大家好,又见面了,我是你们的朋友全栈君。
三篇综述链接:
- 深度学习方法在负荷预测中的应用综述(论文阅读)
- 光伏发电量和用电量的概率预测研究综述(1)
- 光伏发电量和用电量的概率预测研究综述(2)
- 光伏发电量和用电量的概率预测研究综述(3)
- 能源预测:回顾与展望(IEEE论文)
目录
前面只是对三篇综述大致浏览了一遍,并画出了重点,今天将三篇综述的论文整合如下(重点是电力负荷预测)。
1.深度学习方法在负荷预测中的应用综述
本篇论文主要介绍了当下用于智能电网电力负荷预测的多种DL方法,并对它们的效果进行了比较。对于RMSE的降低效果上,集成DBN和SVM的方法RMSE降低显著,达到了21.2%。此外,PDRNN方法与ARIMA方法相比有很大的降低,达到了19.2%。而使用带有k-means的CNN相比于只使用CNN,下降百分比也达到了12.3%。
简单来说,所谓监督学习(Supervised learning),是指利用一组已知类别的样本调整分类 or 回归的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习可以理解为学生从老师那里获取知识、信息,老师提供对错指示、告知最终答案。 学生在学习过程中借助老师的提示获得经验、技能,最后对没有学习过的问题也可以做出正确解答。“老师提供对错指示”这句话很关键,它告诉我们:我们的训练样本,都是有“标准答案的”,比如分类,你在训练的时候就已经知道了它的正确类别,比如回归,你在训练的时候同样也提前知道了真实值。
监督学习要实现的目标是“对于输入数据X能预测变量Y”。这个预测可以是分类,也可以是具体的一个数值。
无监督学习的样本是没有标记的,无监督学习的最典型代表就是聚类。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。
表1是2014 – 2016年发表的负荷预测论文中使用的DL方法的综述论文集合:
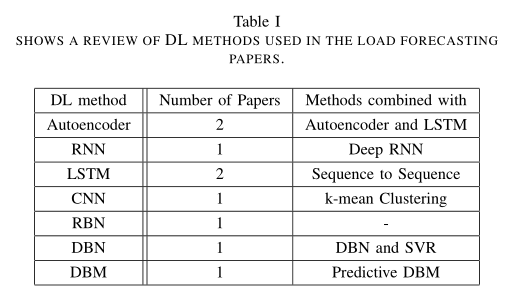

可以看到,机器学习方向有SVM和k-means参与到了预测之中,DL仍是主流。
下面将简要概述SG中最新负荷预测问题的相关DL架构。
DL被应用于短期预测(STLF)、中期预测(MTLF)和长期预测(LTLF)。 电力负荷预测受到多方面因素影响,比如时间,天气以及客户类型等,特别是对于短期预测来说更是如此。一般文献中对LTLF的研究时间间隔多为一个小时到几周,MTLF为一个月到五年,LTLF的平均使用周期为5~20年。
使用期限不同,相应地被应用到不同方面,STLF应用于实时控制、能量转移调度、经济调度和需求响应;MTLF用于规划近期的发电plan,并显示电力系统在时间间隔内的动态;LTLF用来根据规模和类型来规划发电plan,以满足未来的需求和成本效益。
去噪自编码器被用于短期的电价预测,针对前一天的预测有着很好的效果;另外,自编码器与LSTM结合比之一般的DL方法,RMSE也有所下降。
在大多数论文中,我们使用RMSE和平均绝对误差(MAE)来评价所提方法的性能,并将其与其他文献中的方法进行比较。其表达式如下:

其中x是测量的输入时间序列,y是预测的输出时间序列,N是时间序列的样本个数。
神经网络技术广泛应用于负荷预测问题,本文重点综述了目前应用于SG负荷预测的各种DL方法的研究现状,可以总结如下:
- 堆叠降噪自编码器算法用于电价的STLF,其对于前一天的预测效果很好。
- 自动编码器和LSTM算法相结合,为可再生能源发电厂的预测提供了良好的RMSE结果。
- 爱尔兰智能电表的负荷预测方面,深度RNN显示出优于其他预测方法(如ARIMA、SVR)的性能。
- 基于LSTM的Seq2Seq在1小时分辨率下表现良好。
- 采用k-means的CNN对冬夏STLF有着较好的预测性能。
- RBM用于客户的负荷预测,与ARIMA、DSHW和SSN相比,RBM的性能较好。
- DBN和支持向量机相结合,获得了最佳的负荷预测性能。
- 预测DBM应用于智能电网的风速预测,在RMSE方面,与AR和SVR相比表现出了良好的性能。
2.光伏发电量和用电量的概率预测研究综述
本文重点介绍了以下两个方面:
- 太阳能概率预测(PSPF)和负荷预测(PLF)领域的最新进展。一个重要的发现是:没有一种特定的模式可以适用于任何情况!
- 分析现有技术并评估不同方法的性能,以及这些方法在何种程度上可以推广,以便它们不仅在其设计的数据集上表现最佳,还可以在其他数据集或不同的案例研究上使用。
重点关注负荷预测!!电力消耗的预测被认为是一个相对成熟的领域。但SG的出现带来了需求响应与需求侧的管理的问题,需求响应将变得更加具有动态性。
传统上讲负荷预测按极短期负荷预测(VSTLF)、短期负荷预测(STLF)、中期负荷预测(MTLF)和长期负荷预测(LTLF)进行划分,预测区间分别为1天、2周、3年和30年。但是也有一些更为粗略的划分,比如只是分为短期和长期,还有的分为STLF、MTLF和LTLF,预测窗口分别为1小时到1周、1周到1年和1年以上,这个标准并不是固定的。
这一段总结了前面提到的几篇论文具体干了些什么事情。我认为值得注意的有:
- [26]中讨论了17篇负荷预测文章,之后他们将重点放在了他们认为以前没有做过的概率负荷预测(PLF) 上,说明PLF涉及的人还不是很多。
- [23]以及[36]发现了一个趋势,尽管人工神经网络(ann)仍然是目前使用最多的对辐照度和负荷进行预测的模型,但梯度增加,随机森林和支持向量机在科学界得到越来越多的关注。
- [22]评估并比较了三种不同类型的ann在预测中国日全球辐照量方面的性能。他们发现,精度强烈地依赖于模型和位置,有时产生显著不同的结果,但总体多层感知器(MLP)和径向基神经网络(RBNN)优于其余的神经网络和物理模型。
2.1 Basic definitions and comparison models
提供具有PDF(概率密度函数)或预测区间的实用程序,即预测随机变量以特定概率测量的未来生产和需求的间隔可以说比单个值更有价值,因为它允许风险管理。应当注意,预测区间和置信区间不相同。
重点来了:要在概率预测中构建PDF,通常有两种方法。首先,可以假设密度函数,这是参数方法。其次是非参数方法,其中没有做出这样的假设。然而,假设分布很少代表观察结果并且通常是无效的,或者至少是次优的,这说明参数方法存在一定局限性。因此,综述的大多数论文都考虑非参数方法。
晴空模型旨在模拟晴天条件下的直接法向辐照度(DNI)和漫反射水平辐照度(DHI) ,同时考虑太阳的几何形状和气象输入,如水汽含量。
晴天辐照度通常用于标准化太阳辐照度,以便对时间序列进行固定。 通过晴空模型或地外辐照度建模的晴空辐照度实现归一化。前者的结果称为晴空指数,其表述如下:
k t = I t I t c l r k_{t}=\frac{I_{t}}{I_{t}^{clr}} kt=ItclrIt
其中 I t I_{t} It是辐照度, I t c l r I_{t}^{clr} Itclr是晴空辐照度,辐照度/晴空辐照度,即晴空辐照度归一化, k t k_{t} kt称为晴空指数,用于持久性预测。
