大家好,又见面了,我是你们的朋友全栈君。
这篇文章是Deep Residual Learning for Image Recognition 的翻译,精简部分内容的同时补充了相关的概念,如有错误,敬请指正。
Abstract
深度神经网络通常都比较难训练。我们提出残差学习的框架来减轻深层网络训练的难度。我们重新构建了网络以便学习包含推理的残差函数,而不是学习未经过推理的函数。实验结果显示,残差网络更容易优化,并且加深网络层数有助于提高正确率。在ImageNet上使用152层的残差网络(VGG net的8倍深度,但残差网络复杂度更低)。对这些网络使用集成方法实现了3.75%的错误率。获得了ILSVRC 2015竞赛的第一名。同时,我们也在CIFAR-10上分别使用100和1000层的网络进行了实验。
网络能表达的深层特征是许多视觉识别任务的关键。借助网络的深层表达能力,残差网络在COCO目标检测数据集上实现了28%的相对提升。
1. Introduction
深度卷积网络在图像分类任务上取得了一系列突破。深度网络通过多层端到端的方式,集成了低中高三个层次的特征和分类器,并且这些特征的数量还可以通过堆叠层数来增加。在ImageNet数据集上获胜的网络揭示了网络深度的重要性。
随着网络层数的增加,训练的问题随之凸显。比较显著的问题有梯度消失/爆炸,这会在一开始就影响收敛。收敛的问题可以通过正则化来得到部分的解决。
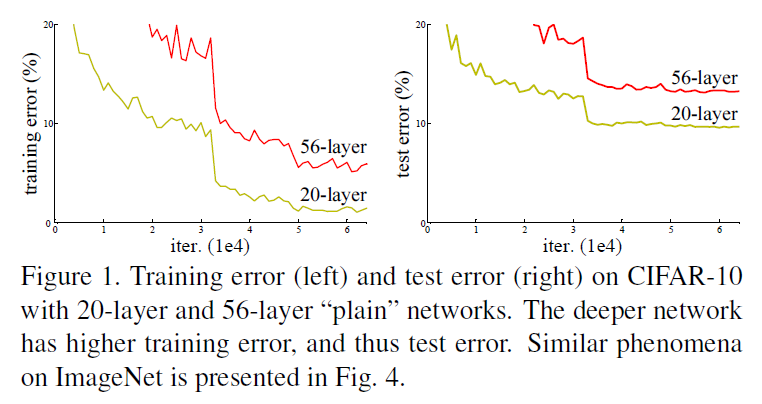
在深层网络能够收敛的前提下,随着网络深度的增加,正确率开始饱和甚至下降,称之为网络的退化(degradation)问题。 示例可见Figure 1. 显然,56层的网络相对于20层的网络,不管是训练误差还是测试误差都显著增大。

