大家好,又见面了,我是你们的朋友全栈君。
目 录
1. 概 念
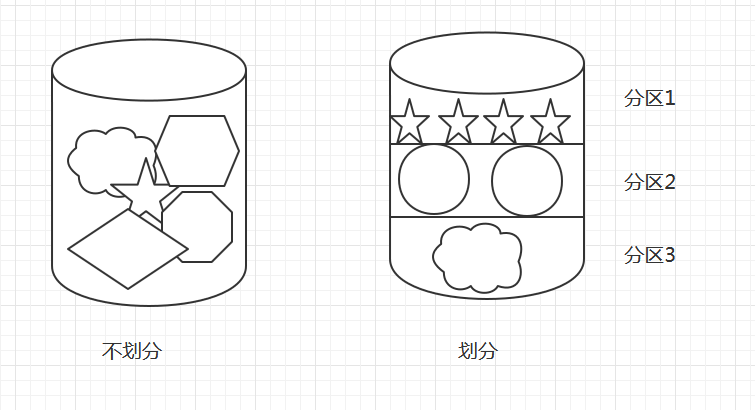

图1.1 分区的概念
假如你有个大木桶要装东西,如果木桶没有划分层,所有东西全部放入里面,虽然可以装,但是对大木桶的使用就合不合理,造成杂乱无章,寻找东西时候也耗时,甚至还有不同物品之间不能存放在一起而导致危险,那更好的做法自然是给大木桶画一下不同的区域,分成不同的层,每个层放不同的东西,即安全,寻找起来也方便;
计算机的磁盘(也叫硬盘)也是如此,为了区分存储内容的不同,以及快速定位寻址文件,也需要采取分区的形式;
2. 为啥要分区
不论磁盘的分区还是数据库表的分区以及其它的分区,核心思想和分区的目的基本都一致,可以概括以下两点原因;
-
数据的安全性隔离:因为每个分区是独立分开的,所以当你需要重现格式化或数据重新填充分区A时,分区B并不会受影响,这就是为啥你Windows重装系统的话,一般只是C盘重新载入新系统数据,而其他的D,E,F盘并不会受影响;
-
系统的效率考虑:加快数据寻址的效率,当你只有一块分区时,找数据文件a你得重头找到尾部,但是当你分区了,操作系统会记录文件的绝对路径,你就可以直接从某个分区下去找,大大提升了速度和效率;
3. 磁盘的结构

图3.1 磁盘的整个组成
如图3.1,磁盘的主要组成有:主轴(含承轴及马达),磁盘盘(可能有多个盘),磁头,磁头臂等; 主轴(含承轴及马达)负责让磁盘盘转起来,磁头负责读取数据,磁头臂负责将磁头接触到磁盘盘,当不读取数据时负责将磁头停在磁头停泊区;
磁盘盘结构比较特殊,拿其中一块出来讲解,如图3.2;磁盘盘主要有:磁道,簇,扇面,扇区组成;一般的磁盘设计是磁头沿着磁道由外圈顺时针一直读取到内圈;将每个同心圆切割成一个个小小块,称为扇区,是磁盘最小的存储单位!,同心圆的扇区一起组成扇面,而第一个扇面又显得重要些,它记录了整个磁盘的重要信息;
3.2 磁盘盘组成示意图
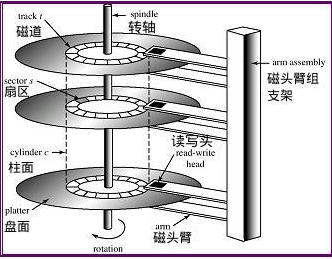
3.3 多块磁盘盘组成示意图
4. 磁盘的分类
4.1 IDE硬盘
目前(20210516)基本已经淘汰,做个大概了解,IDE即Integrated Drive Electronics,它的本意是指把控制器与盘体集成在一起的硬盘驱动器,IDE是表示硬盘的传输接口。我们常说的IDE接口,也叫ATA(Advanced Technology Attachment)、PATA接口,现在PC机使用的硬盘大多数都是IDE兼容的,只需用一根电缆将它们与主板或接口卡连起来就可以了。

图4.1 IDE硬盘
4.2 SCSI硬盘
SCSI 硬盘即采用 SCSI 接口的硬盘。它由于性能好、稳定性高,因此在服务器上得到广泛应用。同时其价格也不菲,正因它的价格昂贵,所以在普通PC上很少见到它的踪迹。SCSI 硬盘使用 50 针接口;

图4.2 SCSI硬盘
4.3 SATA硬盘
SATA(Serial ATA)口的硬盘又叫串口硬盘,Serial ATA 采用串行连接方式,串行 ATA 总线使用嵌入式时钟信号,具备了更强的纠错能力,与以往相比其最大的区别在于能对传输指令(不仅仅是数据)进行检查,如果发现错误会自动矫正,这在很大程度上提高了数据传输的可靠性。串行接口还具有结构简单、支持热插拔的优点

图4.3 SATA硬盘
4.4 固态硬盘
固态硬盘(Solid State Disk),一般称之为 SSD 硬盘,固态硬盘是用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成。其主要特点是没有传统硬盘的机械结构,读写速度非常快;其实,严格上来说固态硬盘不能算磁盘,因为他靠的存储技术是内存和闪存,而且并没有传统磁盘的组成结构,但是由于大家都叫习惯了,就采用了统一的命名;

图4.4 固态硬盘
5. 磁盘分区命名规则
由于磁盘驱动的不同,磁盘可以分为IDE磁盘和SCSI硬盘,IDE硬盘基本已过时(对Linux服务器而言),而之前谈到的SATA、USB、SAS等硬盘的接口都是SCSI硬盘,所以这些都统称为SCSI硬盘,是目前Linux服务器的主流,在 Linux 系统中磁盘设备文件的命名规则为:
主设备号 + 次设备号 + 磁盘分区号
而Linux万物皆文件的个性,硬盘自然是映射再/dev/目录下,IDE硬盘为/dev/hdx~,SCSI硬盘为/dev/sdx~;