地外辐照度归一化定义为清晰度指数 K t K_{t} Kt:
K t = I t I t e x t r K_{t}=\frac{I_{t}}{I_{t}^{extr}} Kt=ItextrIt
其中 I t e x t r I_{t}^{extr} Itextr是地外辐照度. 当然,由于没有大气层,地外辐照度比晴朗的天空辐照度更容易建模。
Inman等人提到的一种简单的地外辐照度模型表述为:
I t e x t r = I 0 c o s ( θ t ) I_{t}^{extr}=I_{0}cos(\theta_{t}) Itextr=I0cos(θt)
其中太阳常数 I 0 I_{0} I0=1360W/m2, θ t \theta_{t} θt是时间t处的太阳天顶角。
最后,值得注意的是,晴空指数 k t k_{t} kt总是大于清晰度指数 K t K_{t} Kt,因为晴空辐照度总是低于地外辐照度。也就是公式1的分母是小于公式2的分母的,而它们分子相同。
2.2 Benchmarks for deterministic forecast
关于负荷预测,没有单一的普遍基准,而是存在各种各样的基准。 本段介绍了本文所述论文中使用的几个基准,其中最简单的一个是持久性方法,即与 SPF一样的朴素预测器。
另外一种常用的基准我们称之为:双季节性Holt-Winters-Taylor(HWT)指数平滑(ES),该方法的优点在于它能够结合两种季节性模式,例如,日内和周内循环。它的数学公式如下:

其中 α , γ , δ 和 ω \alpha,\gamma,\delta和\omega α,γ,δ和ω是平滑参数, x ~ t ( k ) \tilde{x}_{t}(k) x~t(k)是预测范围k的预测。此外,季节性指数 s 1 s_{1} s1和 s 2 s_{2} s2确定调查中的季节周期,例如,对于上述日内和周内周期, s 1 = 24 s_{1}=24 s1=24和 s 2 = 68 s_{2}=68 s2=68。
Vanilla是Hong[28]在2010年提出的一种基准方法,它将新近效应考虑在内,这是心理学中的一个术语,暗示人们往往会记住他们最近读到的最好的东西。这意味着当进一步观察时,当前负荷需求对过去温度测量的依赖性降低。对此的适当数学表示是温度的移动平均值(MA)。Vanilla基准假设未来的电力需求仅取决于日历变量和温度,还包括例如小时,周或月与温度之间的相互作用。它的表述如下[49]:
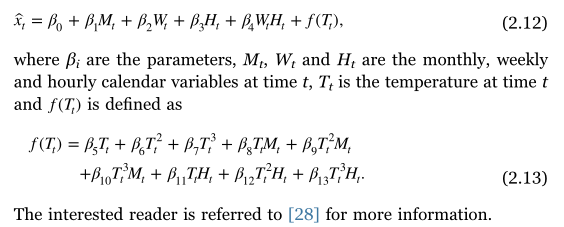
其中 β i \beta_{i} βi是参数, M t , W t , H t M_{t},W_{t},H_{t} Mt,Wt,Ht是时刻t的月、周、小时的日历变量, T t T_{t} Tt是时刻t的温度, f ( T t ) f(T_{t}) f(Tt)定义为:
f ( T t ) = β 5 T t + β 6 T 2 + β 7 T 3 + β 8 T t M t + β 9 T t 2 M t + β 10 T t 3 M t + β 11 T t H t + β 12 T t 2 H t + β 13 T t 3 H t f(T_{t})=\beta_{5}T_{t}+\beta_{6}T^{2}+\beta_{7}T^{3}+\beta_{8}T_{t}M_{t}+\beta_{9}T_{t}^{2}M_{t}\\+\beta_{10}T_{t}^{3}M_{t}+\beta_{11}T_{t}H_{t}+\beta_{12}T_{t}^{2}H_{t}+\beta_{13}T_{t}^{3}H_{t} f(Tt)=β5Tt+β6T2+β7T3+β8TtMt+β9Tt2Mt+β10Tt3Mt+β11TtHt+β12Tt2Ht+β13Tt3Ht
ARIMA方法通常也可以用作基准,它的一个重要条件是所研究的时间序列是平稳的, 即具有恒定的均值和方差,并且存在几种方法来固定、时间序列,例如差分、变换到对数标度或标准化。
2.3 Benchmarks for probabilistic forecast
据作者了解,目前没有专门用于负荷预测的概率基准。而是用确定性基准创建概率基准。例如,Arora和Taylor([53])使用蒙特卡罗(MC)模拟方法生成双季节 HWT ES方法的概率预测。此外,刘等人 [49]利用姐妹模型,即具有不同滞后温度和滞后日移动平均值的模型,来构建密度分布预测。最后,Quan等人[54]利用ARIMA模型的直接一步法,以构建90%的预测区间。
总结如下: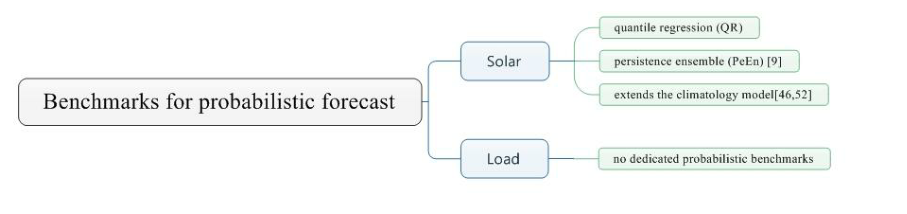
2.4 Performance metrics
确定性预测的性能评估
2.4.1 MAE
平均绝对误差(MAE)通过计算这两者之间的平均误差来显示预测的准确性,可以表述如下:
M A E = 1 N ∑ i = 1 N ∣ x ~ i − x i ∣ MAE=\frac{1}{N}\sum_{i=1}^{N}|\tilde{x}_{i}-x_{i}| MAE=N1i=1∑N∣x~i−xi∣
N是时间序列的长度, x ~ i \tilde{x}_{i} x~i是预测值, x i x_{i} xi是测量值。在比较同一时间序列的多个预测时,此指标非常有用。但由于它与规模有关,因此不能在不同时间序列的预测中使用,因为它具有固有的规模差异。
2.4.2 MSE(RMSE)
均方误差(MSE)和RMSE定义为:
M S E = 1 N ∑ i = 1 N ( x ~ i − x i ) 2 R M S E = 1 N ∑ i = 1 N ( x ~ i − x i ) 2 MSE=\frac{1}{N}\sum_{i=1}^{N}(\tilde{x}_{i}-x_{i})^2\\ RMSE=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(\tilde{x}_{i}-x_{i})^2} MSE=N1i=1∑N(x~i−xi)2RMSE=N1i=1∑N(x~i−xi)2
参数意义同MAE。由于尺度依赖性,它们的适用性同样受到限制。此外,由于误差平方,这些对异常值比 MAE更敏感。然而,因为它们分别提供了对误差的方差和标准偏差的快速认知,这些指标因其在统计建模中的理论相关性而被广泛使用[55]。
2.4.3 MAPE/NRMSE
前面也提到了,平均绝对误差(MAE)、均方误差(MSE)以及均方根误差(RMSE)不能用于比较不同时间序列之间的预测结果。为了能够比较不同时间和空间尺度上的预测,可以使用百分比误差测量。Hoff 等人[59]研究发现,对于太阳能预测(SPF),有几个分母可用于归一化误差。他们发现三个是最合适的,即平均或加权平均辐照度或已产生的功率以及光伏电站的容量。由容量标准化的平均绝对百分误差(MAPE)和归一化均方根误差(NRMSE)表述如下:
