级别增长。
大数据使分析师和数据专家有机会获得更好的见解,进行更明智的决策,但是它同时也会带来许多的挑战。可用的内存可能无法足以处理大数据集,可能需要花太久的时间进行处理或可能流动太快而无法存储。标准算法通常不能以合理的时间或内存来处理大数据集。没有任何一种单一方法可以处理大数据。为此,MATLAB 提供了许多工具来解决这些挑战。
在 MATLAB 中处理大数据
- 64 位计算。64 位版本的 MATLAB 可迅速增加内存中可保留的数据量——通常可达到任意 32 位程序的 2000 倍。32 位程序限制您只能使用 2 GB 的内存,而 64 位 MATLAB 的内存可以达到操作系统的物理内存限制。对于 Windows 8,台式机内存为 500 GB,Windows Server 内存为 4 TB。
- 内存映射的变量。 借助 MATLAB 中的memmapfile 函数,您可以将文件或文件的一部分映射到内存中的 MATLAB 变量。这样,您就可以高效访问磁盘上由于太大而无法保留在内存中或需要花太长时间而无法加载的大数据集。
- 磁盘变量。matfile 函数使您可以直接从磁盘上的 MAT 文件访问 MATLAB 变量(使用 MATLAB 索引命令),无需将全部变量加载到内存。这使您可以在大数据集上进行块处理,这些大数据集因为太大而无法保存在内存中。
- 内在的多核数学。MATLAB 中的许多内置数学函数,如fft、inv 和eig 都是多线程的。通过并行运行,这些函数充分利用计算机的多核,提供高性能的大数据集计算。
- GPU 计算。如果您正在使用 GPU,Parallel Computing Toolbox 中的GPU 优化的数学函数可以为大数据集提供更高的性能。
- 并行计算。Parallel Computing Toolbox 提供 并行 for 循环 , 该循环在多核计算机上并行运行您的 MATLAB 代码和算法。如果您使用MATLAB Distributed Computing Server,则可以在机器群集上并行执行,这些机器可扩展到数千台计算机。
- 云计算。对于数百或数千台计算机的按需并行处理,您可以在Amazon Elastic Computing Cloud(亚马逊弹性计算云)(EC2) 上使用 MATLAB Distributed Computing Server 并行运行 MATLAB 计算。借助云计算,您无需购买或维护您自己的群集或数据中心就可以处理大数据。
- 分布式阵列。 使用 Parallel Computing Toolbox 和 MATLAB Distributed Computing Server,您可以处理分布在计算机群集内存中的矩阵和多维数组。使用此方法,您可以针对因太大而无法由单台计算机内存处理的大数据集,进行存储和执行计算。
- 流式算法。 使用系统对象,您可以对因太大或太快而无法保留在内存中的数据传入流执行流式处理。此外,您还可以使用MATLAB Coder 通过 MATLAB 算法生成嵌入式 C/C++ 代码,并针对高性能实时系统运行产生的代码。
- 图像块处理。使用Image Processing Toolbox中的blockproc函数,您可以处理特别大的图像,方法是每次以模块的形式高效处理它们。与 Parallel Computing Toolbox 一起使用时,在多核和 GPU 上并行运行计算。
- 机器学习。机器学习有助于通过大数据集提取见解和开发预测性模型。广泛的机器学习算法,包括Statistics and Machine Learning Toolbox 和Neural Network Toolbox 中提供的促进式 (boosted) 和袋装 (bagged) 决策树、K 均值和分层聚类、k-最近邻搜索、高斯混合、期望最大化算法、隐马尔可夫模型和神经网络。
示例与具体方法
- 使用 MATLAB 处理大数据42:23(网络讲座)
- 利用 PCT 和 MDCS 进行内存中的大数据分析(博客)
- 用于可视化大型数据集的 Plot(大型)函数(文件交换)
- 使用 memmapfile 导航“大数据”二进制文件(Loren 谈 MATLAB 技巧博客)
- 处理“特别大的”图像:块处理(Steve 谈图像处理博客)
- 使用系统对象进行 MATLAB 中的流式处理(概述)
- Using Distributed Arrays to Process Large Matrices7:36(视频)
- 使用 SPMD 和分布式阵列求解大规模线性代数问题(文章)
应用示例
- Tesco 使用 Supply Chain Analytics 一年节省了一亿英镑(文章及相关)
- How Weather and Pricing Affect Sales: Using MATLAB to Improve Tesco’s Supply Chain23:51
- Naturalistic 汽车驾驶数据处理和分析(文章及相关 )
- Data Processing Framework Supporting Large-Scale Driving Data Analysis30:38
