大家好,又见面了,我是你们的朋友全栈君。
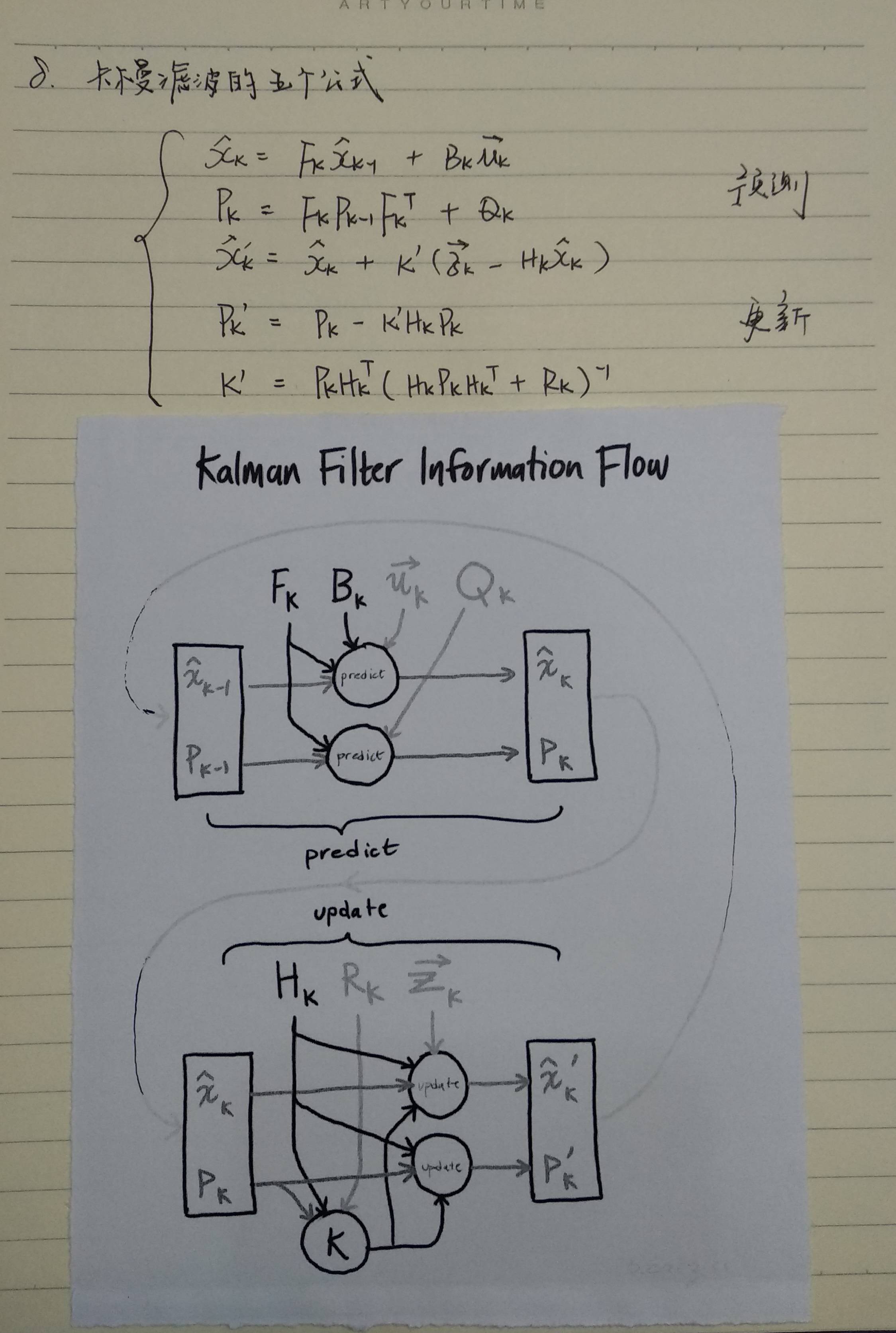
算法原理





python实现
# KF algorith demo by Leo
# 2020.01.06
# ZJG CAMPUS,ZJU
import numpy as np
import matplotlib.pyplot as plt
''' 生成带噪声的传感器观测值Z Z中一共包含500个samples,第k个sample代表k时刻传感器的读数 假设只对机器人位置进行传感器观测,并且只用距离表示位置 因此,Z中只有一个观测变量,即机器人的位置,这个位置一维数据表示 '''
# 生成不带噪声的数据
Z_raw = [i for i in range(500)]
# 创建一个均值为0,方差为1的高斯噪声,共有500个samples,精确到小数点后两位
noise = np.round(np.random.normal(0, 1, 500), 2)
# 将z的观测值和噪声相加
Z = np.mat(Z_raw) + np.mat(noise)
''' 定义状态向量X的初始状态 X中包含两个状态变量:p和v,二者都被初始化为0,且二者都用标量表示 '''
X = np.mat([[0,], [0,]])
''' 定义初始状态协方差矩阵P '''
P = np.mat([[1, 0], [0, 1]])
''' 定义状态转移矩阵F,假设每秒钟采一次样,所以delta_t = 1 '''
F = np.mat([[1, 1], [0, 1]])
''' 定义状态转移协方差矩阵Q 这里我们把协方差设置的很小,因为觉得状态转移矩阵准确度高 '''
Q = np.mat([[0.0001, 0], [0, 0.0001]])
''' 定义观测矩阵H '''
H = np.mat([1, 0])
''' 定义观测噪声协方差R '''
R = np.mat([1])
''' 卡尔曼滤波算法的预测和更新过程 '''
for i in range(100):
x_predict = F * X#demo中没有引入控制矩阵B
p_predict = F * P * F.T + Q
K = p_predict * H.T / (H * p_predict * H.T + R)
X = x_predict + K *(Z[0, i] - H * x_predict)
P = (np.eye(2) - K * H) * p_predict
print(X)
plt.plot(X[0, 0], X[1, 0], 'ro', markersize = 4)
plt.show()
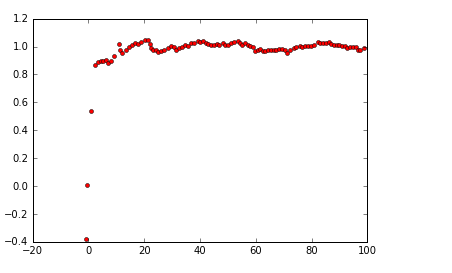
其中,横轴表示X[0,0],即位置p; 纵轴表示X[1,0],即速度v
可以看到速度v很快收敛于1.0,这是因为设置delta_t=1,即Z中的数据从0-500,每秒加1,卡尔曼滤波预测的速度与实际速度1.0很好的契合。
并且,我相信如果将横轴展开来看,卡尔曼滤波也对位置的预测具有很好的契合。
参考资料
1.[blog]详解卡尔曼滤波原理
翻译自http://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/
blog地址:https://blog.csdn.net/u010720661/article/details/63253509
2.[blog]我所理解的卡尔曼滤波
blog地址:https://www.jianshu.com/p/d3b1c3d307e0
3.[blog]卡尔曼滤波,最最容易理解的讲解.找遍网上就这篇看懂了.
blog地址:https://blog.csdn.net/phker/article/details/48468591
4.[paper]A New Approach to Linear Filtering
and Prediction Problems
paper地址:http://www.cs.unc.edu/~welch/kalman/media/pdf/Kalman1960.pdf
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/140986.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