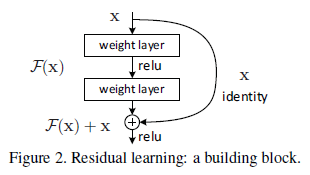
y=x
),这种情况下深层网络的训练误差应该和浅层网络相等。因此,网络退化的根本原因还是优化问题。 为了解决优化的难题,提出了残差网络。在残差网络中,不是让网络直接拟合原先的映射,而是拟合残差映射。 假设原始的映射为
H(x)
,残差网络拟合的映射为:
F(x):=H(x)
。
2. Related Work
Shortcut Connections
高速网络(highway networks)1和快捷连接有相似之处,但是高速网络中含有参数。高速网络中的gate在训练过程中可能关闭,相反,残差网络中的连接不会关闭,残差函数可以被学习。
3. Deep Residual Learning
在堆叠的几层网络上使用残差连接。整个网络的架构如图:
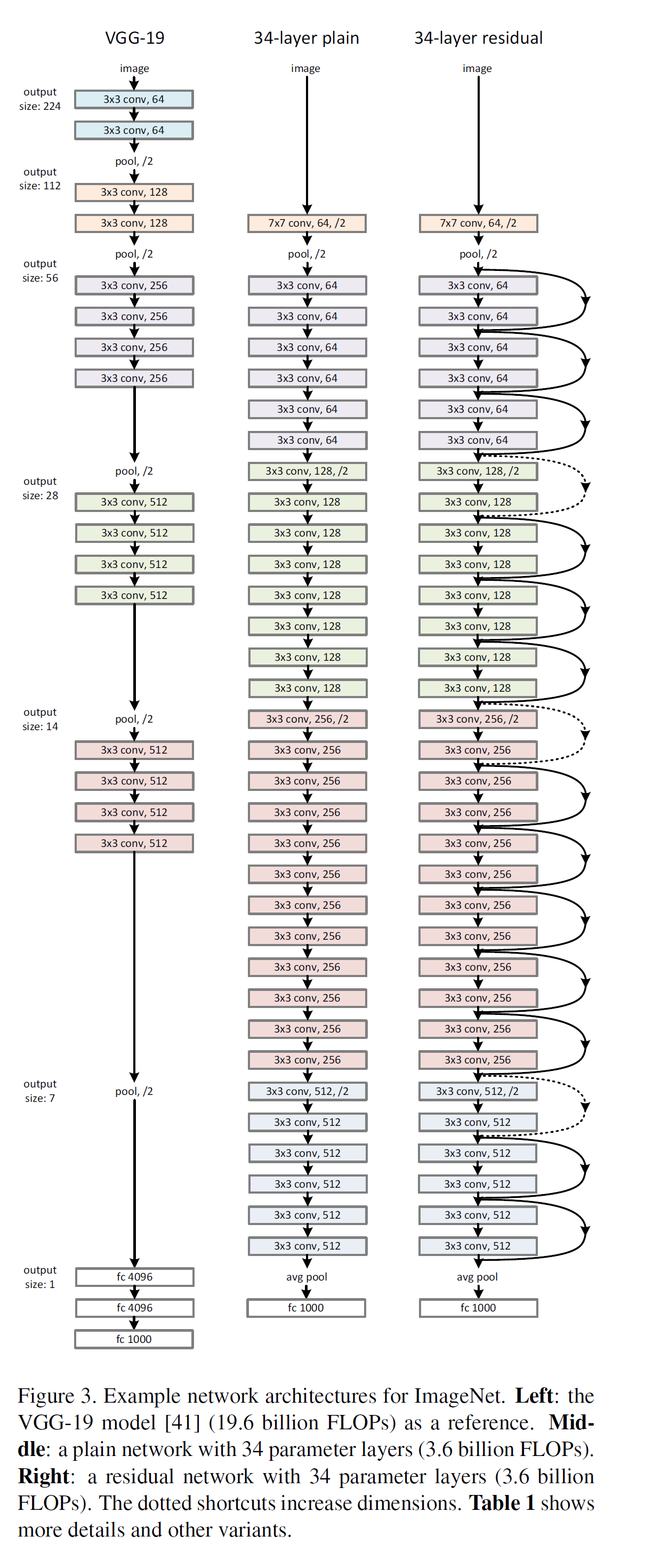
Implementation
在ImageNet上的测试设置如下:
图片使用欠采样放缩到 [256∗480] ,以提供尺寸上的数据增强。对原图作水平翻转,并且使用 [224∗224] 的随机采样,同时每一个像素作去均值处理。在每一个卷积层之后,激活函数之前使用BN。使用SGD,mini-batch大小为256。学习率的初始值为0.1,当训练误差不再缩小时降低学习率为原先的1/10继续训练。训练过程进行了600000次迭代。
4. Experiments
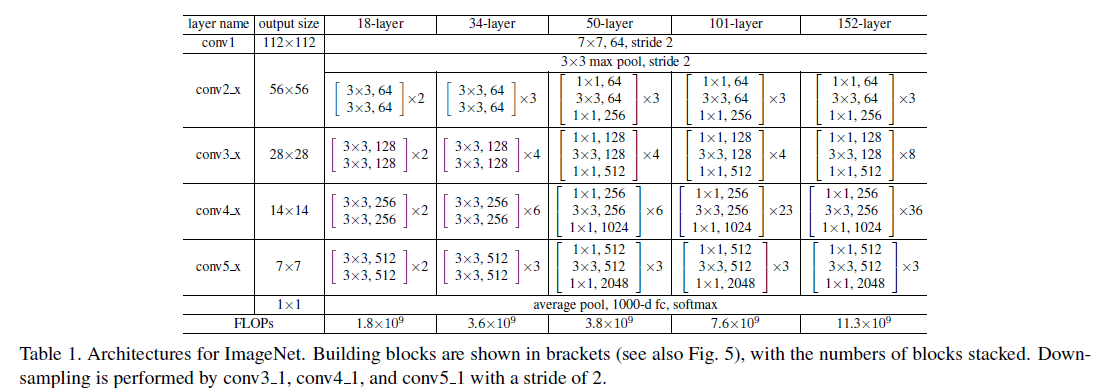
Table1中给出了不同层数的ResNet架构。
