大家好,又见面了,我是你们的朋友全栈君。
一、语音交互
语音交互(VUI: Voice User Interface)是指人与人或者人与设备通过自然语音进行信息传递的过程。
1. 语音交互的优势
(1)输入效率高:相对于键盘输入,语音输入的速度是传统输入方式的3倍以上(有权威统计分析得到的数据)。语音检索效率高;可跨空间,也称为远程语音交互,至少一米以上;指令可组合,比如:对着智能机顶盒说:“看一部周星驰的电影,评分8分”以上。
(2)解放双手和双眼,更安全:如车载系统的语音点播和语音导航场景(不可能一般用手开车,一边用手点播音乐);比如医疗场景,医生可以一边动手术,一边口语记录病例数据。
(3)使用门槛低:对于某些无法使用文字来交互的特殊人群(老人/小孩/视觉有障碍的人群/不同国家的人)来说,语音交互为其带来极大的便利。
(4)语音能传递更多的信息:比如声纹、年龄、性别、情感等(这些信息都可以通过一定的算法来提取)。
2. 语音交互的劣势
(1)信息接收效率低:从输出的效果或者角度来理解,输出是线性的输出,比如必须等说话人说完或者说出大部分语音才能理解他的意思,而文字就不同,文字可以揣摩上下文。