M A P E = 100 N ∑ i = 1 N ∣ x ~ i − x i P 0 ∣ N R M S E = 100 N ∑ i = 1 N ( x ~ i − x i P 0 ) 2 MAPE=\frac{100}{N}\sum_{i=1}^{N}|\frac{\tilde{x}_{i}-x_{i}}{P_{0}}| \\ NRMSE=\sqrt{\frac{100}{N}\sum_{i=1}^{N}(\frac{\tilde{x}_{i}-x_{i}}{P_{0}})^2} MAPE=N100i=1∑N∣P0x~i−xi∣NRMSE=N100i=1∑N(P0x~i−xi)2
这里 P 0 P_{0} P0是SPF情况下光伏电站的额定功率。MAPE测量的优点在于它是直接且广泛接受的,例如在风力涡轮机行业[59]。与RMSE类似,NRMSE对异常值也比MAPE更敏感。 有时候,式(2.20)(2.21)用测量值归一化,即把 P 0 P_{0} P0换成 x i x_{i} xi,其缺点是假定具有含义的绝对零值,例如在温度和开尔文尺度的情况下。
2.4.4 MBE
为了评估预测的偏差,即模型是否过高或过低估计,应该利用平均偏差误差(MBE),其表达式如下:
M B E = 1 N ∑ i = 1 N ( x ~ i − x i ) MBE=\frac{1}{N}\sum_{i=1}^{N}(\tilde{x}_{i}-x_{i}) MBE=N1i=1∑N(x~i−xi)
2.4.5 MASE
最近,Hyndman和Koehler[55]提出了一种新的度量,旨在独立于规模,对异常值的敏感性低于基于相对误差的相对测量和度量的方法。在平均绝对标度误差(MASE)中,使用基准方法的样本内MAE(即持久性方法)来缩放误差。MASE的表述如下:
M A S E = M A E 1 n − 1 ∑ i = 2 N ∣ x i − x i − 1 ∣ MASE=\frac{MAE}{\frac{1}{n-1}\sum_{i=2}^{N}|x_{i}-x_{i-1}|} MASE=n−11∑i=2N∣xi−xi−1∣MAE
2.4.6 ρ \rho ρ
两个变量之间的线性相关性,即测量值 x x x和预测值㼿 x ~ \tilde{x} x~,可以通过 Pearson相关系数确定,并定义如下:
ρ = c o v ( x , x ~ ) σ x σ x ~ \rho=\frac{cov(x,\tilde{x})}{\sigma_{x}\sigma_{\tilde{x}}} ρ=σxσx~cov(x,x~)
这里,ρ=1表示总正相关,ρ=0不相关,ρ=−1总负相关。由于协方差cov表示两个变量一起变化多少,因此可以以类似的方式解释相关系数。例如,系数1意味着两个变量具有相同的趋势。
2.4.7 R 2 R^2 R2
确定系数 R 2 R^{2} R2是度量统计模型在多大程度上适合数据并且描述误差的方差和测量值的方差在何种程度上重合的度量。 R 2 R^{2} R2可以定义如下:
R 2 = 1 − σ 2 ( x ~ − x ) σ 2 ( x ) R^{2}=1-\frac{\sigma^{2}(\tilde{x}-x)}{\sigma^{2}(x)} R2=1−σ2(x)σ2(x~−x)
2.4.8 KSI
Kolmogorov-Smirnov 积分(KSI)量化了预测和测量在何种程度上来自同一分布,适合在较长时间尺度上进行比较。这是一个非参数测试,其公式如下:
K S I = ∫ x m i n x m a x D n d x KSI=\int_{x_{min}}^{x_{max}}D_{n}dx KSI=∫xminxmaxDndx
其中 D n D_{n} Dn是每个时间间隔的累积分布函数之间的差异,定义如下:
D n = m a x ∣ F ( x i ) − F ~ ( x i ) ∣ , x i ∈ [ x m i n + ( n − 1 ) p , x m i n + n p ] D_{n}=max|F(x_{i})-\tilde{F}(x_{i})|,x_{i}\\ \in[x_{min}+(n-1)p,x_{min}+np] Dn=max∣F(xi)−F~(xi)∣,xi∈[xmin+(n−1)p,xmin+np]
其中,F和 F ~ \tilde{F} F~分别表示预测和测量的累积分布[61]。此外,p是间隔距离,并表示为:
p = x m a x − x m i n m p=\frac{x_{max}-x_{min}}{m} p=mxmax−xmin
这里m是离散化水平,根据Espinar等人的说法 [61]选择为100,因为更高的m不会增加精度,反而带来计算时间的代价。为了确定零假设,即预测值和测量值是否具有相同的分布,可以以99%置信水平接受,Dn应低于阈值 Vc,其公式如下:
V c = 1.63 N , N > = 35 V_{c}=\frac{1.63}{\sqrt{N}},N>=35 Vc=N1.63,N>=35
其中N是时间序列的长度[61]。从式(2.26)可以看出,人们可以在整个测量范围内评估预测的累积分布与测量值的偏差,其中 KSI 值为零意味着两个分布相等。KSI测试相对于Kolmogorov-Smirnov(KS)测试的优势在于,除了总结是否拒绝或接受上述零假设外,还可以量化误差[61]。
概率预测的性能指标
2.4.9 PICP
显然,概率预测的目的是确保观测的概率分布在预测区间内。为了评估是否是这种情况,可以计算预测区间覆盖概率(PICP) ,其公式如下[64]:
P I C P = 1 N ∑ i = 1 N ϵ i PICP=\frac{1}{N}\sum_{i=1}^{N}\epsilon_{i} PICP=N1i=1∑Nϵi
这里 ϵ i \epsilon_{i} ϵi定义为:
ϵ i = { 1 i f x i ∈ [ L i , U i ] 0 i f x i ∉ [ L i , U i ] \epsilon_{i}=\left\{ \begin{array}{rcl} 1 & & {if\ x_{i} \in [L_{i}, U_{i}]}\\ 0 & & {if\ x_{i} \notin [L_{i}, U_{i}]} \end{array} \right. ϵi={
10if xi∈[Li,Ui]if xi∈/[Li,Ui]
其中 L i L_{i} Li和 U i U_{i} Ui分别代表预测区间的下限和上限。根据 ϵ i \epsilon_{i} ϵi的公式,我们可以推断出PICP高就意味着更多的结果位于预测区间的范围内,这显然是好的。PICP度量是可靠性的定量表达,应该高于标称置信水平,因为它们是无效的并且应该被丢弃[65]。
2.4.10 PINAW
用预测区间归一化平均宽度 (PINAW)同时分析 PICP,这是一种定量评估预测区间宽度的度量。PINAW 定义如下[64]:
P I N A W = 1 N R ∑ i = 1 N ( U i − L i ) PINAW=\frac{1}{NR}\sum_{i=1}^{N}(U_{i}-L_{i}) PINAW=NR1i=1∑N(Ui−Li)
其中R表示预测区间平均宽度的归一化,并表示最大预测值减去最小预测值。
2.4.11 CWC
