大家好,又见面了,我是你们的朋友全栈君。
前言
线程池在面试、开发过程中都比较重要。本文总结了一些关于该方面的相关知识点。
以下内容收集于 蚂蚁课堂
什么是线程池
线程池和数据库连接池非常类似,可以统一管理和维护线程,减少没有必要的开销。
为什么要使用线程池
因为在项目开发过程中频繁的开启线程或者停止线程,线程需要重新被CPU从就绪状态调度到运行状态,需要发生CPU的上下文切换,效率非常低。
线程的生命周期如下图所示:
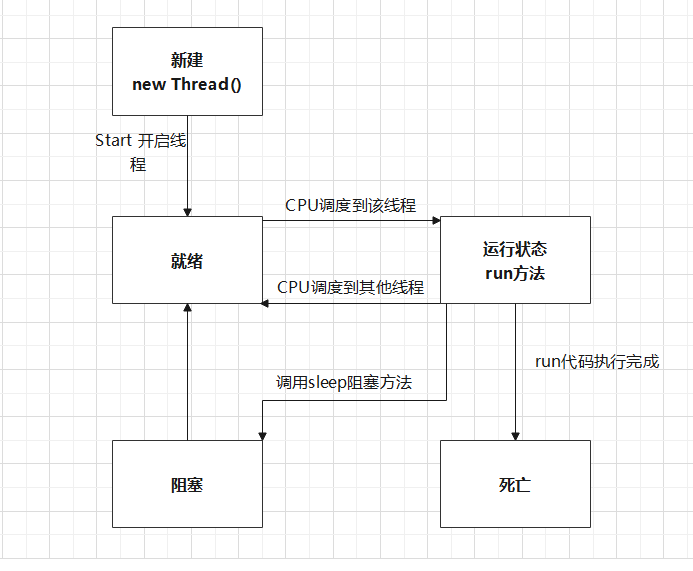

线程池有哪些作用
- 降低资源消耗:通过池化技术重复利用已创建好的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延迟定时线程池 ScheduledThreadPoolExecutor ,就允许任务延期执行或定期执行。
线程池的创建方式
分为以下几种创建方式:
- Executors.newCachedThreadPool():可缓存线程池
- Executors.newFixedThreadPool():可定长度,限制最大线程数
- Executors.newScheduledThreadPool():可定时线程池
- Executors.newSingleThreadExecutor():单例线程池
底层都是基于 ThreadPoolExecutor 构造函数封装
如何实现复用
本质思想:创建一个线程,不会立马体质或者销毁,而是一直实现复用。
- 提前创建固定大小的线程一直保持正在运行的状态(可能会非常消耗CPU资源)。
- 当需要线程执行任务,将该任务提交缓存在并发队列中,如果缓存队列满了,则会执行拒绝策略。
- 正在运行的线程从并发队列中获取任务执行从而实现线程复用的问题。
线程池底层原理如下图所示:

线程池核心点:复用机制- 提前创建好固定的线程一直在运行状态—死循环实现。
- 提交的线程任务缓存到一个并发队列集合中,交给我们正在运行的线程执行。
- 正在运行的线程就从队列中获取该任务执行。
简单实现代码如下:
/** * @author zfl_a * @date 2021/3/20 * @project multi-thread */
public class CustExcutors {
// 存放线程任务
public BlockingDeque<Runnable> runnableList ;
// 停止线程标识位
private volatile Boolean isRun = true ;
/** * 初始化 * @param dequeSize 队列容器大小 * @param threadCount 线程池大小 */
public CustExcutors(int dequeSize,int threadCount){
runnableList = new LinkedBlockingDeque<>(dequeSize);
for (int i=0;i<threadCount;i++) {
WorkThread workThread = new WorkThread();
workThread.start();
}
}
public void execute(Runnable runnable){
runnableList.offer(runnable);
}
class WorkThread extends Thread {
@Override
public void run (){
// 标识位位true 或者队列中有未执行完成的任务
while(isRun || runnableList.size()>0) {
Runnable runnable = runnableList.poll();
// 如果不为空 ,执行
if(runnable!=null) {
runnable.run();
}
}
}
}
public static void main(String[] args) {
CustExcutors custExcutors = new CustExcutors(10,2);
for (int x=0;x<10;x++) {
final int i = x ;
custExcutors.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"----"+i);
}
});
}
// 停止线程
custExcutors.isRun=false;
}
}
运行结果:只有两个线程在运行任务

ThreadPoolExecutor核心参数
- corePoolSize:核心线程数量,一直正在保持运行的线程。
- maximumPoolSize:最大线程数,线程池允许创建的最大线程数。
- keepAliveTime:超出 corePoolSize 后创建的线程存活时间(当超过核心线程数后,又没有线程任务执行,达到该存活时间后,停止该线程)。
- unit:keepAliveTime 的时间单位。
- workQueue:任务队列,用于保持待执行的任务。
- threadFactory :线程池内部创建线程所用的工厂。
- handler:任务无法执行时的处理器(当任务被拒绝时)。
其他相关总结
-
线程池不会一直在运行状态。假设配置核心线程数 corePoolSize 为2 ,最大线程数 maximumPoolSize 为5,我们可以通过 corePoolSize 核心线程数后创建的线程的存活时间例如为60s,在60s内没有线程任务执行,则会停止该线程。
-
线程池底层 ThreadPoolExecutor 底层实现原理
2.1. 当线程数小于核心线程数时,创建线程。
2.2. 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
2.3. 当线程数大于等于核心线程数,且任务队列已满,有以下两种情况。
2.3.1. 如果线程数小于最大线程数,创建线程。
2.3.2. 如果线程数等于最大线程数,抛出异常,拒绝任务。 -
如果队列满了,且任务总数>最大线程数则当前线程走拒绝策略。可自定义拒绝异常,将该任务缓存到Redis、本地文件、mysql中,后期项目启动实现补偿。
-
拒绝策略有以下几种:
4.1. AbortPolicy:丢弃任务,抛出运行时异常。
4.2. CallerRunsPolicy:执行任务。
4.3. DiscardPolicy 忽视
4.4. DiscardOldestPolicy:从队列中剔除最先进入队列(最后一个执行)的任务。
4.5. 实现 RejectedExecutionHandler 接口,可自定义处理器。 -
如何合理配置参数
自定义线程池就需要我们自己配置最大线程数 maximumPoolSize ,为了高效的并发运行,这时需要看我们的业务是IO密集型还是CPU密集型。5.1 CPU密集型:
CPU密集的意思是该任务需要最大的运算,而没有阻塞,CPU一直全速运行。CPU密集任务只有在真正的多核CPU上才能得到加速(通过多线程)。而在单核CPU上,无论你开几个模拟的多线程该任务都不可能得到加速,因为CPU总的运算能力就那么多。5.2 IO密集型
IO密集型,即该任务需要大量的IO,即大量的阻塞。在单线程上运行IO密集型的任务会导致大量的CPU运算能力浪费在等待。所以在IO密集型任务中使用多线程可以大大的加速程序运行,即使在单核CPU上这种加速主要就是利用了被浪费掉的阻塞时间。IO 密集型时,大部分线程都阻塞,故需要多配制线程数。公式为:
CPU核数*2 CPU核数/(1-阻塞系数) 阻塞系数在0.8~0.9之间 查看CPU核数: System.out.println(Runtime.getRuntime().availableProcessors());
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141560.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