比如某种信息的传递,人们更喜欢看文字,提取关键字即可,没必要一个字一个字阅读。微信推出的语音转文本功能,就是考虑到这个痛点。对于大段的语音,如果转成文本,几秒钟就可以知道是什么信息,而听语音估计要听一两分钟。
(2)复杂的声学环境:环境中存在不想听到的声音,但是也有想要听到的声音。
(3)心理负担:用户的心里负担,比如想要检索某些敏感的信息(这时候,文本输入就相对有优势)。
3. 人机语音交互历史
(1)2011年,iPhone4s,Siri问世。
(2)近年来,智能音箱市场的崛起[小雅、小度、小爱同学、天猫精灵]。
(2)智能AI机器人。
4. 人机语音交互流程
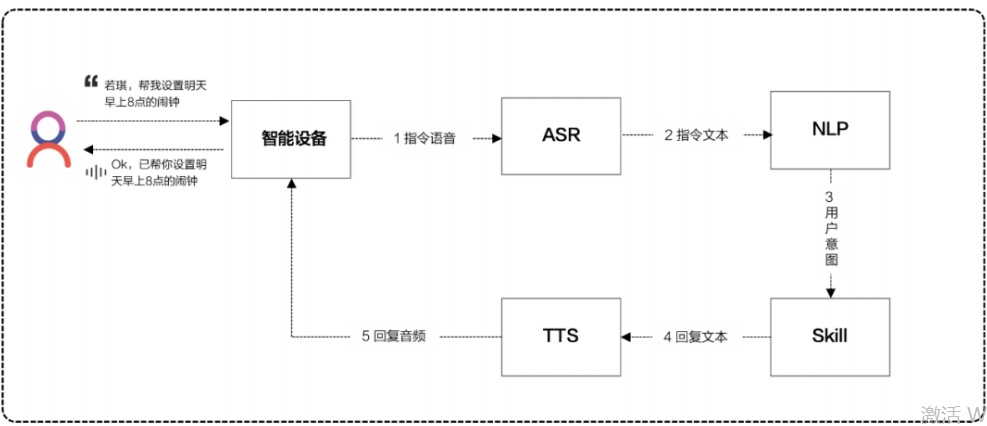

流程解析:
1)用户:唤醒词+指令—>语音—>智能硬件设备—>语音—>ASR(自动语音识别系统)—>文本—>NLP(自然语言理解系统)—>解析用户意图,调用对应的接口代码实现对应的功能。—>回复反馈文本—>文本—>TTS(文本转语音系统)—>语音—>智能硬件设备—>播报给用户。
2)一轮完整的交互流程就包括文本转语音、语音转文本、核心是文本的解析(NLP),而前端语音信号处理是重要的基石,我们要做的就是提取到纯净的、高质量的前端语音数据。