Khosravi等人[66]注意到PICP和PINAW通常具有直接关系,其中预测间隔(PINAW)的高宽度意味着结果的高覆盖率(PICP) ,因此提出了同时评估两者的定量测量。尽管作者将其命名为基于覆盖长度的标准(CLC),但后来它被重命名为基于覆盖宽度的标准 (CWC) ,参见例如[64]。 CWC的表述如下[64]:
C W C = P I N A W ( 1 + γ ( P I C P ) e − η ( P I C P − μ ) ) CWC=PINAW(1+\gamma(PICP)e^{-\eta(PICP-\mu)}) CWC=PINAW(1+γ(PICP)e−η(PICP−μ))
其中η和μ是控制参数,训练期间 γ(PICP)=1。参数μ表示在训练阶段期间要实现的预分配的PICP,并且为了选择该参数,标称置信水平[(1−α)%]可以用作指导。此外,η是一个惩罚项,如果不满足预分配的 PICP,将导致CWC指数增长。当PICP≈μ时,人们已经实现了PICP和 PINAW之间的平衡,并且可以继续测试模型[64]。 然后,根据μ确定具有 γ(PICP)的CWC,其公式如下:
γ ( P I C P ) = { 0 i f P I C P ≥ μ 1 i f P I C P < μ \gamma(PICP)=\left\{ \begin{array}{rcl} 0 & & {if\ PICP \geq \mu}\\ 1 & & {if\ PICP < \mu} \end{array} \right. γ(PICP)={
01if PICP≥μif PICP<μ
此外还有连续排名概率得分(CRPS) ,弹球失控函数和温克勒得分。
2.5 Forecasting techniques
虽然在SPF中,时间序列方法(如ARIMA)和基于人工智能(AI)的方法(如人工神经网络)都被认为是统计方法,但在负荷预测中,通常会对统计方法和基于人工智能的方法进行区分。
2.5.1 统计方法
一个典型的基准方法是概率预测的非参情况,确定性预测的基准方法通常是持久性模型。
对于统计方法,参数化的体现是ANN或者ARIMA等,但不在本文讨论范围之内。几种(统计)非参数方法:
- 分位数回归(Quantile Regression,QR)
- 分位数回归森林(Quantile Regression Forests,QRF)
- 高斯过程(Gaussian Processes, GP)
- 自举法(Bootstrapping)
- 限上限估算法(LUBE)
- 梯度提升(Gradient Boosting,GB)
- 核密度估计(Kernel Density Estimation, KDE)
- K近邻(KNN)
- 模拟集成(Analog Ensemble, AnEn)
2.5.2 物理方法
通过物理方法,通常的做法是假设描述错误的密度函数。其原因在于物理方法允许在非参数方法方面的变化较小,因为在那种情况下需要应用统计方法形式的后处理。这通常被称为混合方法,并在第3.3节中详细说明。
参数方法依赖于将预测方法的误差建模,在这种情况下是物理模型,作为特定密度函数,例如,法线,β或伽马。这可以通过几种方式实现。例如,Lorenz等人[8]将预测误差建模为正态分布,随后评估误差是否依赖于晴空指数和太阳天顶角。然后将该依赖性建模为四阶多项式,之后可以估计未来的误差。
如前所述,非参数方法的可能方法几乎没有变化。实际上,目前正在使用一种方法,称为集成预测。该方法依赖于NWP模型的多次运行,但在初始和边界条件下的微小扰动,被设计为在统计上相同。通过这种方式,产生了若干确定性预测,之后可以从这些预测中构建密度预测。这种方法的缺点是运行NWP模型在计算上要求很高,尤其是几次带有扰动的运行。
2.5.3 混合方法
如前所述,NWP模型构建概率预测的密度函数的能力有限。同样,基于天空图像的预测也缺乏生成PDF的能力。因此,存在混合方法,其中物理方法的后处理通过统计方法完成,以便消除偏差并构建密度函数。
楚等人[88]提出了一种基于天空图像和五种统计模型的混合方法,即四个ANN和一个支持向量机(SVM),分别用于预测平均DNI和相关标准偏差并对变异周期进行分类。在假设这些是正态分布的情况下,利用方差来构建预测区间。
另一个例子是Sperati等人[89]的工作,他们利用欧洲中期天气预报中心(ECMWF)集合预报系统(EPS)对NWP模型进行集成预测,之后使用NN来减少偏差并创建PDF,以及其他两种后处理技术,将在下一节中详细说明。
2.6 Review sorted on temporal horizon
2.6.1 Intra-hour
小时预测通常基于统计方法,关于负荷预测,小时内预测相当罕见,即消费数据的分辨率比较粗狂。然而,智能表计的最新发展允许以更高的时间分辨率进行测量,这就允许降低时间范围。
负荷。如前所述,用一小时甚至一天的时间来预测电力需求是相当不寻常的。因此,本节仅综述在此范围内进行的两项研究。第一个是Bracale等人[99]的研究中,结合贝叶斯推理(BI)方法的随机时间序列被用来创建15分钟和24-48小时的范围的概率预测。此外,根据时间序列是否差异(正态分布)(Weibull或Log-Normal分布),利用若干密度函数来构建单个国内负载的预测间隔和五个国内负载的总和。所提出的模型使用测量和参数的先前PDF以及ARIMA对平均值的预测来通过BI导出先前PDF的共轭分布,以便建立国内负荷的预测后验分布。结果显示,与概率持续性相比,改善了27-31%。此外,结果表明,假设正态分布的方法提供了最好的可靠性,与理想可靠性的最大偏差小于3%。
第二个是Guan等人[100]的研究,以时间分辨率5分钟预测每小时范围的负荷,即随后的一小时内每5分钟有12个预测。为了实现这一点,作者将负荷数据分解为不同频率的三个分量,用于三个小波NN(WNN)。另外,使用日历变量作为WNN的输入,以帮助它们识别负载数据的周期性模式。然后通过混合卡尔曼滤波器训练WN-N,其具有可用于导出预测间隔的创新协方差作为输出之一。根据协方差,在正态分布的假设下,方差估计可以通过频率的正交性获得并加在一起,以确定总体方差。虽然没有使用概率性能指标来评估预测区间,但作者表明,正态性假设仅在去除尾部后才有效,因为它们比高斯分布更重。
2.6.2 Intra-day
Almeida和Gama[114]提出了一种基于NN构建预测区间的方法,其提前期为0-24小时且具有每小时分辨率。作者使用了45个不同类型消费者所连接的变电站的总负荷需求。他们认为,由于存在许多不同的负荷配置文件,因此需要对这些配置文件进行聚类以提高预测性能。聚类是通过Kulback-Leibler距离进行的,因为欧几里德距离在处理较不稳定的数据(如住宅负荷)时会造成困难。为了创建非参数预测区间,采用了两种不同的方法。第一种是双扰动和组合方法(DPC),其中使用轻微扰动的数据进行预测。第二种方法是共形预测(CP),它假设数据是相同且独立分布的(i.i.d.),查看过去的数据以确定未来预测的置信水平。多层感知器(MLP)的输入是压延变量和负载曲线的过去值,属于某个簇。从结果看来,DPC方法在所有簇上显示出比CP更一致的PINAW性能,平均为20%。此外,可靠性图表明,在负载需求变化很大的集群的情况下,覆盖概率显着降低。不幸的是,在没有提到PICP达到63%和96%的信心水平的情况下,给出了一个说明PICP的情节。
