大家好,又见面了,我是你们的朋友全栈君。
Protecting World Leaders Against Deep Fakes(CVPR 2020)
paper PDF
Introduction
深度学习的应用促使了人脸伪造技术的巨大进步。现有AI-合成的人脸伪造方式可以分为以下三种:
- face swap:将视频中出现的人脸替换为其他人的脸,一般对整个面部进行对齐和替换
- lip-sync:使得视频中的人物口型按照既定音频变化,一般仅伪造目标的唇部区域
- puppet-master:使视频中人物做出给定的面部表情,包括头部运动,一般需要对视频中人脸建立3D模型,并对唇部区域进行伪造
对图像和视频进行认证是一个悠久的话题,有大量的文献提出各种各样的方式。但利用人工智能合成是一个相对较新的技术,目前对该方面的认证技术还不够完善。现有的一些研究者试图通过发掘伪造过程中出现图像中存在的pixel-level的“痕迹”进行伪造检测。但是这种认证方式无疑对如图像压缩、resize、噪声等渲染攻击十分脆弱。
本文发现不同人在说话时,面部表情和头部运动存在明显的模式差异。而在上述的三种伪造方式中都对这种模式造成了破坏(即视频中的人脸区域发生了篡改,导致人物说话时面部表情和头部运动的模式与人物身份不相符)。利用这种方式,建立国家领导人个人的soft-biometric模型,并使用这些模型来区分视频的真假。
Innovation
- 对具体人物说话时面部表情和头部运动模式进行建模(20种面部运动单元的相关性),通过判断视频中人物所表现的说话模式是否与所建立的模型一致来判断是否是伪造视频。这种方式提取的高层特征,对压缩、resize等攻击具有较强的鲁棒性。
Method
利用OpenFace2对视频中的人脸提取以下20种运动单元的强度和发生情况。
inner brow raiser (AU01), outer brow raiser (AU02), brow lowerer (AU04), upper lid raiser (AU05), cheek raiser (AU06), lid tightener (AU07), nose wrinkler (AU09), upper lip raiser (AU10), lip corner puller (AU12), dimpler (AU14), lip cor- ner depressor (AU15), chin raiser (AU17), lip stretcher (AU20), lip tightener (AU23), lip part (AU25), jaw drop (AU26), head rotation about the x-axis (pitch),head rotation about the z-axis (roll),the 3-D horizontal distance between the corners of the mouth (mouthh),the 3-D vertical distance between the lower and upper lip (mouthv).