ImageNet Classification
Plain Networks
分别使用18层的plain nets和34层的plain nets,结果显示34层的网络有更高的验证误差。下图比较了整个过程的训练和测试误差:
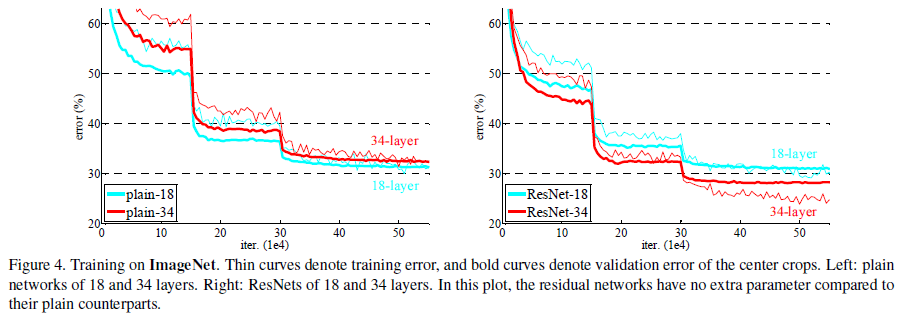
Residual Networks
测试18层和34层的ResNet。注意到34层的训练和测试误差都要比18层的小。这说明网络退化的问题得到了部分解决,通过加深网络深度,可以提高正确率。注意到18层的plain net和18层的ResNet可以达到相近的正确率,但是ResNet收敛更快。这说明网络不够深的时候,SGD还是能够找到很好的解。
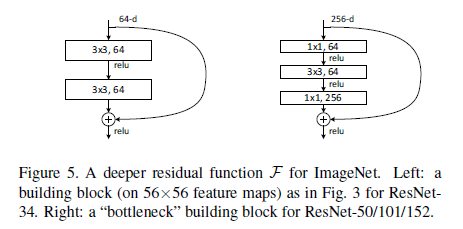
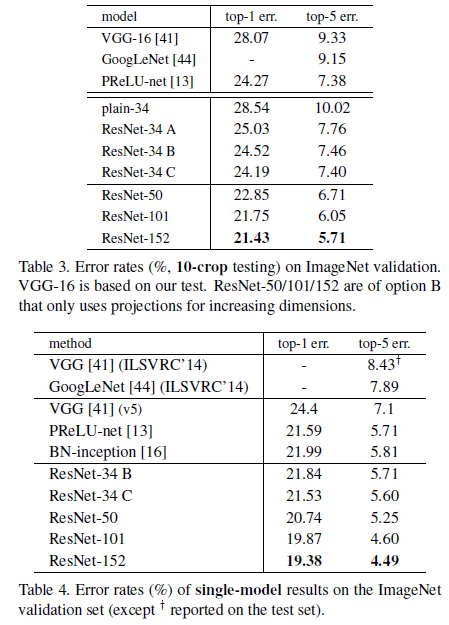
Identity vs. Projection Shortcuts
比较了三种选择:
(A)zero-padding shortcuts用来增加维度(Residual block的维度小于输出维度时,使用0来进行填充),所有的shortcut无参数。
(B)projection shortcuts用来增加维度(维度不一致时使用),其他的shortcut都是恒等映射(identity)类型。
(C)所有的shortcut都是使用projection shortcuts。
Table3中给出了实验结果:
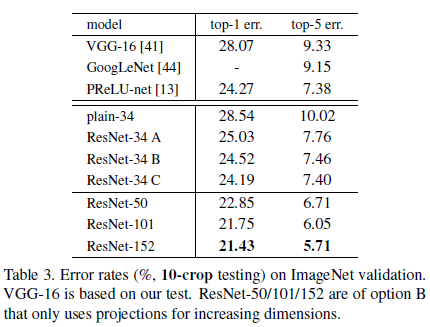
Deeper Bottleneck Architectures.