5. 语音交互适用场景
下图为相关的统计数据:包括积极因素和消极因素,分三个等级(0/1/2)打分。
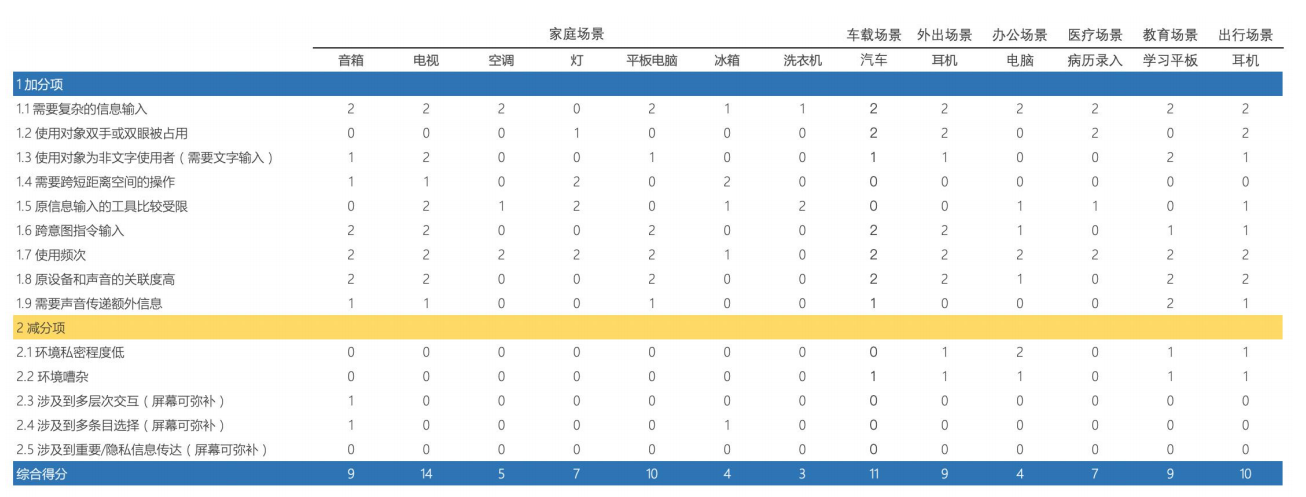
数据分析结果:家庭场景使用语音交互的需求和用户的意愿很高,其次是车载,最后是出行场景(耳机)。
二、复杂的声学环境
1. 因素
1)方向性干扰:人声干扰
2)环境噪声(散射噪声,各个方向都有可能)
3)远讲产生的混响
4)声学回声(设备自身产生的)
人和机器都听不清。
2. 前端语音信号处理的意义
面对噪声、干扰、声学回声、混响等不利因素,运用信号处理、机器学习等手段,提高目标语音的信噪比或者主观听觉感受,增强语音交互后续环节的稳健性。
1)让人听清:更高的信噪比、更好的主观听觉感受和可懂度,更低的处理延时
2)让机器听清[ASR]:更好的声学模型适配,更高的语音识别性能
三、前端语音信号处理
1. 场景实例
例1:音视频通话/会议

远端的人说出的话(设备自身产生的回声),又被自己的麦克风拾取到。所以,对于一般的音视频通话系统,比如智能音箱、智能会议系统、会议音箱等都有一个回声消除模块,否则远端的人又会听到自己说话的声音。
