大家好,又见面了,我是你们的朋友全栈君。
1.0 连接查询—多表查询
数据库已有的表和里面的内容

1. 等值连接与非等值连接
什么叫等值连接呢?
就拿上面的的student 表与 SC表来说 我们把他们合到一起 可以比较的列在一起进行比较,如果值相等,那么这列的元素所在的 行就会合并
eg:
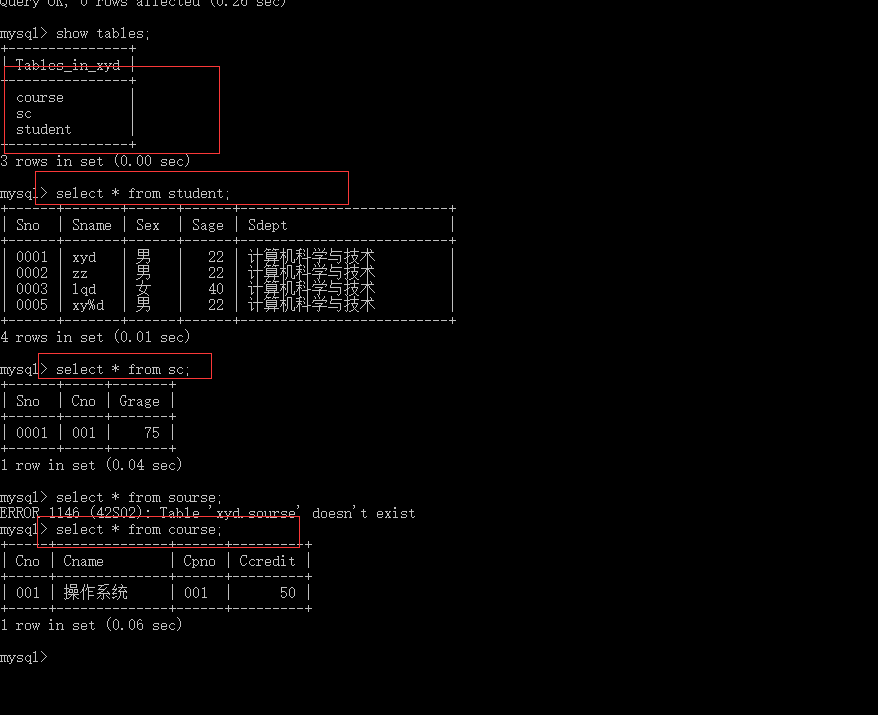
select student.* ,SC.* from student ,sc where student.Sno = Sc.Sno;
可以看出来 Sno 的值相等的行合并为一行了
等值连接的过程是 我们在student表中的一个字段,去Sc表扫描每一行,满足条件就输出,知道扫描完成,
这是一种可能情况,也叫嵌套循环连接算法 我们可以用建立索引来提高效率
什么叫非等值连接呢?
还是上面的例子 简单的来说就是满足不等条件的放在一行
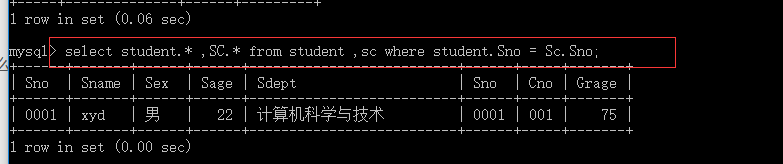
select student.* ,SC.* from student ,sc where student.Sno > Sc.Sno;
一种可能的比较方法是 student中每一个Sno 的值与sc表的第一个元素比较 等student.Sno 的值都与Sc.sno 第一个值比较完成后,在与下一个值比较,以此类推 满足条件就是一行
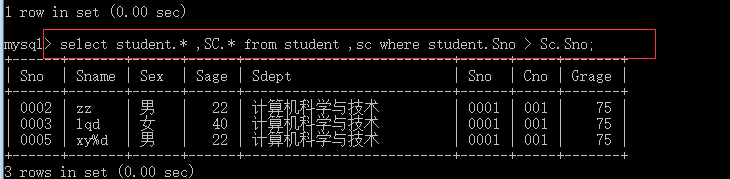
为了满足接下来的例子 插入数据后的三张表如下
eg: select student.,sc. from student,sc where student.sno>sc.sno;
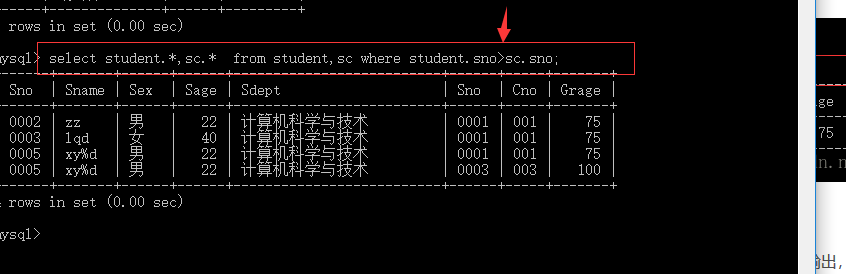
数据我已经插入了,注意因为sc含有表级完整性约束 也就是外键 所以应该先插入course 在插入sc表,否则插不进去
至于原因很简单 既然SC表的cno 是参照course的,那么course要是没有cno与sc 相等的,那肯定差不进去呗
自然连接
我们在进行等值连接的时候 student.Sno 和sc.sno 数值是一样 显=显示两遍了 让他只显示一遍就是自然连接
select A.sno,A.sname,A.sex,A.sage,A.sdept,B.cno,B.grage from student A,sc B where A.sno = B.sno;