2.6.3 Day-ahead
刘等人[49]提出了一种有趣的方法,其中使用QR平均(QRA)将几个确定性预测整形为概率预测。确定性预测由所谓的姐妹模型创建,即具有相似结构但以不同时间滞后和不同训练数据长度运行的回归模型。此外,这些回归模型具有第2.4节中提到的新近效应。然后,应用QRA,其基于所有点预测最小化分位数q的分位数损失函数,以估计最佳参数集。使用了四种不同的训练数据长度,并使用滚动方案应用这些长度,这意味着更新了参数。在选择QRA模型的最佳组成时,作者表明,根据所使用的指标,即弹球,温克勒得分(50%)或温克勒得分(90%),QRA需要7或8个姐妹模型和183或365几天的校准数据。所提出的方法的显着优点在于它可以与许多点预测方法一起使用,在相同QRA模型中的不同方法与具有不同训练方案的单个方法一起使用。最好的QRA模型显示弹球得分为2.85,Winkler得分(50%)为25.04,Winkler得分(90%)为55.85。
虽然研究(参见例如,[43],[44])已经提供了证据,假设表示错误的分布通常是无效的,或者至少是次优的,Xie等人[68]试图从另一个角度接近关于预测密度的假设。作者不是试图证明假设是否无效,而是试图通过假设高斯分布来提高概率预测的质量。本文中使用的回归模型是2.4节中描述的Vanilla模型。这些模型取决于温度,因此,为了创建预测密度,使用30年的历史数据来创建30个天气情景,这些情景又用于创建30个确定性预测,利用这些预测可以计算所需的分位数。结果表明,正态性假设确实无效,但是,当残差基于压延变量分组时,KS检验的合格率是显着的。然后,添加额外的模拟高斯残差来检查更高的通过率是否导致更好的分位数分数,这导致了有趣的结论。首先,如果基础模型的准确性较差,则此方法有助于改进预测,但如果基础模型显示出良好的准确性,则这可以忽略不计。其次,在KS测试和分位数分数之间没有发现趋势,这导致了更高的合格率并不表示更好的分组选项的结论。为了评估其结论的有效性,人工神经网络也被采用并显示出类似的结果[68]。
Taieb等人[72]使用智能仪表数据在家庭层面上研究PLF的少数研究之一。预测方法基于增强附加QR,其在分位数的可加性假设下将加性QR与GB组合,即可以通过例如GB添加若干模型来估计每个分位数。在本文中,聚合和个人需求概况被认为是提前一天生成每小时的预测。除了考虑需求概况外,由于温度和电力消耗之间的高度相关性,还考虑了附近机场的温度曲线。此外,由于个人需求通常接近于零,作者进行了平方根变换以保证非零预测。结果表明,以一天中的时间为条件的基准,即考虑到日历变量,显示出比无条件基准显着改善,这导致确认这些变量的重要性。此外,对于增加的预测范围,该基准和QR在CRPS方面表现出类似的表现,这表明这些变量对于滞后的变量的重要性。最后,通过产生足够宽的预测密度来满足不稳定的需求,QR在分解规模上优于正常假设,超过了基准。然而,在汇总水平QR显示缺乏锐度。
另一项考虑智能仪表数据的研究由Arora&&Taylor[53]执行,他们将非参数方法基于条件核密度(CKD)估计。然而,与Taieb等人[72]在智能电表数据预测中讨论的先前研究相反。由于潜在的有限可用性和可负担性,本作者未包括天气变量。结果发现,住宅消费者的需求模式在一周内没有显着变化,因此季节性因素被选择为每日和每周。为了考虑假期,将该日与前一个假日和上一个星期日进行比较,之后假期将被视为最相似的假期。关于CKD,它是KDE的扩展,作者估计变量 x ^ \hat{x} x^的响应,以变量x为条件,有效地估计二维而不是一维的核。此外,已经提出了几种CKD结构,以确定最有效的结构,范围从以星期和一天的时间为条件到日内循环的类型。在这些方法中,有趣的是,实际上有四种基于CKD的方法和一种基于KDE的方法非常相似,后者基于考虑日内周期。发现CRPS介于0.013和0.055之间,最大的误差发生在易失时间段内。此外,该方法在预测时间为6小时的情况下也表现出最高的可靠性,而对于更长的交付周期,其他方法以及HWT基准也显示出非高的准确性。
巴塔等人[127]旨在利用欧洲输电系统电力运营商网络(ENT-SO-E)的开放获取数据,建立国家能源消费预测框架。为了构建预测密度,采用了GB回归树(GBRT),并根据各国自己提供的实际负荷数据和预测进行了基准测试。拟议的框架从收集和存储数据开始,之后建立GRBT模型并用于预测。数据仅包含滞后值,并汇总为每小时值。就点预测而言,拟议的框架表现出良好的表现,尽管相对于现有方法的相对改进取决于该国,因为一些人本身使用非常准确的预测,例如斯堪的纳维亚和比荷卢三国。此外,作者认为很难比较实现这些结果的模型,因为这不是透明的,类似于使用了哪些数据。平均弹球损失为38.144,但由于各国只公布了点预测,因此无法将其置于背景中。
Kou和Gao没有关注住宅用电量,而是提出了能源密集型企业(EIE)的PLF方法,特别是1000MW的钢铁厂。该方法基于高斯过程(GP),其假设方差是正态分布的。然而,由于假设高斯方差不被认为是现实的,作者应用异方差GP(HGP)进行本研究。此外,由于HGP的计算负担很大,作者对数据进行了细化,创建了简化的HGP(SHGP)模型。为了确定最有价值的数据作为回归模型的输入,作者采用了前贪婪的方法,将每个预测器分别合并并计算后续模型的预测误差,之后选择具有最低误差的组合并预测从候选集中删除。在可靠性方面,SHGP优于基准GP和样条QR(SQR),有趣地看到后一种方法一直低估每个分位数的需求。最后,SHGP模型的清晰度低于SQR,尽管不是很明显,使作者得出结论,所提出的模型是一种竞争性替代方案。
另一种参数方法由Wijaya等人[128]采用,扩展了广义加性模型(GAM),它是响应变量线性地依赖于回归量的线性模型,扩展到GAM2,其中第二个GAM应用于平方残差。可以使用GARCH模型将该方法与平方残差建模进行比较,并且由于这些方法很少是同方差的,因此是必要的。首先,使用GAM函数估计平均值,随后将其用于预测,之后在与训练集进行比较时评估误差。然后在这些残差上安装另一个GAM。此外,在每天之后,通过用于添加模型的在线学习算法,向所提出的模型提供当天的数据,以便评估其错误并在必要时更新参数。在不添加在线学习算法的情况下,预测间隔没有覆盖整个置信水平,但是通过添加该算法可以实现。此外,作者表明预测间隔的宽度是令人满意的,尽管未使用2.5.2节中定义的宽度。此外,本文没有使用基准,因此阻碍了相对改进的比较。
Quan等人的两篇论文[64],[54]认为LUBE方法结合NN,在第3节中详细说明,用一周的时间来预测电力负荷。该方法的其他应用集中于最小化CWC,然而,作者认为,由于CWC具有许多参数并且对这些参数敏感,因此通过最小化宽度来解决优化问题可以更有效,同时限制覆盖概率。选择后者作为约束,因为这决定了预测区间的有效性[65]。为了解决优化问题,作者使用了PSO。此外,所提出的方法的性能对NN结构敏感,因此使用PINAW作为评估指标,已经构建了100个候选者,即两个隐藏层的10个神经元,并且对性能进行了测试。该模型显示多次运行的一致性,中位数PICP为90.81%至91.03%,中位PINAW为14.52%至36.53%,CWC为14.52%至36.53%,得分为86.59-4725.06,具体取决于每个城市的负荷变化。此外,它的表现优于基准模型ARIMA,ES和天真模型。最后,计算性能非常高,台式计算机上的预测间隔构建时间低于10毫秒。