IDE硬盘 hdx~:hd表明为设备类型,这里指IDE硬盘,x为盘号,值可以为a(基本盘),b(基本从属盘),c(辅助主盘),d(辅助从属盘);~代表分区,前四个分区1-4表示,他们是主分区或者扩展分区,从5开始就是逻辑分区;例如:第一块盘hda,第二块盘hdb…第一块盘的第一个分区hda1,第二个分区hda2…SCSI硬盘 sdx~:sd表明为设备类型,这里指SCSI硬盘,x为盘号,值可以为a(基本盘),b(基本从属盘),c(辅助主盘),d(辅助从属盘);~代表分区,前四个分区1-4表示,他们是主分区或者扩展分区,从5开始就是逻辑分区;例如:第一块盘sda,第二块盘sdb… 第一块盘的第一个分区sda1,第二个分区sda2…
考虑到常用性,以下内容就以SCSI硬盘为主来讲;
刚刚讲到的
x,那系统是怎么识别sda,sdb,sdc即磁盘1,磁盘2,磁盘3的呢?如在你的PC上,有两个SATA磁盘个一个USB磁盘,而这两个SATA磁盘分别放在SATA1和SATA5插槽上,USB磁盘则在USB接口上,那这三块磁盘的顺序是什么呢?
其实,磁盘的顺序是靠侦测到的顺序来标识的;
- SATA1插槽上的为:/dev/sda
- SATA2插槽上的为:/dev/sdb
- USB(开机完成才能被系统捕捉到):/dev/sdc
6. 磁盘分区类型及原理
6.1 MBR(Master Boot Record)分区格式
早期磁盘第一个扇区(521bytes)里面包含重要的信息MBR(Master Boot Record),其中446 bytes,安装开机管理程序的地方;剩下的64bytes记录硬盘分区的数据,即分区表,大概示意图如图6.1;
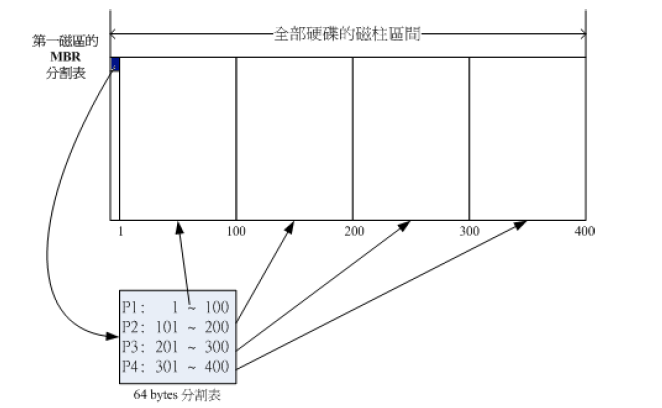
图6.1 MBR分区的示意图
以下的四个分区我们并不能区分是主分区还是扩展分区,两种都有可能;
- P1:/dev/sda1
- P2:/dev/sda2
- P3:/dev/sda3
- P4:/dev/sda4
既然第一个扇区的分区表只能记录四个分区的数据,那自然就想到用额外的扇区来 记录分区信息,这就是扩展分区的由来,如图6.2,分区情况应该为;
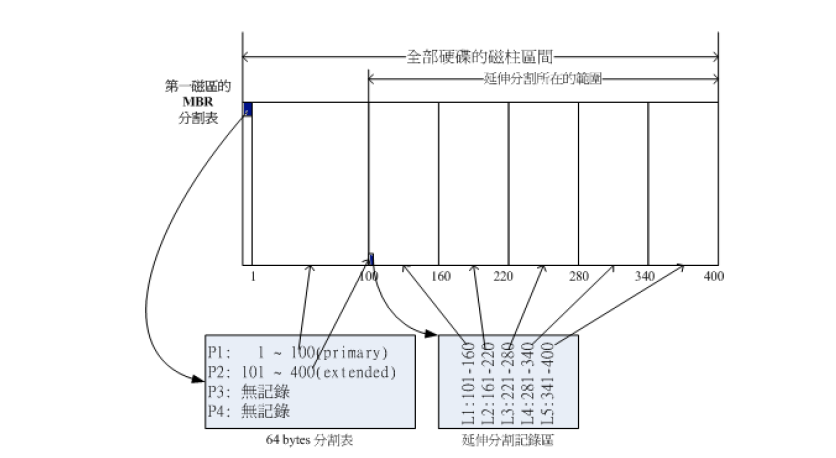
图6.2 MBR分区扩展分区示意图
以上的分区情况为如下,为啥缺少了
/dev/sda3、/dev/sda4呢,原因就是前面四个号都是预留给主分区和逻辑分区的;
- P1:/dev/sda1 (主分区)
- P2:/dev/sda2(扩展分区)
- P3:/dev/sda5(逻辑分区)
- P4:/dev/sda6(逻辑分区)
- P5:/dev/sda7(逻辑分区)
- P6:/dev/sda8(逻辑分区)
- P7:/dev/sda9(逻辑分区)
主分区、扩展分区、逻辑分区的总结内容如下;
- 主分区( primary)P
1)系统中必须要存在的分区,系统盘选择主分区安装
2)数字编号只能是1-4.sda1、sda2、sda3、sda4
3)主分区最多四个,最少一个。
4)能被单独格式化
- 扩展分区( extend)E
1)相当于一个独立的小磁盘。独立的分区表,不能独立存在。
2)有独立的分区表。
3)不能独立存在,即不能直接存放数据
4)必须在扩展分区上建立逻辑分区才能存放数据
5)占用主分区的编号(主分区+扩展分区)之和最多4个
6)不能被格式化
- 逻辑分区(1ogic)L
1)数字编号只能是从5开始
2)存放于扩展分区之上
3)存放任意普通数据
4)能被单独格式化
5)两个独立的逻辑分区可以支持合并成一个新的逻辑分区
- 磁盘分区方式
1)1~4个主分区
2)扩展分区至多能有一个,且 2 ≤ 扩展分区+主分区≤ 4
学习以上内容后,聊聊分区策略,举例如下;
博主有一块硬盘,如果我想要得到6个分区,用MBR分区格式该怎么分配;
首先主分区,扩展分区只能有4个,不够呀,那就需要用到扩展分区,可以分配为,P+P+P+E(E内包含3个逻辑分区L)即,P+P+P+E(L+L+L);当然也可以P+E(L+L+L+L+L) ,可以根据个人想法来实现即可
MBR分区的原理清晰后,其不足的地方也暴露的无疑,因为分区表的容量16bytes有限,始终存在以下不足;
- 操作系统无法抓取2.2T以上的磁盘容量,个人PC可能目前来说够,但是服务器已经无法满足了;
- MBR仅有一块分区表,无法实现高可用,一旦被损坏,很难再救援恢复;
- MBR内存放的开机管理程序也只有446bytes,也是无法容纳更多的开机程序代码的;
你的不努力或者局限,自然就有新星的出现,于是GPT就出现了;
6.2 GPT(GUID Partition Table)分区格式
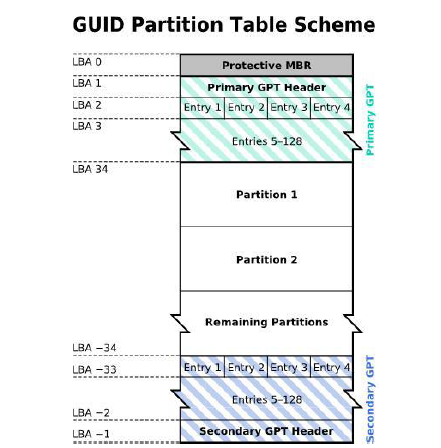