其中 A B 是分别起的别名
2. 自身连接
顾名思义 就是自己和自己连接 ,为了区分用到的是哪个自己 要起别名
select A.sno,A.sname,A.sex,A.sage,A.sdept, B.sno,B.sname,B.sex,B.sage,B.sdept from student A,student B where A.sno > B.sno;

select A.sno,A.sname,A.sex,A.sage,A.sdept, B.sno,B.sname,B.sex,B.sage,B.sdept from student A,student B where A.sno = B.sno;

3.0 外连接 分为左外连接与右外链接
外链接与正常连接的区别是 通常的连接只会输出满足条件的连接 不满足的不会输出
例如上面的自然连接的例子中 学号为002的学生并没有显示出来 因为他不符合要求,左连接就是保留左边表的左右数据,连接的表如果没有就是null
语句格式是 left outer join 表明 on(..) ;
eg: select * from student left outer join sc on(student.sno = sc.sno);

右链接就是保存右表的所有数据 right outer join 表明 on();
4.0 多表连接 查询每个小学生的学号 姓名 年龄 性别 课程 课程号
select * from student a,sc b,course c where a.sno = b.sno and b.cno = c.cno;

2.0 嵌套查询
在sql语言中 有个 select .. from … where .. 叫做查询块
把一个查询快放在另一个查询块的where或者 having子句中的查询叫做嵌套查询
1. 带有 in谓词的子查询
因为子查询出来的往往是一个集合,所以in是嵌套查询中最常用的谓词
例如:我们查询与xyd 在同一个系的学生
大致分为以下几步:
1.0 查询xyd在哪个系?
select Sdept from student where Sname = ‘xyd’;
结果是计算机科学与技术
2.0 查询这个系都有哪些学生
select Sname from student where Sdept = ‘计算机科学与技术’;
这样就查出来了 然后我们进行嵌套
select Sname from student where Sdept in(select Sdept from student where Sname = ‘xyd’) ;
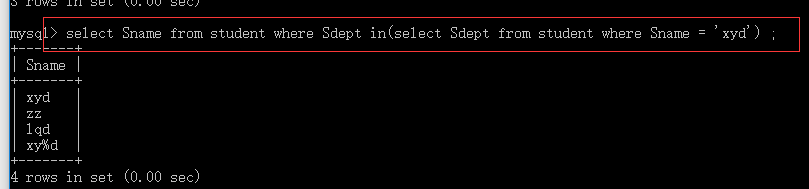
子查询的条件与父查询无关 叫做不相关子查询
这件事也可以用连接查询来查询
select B.Sname from student A,Student B where A.sdept = B.sdept and A.sname = ‘xyd’;
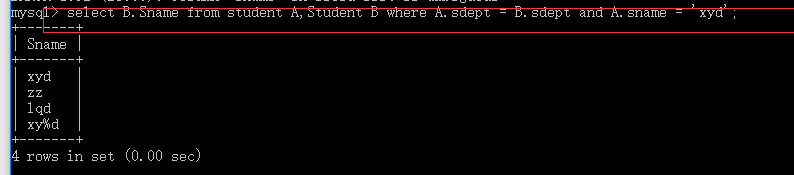
这就涉及到数据库调优的知识了,由于嵌套查询的调优技术还没有成熟,所以我们能用连接查询就用连接查询
2. 带有比较运算符的子查询
因为一般我们子查询的结果是个集合,索引要用in 但是当我们知道子查询的结果是单个值得时 就可以不用in了,
可以用 < > = 等比较运算符运算
例如上面的例子select Sname from student where Sdept in(select Sdept from student where Sname = ‘xyd’) ; 我们查询的只能是一个值 所以就可以用 = 了
eg:变为select Sname from student where Sdept = (select Sdept from student where Sname = ‘xyd’) ;