为了提高QR的预测准确性并允许其考虑非线性关系,He等人[129]提出基于KDE将NN与QR结合使用。由于QR是线性模型,并且回归量和回归之间的关系通过非线性依赖性更准确地建模,因此作者主张将NN与QR结合起来,如前所述。这意味着每个分位数由NN估计,之后分位数函数被用作KDE的输入以估计和平滑密度函数。尽管该方法是有趣的,但是所呈现的数值结果不允许基准(即,径向基函数QR(RBFQR))与所提出的方法之间的公平比较。更具体地说,根据案例研究,RBFQR的PICP为0%至5.95%,PINAW为1.06e-05%至1.24%。显然,接近零的PINAW与极低的PICP相结合,几乎没有传达关于响应变量概率的信息,因此,所提出的模型总是优于这样的基准。不幸的是,作者没有详细说明这些统计数据,特别是因为他们的方法显示了有希望的结果。
作为考虑非线性关系的另一种尝试,He等人[130]提出利用基于核的SVR与QR结合,因为难以用后者解决非线性问题。通过引入基于内核的SVR,QR的损失函数可以用于优化问题而不是SVR的复数惩罚函数,然后将内核用作相似函数来逼近输入向量的非线性依赖性。最后,为了量化并考虑输入变量(即电价和电力负荷)之间的相关性,作者使用了copula理论。这项研究中有趣的前提确实是实时价格和电力负荷之间的相关性,这表明它具有显着的相互依赖性。培训数据的数量取决于提前期,即提前一天预测的培训数据的十天和提前4天预测的25天的培训数据。对于日前预测,结果显示所提出的模型在PICP和PINAW方面表现良好,PICP为100%,PINAW在15.76%和16.48%之间,具体取决于所选的内核函数。此外,当通过copula考虑实时电价时,PINAW显着降低至11.75%-11.62%。考虑到4天视野的案例研究显示,PICP减少,PINAW增加分别为82.81-96.35%和23.69-30.65%。此外,包含实时电价的改善并不像第一个案例研究那么重要。最后,作者指出,无论使用何种方法,都应包括实时价格。
Xie和Hong[131]没有关注模型,而是比较了两个模型选择框架,特别是PLF。作者认为,PLF的模型选择可以通过点误差测量(第2.5.1节或概率误差测量(第2.5.2节))来完成,并且前者可以被认为是计算密集度较低但在应用于PLF。因此,作者研究了在使用概率误差测量时可以提高准确度的范围。作为模型,使用多元线性回归(MLR),其被馈送到多个温度场景以创建概率预测。使用的误差度量是确定性预测的MAPE和概率预的分位数分数。结果表明,后者的度量确实导致了比使用MAPE时更好的概率预测,但差异可以忽略不计。
以下论文已根据GEFCom2014发表,并在此处以随机顺序进行讨论。首先,盖拉德等人[132]也利用GAM的扩展,即分位数GAM(quantGAM)参与并最终赢得GEFCom2014。首先,通过捕获均值和回归量之间的非线性关系,GAM用于拟合上述均值。然后,作为用于找到均值的最小化过程的结果的平滑函数被用作训练QR的回归量,以便获得每个分位数的估计。由于电力需求在很大程度上取决于一天中的时间,作者将时间序列分成24个,每天一个小时,因此,安装了</font size = 4 color = red>24个不同的模型。此外,由于温度的影响及其不确定性,这些首先被分开了。这意味着首先预测取决于一年中的时间的温度,之后进行以温度为条件的负荷的预测。最后,后者对前者进行了平均,以获得最终的预测模型。该方法在比赛中获得第一名,弹球得分为3.98-10.73,具体取决于月份,夏季月份由于变异性较小而明显显示出更好的结果。此外,虽然未指定哪个模型被用作基准,但是在基准测试中实现了显着的改进。
谢和洪[133]提出了一个PLF框架,其中进行了预处理,预测和后处理。通过使用Vanilla基准模型清理数据来初始化预处理步骤。这是通过用所有可用数据训练模型并随后计算观察和预测之间的绝对百分比误差(APE)来完成的。如果误差大于50%,则该观察将被预测所取代,这是0.05%的数据的情况。预处理的第二部分涉及气象站选择,即哪个匿名气象站将提供最有价值的信息。第一次预测是通过多元线性回归(MLR),即Vanilla基准进行的,之后残差预测是四种方法的平均值,即未观察到的组分模型(UCM),ES,ANN和ARIMA。最终的预测是第一次预测和平均预测的结合。后处理基于Xie等人[68]的论文,其中发现残差的正态性假设可以改善概率预测,因此这里应用了这种方法。结果显示,残差的后处理导致分位数分数方面的改善,有趣的是,在该类别中,平均而言,基准实际上以7.908的分位数得分实际上表现最佳,因此优于模型。结合基准和前面提到的四种模型。不幸的是,作者没有提到为什么会这样。
Mangalova和Shesterneva[134]采用了非参数方法,拟合了一系列Nadaraya-Watson估计器。为了对基本模型进行优化,作者通过最小化分位数来寻找核的最优带宽。为进一步改进所提出的模型,虽然预测结果并无显著改善,但仍以温度作为输入变量。分位数得分在3.93到12.74之间,视月份而定。在夏季的几个月里,变化较少,分位数得分平均较低。该模型的主要优点是可以获得仅依赖于一个参数的预测密度。最后,作者得出结论,在比赛后对转换为分位数的方法进行修改,可以显著提高准确性。
Dordonnat等人[135]使用了GAM温度依赖的确定性负荷模型,基于广义交叉验证(GCV)评分选择了匿名气象站。然后,针对温度偏离移动平均的情况建立AR模型,生成N个样本,然后插入确定性负荷模型,获得N个负荷样本。最后,将确定性负荷模型预测样本与观测样本进行比较,评估误差,量化不确定性,并推导出其分位数。作者指出,MAPE最高的模型,即确定性度量,并不意味着它在用分位数分数评估时表现最好,这是一个明确的信号,表明绩效度量不能互换。表现最好的模型的平均分位数得分为7.37,这个分数确保了Dordonnat等人进入竞赛的前五名。
Ziel和Liu[136]提出了一种基于最小绝对收缩和选择算子(套索)估计的方法。选择了以负荷和温度为输入的VAR模型,并扩展了代表分段线性函数的阈值。这样做的原因是负载与温度之间的非线性关系。但是,为了减少潜在阈值函数的数量并因此减少了计算时间,应用了套索算法,该算法仅选择了显着的非线性影响。由于预测范围是一个小时且具有每小时的分辨率,因此考虑了之前的1200个时滞,即1200小时。此外,选择了八个随时间变化的系数,从而反映了与季节有关的最重要的系数,并尽可能减少了参数空间。相反,作者认为残差是同方的,这一假设在PLF中很少成立。拟议的模型在分位数方面优于Vanilla基准,在竞争中平均为7.44。