例2:苹果手机的又几个麦克风?4个及以上

目的:保证通话质量、主动降噪(至少具备两个麦克风)。
例3:个人PC
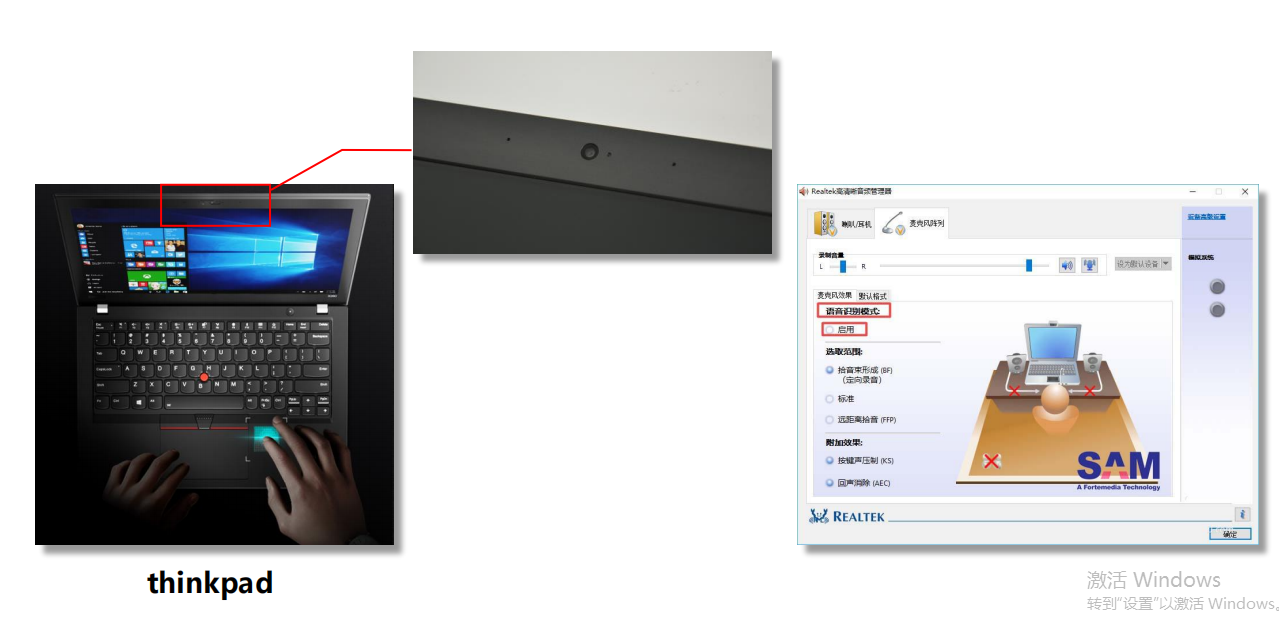
例4:智能设备(车载/音箱/App手机助手)

2. 场景细分
针对不同的干扰因素,采用不同的信号处理算法。
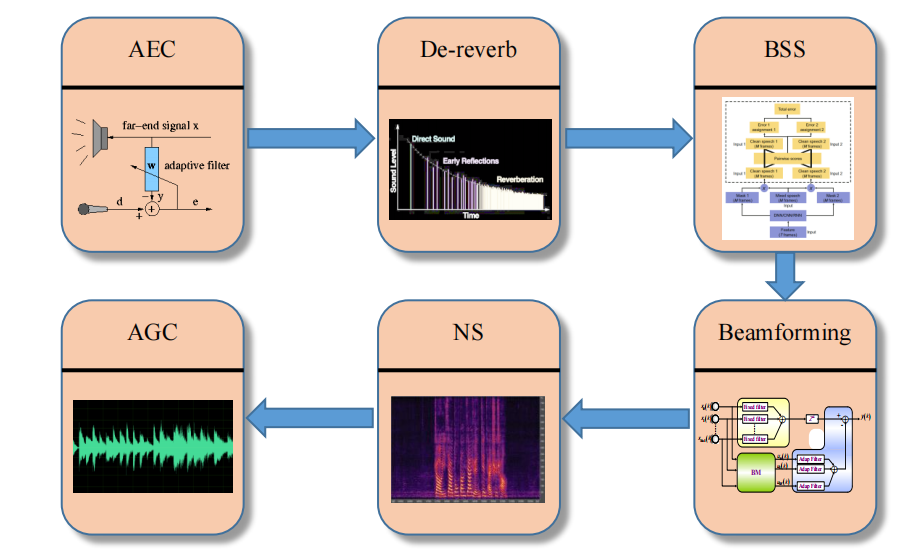
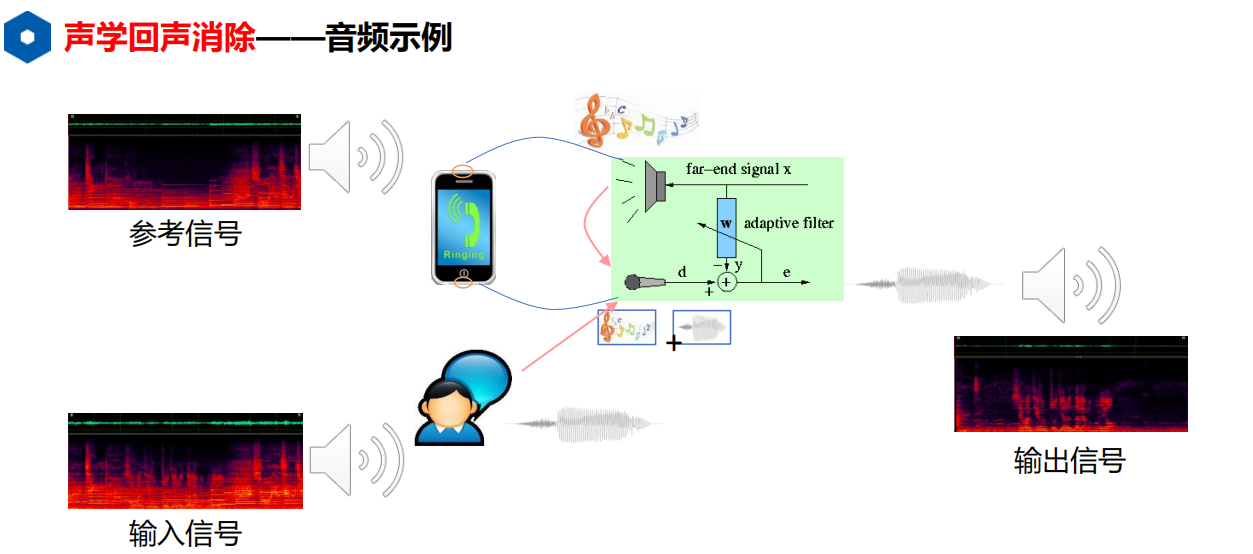
1)声学回声消除模块(AEC: Acoustic Echo Cancellation)
该模块一般位于一个人机交互系统的最前端,和唤醒系统联系紧密。
2)解混响模块(De-reverb)
解决的是远讲语音产生的混响效应。
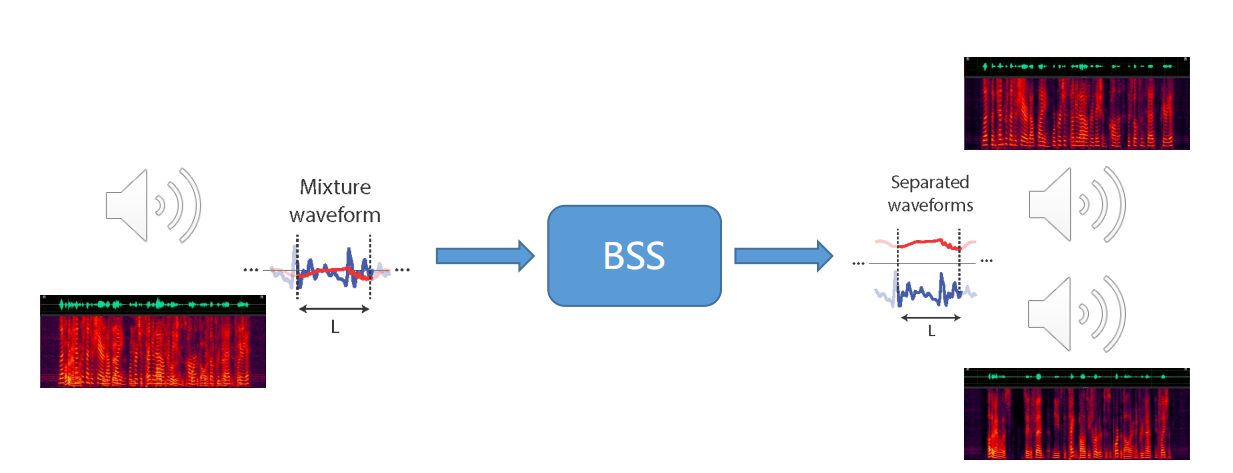
3)盲源分离模块(BSS: Blind Source Separation)
单/多通道的盲分离,干扰因素一般是方向性干扰,即人声干扰。主要是分离出干扰人声的信号,提取出目标人声信号(比如:A对着音箱下达指令的同时,B站在旁边说了一句不相干的话)。