上面我们讲了什么叫做不相关子查询,
如果子查询的查询条件与父查询有关就叫做相关子查询
eg:查询每个学生超过他选修课程平均成绩的课程号
select Sno,Cno from Sc x where Grade > (select avg(grade) from sc y where y.sno = x.sno);
上述SQL的一种可能执行过程是这样的
- 首先查询x.sno 假设找到的是1
- 然后执行 select avg(grade) from sc y where y.sno = 1;
- 假设结果设80
- 然后执行 select Sno,Cno from Sc x where Grade > 80;
- 回到1 找到下一个 x.sno 假设2
- 重复执行1-5 知道 x表中的Sno 全部查询完毕
我们看到子查询的y.sno 的值依赖于父查询的x.sno 这就叫做相关子查询
由此我们可以看出来 求解相关子查询的时候不能像不相关子查询那样一次性把子查询结果求出来,然后在求解父查询 因为相关子查询与父查询有关,所以必须反复进行子查询 而不是子查询这次完事后就不用了
3. 带有any或者all 谓词的子查询
我们用比较运算符的时候,只能在返回值是一个的时候用,并且 单个值得时候 = 和in 的左右是一样的,但是你不能用 in 代替
< > 那返回多值得时候 假设返回的是1-100之间的数,但是我只想要大于结果集中所有数的怎么办呢?
这就是要带有any 和all 的子查询
any 和 all 什么意思怎么用呢? 看下表:
使用 any或者all的时候必须配合比较运算符 并且有的数据库不用any 用some
| 谓词 | 解释 |
|---|---|
| >any | 大于子查询结果集中的某个值 |
| >all | 大于子查询结果集中的所有值 |
| < any | 小于子查询结果集中的某个值 |
| < all | 小于子查询结果集中的所有值 |
| >=any | 大于等与子查询结果集中的某个值 |
| >=all | 大于等与子查询结果集中的所有值 |
| <=any | 小于等于子查询结果集中的某个值 |
| <=all | 小于等于子查询结果集中的所有值 |
| =any | 等于子查询结果集中的某个值 |
| =all | 等于子查询结果集中的所有值 |
| !=any | 不等于子查询结果集中的某个值 |
| !=all | 不等于子查询结果集中的所有值 |
eg:查询student中年龄小于最大值得所有人
select sname,sage from student where sage < any (select sage from student);
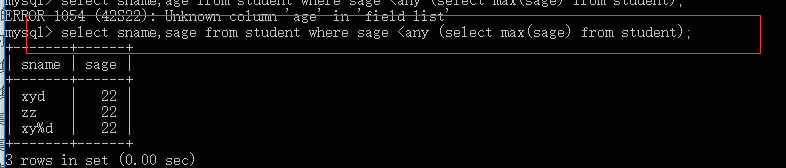
上述SQL也可以用聚集函数来查询
select sname,sage from student where sage < (select max(sage) from student);
结果是一样的 但是聚集函数的查询效率要高 聚集函数和any或者all的对应关系如下
| = | < | > | != 或者 <> | <= | >= | |
|---|---|---|---|---|---|---|
| any | in | < max | > min | – | <= max | >= min |
| all | – | < min | >max | not in | <= min | >= max |
4. 带有exists 的子查询
exists 代表存在量词 的意思 返回值是true 或者false
我们可以用它判断是否属于这个集合,是否是子集,两个集合是否相等 交集是否为空
我们查询所有选修了005号课程的学生
select sname from student where exists (select * from Sc where sc.sno = student.sno and cno = ‘001’);
结果应该是空
select sname from student where exists (select * from Sc where sc.sno = student.sno and cno = ‘001’);