Haben和Giasemidis[137]根据GEFCom2014发表了关于PLF的最终论文,我们将其纳入我们的综述。作者以Arora和Taylor[53]的工作为基础,建立了一个温度范围。但是,此处使用的衰减参数是对称的,这意味着将一年中的相似日期纳入预测。此外,QR还参与创建混合模型以通过添加这些模型来确定相对改进。结果发现,以温度为条件的CKD对于日间预报的效果最佳,但对于较长的视野效果较差,这是由于温度预测不准确所致。此外,将不同的CKD与QR结合使用,得出的结论是QR带来了这些组合中所见的大部分改进,并且被认为是平均而言最佳的非混合预测。不幸的是,没有给出平均分位数,但是从给出的图表中估计得出的分数约为8。
Takeda等[138]将EnKF与SSMs相结合,对东京及其周边地区的电力负荷进行了预测和分析。值得注意的是,作者并没有进行概率预测,但主要作者后来研究了EnKF在光伏发电的情况下,并在其中实际上进行了PSPF[113]。作者认为,将SSMs与EnKF结合使用的主要原因是,统计方法,如ann或MLR,不能提供任何关于电力消耗结构变化的洞见。为了进一步提高精度,作者采用了lasso和MLR。由于使用lasso和MLR的结果没有显着差异,他们建议使用lasso,因为它有避免过拟合的能力。在MAPE方面,EnKF+lasso模型获得了1.87%的分数,虽然它优于目前使用的MLR模型,但它没有优于第二个MLR模型的实用程序。
3.能源预测:回顾与展望
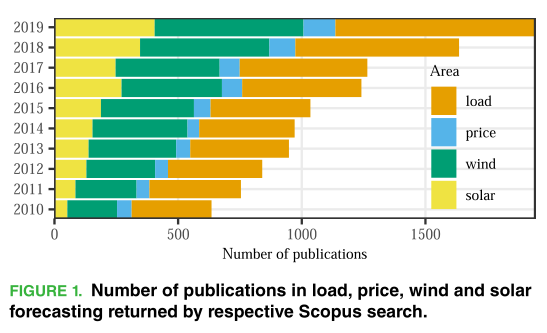
图1显示了过去10年能源预测文献的增长情况。负荷预测文献占能源预测文献的一半左右。在所有四个子域上都可以观察到增加的趋势。可再生能源预测文献的增长势头强于负荷和价格预测,这在很大程度上归因于近十年来全球可再生能源一体化的努力。
3.1 ML/DL
预测的基本假设是假定未来在某种程度上与历史有相似的模式或分布。从历史数据中发现模式或隐藏信息是准确预测的关键。
近年来,由于计算技术的进步,人工智能/ML领域正在经历另一场热潮。各种先进的人工智能/ML技术,如深度学习[27],[28],强化学习[29],迁移学习[30],已被用于能量预测。
深度学习的一个缺点是,它的训练过程比回归模型复杂得多,耗时也长得多。要估计的不仅是参数的纯数量(权值),还有超参数(网络结构、激活函数、停止条件、正则化等)[31]的优化。深度学习技术的应用依赖于不断增加的计算能力和收集的数据。
3.2 组合预测
组合预测已被广泛认为是预测的最佳实践之一。1969年[32]正式讨论了预测组合的好处。后来发表了许多实证研究,证明了组合预测的积极和消极影响。一些值得注意的评述可以在[33]-[35]中找到。
预测组合策略的成功在能源预测文献中很容易找到:
- 在点负荷预测[36]中发现一种同质组合是有效的,在这种组合中,作者通过一系列回归模型生成的所谓的姐妹预测测试了11种组合算法。
- 同样的回归模型被发现是通过分位数回归平均[37]来生成概率负荷预测的良好输入。
- 集成预测方法也被应用到智能电表数据[38]和能源预测的其他子领域,如价格预测[39]-[41]。
- 经验结果表明,对于点预测和概率预测,即使同一模型的预测仅在几个短窗口和几个长窗口上取平均值[42],[43],如果结合起来,预测的质量都能显著提高。
集成预测的另一种方法是利用数据空间和参数空间来量化与预测模型相关的不确定性。由51个成员组成的ECMWF集合预报系统是迄今为止最好的数值天气预报模式之一。风速和辐照度预报在风力和太阳预报中尤为重要,而温度预报则是负荷预报的重要手段。读者可参阅[44]了解集合天气预报的概述。
3.3 层次预测
与传统预测相比,分层预测有两个明显的优势。首先,一个层次的最终预测是一致的。换句话说,低水平预测的总和接近或等于相应的高水平预测。其次,调和后的预测往往(如果不是总是)比基本预测更准确。
关于层次预测:
- 层次预测的最新发展主要由Hyndman的研究小组[45]贡献。
- 在几个出版物中,阻碍层次预测大规模应用的计算问题已经被解决[46]-[48]。
- 由于框架的通用性,层次预测已被应用于能源预测,特别是负荷和太阳能预测,如[49]-[51]。
- GEFCom2012的负荷预测轨迹被设计为一个分层负荷预测问题,但参赛者都没有利用层级[52]。
- GEFCom2017致力于分层概率负荷预测[51],但分层的使用相当适度。在预选赛中选出的12名决赛选手中,只有4人采用了等级制度,但他们都没有进入预选赛的前6名。
- 层次调节既适用于点预测,也适用于概率预测。然而,对于相干性的定义,特别是在概率框架内,至今尚无共识。
3.4 概率预测
概率预测可以使用参数、半参数或非参数方法,以概率分布、分位数或区间的形式发布。无论发出哪种形式的概率预测,都可以使用从一种形式转换为另一种形式的方法。此外,用概率预测可以根据[55]中提出的指导方针归纳为点预测。
在最近的能源预测历史上,最重要的一步可能是从确定性的观点过渡到概率的观点。在概率预测方面,风电预测无疑处于领先地位,这在很大程度上可能是由于早期风力预报员和气象学家之间的密切合作。
生成良好概率预测的首要原则是在进行校准后提高清晰度[69]。为此,可以使用各种后处理技术(例如集成模型输出统计数据[70]或预测组合[71])来校准和优化初始预测。话虽如此,尽管其历史悠久,但结合概率预测仍然是一个代表性不足的话题[72]。组合预测分布,分位数和区间的方法也可能有所不同[73]-[75]。在负载预测领域可以找到一些特定示例。研究人员提出了各种预测组合策略,以生成和改进概率负荷预测[37],[76],[77]。其中一项是在[41]中首次提出用于概率价格预测的分位数回归平均法,尤其值得强调,因为它也被证明在概率负荷预测中有效[37],[76]。
3.5 预测比赛与六大数据来源
预测比赛
文献中第一个著名的能源预测竞赛可以追溯到20世纪90年代初,比赛的重点是提前一天负荷预测,由普吉声电力和照明公司主办。10名参赛者的模型各不相同,有神经网络模型、状态空间模型、多元回归模型等。多元回归模型被认为是14个竞争性模型中表现最好的[78]。
2001年,EUNITE网络组织了一场预测一个月日负荷的比赛,SVM在负荷预测领域闪亮登场,获奖作品主要基于支持向量机(SVM),这是SVM首次成功应用于负荷预测[24]。
与研究论文有关的数据
一些学术期刊鼓励作者提交数据和代码,以促进可重复的研究。除了在期刊上发布代码和数据,一些研究人员可能会将他们的代码上传到公共存储库,如GitHub[84]。有些人选择更进一步,在自由软件环境中开发软件包,例如R项目[85]。
ISO/RTO数据
独立系统运营商(ISOs)和区域传输运营商(RTOs)是另一个经常使用的数据源,尤其是负荷和价格数据。这些ISOs/RTOs发布的数据的长度、种类和质量各不相同。许多ISOs不发布天气信息,而天气信息是负载的重要驱动因素,影响价格。ISO新英格兰是那些使他们的数据档案易于获取的组织之一。因此,它是能源预测案例研究中经常被引用的组织。GEFCom2017的预选赛也使用了ISO新英格兰数据[51]。
智能电表项目
几个著名的智能电表项目已经向科学界发布了有价值的数据集。爱尔兰数据是常用的数据集之一[86]。“Pecan Street”和“Low
