
大家好,又见面了,我是你们的朋友全栈君。
SQL数据库之索引使用原则及利弊
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
优点
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序 子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
PS:正确的索引会大大提高数据查询、对结果排序、分组的操作效率。
缺点
- 存储空间,每个索引都要空间存储
- 如果非聚集索引很多,一旦聚集索引改变,那么所有非聚集索引都会跟着变。
- 过多索引会导致优化器优化过程需要评估的组合增多。
- 每个索引都有统计信息,索引越多统计信息越多。
- 更新开销,一旦一个数据改变,并且改变的列比较多,可能会引起好几个索引跟着改变。
PS:创建索引和维护索引要耗费时间,这种时间消耗会随着数据量的增加而增加;索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大;当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
分类
聚集索引>>
聚集索引基于数据行的键值,在表内排序和存储这些数据行。每个表只能有一个聚集索引,应为数据行本分只能按一个顺序存储。在聚集索引中,表中各行的物理顺序与索引键值的逻辑(索引)顺序相同。聚集索引通常可加快UPDATE和DELETE操作的速度,因为这两个操作需要读取大量的数据。创建或修改聚集索引可能要花很长时间,因为执行这两个操作时要在磁盘上对表的行进行重组。
非聚集索引>>
因为一个表中只能有一个聚集索引,如果需要在表中建立多个索引,则可以创建为非聚集索引。表中的数据并不按照非聚集索引列的顺序存储,但非聚集索引的索引行中保存了非聚集键值和行定位器,可以快捷地根据非聚集键的值来定位记录的存储位置。非聚集索引,本质上来说也是聚集索引的一种.非聚集索引并不改变其所在表的物理结构,而是额外生成一个聚集索引的B树结构,但叶子节点是对于其所在表的引用,这个引用分为两种,如果其所在表上没有聚集索引,则引用行号。如果其所在表上已经有了聚集索引,则引用聚集索引的页。
使用原则
- 不要索引数据量不大的表,对于小表来讲,表扫描的成本并不高。
- 不要设置过多的索引,在没有聚集索引的表中,最大可以设置249个非聚集索引,过多的索引首先会带来更大的磁盘空间,而且在数据发生修改时,对索引的维护是特别消耗性能的。
- 合理应用复合索引,有某些情况下可以考虑创建包含所有输出列的覆盖索引。
- 对经常使用范围查询的字段,可能考虑聚集索引。
- 避免对不常用的列,逻辑性列,大字段列创建索引。
创建索引
- 在经常需要搜索的列上,可以加快搜索的速度;
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
- 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
避免索引
- 对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
- 对于那 些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引并不能明显加快检索速度。
- 对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
- 当修改性能远远大于检索性能时,不应该创建索引。这是因为修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
索引算法
BTree索引
- BTree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用BTree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。按照翻译,B 通常认为是Balance的简称。这个数据结构一般用于数据库的索引,综合效率较高。逻辑结构为一颗N叉平衡树,每列中distinct key 都对应一个 RIDs(Row IDentifiers)数组。树状结构适合频繁的更新操作,适用于事物型数据库。
不适合场景
- 单列索引的列不能包含null的记录,复合索引的各个列不能包含同时为null的记录,否则会全表扫描;
- 不适合键值较少的列(重复数据较多的列),即低基数情况,索引结构空间冗余,B-Tree树上会存在大量相同键值的叶子节点,造成严重的空间和I/O扫描浪费;
- N叉平衡树的结构会随着记录的增多而膨胀。
- 单一索引路径选择问题,即SQL条件中包含多列时,即时每个列对应一个索引,在执行中也只能沿着一个索引的执行路径, 而其它列之能作为筛选条件。
- 前导模糊查询不能利用索引(like ‘%XX’或者like ‘%XX%’)
Hash散列索引
- Hash散列索引是根据HASH算法来构建的索引。虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。精确查找非常快(包括= <> 和in),其检索效率非常高,索引的检索可以一次定位,不像BTree 索引需要从根节点到枝节点,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
不适合场景
- 不适合模糊查询和范围查询(包括like,>,<,between……and等),由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样;
- 不适合排序,数据库无法利用索引的数据来提升排序性能,同样是因为Hash值的大小不确定;
- 复合索引不能利用部分索引字段查询,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
- 同样不适合键值较少的列(重复值较多的列);
Bitmap位图索引
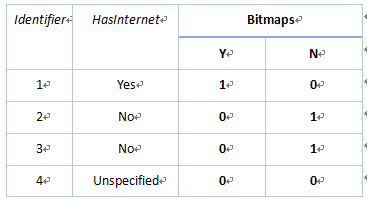
就是用位图表示的索引,对列的每个键值建立一个位图,即每列中的distinct key都对应一bit序列。相对于BTree索引,占用的空间非常小,创建和使用非常快。位图索引由于只存储键值的起止Rowid和位图,占用的空间非常少。下图是位图索引的一个直观描述。其中,Identifier列是每一行的唯一标识,HasInternet是索引列,那么右侧的Bitmaps下方的两列Y和N则表示左侧所对应的bitmap索引。

- 适合决策支持系统,数据仓库,OLAP类分析场景,图数据库;
- 当select count(XX) 时,可以直接访问索引中一个位图就快速得出统计数据;
- 当根据键值做and,or或 in(x,y,..)查询时,直接用索引的位图进行或运算,快速得出结果行数据。
- 利用计算机硬件对按位操作(AND/OR/XOR)的强有力的支持,从而使单列内部的按位操作可以有效的转化为按位逻辑操作。
- 多列之间的结果聚合也可以有效的转化为按位逻辑操作。
- 适合只读,较少更新或者追加的数据集上的查询操作。
不适合的场景
- 不适合键值较多的列(重复值较少的列);
- 不适合update、insert、delete频繁的列,代价很高。
- 更新操作慢,由于更新操作的锁只能有单用户获取,并且需要同时锁住很多索引,故并发性能较差。
转载来源:https://www.cnblogs.com/zuowj/p/3520509.html
参考来源:https://blog.csdn.net/u010265638/article/details/71191116
参考来源:https://blog.csdn.net/sanyaoxu_2/article/details/79026050
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141415.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...