GPT将磁盘划分为一块块的逻辑区块地址(Logical Block Address,简称LBA) 来处理,每个LBA预设计为512bytes,即一个扇区的大小;同时改进MBR之用一块扇区来标识分区表的弊端,GPT使用了前后各34个LBA来标识分区表信息(最后的34各区可以理解为备份,达到高可用),如图6.3;
LBA的标识是从0开始的,LBA0-34共35块,这里分别阐述下其含义;
LBA0:包含两部分,一部分是类似MBR的446bytes,存储开机管理程序,第二部分则是存储一个特殊的标记,标识该磁盘为GPT格式,而看不懂GPT分区的程序则无法操作该磁盘,起到保护作用,放心,目前基本的管理程序都能识别GPT格式,所以该LBA块实际上与分区信息并无直接关联,这就是为啥不算入34LBA的原因;LBA1:GPT的表头,记录分区本身的位置与大小,同时记录分区在备份中最后34个LBA中的位置,方便恢复;LBA2-34:共32块LBA,每块LBA记录4笔分区表,共支持4*23=128笔分区;而每个LBA默认为512bytes,则每笔记录用到512/4=128bytes,每笔记录拿出64bytes来记录开始、结束的扇区号码,因此对一个单一分区槽而言,支持的最大容量为 2 64 ∗ 512 b y t e s = 2 63 ∗ 1 K b y t e s = 2 33 T B = 8 Z B 2^{64}*512bytes=2^{63}*1Kbytes=2^{33}TB=8ZB 264∗512bytes=263∗1Kbytes=233TB=8ZB
注:
1 Z B = 2 30 T B 1 ZB = 2^{30} TB 1ZB=230TB
6.3 GPT分区示意图
因此基本上GPT弥补了MBR的不足,但是GPT只是分区格式方法不同哈,以SCSI硬盘为例,磁盘的命名规则并没有大改;仍然是第一块盘sda,第二块盘sdb… 第一块盘的第一个分区sda1,第二个分区sda2等,但是GPR去除了扩展分区的概念,直接分区为主分区和逻辑分区;
以上就是分区的理论支持,接下来进入分区实操环节;
7. 磁盘分区实操
7.1 给虚拟机添加一块磁盘
这里就采用虚拟机来模拟添加磁盘,博主用的虚拟机是VMware,操作如下;
- 因为是添加硬件,需要先关闭虚拟机。点击
关机。如图7.1;
图7.1 关闭虚拟机
- 然后选中虚拟机,鼠标右键,点击
设置,如图7.2;
图7.2 点击设置
- 跳转图7.3,选择
硬盘,点击下一步;
图7.3 添加硬盘
- 跳转图7.4,选择
SCSI(S),点击下一步;
图7.4 选择SCSI硬盘
- 跳转图7.5,设置硬盘的大小,这里为了说明问题,博主就选默认的20G,点击
下一步;
图7.5 选择硬盘大小
- 跳转图7.6,选择
创建新虚拟磁盘(V),点击下一步;
图7.6 选择创建新虚拟磁盘
- 跳转图7.7,给磁盘文件命名,这个没关系,博主采用默认的,点击
完成;
图7.7 给磁盘文件命名
- 跳转图7.8,点击
确定完成硬盘的增加,然后记得开机;
图7.5 选择硬盘大小
7.2 MBR方式分区实操
开机后利用指令lsblk(老师不离开),可以看到磁盘sdb就是刚刚添加的磁盘,无分区情况;sda就是之前安装虚拟机设置的磁盘,有两个分区sda1和sda2;
[hadoop@node2 ~]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
sr0 11:0 1 4.4G 0 rom
# 也可以用fdisk来查看磁盘
[root@node2 /]# fdisk -l
磁盘 /dev/sda:64.4 GB, 64424509440 字节,125829120 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x0001d6b8
设备 Boot Start End Blocks Id System
/dev/sda1 * 2048 2099199 1048576 83 Linux
/dev/sda2 2099200 125829119 61864960 8e Linux LVM
磁盘 /dev/sdb:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘 /dev/mapper/centos-root:41.1 GB, 41120956416 字节,80314368 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘 /dev/mapper/centos-swap:2147 MB, 2147483648 字节,4194304 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘 /dev/mapper/centos-home:20.1 GB, 20073938944 字节,39206912 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