- Listening to the World’s Oceans: Searching for Marine Mammals by Detecting and Classifying Terabytes of Bioacoustic Data in Clouds of Noise51:32(网络讲座)
- Edwards Air Force Base 加速了大规模飞机测试数据的分析(用户案例)
- 通过高性能计算进行地震数据处理(概述)
- 生态系统如何影响区域气候建模(文章)
软件参考
- 在 MATLAB 中高效使用内存的策略(文档)
- MATLAB 中内存映射概述(文档)
- 大型 Multi-Entry 文本文件(FASTA、FASTQ、SAM)(文档)
- Image Processing Toolbox 中的相异块处理(文档)
====================================================================================
上面是matlab官网的一些相关介绍。
其中在编程中用到的几个重要函数:
1、Matlab内存映射文件
在maltab程序中,经常需要读取一些.mat格式的数据文件,如果文件非常大,内存装不下或者加载时间过长,我们可以通过matlab提供了内存映射文件机制(memroy mapped file)[1]来解决这一问题。内存文件映射是一种内存管理方法,应用程序可以通过内存指针对磁盘上的文件进行访问,从而不需要预先将整个文件加载到内存中去。
Matlab内存映射文件的语法格式如下:
m = memmapfile(filename)
m = memmapfile(filename, prop1, value1, prop2, value2, …)
memmapfile(filename)创建了一个默认参数的内存映射文件,而m = memmapfile(filename, prop1, value1, prop2, value2, …)创建一个指定参数的内存映射文件,参数设置见下表1,最后一列Default表示参数默认值,其中Repeat属性中的inf表示顺序读取文件直至文件末尾,映射的内存数据可通过m.Data属性来访问。
表1. Matlab memmapfile参数列表

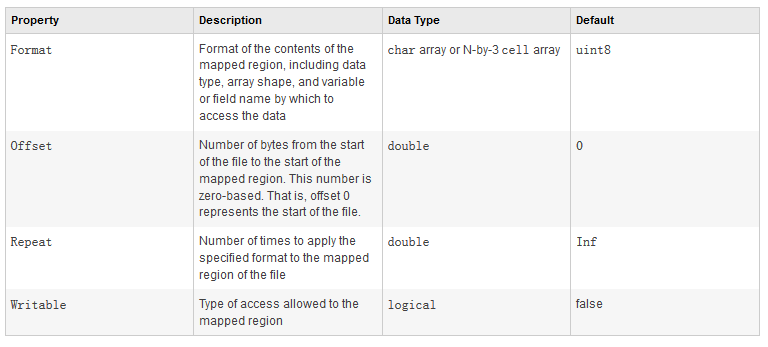
调用示例:
首先创建一个5000*1维的double数组并保存,gallery是一个maltab测试函数,返回给定参数的测试数组。
randData = gallery('uniformdata', [5000, 1], 0, 'double');
fid = fopen('records.dat','w');
fwrite(fid, randData, 'double');
fclose(fid);
Example 1 创建默认内存映射文件
m = memmapfile('records.dat');
Example 2 创建指定参数的内存映射文件
设置offset、Format和Writeble属性,,注意最后得到了一个9744*1的uint32数组,总共是38976字节,加上offset刚好等于5000个double数组的总字节数。
m = memmapfile('records.dat', ...
'Offset', 1024, ...
'Format', 'uint32', ...
'Writable', true);
Type the object name to see the current settings for all properties:
m =
Filename: 'd:\matlab\records.dat'
Writable: true
Offset: 1024
Format: 'uint32'
Repeat: Inf
Data: 9744x1 uint32 array
Example 3 映射对象
将record.dat文件映射成对象,该对象拥有一个4*10*8 uint32数组成员,变量名为x,,可以通过m.Data(*).x进行访问,*表示index.
m = memmapfile('records.dat', ...
'Offset', 1024, ...
'Format', {'uint32' [4 10 18] 'x'});
A = m.Data(1).x;
whos A
Name Size Bytes Class
A 4x10x18 2880 uint32 array
Example 4 映射复杂对象
复杂对象拥有model,serialno,expenses三个属性,读取1000次。
m = memmapfile('records.dat', ...
'Format', { ...
'int16' [2 2] 'model'; ...
'uint32' [1 1] 'serialno'; ...
'single' [1 3] 'expenses'}, ...