第一个语句返回的是false 也就是 where后是false 第二个是where true
因为子查询只显示真假 所有我们一般select后面跟* 号 因为写列名无意义
我们还可以用存在量词表示全称量词,这里不深入了
3.0 集合查询
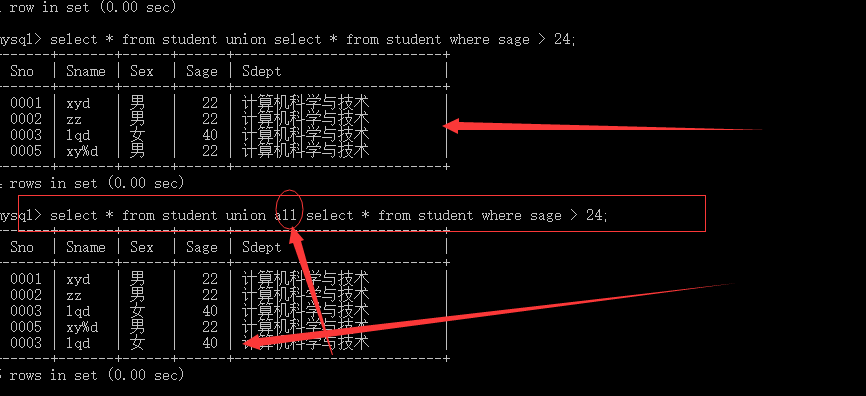
就是实现的集合的运算 主要有 交集 intersect 并集 union 差集except
用法一样 只举一个例子:
eg; 查询student 表中所有人和年龄大于24的人
select * from student union select * from student where sage > 24;
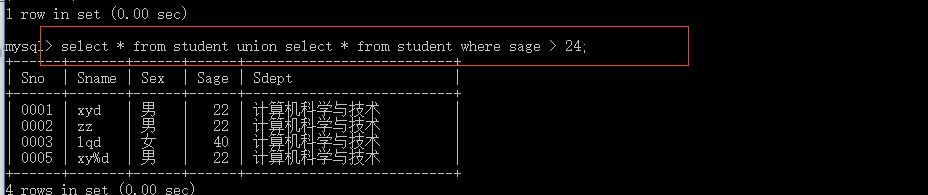
这实际就是求 查询student 表中所有人和年龄大于24的人 的并集 系统会自动除去重复元素,如果不想除去 可以用 union all
4.0 基于派生表的查询
子查询除了可以放在where 或者 having 后面 还可以放在from 后面 这时候子查询出来的表叫做派生表 我们必须要为派生表起别名
例如
select * from student; 的结果如下
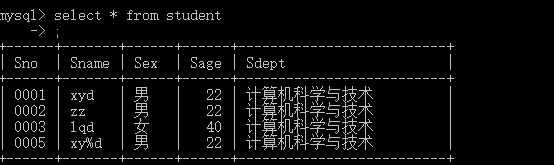
我们在这个基础上查询年龄等于22的所有人的名字:
select A.Sname from (select * from student) A where A.Sage = 22;
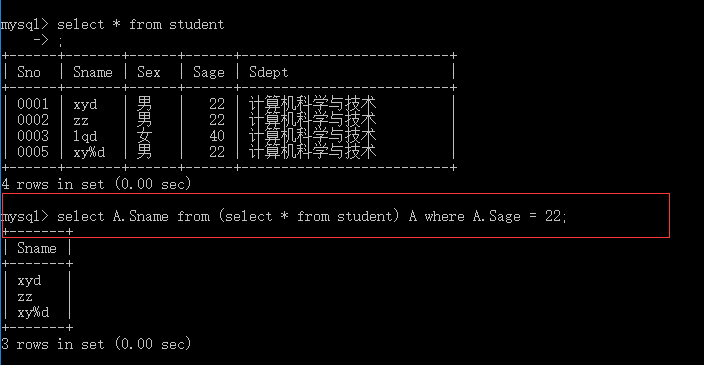
这里的A就是别名
select A.Sname from (select * from student) as A where A.Sage = 22
as 可以省略 也是起别名的方式
5.0 select 语句的一般格式(中括号为可选项)
select [distinct|all] 目标列表达式 别名 ,目标表达式 别名 。。。
from 视图或者表 别名,视图或者表 别名 。。。 (子查询) [as] 别名
[where 条件表达式]
[group by 列名 having 条件表达式]
[order by 列名asc|desc ] /升序,降序 /
5.1 目标列表达式的一般格式:
*
列名
表名.列名
字符串
算数表达式
聚集函数
5.2 聚集函数的一般格式
count ( [ distinct | all ] 列名)
5.3 where子句表达式的可选格式
5.3.1 属性列名 算数表达式 属性列名|常数|[any|all] 子查询语句
5.3.2 [not ]between。。。and ..
5.3.3 not in()
5.3.4 not like
5.3.5 is null
5.3.6 exists
5.3.7 and or
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/142066.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