接下来开始采用MBR的方式进行分区,用到指令fdisk;
要求:给20G的新磁盘分区,要求为P(5G)+P(5G)+L(5G)+L(5G);
即,两个主分区,每个5G,两个逻辑分区,每个5G,之前说过逻辑分区不能单独存在,必须搭载扩展分区,所以实际情况应该是两个主分区,每个5G,一个扩展分区10G,扩展分区里面两个逻辑分区,每个5G
操作如下;
# fdisk /dev/sdb指令进入分区操作的交互命令行
[root@node2 hadoop]# fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
Device does not contain a recognized partition table
使用磁盘标识符 0xcc9206a3 创建新的 DOS 磁盘标签。
命令(输入 m 获取帮助):
# 输入m活的操作提示
命令操作
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
g create a new empty GPT partition table
G create an IRIX (SGI) partition table
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
# 根据提示输入n add a new partition
命令(输入 m 获取帮助):n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
# 这里p是主分区,e为拓展分区,先来个主分区,选择p
Select (default p): p
分区号 (1-4,默认 1):1
# 这里跳转到选择分区号,之前理论讲过MBR只能有四个主或扩展分区,因为是新的分区,这里选择1即可;
起始 扇区 (2048-41943039,默认为 2048):
将使用默认值 2048
# 这里选择起始的扇区,选择默认的即可
Last 扇区, +扇区 or +size{
K,M,G} (2048-41943039,默认为 41943039):+5G
分区 1 已设置为 Linux 类型,大小设为 5 GiB
# 这里选择结束的扇区,如果你选择默认的,那么就是将整块磁盘给到一个分区,
# 这里磁盘有20G,我们可以来个5G的,选择+5G,就是给第一个分区5G空间
# 这里还没完,还需要写入w,则完成分区1分区;
命令(输入 m 获取帮助):w
The partition table has been altered!
Calling ioctl() to re-read partition table.
正在同步磁盘。
# 完成同步后会自动退出,再次使用lsblk指令查看,发现已经多了sdb1
[root@node2 hadoop]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
└─sdb1 8:17 0 5G 0 part
sr0 11:0 1 4.4G 0 rom
# 再来创建第二个主分区
[root@node2 hadoop]# fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
命令(输入 m 获取帮助):n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
# 选择p表示创建第二个主分区
Select (default p): p
# 这里自动选择序号2,因为1已经被第一个主分区占用
分区号 (2-4,默认 2):2
# 其实位置选择默认即可
起始 扇区 (10487808-41943039,默认为 10487808):
将使用默认值 10487808
# 结束扇区依然选择5G
Last 扇区, +扇区 or +size{
K,M,G} (10487808-41943039,默认为 41943039):+5G
分区 2 已设置为 Linux 类型,大小设为 5 GiB
# w指令保存磁盘修改
命令(输入 m 获取帮助):w
The partition table has been altered!
Calling ioctl() to re-read partition table.