<strong>'Repeat', 1000</strong>);2、硬盘访问.mat文件
Matlab程序中经常要访问.mat文件,通常在作法是用load函数直接加载.mat文件。如果.mat文件非常大,超过了系统可用内存的时候该怎么办呢?Matlab2013b为提供了matfile函数,matfile函数可以通过索引直接访问.mat文件中的Matlab变量,而无需将.mat文件加载入内存。
matfile有两种用法:
m = matfile(filename),用文件名创建matfile对象,通过这个对象可以直接访问mat文件中的matlab变量。
m = matfile(filename,’Writable’,isWritable),isWritable开启或关闭文件写操作。
使用示例:
1. 向mat文件中写入变量
x = magic(20);
m = matfile(‘myFile.mat’); % 创建一个指向myFile.mat的matfile对象
m.x = x; % 写入x
m.y(81:100,81:100) = magic(20); % 使用坐标索引
2. 加载变量
filename =‘topography.mat’;
m = matfile(filename);
topo = m.topo; %读取变量topo
[nrows,ncols] = size(m,‘stocks’); %读取stocks变量的size
avgs = zeros(1,ncols);
for idx = 1:ncols
avgs(idx) = mean(m.stocks(:,idx));
end
3. 开启写权限
filename =‘myFile.mat’;
m = matfile(filename,‘Writable’,true);
或者
m.Properties.Writable = true;
3、处理任意大图像的blockproc函数
新版本的MATLAB推出了可以处理任意大图像的函数blockproc,其用法如下:
B = blockproc(A,[M N],fun)
B = blockproc(src_filename,[M N],fun)
B = blockproc(adapter,[M N],fun)
blockproc(...,param,val,...)A是要处理的图像矩阵,如果图像太大不能完全导入内存,也可以用图像文件名src_filename来表示。[M,N]是希望每次分块处理的矩阵大小,fun是函数句柄,即对每块矩阵的处理函数。
需要说明的是blockproc默认支持tiff/tif和jpeg2000格式的任意大图像处理,如果要读取其他格式的大图像需要针对该图像格式再写一个继承自MATLAB中ImageAdapter这个抽象类的子类adapter,来满足blockproc的输入要求。MATLAB帮助文档中有一个读取lan格式的LanAdapter示例类,大家可以参照那个格式来构造任意图像格式的Adapter类来实现blockproc函数对任意大图像文件的支持。
最后一种调用格式可以实现读取大图像文件,分块处理后再在指定路径写入处理后的图像文件,这个非常有用。
fun = @(block_struct) repmat(block_struct.data,5,5) ;
%注意处理函数的输入必须是结构体,其data域是我们的矩阵数据,这是由blockproc分块后的机制决定
blockproc('moon.tif',[16 16],fun,'Destination','C:\moonmoon.tif');
imshow('C:\moonmoon.tif')
可以看到分块处理后的效果,当然这是简单的把原图像分块(每一子块大小16*16)复制了25倍后的效果。
4、nlfilter函数
功能:用来执行通用的滑动邻域操作。
用法:
B = nlfilter(A,[m n],fun)
B = nlfilter(A,[m n],fun,P1,P2,...)
B = nlfilter(A,'indexed',...)
B = nlfilter(A,[m n],fun)对图像A的每个大小为m*n的patch进行fun函数的操作,patch的取法为滑动(sliding),即patch的中心像素遍历图像的每个点,当取到边界时需要进行边界延拓。fun必须是函数的句柄,可自由定义也可取matlab内置的函数。例如fun函数必须接受m*n块作为输入,并返回一个标量y,形如:
c=fun(x)
c为m*n块x的中心像素点的输入值。
例子:B = nlfilter(A,[3 3],@myfun);
其中myfun是以m文件如下:
function scalar = myfun(x)
scalar = median(x(:));
5、colfilter函数
调用格式:B = colfilt(A,[m n],block_type,fun)
意为将图像A重排成每列为m*n块拉成一列组成的临时矩阵,对该临时矩阵进行fun函数的操作。
例:
对图像的I的每个5*5邻域进行取标准差的运算 :I2 = uint8(colfilt(I,[5 5],’sliding’,@std));
另:
在调用fun函数处理前,colfilt先调用了im2col生成了临时矩阵,调用fun函数处理之后,又调用col2im将成列的矩阵重排为块。
colfilt与blockproc及nlfilter相比,用法类似,但速度更快。
6、padarray函数
功能:填充图像或填充数组。
用法:B = padarray(A,padsize,padval,direction)
A为输入图像,B为填充后的图像,padsize给出了给出了填充的行数和列数,通常用[r c]来表示。padval和direction分别表示填充方法和方向。它们的具体值和描述如下:
padval:
'symmetric'表示图像大小通过围绕边界进行镜像反射来扩展;
'replicate'表示图像大小通过复制外边界中的值来扩展;
'circular'图像大小通过将图像看成是一个二维周期函数的一个周期来进行扩展。
direction:
'pre'表示在每一维的第一个元素前填充;
'post'表示在每一维的最后一个元素后填充;
'both'表示在每一维的第一个元素前和最后一个元素后填充,此项为默认值。
若参量中不包括direction,则默认值为'both'。若参量中不包含padval,则默认用零来填充。若参量中不包括任何参数,则默认填充为零且方向为'both'。在计算结束时,图像会被修剪成原始大小。
举例:
A = [1 2; 3 4];
B = padarray(A,[3 2],'replicate','post')
7、repmat
即 Replicate Matrix ,复制和平铺矩阵,是 MATLAB 里面的一个函数。repmat( )函数的作用主要是利用了类似分治算法构造矩阵的思想、给出一个小规模矩阵,按指定要求构造出一个大矩阵
B = repmat(A,m,n)
B = repmat(A,[m n])
B = repmat(A,[m n p...])
一、repmat(NaN,m,n)等价于NaN(m,n).
二、repmat(single(inf),m,n)等价于inf(m,n,'single').
三、repmat(int8(0),m,n)等价于zeros(m,n,'int8').
四、repmat(uint32(1),m,n)等价于ones(m,n,'uint32').
五、repmat(eps,m,n)等价于eps(ones(m,n)).B = repmat(A,m,n)
8、左除和右除
在matlab中,如果有以下操作:
Inv(A)*B, 建议用左除A\B代替。
A右除B,相当于A右乘B的逆矩阵,A左除B,相当于A的逆矩阵左乘B
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/142490.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