Carbon London”是科学文献中另外两个常用的数据来源。最近发表的一篇关于智能电表数据分析的评论已经涵盖了这些数据集,以及其他一些有用的数据集[87],读者可以在那里找到一个更全面的列表。
现场气象资料
对天气变量的现场测量来自地面气象站、浮标和无线电探空仪。经适当的仪器校正后,这些量度是最准确的天气资料。然而,现场数据很少,而且来自自主资源。因此,当为预测目的寻找这些测量值时,质量控制程序必须被放在高度优先的位置。例如,在太阳预报中,基线太阳辐射网(BSRN)和地表辐射预算网(SURFRAD)是两个质量最高的监测网络。这两个数据集都可以使用R中的+SolarD-ata+包[88],[89]来访问。
遥感数据
由于并不是所有地方都可以获得地面测量数据,通过遥感获取的网格化天气数据在天气预报中变得非常重要。这些遥感数据可能来自地球同步气象卫星或极地轨道飞行器上的仪器。在[90]中回顾了用于太阳预报的几个流行的遥感数据库。
数值天气预报和再分析数据
NWP的数据是由国家气象中心生成的,可以在世界各地提供,其中一些是免费的。尽管这些数据集托管在由不同气象机构维护的不同数据服务器上,但只要知道确切的链接,任何具有基本计算机知识的人都可以下载和使用这些数据。再分析是NWP资料的一个特殊情况,它实质上是使用一致同化方案的天气模式的再运行。最近的两次全球再分析是MERRA-2和ERA5,它们都提供了从1980年到现在每小时数以千计的大气变量。请注意,即使NWP数据是有用的输入,它们并不总是现成的,需要一些预处理和重新校准。对于在太阳预报中常用的NWP模型,读者可以参考[91]。这两个再分析的细节见[92]和[93]。
除了这六个重要的数据来源外,还有一些网站为能源预测提供开放数据,促进该领域的研究,如open Power System da-ta[94]和open energy modeling Initiative[95]。
3.6 论文的一些常见问题
首先,最重要的是,文献中的能源预测模型是使用唯一且有限的数据集进行评估的,例如较短的时间段,一个单一的位置以及从未在其他任何研究中使用过的数据集。 如果可能的话,这使得与文献中较早提出的模型进行比较存在问题。 另一个极端也是如此, 对某些数据集的研究非常好,以至于研究人员可能会使用一些将来的信息来给他们提出的方法带来不公平的优势。
其次,评估指标往往不充分。例如,平均绝对百分比误差(MAPE)用于接近零负荷、零价格或可再生能源发电。有时,作者倾向于选择支持他们所提议的方法的误差度量,但对其他误差度量隐藏了结果。
第三,许多论文避免了直接与经典的、已建立的和最先进的模型进行比较。一个假设的例子可以是提出一个神经网络、小波和粒子群优化的混合模型来预测风力发电,而竞争模型是一个具有任意结构和参数调整不良的神经网络模型。
最后但并非最不重要的是,各篇论文对预测术语的使用不一致,这往往导致对预测模型、方法和过程的含糊描述。有时,一个新术语被发明出来,使提议的想法看起来很新奇。这种做法通常会让文章在搜索引擎中很难被注意到,除非这个想法是真正具有开创性的,这使得这个新发明的术语得到广泛认可。
3.7 写论文的一些建议
文献综述
审稿人和编辑希望作者提供高质量的参考文献,以适当地为他们提出的研究奠定基础。
- 参考列表应该优先考虑最先进的方法和经典的方法。
- 文献的覆盖密度可能会随着该区域离核心提案越远而减少。例如,如果长期概率负荷预测提出的想法是使用一个方法,参考列表应该优先考虑其他长期概率负荷预测文件和其他文件,使用这个特定的方法,其次是长期负荷预测和概率负荷预测论文,再其次是负荷预测的论文和概率预测文件在其他能源预测子域,紧随其后的是一般预测的论文。
- 在汇编了引用列表之后,应该避免批量引用。与其在一句话的结尾引用多个引用,不如单独或小组讨论每个引用,这需要作者看到他们所引用的内容。
预测的术语
作者应避免在该领域引入行话。大多数问题和过程都可以通过精确地遵循现有的术语来清楚地解释。我们鼓励能源预测者追溯到预测、统计和机器学习文献中原始和正式的术语,如样本外测试[96]和交叉验证[97]。能源预测的一个重要概念是预测范围,它指的是为未来准备预测的时间长度。虽然能源预测的许多子领域使用“短”、“长”及其变体来描述预测范围,但定义往往是模糊的,鼓励作者用精确的语言来描述他们的预测过程。例如,“提前日预报”是指今天某个时候发布的下一个日历日24小时的预报,这与“提前24小时预报”不同。在太阳预报中,研究人员正在远离使用短期、中期和长期来描述预测范围。相反,他们使用小时内、一天内和前一天。
比较研究
要提出一个新想法,你必须将它与现有的想法进行比较,最好是最先进的方法或文献中已经建立的东西:
- 如果这个提议是针对一个新问题而没有确定的解决方案,那么就需要与朴素的方法进行比较。
- 当评估点或概率预测时,应该选择正确的错误或技能度量[54],[98]。当不同的模型在所选的误差度量中具有几乎相同的值时,应该进行显著性检验,如Diebold-Mariano检验。
- 有时,一份手稿呈现出令人惊讶的好结果,表明所提出的方法优于它的对手,这往往是太好而不真实的。如果得到了夸大的结果,建议作者进行全面检查,看看在参数估计、模型选择或超参数调优过程中,未来的信息是否泄露到过程中。
- 作者也被鼓励检查预测过程中的一个核心步骤是否容易替换。如果是这样,探索这些变化,以提供所提议方法的完整图景。
提高再现性
大多数有经验的编辑和审稿人都明白可重复研究的重要性,作者可以通过使用公共数据或发布他们的数据和代码来提高他们研究的可重复性。有时,研究赞助商可能不允许作者发表数据或代码。在这些情况下,必须使用正式的术语清楚地解释所提议的方法。
找到合适的期刊
并不是所有的手稿最终都能在顶级期刊上发表。为了避免浪费发表时间和评论资源,作者被鼓励寻找合适的期刊来发表他们的研究。例如,在图1中的22个主要的能源预测论文出版渠道中,在II-B部分被点名的论文不太可能被其他期刊拒绝。相反,他们大多在寻找具有高档案价值的研究,突破性的想法,以及对新问题的可靠的技术解决方案。一些期刊,如IEEE Transactions,可能要求一篇论文需要5名或5名以上的审稿人。有些期刊,比如《国际预测杂志》,只需要两个审稿人,但他们的审稿人通常给出全面的评论,可能导致重大修改。如果作者正在寻找一个简单的审查过程,他们可能想要寻找其他场所。一些期刊,如太阳能,强烈支持可重复的研究。愿意发布代码和数据的作者可以考虑这样的场合。
原文链接:
- A Review of Deep Learning Methods Applied on Load Forecasting
- Review on probabilistic forecasting of photovoltaic power production and electricity consumption
- Energy Forecasting: A Review and Outlook
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141534.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