利用Pearson correlation计算这些运动单元之间的线性关系,以此来表征一个人的头部运动特征。一共有20种运动单元,共产生 C 20 2 = 20 × 19 ÷ 2 = 190 C_{20}^{2}=20 \times 19 \div 2=190 C202=20×19÷2=190维特征。通过某一具体领导人的视频数据集提取的该种特征来训练**one-class support vector machine (SVM)**模型,模型结果反应视频种该领导人是否伪造。对190维特征进行t-SNE可视化显示了这种特征的身份相关性。


Experiment
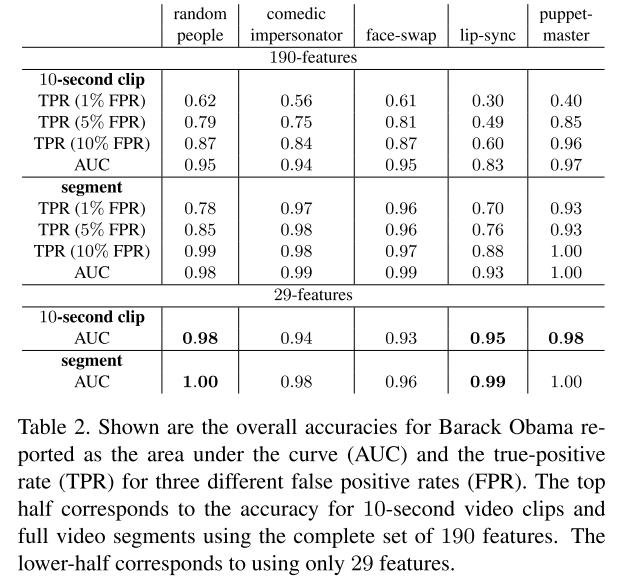
下表上半部分显示的是基于190个特征的奥巴马视频的准确度。前四行对应10秒clips的精度,后四行对应全视频片段的精度。10秒clips和完整片段的平均AUC值分别为0.93和0.98。其中lip-sync类型的视频,伪造检测的准确度较低,AUC分别为0.83和0.93,这可能是因为与其他伪造方式相比,lip-sync只篡改了嘴部区域。因此,许多面部表情和动作被保存在这些虚假视频中。作者提出可以考虑加入语言模型,获得特定人物说话时所说语言和唇部运动的相关模式来优化这方面的缺陷。
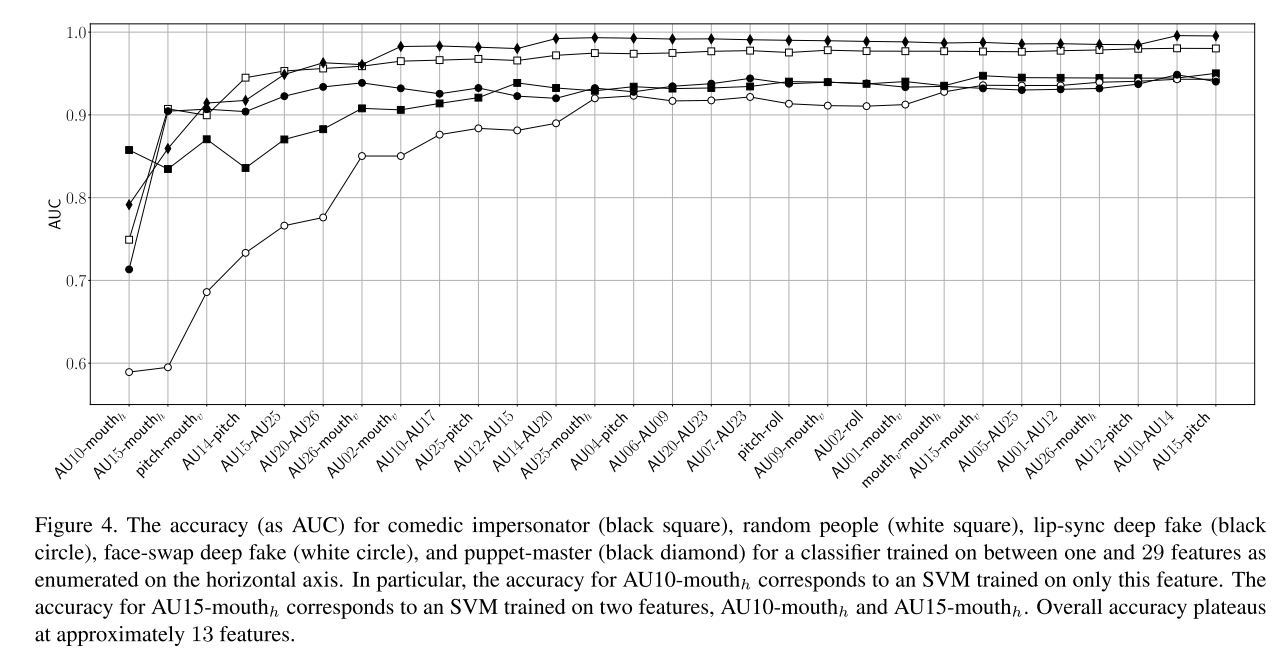
为了进一步选择合适的特征来区分不同人物的面部表情和头部运动模型,作者进行了从选择最优的一个特征,到选择全部190个特征进行训练。发现训练的准确率在29个特征时到达稳定水平,如下图:
鲁棒性研究,作者分别进行了压缩测试、视频长度测试。测试结果表明该种方式能够对视频的压缩和长短具有较强的鲁棒性。考虑到一个人的说话风格和面部行为可能会随着说话的语境而变化 ,作者也进行了不同语境下模型准确率的实验。测试结果显示不同的语境对测试结果有较大的影响,尤其是当说话者没有面对镜头的时候,这种运动单元的可靠性会大大降低。作者也提出扩大训练数据集、寻找更加鲁班的模式特征等方式以进一步改进模型效果。或者通过语言分析抓住说话内容和说话方式之间的相关性来扩充该模型。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/141385.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
