大家好,又见面了,我是你们的朋友全栈君。
1.神经网络和自动编码器简介
神经网络概论
在计算机科学中,人工神经网络由成千上万个以特定方式连接的节点组成。节点通常分层排列; 它们的连接方式决定了网络的类型,最终决定了网络在另一网络上执行特定计算任务的能力。传统的神经网络可能看起来像这样:
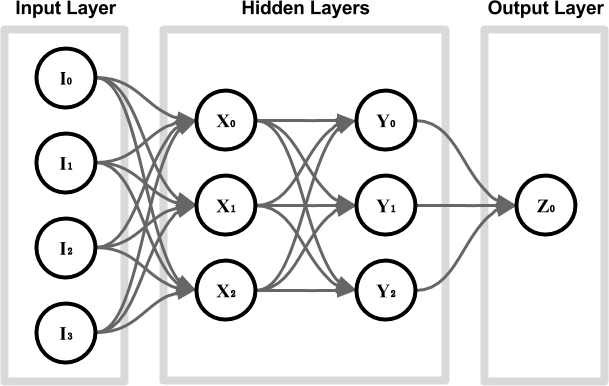

输入层中的每个节点(或人工神经元)都包含一个数值,该数值对我们要馈送到网络的输入进行编码。如果我们要预测明天的天气,则输入节点可能包含以范围内的数字编码的压力,温度,湿度和风速\ left [-1,+ 1 \ right]。这些值被广播到下一层。有趣的是,每个边缘都会衰减或放大其传输的值。每个节点将其接收到的所有值相加,并根据其自身的功能输出一个新值。计算结果可以从输出层中检索出来;在这种情况下,仅产生一个值(例如,下雨的概率)。
当图像是神经网络的输入(或输出)时,我们通常为每个像素有三个输入节点,并以其包含的红色,绿色和蓝色的数量进行初始化。迄今为止,基于图像的应用程序最有效的体系结构是卷积神经 网络(CNN),而这正是Deep Fakes所使用的。
训练神经网络意味着找到 所有边缘的一组 权重,以便输出层产生所需的结果。实现此目的最常用的技术之一是反向传播,它可以在每次网络出错时通过重新调整权重来工作。
人脸检测和图像生成背后的基本思想是,每一层将逐渐代表核心复杂特征。例如,在人脸的情况下,第一层可能会检测边缘,第二人脸特征是第三层能够用来检测图像的边缘(如下):

实际上,每一层的响应远非如此简单。这就是为什么《深梦》最初被用来研究卷积神经网络学习方式和方法的原因。
自动编码器
神经网络具有各种形状和大小。正是形状和大小决定了解决特定问题时网络的性能。自动编码器 是一种特殊的神经网络,其目的是匹配提供的输入。乍一看,自动编码器似乎只是玩具示例,因为它们似乎无法解决任何实际问题。
让我们看一下下面的网络,该网络具有两个完全连接的隐藏层,每个都有四个神经元。
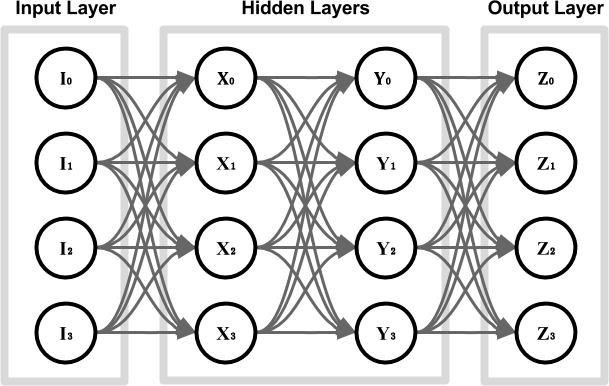
如果我们将此网络训练为自动编码器,则可能会遇到严重的问题。边缘可能会收敛到一个解决方案,在该解决方案中,将输入值简单地传输到其各自的输出节点中,如下图所示。当这种情况发生时,就没有真正的学习发生。网络已经重新布线,只需将输出节点连接到输入节点即可。
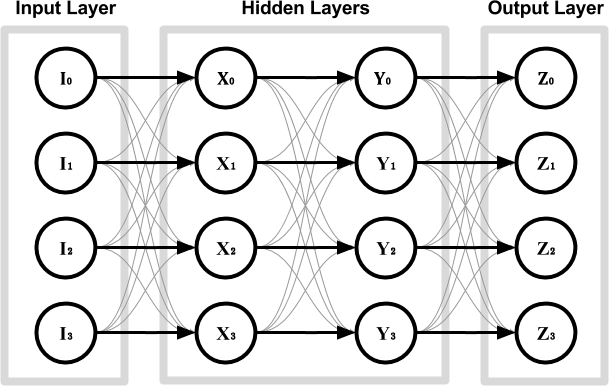
但是,如果其中一层具有较少的节点(下图),则会发生一些有趣的事情。在这种情况下,输入值不能简单地连接到它们各自的输出节点。为了成功完成此任务,自动编码器必须以某种方式压缩 所提供的信息,并在将其呈现为最终输出之前对其进行重构。
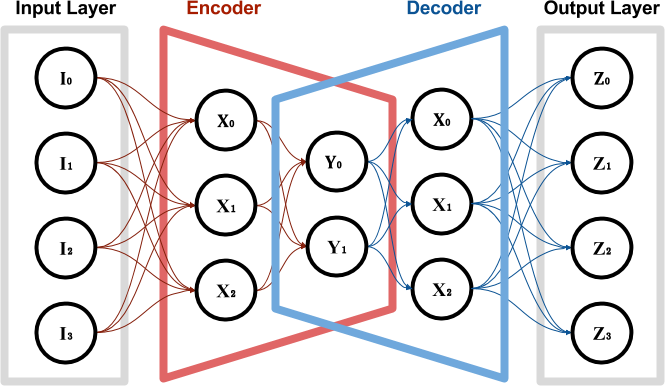
如果训练成功,则自动编码器将学习如何以其他但更紧凑的形式表示输入值。自动编码器可以解耦为两个独立的网络:编码器和解码器,两者共享中间的层。这些值[Y_0,Y_1]通常称为基本向量,它们代表所谓的潜伏空间中的输入图像。
自动编码器自然是有损的,这意味着它们将无法完美地重建输入图像。从下面的比较中可以看出这一点,该比较取自Keras中的Building Autoencoders。第一行显示了随机图像,这些图像已一张一张地馈送到训练有素的自动编码器。下方的行显示了网络如何重建它们。

