大家好,又见面了,我是你们的朋友全栈君。
数据产品和数据密不可分作为数据产品经理理解数据从产生、存储到应用的整个流程,以及大数据建设需要采用的技术框架Hadoop是必备的知识清单,以此在搭建数据产品时能够从全局的视角理解从数据到产品化的价值。本篇文章从三个维度:
1.大数据的处理流程
2.大数据的的平台框架Hadoop
3.Hadoop生态圈组件
理解了数据从产生到场景应用每个环节的流程过程以及企业在建立大数据平台时需要采用的技术框架Hadoop以及生态圈中60多个组件的功能作为数据产品经理才算是入门并非是要深层次的理解技术,一方面建立数据全局视角当业务数据出现问题时能够准确诊断到底是哪个环节出现问题,是数据源出现问题,还是数据查询逻辑的问题, 另外一方面数据产品化需要理解背后的运行原理和逻辑。
一大数据的处理过程:
1.数据生产
2.数据采集
3.数据预处理
4.数据储存
5.数据挖掘、统计与分析
6.数据ETL与存储关系系数据库
7.数据可视化
以上是数据流转的整个过程包括了7个环节,从数据的生产到数据储存再到数据可视化应用的全局过程。下图为数据处理全过程:
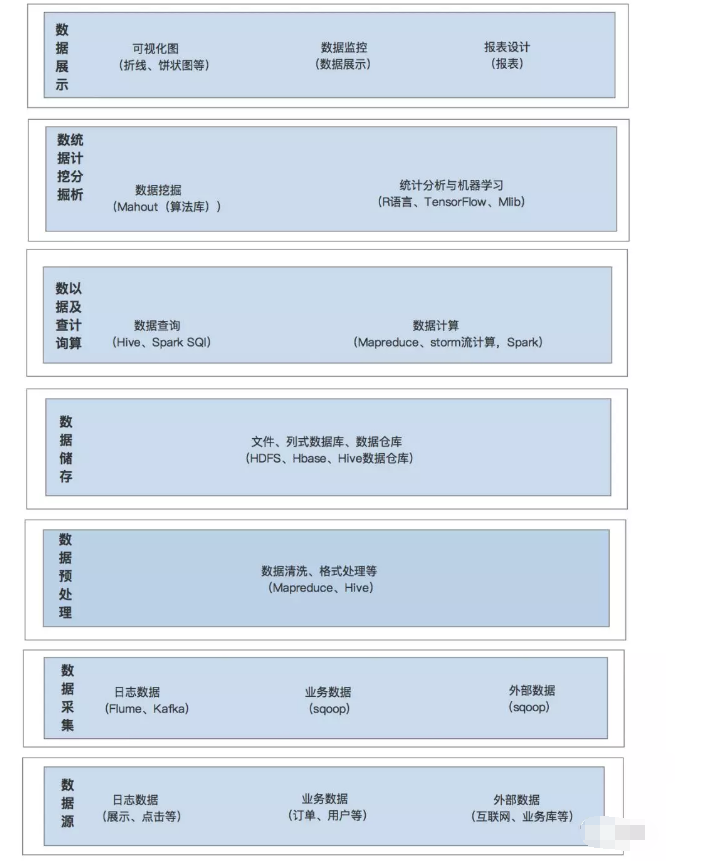

1数据生产
数据生产过程中主要有三大数据源:日志数据、业务数据库、互联网数据
日志数据:企业提供给用户产品,用户与产品互动后会产生日志数据,通过Flume进行收集后上传到HDFS文件系统中进行离线处理,同时数据上传至Kafka消息对列中时作为数据进行缓冲以及实时处理
业务数据:业务数据包括企业自身产生的业务数据比如用户数据、订单数据等等,同时也包括第三方的企业提供的关系型数据。通过Sqoop导入导出至HDFS分布式文件系统或关系型数据库中。如果你对大数据开发感兴趣,想系统学习大数据的话,可以加入大数据技术学习交流扣扣君羊:522189307
互联网数据:主要是使用爬虫在互联网网页、平台上提供的API爬取数据包括结构化、半结构化、非结构化数据,然后通过ETL数据清洗后保存为本地网页数
2数据采集
数据采集使用到的组件主要有Flume、Sqoop、Kafka三个工具,Flume主要用于日志数据采集,Sqoop主要用于与关系型数据库进行数据的导入导出,Kafka消息队列主要运用于实时数据的采集
3数据预处理
数据采集后会通过mapreduce,Hive对数据进行初步的预处理包括:数据清洗、数据拼接、数据格式处理等后会将数据储存在HDFS分布式文件以及Habses类关系型数据库当中。
4数据储存
主要通过三种形式对数据进行数据储存包括:HDFS分布式文件、Hbase、数据仓库。其中Hbase、和数据仓库都是基于HDFS文件的基础上建立的,Hbase的数据存储格式是按照始的文件列式数据存储的,数据仓库是按照多维数组形成的多个表存储的,而HDFS是按照文件的方式储存。
5数据查询与计算
数据查询的组件是Hive、SparkSql。Hive的原理是它能接收用户输入的类sql语句,然后把它翻译成mapreduce程序对HDFS上的数据进行查询、运算,并返回结果,或将结果存入HDFS。SparkSql兼容Hive同时处理效率比Hive高出多陪。