正在同步磁盘。
# lsblk指令得到第二块主分区sbd2
[root@node2 hadoop]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
├─sdb1 8:17 0 5G 0 part
└─sdb2 8:18 0 5G 0 part
sr0 11:0 1 4.4G 0 rom
# 接下来是创建拓展分区和逻辑分区
[root@node2 hadoop]# fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
命令(输入 m 获取帮助):n
Partition type:
p primary (2 primary, 0 extended, 2 free)
e extended
# 选择e表示拓展分区,编号可以选择默认的3
Select (default p): e
分区号 (3,4,默认 3):3
# 起始扇区选择默认的位置
起始 扇区 (20973568-41943039,默认为 20973568):
将使用默认值 20973568
# 剩下的所有磁盘分给这个拓展分区
Last 扇区, +扇区 or +size{
K,M,G} (20973568-41943039,默认为 41943039):
将使用默认值 41943039
分区 3 已设置为 Extended 类型,大小设为 10 GiB
# 记得写入w保存磁盘更改
命令(输入 m 获取帮助):w
The partition table has been altered!
Calling ioctl() to re-read partition table.
正在同步磁盘。
# 之前理论说过,扩展分区是不能单独存在的,必须要有逻辑分区在里面,接下来再来两次,创建逻辑分区
[root@node2 hadoop]# fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
命令(输入 m 获取帮助):n
# 这里你会发现,多了个l(logic) 的选项,即逻辑分区的意思,这里记得选l
Partition type:
p primary (2 primary, 1 extended, 1 free)
l logical (numbered from 5)
Select (default p): l
添加逻辑分区 5
# 选择默认的起始扇区
起始 扇区 (20975616-41943039,默认为 20975616):
将使用默认值 20975616
# 第一个逻辑分区为5G
Last 扇区, +扇区 or +size{
K,M,G} (20975616-41943039,默认为 41943039):+5G
# 默认逻辑分区从编号5开始,因为1-4要预留给到主分区和扩展分区
分区 5 已设置为 Linux 类型,大小设为 5 GiB
# 记得保存磁盘更改,写入w;
命令(输入 m 获取帮助):w
The partition table has been altered!
Calling ioctl() to re-read partition table.
正在同步磁盘。
# 再来一次,创建 第二块逻辑分区
[root@node2 hadoop]# fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
命令(输入 m 获取帮助):n
Partition type:
p primary (2 primary, 1 extended, 1 free)
l logical (numbered from 5)
Select (default p): l
添加逻辑分区 6
起始 扇区 (31463424-41943039,默认为 31463424):
将使用默认值 31463424
# 使用默认的结束扇区,即将剩下的扩展分区的空间全部给到第二个逻辑分区
Last 扇区, +扇区 or +size{
K,M,G} (31463424-41943039,默认为 41943039):
将使用默认值 41943039
分区 6 已设置为 Linux 类型,大小设为 5 GiB
命令(输入 m 获取帮助):w
The partition table has been altered!
Calling ioctl() to re-read partition table.
正在同步磁盘。
# 到此,主分区,扩展分区,逻辑分区的分区操作就算完了;切忌使用前还需要进行格式化,
# 格式化的操作再下个小结挂载的时候再细讲
# 使用lsblk查看刚刚的主分区,扩展分区,逻辑分区的分区操作的结果,
# 发现完全符合之前MBR分区的理论和我们的预期
[root@node2 hadoop]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
├─sdb1 8:17 0 5G 0 part
├─sdb2 8:18 0 5G 0 part
├─sdb3 8:19 0 1K 0 part
├─sdb5 8:21 0 5G 0 part
└─sdb6 8:22 0 5G 0 part
sr0 11:0 1 4.4G 0 rom
# 其他重要指令
# 发现分区操作失误,可以d删除指令
d delete a partition
7.2 GPT分区实操(大于2T的磁盘分区方法,小于也能用)
之前说过MBR分区格式,即对应的fdisk操作有局限就是大于2T的磁盘无法使用该理论和方法,那个人PC可能觉得2T完全满足,但是服务器2T肯定是不足的,因此学习下GPT的分区方法也是很有必要的,使用的指令为parted,博主比较穷,私人是没有2T的硬盘的,这里就用一个20G的来模拟,实现以下要求;
要求:给20G的新磁盘分区,要求为P(5G)+P(5G)+L(5G)+L(5G);
即,两个主分区,每个5G,两个逻辑分区,每个5G,之前说过逻辑分区不能单独存在,必须搭载扩展分区,所以实际情况应该是两个主分区,每个5G,一个扩展分区10G,扩展分区里面两个逻辑分区,每个5G
操作如下;
# 使用lsblk查看刚刚新增的磁盘sdc
[root@node2 hadoop]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
├─sdb1 8:17 0 5G 0 part
├─sdb2 8:18 0 5G 0 part
├─sdb3 8:19 0 1K 0 part
├─sdb5 8:21 0 5G 0 part
└─sdb6 8:22 0 5G 0 part
sdc 8:32 0 20G 0 disk
sr0 11:0 1 4.4G 0 rom
# 进行parted分区
# 使用parted /dev/sdc进入交互的parted命令行
[root@node2 hadoop]# parted /dev/sdc
GNU Parted 3.1
使用 /dev/sdc
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted)
# 输入p查看当前分区,发现为0个分区
(parted) p
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdc: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name 标志
# 将MBR磁盘格式化为GPT
(parted) mklabel gpt
# 创建第一个主分区
(parted) mkpart primary 0 5G
警告: The resulting partition is not properly aligned for best performance.