在探究更深层网络性能的时候,处于训练时间的考虑,我们使用bottleneck design的方式来设计building block。对于每一个残差函数 F ,使用一个三层的stack代替以前的两层。这三层分别使用1
×
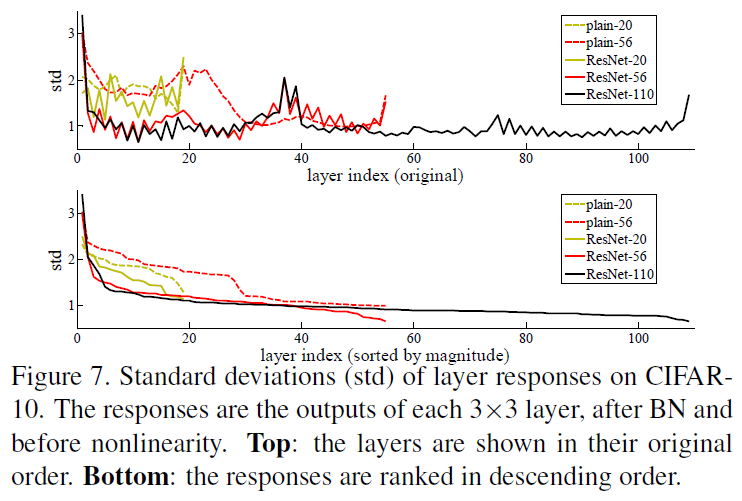
4.2. CIFAR10 and Analysis
在CIFAR10数据集上的测试表明,ResNet的layer对于输入信号具有更小的响应。
总结
ResNet和Highway Network的思路比较类似,都是将部分原始输入的信息不经过矩阵乘法和非线性变换,直接传输到下一层。这就如同在深层网络中建立了许多条信息高速公路。ResNet通过改变学习目标,即不再学习完整的输出 F(x) ,而是学习残差 H(x)−x ,解决了传统卷积层或全连接层在进行信息传递时存在的丢失、损耗等问题。通过直接将信息从输入绕道传输到输出,一定程度上保护了信息的完整性。同时,由于学习的目标是残差,简化了学习的难度。根据Schmidhuber教授的观点,ResNet类似于一个没有gates的LSTM网络,即旁路输入 x 一直向之后的层传递,而不需要学习。有论文表示,ResNet的效果类似于对不同层数网络进行集成方法。
Inplimentation
这里简单分析一下ResNet152在PyTorch上的实现。
源代码:https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
首先需要导入相关的库。注意这个文件中实现了五种不同层数的ResNet模型’resnet18’, ‘resnet34’, ‘resnet50’, ‘resnet101’, ‘resnet152’
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}接下来定义一个3*3的卷积模板,步长为1,并且使用大小为1的zeropadding。
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)之后定义基础模块BasicBlock。
1. 可以看出BasicBlock架构中,主要使用了两个
3∗3
out += residual这一句在输出上叠加了输入 x (注意到一开始定义了residual = x)
2. if self.downsample is not None:部分的代码,实际上是在进行欠采样,在网络的某些层可能会用到。
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out接下来定义Bottleneck模块。
这三层分别使用
1∗1
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out接下来定义整个残差网络。
1. 第一层卷积使用 7∗7 大小的模板,步长为2,padding为3。之后进行BN,ReLU和maxpool。这些构成了第一部分卷积模块。
2. 之后的layer1到layer4分别是四个不同的模块,具体细节可以参考Table1
3. _make_layer方法作用是生成多个卷积层,形成一个大的模块。
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x- R. K. Srivastava, K. Greff, and J. Schmidhuber. Highway networks.
arXiv:1505.00387, 2015. ↩
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141517.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