数据计算的框架是Hadoop(批处理)、Spark(实时流处理)、Storm(实时流处理)。Hadoop的核心由HDFS分布式文件系统和MapReduce编程框架组成,其中Mapreduce作为计算的组件,Storm的数据则像水流一样源源不断流入,并对其做实时处理。Spark的核心数据处理引擎依然是运行MapReduce计算框架。
6数据挖掘与统计分析
数据挖掘的工具有Madout、MLlib,Madout是构建在Hadoop上的数据挖掘工具包含多个算法模型库,MLlib是构建在Spark上的分布式数据挖掘工具,利用Spark的内存计算,MLlib是Spark对常用的数据挖掘算法的实现库包括分类、回归、协同等算法模型,同时包括相关的测试和数据生成器。
数据统计分析主要是通过类SQL语句进行查询、计算、汇总后来实现统计的比如通过Mapreduce进行的汇总。
7数据应用
数据最终的价值是数据应用到某个领域、某个产业对其进行赋能比如:降本增效、风险预警、产品优化等。实现上述的功能主要是通过数据产品实现包括不限于企业自身的BI系统、商业性的数据产品比如神策、GoogleIO等。后台数据产品三大类。而数据产品的构成包括:报表设计、可视化试图、数据监控。
二、大数据的的平台框架Hadoop
我们先看Hadoop大数据平台框架的历史,然后介绍平台框架的构成:
2004年
Google前后发表三篇论文,也就是传说中的“三驾马车”
-
分页式文件系统GFS
-
大数据分布式计算框架MapReduce
-
NoSQL数据库系统BigTable
2006年
Doug Cutting启动了一个赫赫有名的项目Hadoop,主要包括Hadoop分布式文件系统HDFS和大数据计算引擎MapReduce,分别实现了GFS和MapReduce其中两篇论文
2007年
HBase诞生,实现了Big Table最后一篇论文
2008年
出现 了Pig、Hive,支持使用SQL语法来进行大数据计算,极大的降低了Hadoopr的使用难度,数据分析师和工程师可以无门槛地舒不舒服和大数据进行数据分析和处理
2012年
Haddop将执行引擎和资源调度分离出来,成立了Yarn资源调度系统,这年Spark也开始崭露头角,逐步替代MapReduce在企业应用中的地位。
下图为Hadoop大数据框架的构成:
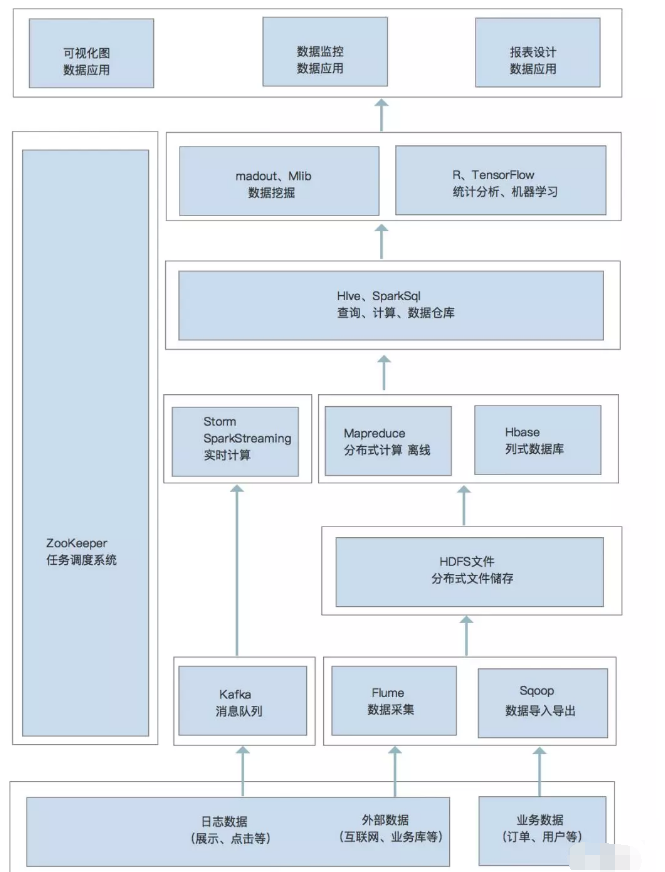
基本的框架是Hadoop三驾马车由HDFS分布式文件储存系统、Mapreudce分布式计算框架、Hbase列式数据库构成,当然上层需要数据仓库查询工具Hive、Pig等构成组成较为完成的大数据平台框架。
三、Hadoop生态圈组件
Hadoop生态圈共60多个组件构成形成了一个完成的大数据框架,企业会依据自身的发展情况选择不同的组件建立适合自身的大数据架构,接下来介绍Hadoop生态圈中各个组件的功能:
1.Sqoop
sqoop 是一款开源的工具,主要用于在 Hadoop(Hive)与传统的数据库(mysql)间进 行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中
2.Flume