忽略/Ignore/放弃/Cancel? Ignore
# 查看当前磁盘分区情况,发现第一个主分区成功
(parted) p
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdc: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name 标志
1 17.4kB 5000MB 5000MB primary
# 创建第二个主分区
(parted) mkpart primary 5G 10G
# 输入p查看第二个主分区
(parted) p
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdc: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name 标志
1 17.4kB 5000MB 5000MB primary
2 5001MB 10.0GB 5000MB primary
# 创建第三个逻辑分区,理论篇说过GPT分区,逻辑分区不需要以扩展分区为载体,所以这里没有扩展分区
(parted) mkpart logic 10G 15G
# 输入p查看第一个个逻辑分区
(parted) p
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdc: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name 标志
1 17.4kB 5000MB 5000MB primary
2 5001MB 10.0GB 5000MB primary
3 10.0GB 15.0GB 5000MB logic
# 创建第2个逻辑分区
(parted) mkpart logic 15G 20G
# 输入p查看当前分区
(parted) p
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdc: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name 标志
1 17.4kB 5000MB 5000MB primary
2 5001MB 10.0GB 5000MB primary
3 10.0GB 15.0GB 5000MB logic
4 15.0GB 20.0GB 5000MB logic
# 也可以使用print查看当前分区
(parted) print
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdc: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name 标志
1 17.4kB 5000MB 5000MB primary
2 5001MB 10.0GB 5000MB primary
3 10.0GB 15.0GB 5000MB logic
4 15.0GB 20.0GB 5000MB logic
# 退出parted交互命令行
(parted) quit
信息: You may need to update /etc/fstab.
# 利用lsblk查看刚刚的gpt分区
[root@node2 hadoop]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
├─sdb1 8:17 0 5G 0 part
├─sdb2 8:18 0 5G 0 part
├─sdb3 8:19 0 1K 0 part
├─sdb5 8:21 0 5G 0 part
└─sdb6 8:22 0 5G 0 part
sdc 8:32 0 20G 0 disk
├─sdc1 8:33 0 4.7G 0 part
├─sdc2 8:34 0 4.7G 0 part
├─sdc3 8:35 0 4.7G 0 part
└─sdc4 8:36 0 4.7G 0 part
sr0 11:0 1 4.4G 0 rom
# parted分区指令的其他命令
# 划分所有空间到一个分区
(parted) mkpart primary 0-1
# 如果要反过来.将GPT磁盘转化为MBR磁盘
(parted) mklable msdos
8. 磁盘的格式化、手动挂载、自动挂载、卸载
8.1 文件系统的类型
Linux:存在几十个文件系统类型:ext2,ext3,ext4,xfs,brtfs等,不同文件系统采用不同的方法来管理磁盘空间,各有优劣;文件系统是具体到分区的,所以格式化针对的是分区,分区格式化是指采用指定的文件系统类型对分区空间进行登记、索引并建立相应的管理表格的过程。
- ext2具有极快的速度和极小的CPU占用率,可用于硬盘和移动存储设备
- ext3增加日志功能,可回溯追踪
- ext4日志式文件系统,支持1EB(1024*1024TB),最大单文件16TB,支持连续写入可减少文件碎片。rhel6默认文件系统
- xfs可以管理500T的硬盘。rhel7默认文件系统
- brtfs文件系统针对固态盘做优化;
8.2 格式化、手动挂载、自动挂载、卸载实操
怎么多怎么记呢,其实很简单, ext一代比一代强,目前要用当然是 ext4, xfs又是更强的文件系统,CentOS7默认的文件系统,如果你的系统支持,优选xfs,再是ext4吧,当然如果是固态硬盘,可以考虑brtfs;
磁盘的格式化,是精确到每个分区的;磁盘分区在使用前,必须先格式化以下,然后具体怎么用呢;具体步骤如下;
- 格式化磁盘分区
- 将磁盘分区挂载到一个文件夹下,其实可以理解为将文件夹映射到该分区下,当有文件存入该文件夹,则实际就存入了该磁盘的分区;
- 挂载分为手动挂载和自动挂载,手动挂载,则开启重启后会失效,自动挂载则在开机的时候给你挂好,让使用者无感;
- 有时候不需要该分区,则需要先卸载该分区对应的文件夹,再删除分区,则为卸载操作;
下面进入实操环节;
# 在根目录下新建一个myfile目录作为挂载的目录
cd /
mkdir file
# 格式化sdc2分区,选用文件系统问目前最优的xfs
# 注意,/dev/sdc2一定要带上2,一定要带上2,一定要带上2
# 不带上什么意思,就是格式化整个磁盘,结果就是你之前做的sdc的分区全部白费了
mkfs.xfs /dev/sdc2
# 手动挂载
[root@node2 /]# mount /dev/sdc2 file/
# 查看挂载情况,发现sdc2后面已经挂在了/file
[root@node2 /]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
├─sdc1 8:33 0 4.7G 0 part
├─sdc2 8:34 0 4.7G 0 part /file
├─sdc3 8:35 0 4.7G 0 part
└─sdc4 8:36 0 4.7G 0 part
sr0 11:0 1 4.4G 0 rom
# 磁盘卸载
# 使用umount卸载分区时,可以指定挂载点,也可以指定挂载的路径
umount /dev/sdc1
# 或者等价于
umount /file
# 此时关机重启下,再lsblk指令,返现该手动挂载的目录失效了
[root@node2 hadoop]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
├─sdc1 8:33 0 4.7G 0 part
├─sdc2 8:34 0 4.7G 0 part
├─sdc3 8:35 0 4.7G 0 part
└─sdc4 8:36 0 4.7G 0 part
sr0 11:0 1 4.4G 0 rom