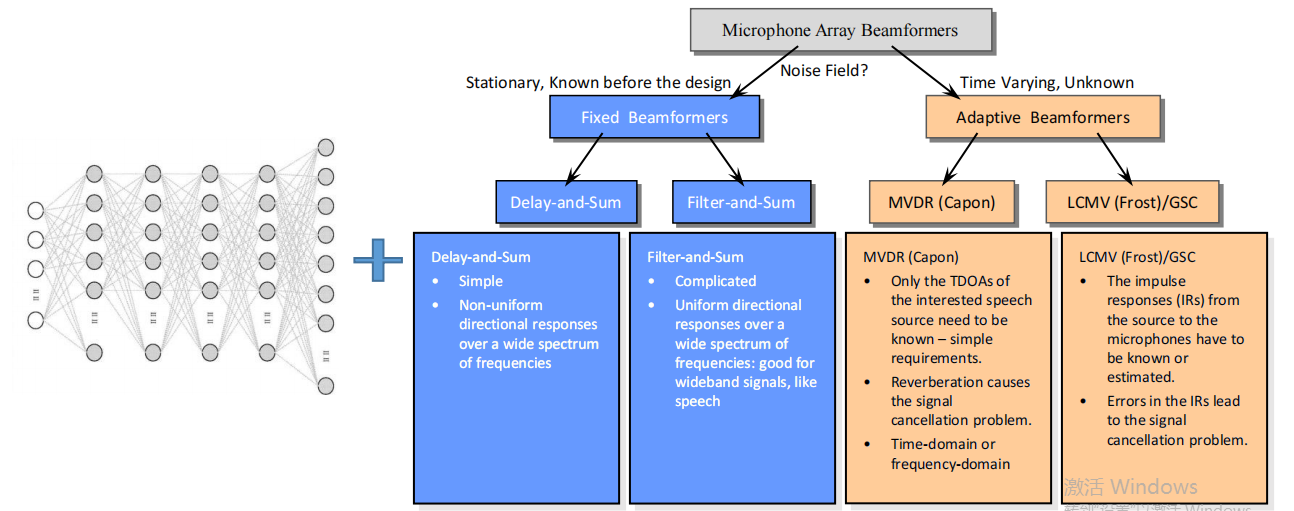
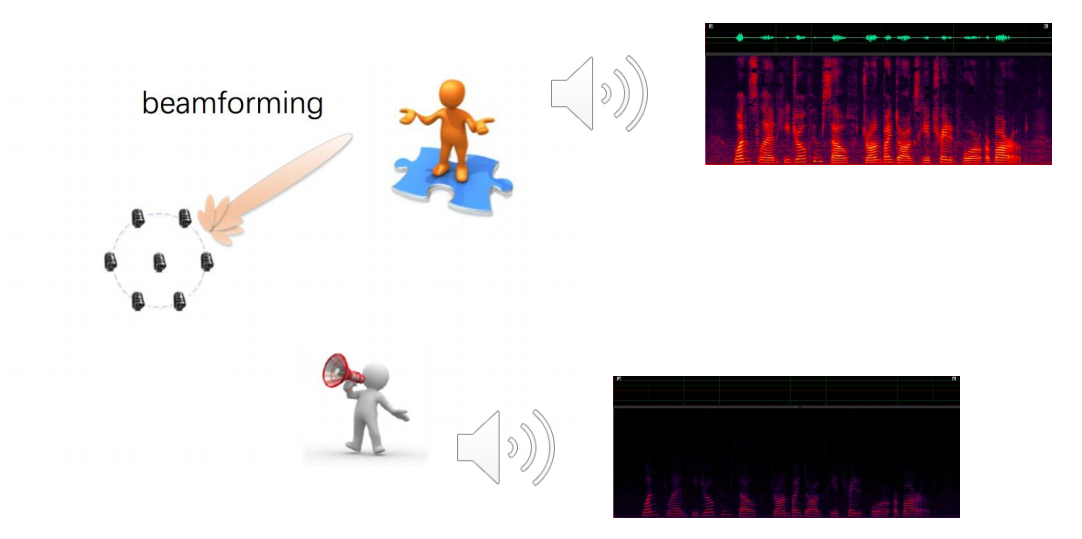
4)波束形成模块(Beamforming)
需要多个通道,多个麦克风,即一般由麦克风阵列来实现。
5)噪声抑制模块(NS: Noise Suppression)
尽可能地消除周围环境的背景噪音。
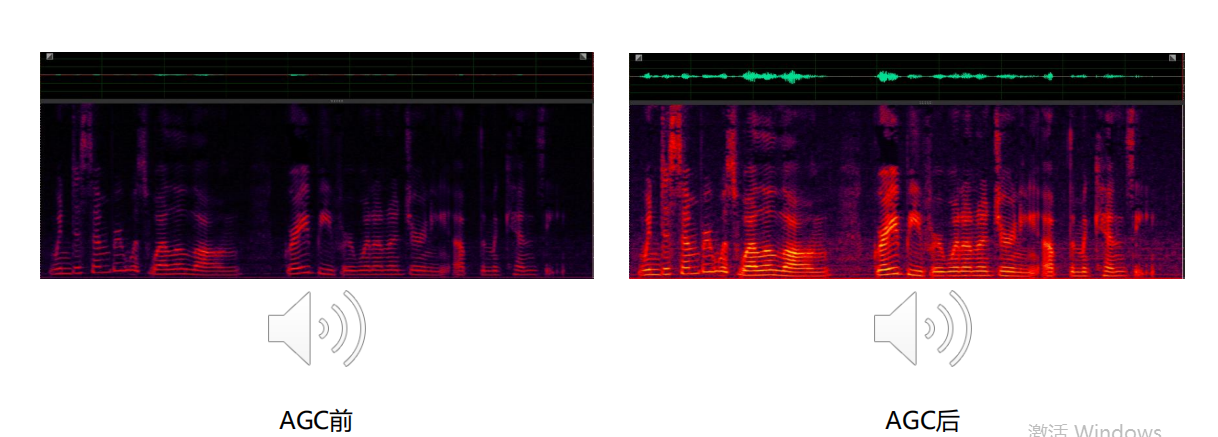
6)幅度控制模块之自动增益控制模块AGC
幅度包括由小变大的拉升、大变小的压缩。交互场景一般是远距离,远场语音交互,那么语音到达拾音模块的时候,能量已经损失,所以大部分情况下需要将幅度拉伸,变大,再送给ASR系统进行识别。
2.1 回声消除
消除设备自身产生的干扰。因为回声指的是设备自己产生的。

2.2 去混响

2.3 语音分离(盲分离)

2.4 波束形成
用于多通道语音增强、信号分离、去混响以及声源定位。主要是:多通道语音增强和声源定位。
2.5 噪声抑制
消除或抑制环境噪声,还有一点是增强语音信号。