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚 合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
3.Kafka
Kafka是由LinkedIn开发的一个分布式的消息系统,用来做实时数据的采集,也经常用来当作缓冲组件。主要用于实时的数据流处理
4.Storm
Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时 处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。Storm 也可被用于“连 续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式
输出给用户。
5.Spark
Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数据进行计 算。
6.Spark Streaming
Spark Streaming支持对流数据的实时处理,以微批的方式对实时数据进行计算。
7.Hbase
HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8.Hive
hive 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张 数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的MapReduce 应用,十分适合数据仓库的统计分析。
9.Mahout
Apache Mahout是个可扩展的机器学习和数据挖掘库,当前Mahout支持主要的4个用 例: 推荐挖掘:搜集用户动作并以此给用户推荐可能喜欢的事物。聚集:收集文件并进行相关文件分组。分 类:从现有的分类文档中学习,寻找文档中的相似特征,并为无标签的文档进行正确 的归类。频繁项集挖掘:将一组项分组,并识别哪些个别项会经常一起出现
10.Zookeeper
Zookeeper 是 Google 的 Chubby 一个开源的实现。它是一个针对大型分布 式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper 的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效,功能 稳定的系统提供给用户。
11.Oozie
Oozie 是一个管理Hdoop作业(job)的工作流程调度管理系统。Oozie 协调作业 就是通过时间(频率)和有效数据触发当前的Oozie 工作流程。
以上是大数据处理的全流程、Hadoop大数据架构以及各个组件的介绍这部分也仅仅是最基础的部分,当然对于数据产品经理仅需了解数据流程过程以及架构的基本原理即可,能够和数据开发进行有效的沟通,能够诊断数据发生异常时是哪个环节出差错即可。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/142383.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