# 因此要实现自动挂载
# 手动挂载
[root@node2 /]# mount /dev/sdc2 file/
# 获取sdc1的UUID
[root@node2 /]# blkid /dev/sdc2
/dev/sdc2: UUID="2b9fa094-078c-4c38-8b1f-d15986f6eb96" TYPE="xfs" PARTLABEL="primary" PARTUUID="83532884-4d4b-40d0-a9b3-4b85adc2ddd3"
# 编辑/etc/fstab文件,加入新的分区挂载
vim /etc/fstab
# 最后一行追加刚刚的磁盘挂载
#
# /etc/fstab
# Created by anaconda on Sat Apr 11 20:27:09 2020
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=ee1291e7-1efb-4872-b874-c51bf0007866 /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
# 上面为系统自带,别理,下面添加这句
/dev/mapper/centos-swap swap swap defaults 0 0
UUID=2b9fa094-078c-4c38-8b1f-d15986f6eb96 /file xfs defaults 0 0
# 注意,如果不用UUID,用磁盘设备名称也可,以下信息等价
/dev/sdc1 /file xfs defaults 0 0
#以上就完成了磁盘的自动挂载,可以开机重启验证下
9. 两块磁盘空间合二为一,并挂载到同一目录下实现扩容
服务器预算中希望有个文件夹有10T,但是手上只有两块5T的磁盘,怎么办呢,能不能把两块5T的磁盘同时挂载到同一个文件夹呢?答案当然是可以的;
那博主比较穷,自热是没有5T的磁盘,那就那两个20G的凑合下吧,实现同时挂载到一个目录下,实现该目录40G的存储空间;
要求将两块20G的磁盘sdb,sdc,同时挂载到目录mydata下,是的目录mydata的存储空间为40G;
下面进入实操环节;
# 这里也采用GPT的分区方法,使用parted指令
[root@node3 hadoop]# parted /dev/sdb
GNU Parted 3.1
使用 /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
# 将磁盘转换成gpt
(parted) mklabel gpt
#这里反正要合并,就设置一个主分区包含整个磁盘
(parted) mkpart primary 0 100%
警告: The resulting partition is not properly aligned for best performance.
忽略/Ignore/放弃/Cancel? Ignore
(parted) p
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name 标志
1 17.4kB 21.5GB 21.5GB primary
# 同理对磁盘/dev/sbc进行相同的操作
[root@node3 hadoop]# parted /dev/sdc
GNU Parted 3.1
使用 /dev/sdc
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) mklabel gpt
(parted) mkpart primart 0 100%
警告: The resulting partition is not properly aligned for best performance.
忽略/Ignore/放弃/Cancel? I
(parted) p
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdc: 21.5GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name 标志
1 17.4kB 21.5GB 21.5GB primart
(parted) quit
信息: You may need to update /etc/fstab.
# 得到目前的磁盘分布如下
[root@node3 hadoop]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 59G 0 part
├─centos-root 253:0 0 38.3G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 18.7G 0 lvm /home
sdb 8:16 0 20G 0 disk
└─sdb1 8:17 0 20G 0 part
sdc 8:32 0 20G 0 disk
└─sdc1 8:33 0 20G 0 part
sdd 8:48 0 20G 0 disk
sr0 11:0 1 4.4G 0 rom
# 创建物理卷的命令为pvcreate;利用该命令将希望添加到卷组的所有分区或磁盘创建为物理卷;
[root@node3 hadoop]# pvcreate /dev/sdb1
Physical volume "/dev/sdb1" successfully created.
# 将分区/dev/sdb1和/dev/sdc1分区创建为物理卷:
[root@node3 hadoop]# pvcreate /dev/sdc1
Physical volume "/dev/sdc1" successfully created.
#创建卷组的命令为vgcreate;用此命令将使用pvcreate建立的物理卷创建为一个完整的卷组;
#将物理卷/dev/sdb1创建为一个名为vgmysql的卷组:
[root@node3 hadoop]# vgcreate vgmygroup1 /dev/sdb1
Volume group "vgmygroup1" successfully created
#此步即为将2块磁盘空间合二为一的关键步骤;当系统中新增了磁盘或新建了物理卷,而要将其添加到已有卷组时,就可使用vgextend命令;
# 将物理卷/dev/sdc1添加到vgmysql卷组中:
[root@node3 hadoop]# vgextend vgmygroup1 /dev/sdc1
Volume group "vgmygroup1" successfully extended
# 查看卷组用vgs,从vgs命令的回显结果来看,卷组vgmysql成功添加
# 并且其总空间为两块物理磁盘的总大小(因换算单位不同,所以不是精确的40G)。
[root@node3 hadoop]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 3 0 wz--n- <59.00g 4.00m
vgmygroup1 2 0 0 wz--n- 39.99g 39.99g
# 创建逻辑卷的命令为lvcreate;用此命令将在使用vgcreate建立的卷组上创建逻辑卷;
# 在卷组vgmysql上创建一个名为lvmysql的逻辑卷,起大小为 39.99G;
# -n:指定逻辑卷名
# -L:指定逻辑卷大小
[root@node3 hadoop]# lvcreate -L 39.99g -n lvmygroup vgmygroup1
Rounding up size to full physical extent 39.99 GiB
Logical volume "lvmygroup" created.