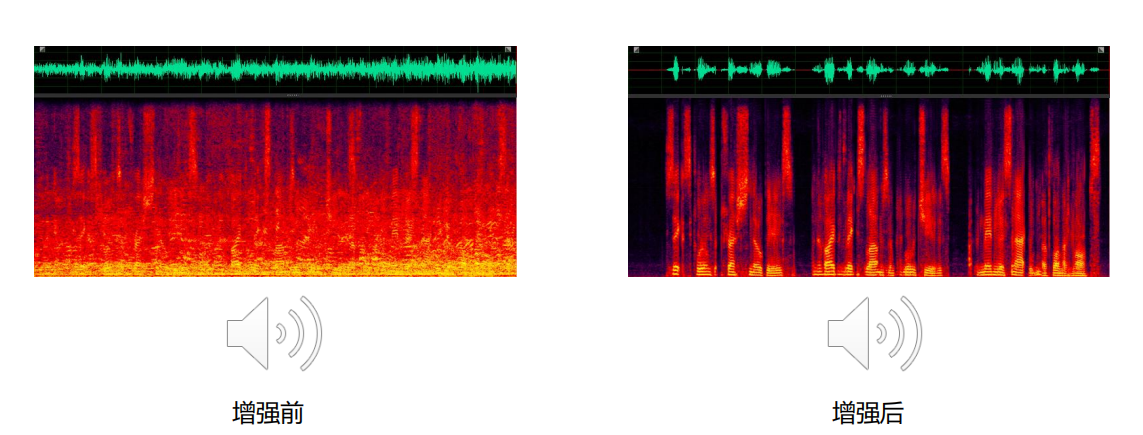
2.6 幅度控制

四、前端信号处理技术路线
在深度学习出现之前,语音信号处理使用的都是传统的处理技术。
1. 传统的前端信号处理方案
1.1 处理依据是“规则”
(1)客观物理模型,即声音传播的物理规律
(2)语音信号的特性:时域特性、频域和空域特性
针对不同的干扰因素,采用不同的信号处理算法加以解决。
1.2 优化目标
抑制干扰信号,提取目标信号。
1.3 优化准则
最小均方误差准则,MSE(Meam Square Error)。
2. 信号处理和深度学习的结合
2.1 处理的依据是“规则+学习”
1)客观物理模型
2)语音信号的特性:时域特性、频域和空域特性
3)海量音频数据先验信息
即保留了声音传播的物理规律和信号本身的特性,又引入了先验数据统计建模的方法。
2.2 优化准则
也是MSE准则。
3. 基于深度学习的前后端联合优化方案
3.1 处理依据是“端到端的联合建模”
1)输入多通道麦克风信号,输出语音识别结果
2)利用近场数据,仿真得到海量的带有各种干扰的训练数据
将前端信号处理和后端ASR声学模型联合建模,用一套深度学习模型完成语音增强和语音识别任务。
3.2 优化准则
识别准确率。
五、参考书籍


六、开源项目和学习代码
(1)Athena-signal
链接:https://github.com/athena-team/athena-signal
(2)Python for Signal Processing
链接:https://github.com/unpingco/Python-for-Signal-Processing
《Python for Signal Processing: Featuring IPython Notebooks》对应源码,包含信号处理12大类(采样定 理、傅里叶变换、滤波器等)、随机过程15大类(高斯马尔科夫、最大似然等)
(3)Speex
(4)Google WebRTC
(5)VOICEBOX: Speech Processing Toolbox for MATLAB
链接:http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141541.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