但是,由于自动编码器被迫尽可能地重建输入图像,因此它必须学习如何识别和表示其最有意义的功能。由于较小的细节通常会被忽略或丢失,因此可以使用自动编码器对图像进行降噪(如下所示)。这非常有效,因为噪声不会添加任何真实信息,因此自动编码器可能会在更重要的功能上忽略它。

2.DeepFakes背后的技术
上一节 我们已经解释AutoEncoding的概念,以及如何神经网络可以用它来压缩和解压缩图像。

上图显示了图像(在此特定情况下为人脸)被馈送到编码器。其结果是该相同面的低维表示,有时称为基本矢量或潜面。根据网络体系结构,潜在的面孔可能根本看起来不像面孔。当通过解码器时,便会重建潜脸。自动编码器是有损耗的,因此重建的面部不太可能具有与最初相同的细节水平。
程序员可以完全控制网络的形状:多少层,每层多少个节点以及它们如何连接。网络的真实知识存储在连接节点的边缘中。每个边缘都有一个权重,找到使自动编码器像描述的那样工作的正确权重集是一个耗时的过程。
训练神经网络意味着优化其权重以实现特定目标。在传统的自动编码器的情况下,网络的性能是根据网络在潜在空间中的表示来重构原始图像的能力来衡量的。
训练假脸
重要的是要注意,如果我们分别训练两个自动编码器,它们将彼此不兼容。潜在面孔基于每个网络在训练过程中认为有意义的特定功能。但是,如果两个自动编码器分别在不同的面上训练,它们的潜在空间将表示不同的功能。
使人脸交换技术成为可能的原因是找到一种方法来强制将两个潜在人脸都编码在相同的特征上。Deepfakes通过让两个网络共享相同的编码器而使用两个不同的解码器来解决此问题。
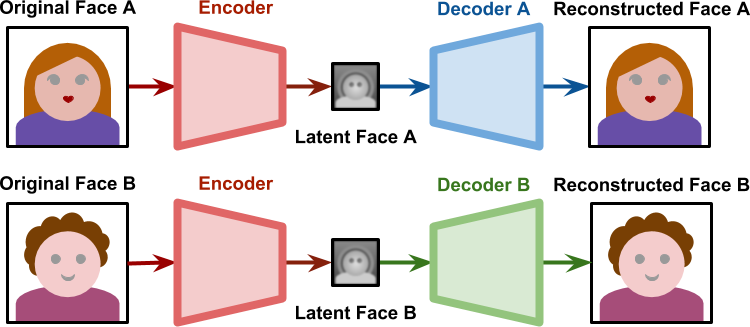
在培训阶段,将分别对待这两个网络。译码器A只训练了A的脸;译码器B只训练了B的脸。但是,所有的潜在面都是由同一个编码器产生的。这意味着编码器本身必须识别出两张脸的共同特征。因为所有的脸共享一个相似的结构,期望编码器学习脸本身的概念是不合理的。
生成假脸
训练过程完成后,我们可以将主题A生成的潜在特征 传递给解码器B。如下图所示,解码器B将尝试从与主题A相关的信息中重建主题B。
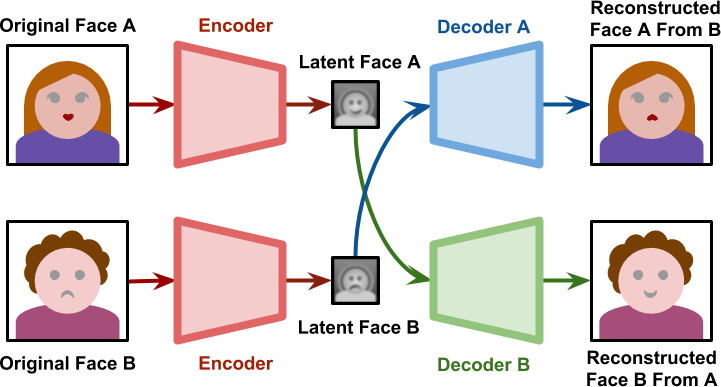
如果网络已经足够好地概括了构成面部的内容,则潜在空间将代表面部表情和方向。这意味着使用与主题A相同的表情和朝向为主题B生成面部。
为了更好地理解这意味着什么,您可以看下面的动画。在左侧,从视频(链接)中提取了UI艺术家Anisa Sanusi的脸 并进行了对齐。右边是经过训练的神经网络,正在重建游戏设计师Henry Hoffman的脸,以匹配Anisa的表情。

在这一点上,很明显,假脸背后的技术并不受约束。例如,它可以用于将苹果变成猕猴桃。

重要的是,训练中使用的两个科目应具有尽可能多的相似之处。这是为了确保共享编码器可以归纳出易于传输的有意义的功能。尽管此技术既可用于面部也可用于水果,但不太可能将面部转换为水果。
原链接:https://www.alanzucconi.com/2018/03/14/understanding-the-technology-behind-deepfakes/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141445.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