# 将创建的lvmysql逻辑卷格式化为xfs
[root@node3 hadoop]# mkfs -t xfs /dev/vgmygroup1/lvmygroup
meta-data=/dev/vgmygroup1/lvmygroup isize=512 agcount=4, agsize=2620928 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=10483712, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=5119, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# 切换到根目录,在根目录下新建文件夹
[root@node3 hadoop]# cd /
[root@node3 /]# mkdir mydata
# 挂载刚刚的逻辑组到新建目录下
[root@node3 /]# mount /dev/vgmygroup1/lvmygroup /mydata/
# 查看磁盘大小和挂载磁盘查看,目录为40G
[root@node3 /]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.8M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 39G 4.3G 35G 12% /
/dev/sda1 1014M 137M 878M 14% /boot
/dev/mapper/centos-home 19G 33M 19G 1% /home
tmpfs 98M 0 98M 0% /run/user/2000
tmpfs 98M 0 98M 0% /run/user/0
/dev/mapper/vgmygroup1-lvmygroup 40G 33M 40G 1% /mydata
# 创建开机自动挂载
[root@node3 /]# echo /dev/mapper/vgmygroup1-lvmygroup /mydata/ xfs defaults 0 0 >> /etc/fstab
# 重启重新查看挂载的磁盘,确认成功自动开机挂载
[root@node3 ~]# sync
[root@node3 ~]# reboot
# 使用df -h指令再次查看,发现完成自动挂载
[root@node3 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.8M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 39G 4.3G 35G 12% /
/dev/mapper/vgmygroup1-lvmygroup 40G 33M 40G 1% /mydata
tmpfs 98M 0 98M 0% /run/user/0
98M 0 98M 0% /run/user/2000
10. 磁盘的查看命令
10.1 df指令
df
df命令参数功能:检查文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
语法:
df [-ahikHTm] [目录或文件名]
选项与参数:
-a :列出所有的文件系统,包括系统特有的 /proc 等文件系统;
-k :以 KBytes 的容量显示各文件系统;
-m :以 MBytes 的容量显示各文件系统;
-h :以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示;
-H :以 M=1000K 取代 M=1024K 的进位方式;
-T :显示文件系统类型, 连同该 partition 的 filesystem 名称 (例如 ext3) 也列出;
-i :不用硬盘容量,而以 inode 的数量来显示
使用样例
[root@node3 ~]# df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 475M 0 475M 0% /dev
tmpfs tmpfs 487M 0 487M 0% /dev/shm
tmpfs tmpfs 487M 7.8M 479M 2% /run
tmpfs tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 39G 4.3G 35G 12% /
/dev/mapper/vgmygroup1-lvmygroup xfs 40G 33M 40G 1% /mydata
tmpfs tmpfs 98M 0 98M 0% /run/user/0
10.2 du指令
du命令也是查看使用空间的,但是与df命令不同的是Linux du命令是对文件和目录磁盘使用的空间的查看,还是和df命令有一些区别的。
语法:
du [-ahskm] 文件或目录名称
选项与参数:
-a :列出所有的文件与目录容量,因为默认仅统计目录底下的文件量而已。
-h :以人们较易读的容量格式 (G/M) 显示;
-s :列出总量而已,而不列出每个各别的目录占用容量;
-S :不包括子目录下的总计,与 -s 有点差别。
-k :以 KBytes 列出容量显示;
-m :以 MBytes 列出容量显示;
使用样例;
[root@node3 hadoop]# du -ah ./*
8.0K ./capacity-scheduler.xml
4.0K ./configuration.xsl
4.0K ./container-executor.cfg
4.0K ./core-site.xml
4.0K ./hadoop-env.cmd
8.0K ./hadoop-env.sh
4.0K ./hadoop-metrics2.properties
4.0K ./hadoop-metrics.properties
12K ./hadoop-policy.xml
4.0K ./hdfs-site.xml
4.0K ./httpfs-env.sh
4.0K ./httpfs-log4j.properties
4.0K ./httpfs-signature.secret
4.0K ./httpfs-site.xml
4.0K ./kms-acls.xml
4.0K ./kms-env.sh
4.0K ./kms-log4j.properties
8.0K ./kms-site.xml
16K ./log4j.properties
4.0K ./mapred-env.cmd
4.0K ./mapred-env.sh
8.0K ./mapred-queues.xml.template
4.0K ./mapred-site.xml
4.0K ./mapred-site.xml.template
4.0K ./slaves
4.0K ./ssl-client.xml.example
4.0K ./ssl-server.xml.example
4.0K ./yarn-env.cmd
8.0K ./yarn-env.sh
8.0K ./yarn-site.xml
至于其他的磁盘指令fdisk,lsblk,parted等,已经在前面的分区地方将的十分清楚了,这里就不在累赘了;
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141647.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
